حاسوب فائق
الحاسب الفائق (بالإنجليزية: Supercomputer) أو الحاسوب الخارق، أو الحاسوب العملاق هو حاسوب ذو إمكانيات هائلة جداً يستخدم لمعالجة كم هائل جداً من البيانات وله القدرة على تخزين كم هائل جداً من البيانات والمعلومات والبرامج وهو لا يصلح للاستخدام الشخصي أو على مستوى مؤسسة محدودة إنما يستخدم على نطاق دولي حيث يمكنه ربط شبكة حاسبات آلية كبيرة جداً على نطاق واسع.

لقد تم استخدام مصطلح الحوسبة الفائقة "Super Computing" لأول مرة في New York World عام 1929 للإشارة إلى أجهزة تنظيم الجداول العملاقة التي قامت IBM بصناعتها لجامعة كولومبيا.
والجدير بالذكر أن أجهزة الحاسوب العملاقة قدمت في الستينات، وصممت في البداية من قبل «سيمور كراي» في Control Data Corporation، وبعد ذلك في Cray Research. في حين أن أجهزة الحاسوب العملاقة التي صممت في السبعينات كانت تستخدم عدد قليل من المعالجات فقط، إلا أنه في التسعينات، بدأت الآلات التي تحتوي على آلاف المعالجات في الظهور، وبحلول نهاية القرن العشرين، أصبحت أجهزة الحاسوب العملاقة المتوازية التي تمتلك عشرات الآلاف من المعالجات هي المعيار الأساسي لهذه الأجهزة.[2][3]
فالأنظمة ذات العدد الهائل من المعالجات، عادة ما تسلك أحد المسارين: النهج الأول، على سبيل المثال، في الحوسبة الشبكية تكون قوة معالجة عدد كبير من الحواسيب في المجالات الإدارية الموزعة والمتنوعة تنتهز الفرصة لاستخدامها كلما كان جهاز الحاسوب متاح. وفي النهج الآخر، يستخدم عدد كبير من المعالجات على مقربة من بعضها البعض، على سبيل المثال، في الحوسبة العنقودية. إن استخدام معالجات متعددة الأنوية جنباً إلى جنب مع المعالجات المركزية هو اتجاه ناشي.[4][5] واعتباراً من نوفمبر 2012، أصبح حاسب Cray Titan العملاق هو أسرع حاسوب في العالم.
وتلعب أجهزة الحاسوب العملاقة دوراً هاماً في مجال العلوم الحاسوبية، كما أنها تستخدم من أجل مجموعة واسعة من المهام المكثفة حسابياً في مختلف المجالات، بما فيها ميكانيكا الكم، التنبؤ بالطقس، أبحاث المناخ، التنقيب عن النفط والغاز، النمذجة الجزيئية (حوسبة تركيب وخواص المركبات الكيميائية، الجزيئات البيولوجية، البوليمرات والبلورات)، المحاكاة الفيزيائية (مثل محاكاة الطائرات في أنفاق الرياح، محاكاة تفجير الأسلحة النووية وأبحاث الاندماج النووي).
التاريخ
يرجع تاريخ الحوسبة العملاقة إلى الستينات، عندما صممت سلسلة من الحواسيب في Control Data Corporation بواسطة «سيمور كراي» بهدف استخدام التصاميم المبتكرة والتوازي لتحقيق أداء هائل في الذروة الحسابية.[6] هذا وقد أُطلق CDC 6600 عام 1964، والذي يعتبر بشكل عام هو أول حاسوب عملاق.[7][8]
ومن ناحية أخرى، فقد ترك «كراي» مركز CDC عام 1972 ليؤسس شركته الخاصة.[9] وبعد أربع سنوات من مغادرته CDC، قام «كراي» بإطلاق (80 MHz Cray 1) عام 1976، والذي أصبح واحد من أكثر أجهزة الحاسوب العملاقة نجاحاً في التاريخ.[10][11] كما أصدر (Cray-2) عام 1985، والذي كان عبارة عن حاسوب ذي 8 معالجات ذات تبريد سائل تضخ مادة Fluorinert من خلاله أثناء عمله. وكان يعمل بسرعة 1.9 جيجا فلوب، مما جعله الأسرع في العالم حتي 1990.[12]

في حين أن أجهزة الحاسوب العملاقة التي طرحت في الثمانينات لم تستخدم سوى عددا قليلا فقط من المعالجات، إلا أنه في التسعينات، بدأت الأجهزة التي تمتلك آلاف المعالجات في الظهور في كل من الولايات المتحدة واليابان، محققة أرقاماً قياسية جديدة في الأداء الحسابي. حيث استخدم الحاسوب العملاق Numerical Wind Tunnel التابع لشركة Fujitsu، 166 معالج موجه للحصول على المركز الأول في عام 1994 مع سرعة ذروة وصلت إلى 1.7 جيجا فلوب لكل معالج.[13][14] أما Hitachi SR2201، فقد حصل على أعلى مستويات الأداء بـ 600 جيجا فلوب عام 1996 عن طريق استخدام 2048 معالج متصل عن طريق شبكة عارضة سريعة ثلاثية الأبعاد.[15][16][17] في حين أن Intel Paragon يمكن أن يكون قد امتلك من 1000إلى 4000 معالج Intel i860 في تشكيلات مختلفة، وقد تم تصنيفه على أنه الأسرع في العالم عام 1993. وقد كان Paragon عبارة عن جهاز (MIMD) يقوم بتوصيل المعالجات عن طريق شبكة عالية السرعة ذات أبعاد ثنائية، والتي تسمح للمعالجات بتنفيذ العمليات في عقد منفصلة، وتتواصل عن طريق واجهة تمرير الرسائل[18] (Message Passing Interface).
المكونات والمعمارية

لقد اتخذت مناهج معمارية الحواسيب العملاقة منعطفات درامية منذ أن قدم أول نظام في الستينات. فمعمارية الحواسيب العملاقة الأولي والتي كان رائدها «سيمور كراي» اعتمدت على التصاميم المبتكرة والتوازي المحلي لتحقيق أداء حسابي متفوق.[6]
وبينما استخدمت الحواسيب العملاقة في السبعينات عدد قليل من المعالجات، إلا أنه في التسعينات، بدأت الأجهزة التي تستخدم آلاف المعالجات في الظهور بحلول نهاية القرن العشرين. ومن هذا المنطلق، أصبحت أجهزة الحواسيب العملاقة المتوازية التي تمتلك عشرات الآلاف من المعالجات هي المعيار الأساسي لهذه الأجهزة. ويمكن لأجهزة الحواسيب العملاقة في القرن 21 أن تستخدم أكثر من 100.000 معالج (بعضها وحدات رسم) متصلة بواسطة اتصالات سريعة.[2][3] طوال العقود الماضية، ظلت إدارة كثافة الحرارة قضية رئيسية بالنسبة لمعظم أجهزة الحاسوب العملاقة المركزية.[19][20][21] حيث أن كمية الحرارة الكبيرة المتولدة من النظام ربما يكون لها آثار أخرى أيضاً، على سبيل المثال، تخفيض العمر الافتراضي لمكونات النظام الأخرى.[22] ولذلك، فقد نشأت توجهات متنوعة لإدارة الحرارة، بدءاً من ضخ Fluorinert خلال النظام، وصولاً إلى نظام التبريد الهجين عن طريق الهواء والسوائل أو تبريد الهواء عن طريق درجة حرارة تكييف الهواء العادي.[12][23]
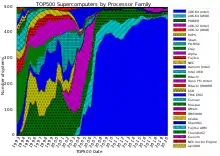
إن الأنظمة ذات العدد الهائل من المعالجات، عادة ما تسلك أحد المسارين: النهج الأول، المعروف بالحوسبة الشبكية حيث تكون قوة المعالجة في العدد الكبير من الحواسيب متنوعة في مجالات الإدارة والتوزيع وتنتهز الفرصة لاستخدامها كلما كان أي جهاز حاسوب متاحا. وفي النهج الآخر، يتم استخدام عدد كبير من المعالجات على مقربة من بعضها البعض، على سبيل المثال، في الحوسبة العنقودية. وفي مثل هذا النظام المركزي المتوازي الضخم تصبح سرعة ومرونة الربط مهمة جداً، وتستخدم الحواسيب العملاقة الحديثة مناهج مختلفة تتنوع بين أنظمة Infiniband وصولاً إلى الرقاقات ثلاثية الأبعاد.[24][25] ويعتبر استخدام المعالجات متعددة الأنوية جنباً إلى جنب مع المعالجات المركزية هو أحد الاتجاهات الناشئة حديثاً كما هو الحال في نظام Cyclops64.[4][5] وحيث أن سعر/أداء معالجات الرسومات المخصصة للأغراض العامة (GPGPUs) قد تحسن، فقد بدأت عدد من أجهزة الحاسوب العملاقة ذات سرعة " petaflop" مثل Tianhe-I و Nebulae بالاعتماد عليها.[26] ومع ذلك، فإن الأنظمة الأخرى مثل " K computer" استمرت في استخدام المعالجات التقليدية مثل SPARC وكان الاستعمال العام لمعالجات وحدات معالجة الرسومات في تطبيقات الحوسبة عالية الأداء محل نقاش دائم.[27] وعلى أية حال، فإن وحدات معالجة الرسومات ""GPU تكتسب شعبية لا بأس بها، وفي عام 2012 حوّل الحاسب العملاق Jaguarإلى Titan عن طريق استبدال وحدات المعالجة المركزية "CPU" بوحدات معالجة رسومات "GPU".[28][29][30] وقد صممت عدة أنظمة «الأغراض الخاصة»، المكرسة لمشكلة واحدة. ويسمح هذا باستخدام رقائق FPGA المبرمجة خصيصاً أو حتي رقائق VLSI التقليدية، والتي توفر معدلات أسعار/أداء أفضل عن طريق التضحية بالعمومية. وتتضمن الأمثلة الخاصة بالحواسيب العملاقة المتخصصة [31] Belle، [32] Deep Blue و [33] Hydra من أجل لعب الشطرنج، Gravity Pipe[34] من أجل الفيزياء الفلكية، MDGRAPE-3 من أجل حساب بنية البروتين الجزيئية[35] و Deep Crack[36] من أجل كسر شفرات DES.
استخدام الطاقة وإدارة الحرارة
الحاسوب العملاق التقليدي يستهلك كميات كبيرة من الطاقة الكهربائية، ويحول الغالبية العظمي منها تقريباً إلى حرارة والتي تتطلب عملية التبريد. على سبيل المثال، Tianhe-1A يستهلك 4.04 ميجا وات من الكهرباء.[37] ويمكن أن تكون تكلفة تشغيل وتبريد النظام كبيرة جداً، على سبيل المثال، 4 ميجا وات * 0.10 دولار لكل كيلو وات تصبح النتيجة الإجمالية 400 دولار في الساعة أو حوالي 3.5 مليون دولار في السنة.

إن إدارة الحرارة تعتبر قضية رئيسية في الأجهزة الإلكترونية المعقدة، وتؤثر على أنظمة الحاسوب القوية بعدد من الطرق المختلفة.[38] إن تصميم الطاقة الحرارية وطاقة وحدة المعالجة المركزية المستهلكة هي قضايا تتجاوز تلك التقنيات التبريدية الخاصة بالحواسيب التقليدية. وجوائز الحوسبة العملاقة الخاصة بالحوسبة الخضراء تعكس هذه القضية.[39][40][41] إن تجميع آلاف المعالجات مع بعضها البعض يولد بالتأكيد كميات ضخمة من الكثافة الحرارية التي تحتاج إلى التعامل معها. لقد كان Cray 2 يعمل بنظام تبريد سائل، واستخدم Fluorinert «شلال تبريد» والذي يتم ضخه من خلال الوحدات تحت الضغط.[12] ومع ذلك، فإن نهج التبريد بالسائل المغمور لم يكن عملي للأنظمة متعددة المقصورات والتي تعتمد على المعالجات الجاهزة للاستخدام، وفي نظام System X طوّر نظام تبريد خاص بالاشتراك مع شركة Liebert والذي دمج بين تكييف الهواء مع التبريد السائل.[23]
أما في نظام Blue Gene تعمدت IBM استخدام المعالجات منخفضة الطاقة للتعامل مع كثافة الحرارة.[42] ومن ناحية أخرى، فإن IBM Power 775 الذي أطلق عام 2011، قد قام بتجميع العناصر التي تحتاج إلى مياه تبريد بشكل وثيق.[43] ومن الناحية الأخرى، فقد استخدم IBM Aquasar system تبريد المياه الساخنة لتحقيق الكفاءة في استخدام الطاقة، حيث كان يتم استخدام المياه لتدفئة المباني كذلك.[44][45] وتقاس كفاءة استخدام الطاقة في أنظمة الحاسوب بشكل عام من حيث «فلوب لكل وات».[46][47] وفي 2008، عمل نظام Roadrunner التابع لشركة IBM بقوة 376 [48][49] MFLOPS/Watt. وفي نوفمبر 2010، وصل Blue Gene/Qإلى 1684 MFLOPS/Watt. أما في يونيو 2011، فإن أعلى مركزين في قائمة Green 500 قد أحتلت من قبل ماكينات Blue Gene في نيويورك (واحد منهم حقق 2097 MFLOPS/W) مع مُركب DEGIMA في ناغازاكي والذي حل ثالثاً مع 1375 MFLOPS/W.[50]
إدارة البرمجيات والنظام
نظام التشغيل
منذ نهاية القرن العشرين، خضعت أنظمة الحواسيب العملاقة لعدد من التحولات الكبري، نظرا لما طرأ من تغييرات في معمارية وتكوين هذه الأجهزة.[51] فبينما كانت الأنظمة الأولي مصممة خصيصاً لكل حاسوب عملاق [3] لإكسابه السرعة، كان يجب على الاتجاه أن يبتعد عن أنظمة التشغيل المحلية والاتجاه إلى تطويع برامج عامة مثل اللينكس.[52]
ومعرفة أن هذه الحواسيب العملاقة الحديثة المتوازية تقوم بفصل العمليات الحسابية عن الخدمات الأخرى عن طريق استخدام أنواع متعددة من العقد، فهي عادة ما تعمل بأنظمة تشغيل مختلفة على العقد المختلفة، على سبيل المثال – استخدام نواة صغيرة وخفيفة الوزن وذات كفاءة مثل CNK أو CNL على عُقد الحوسبة، ولكن يستخدم نظام أكبر مثل أحد مشتقات اللينكس على المخدم وعُقد الدخل والخرج.[53][54][55]
بينما في نظام الحاسوب متعدد المستخدمين التقليدي تكون جدولة الوظائف هي في الواقع مشكلة المهام للمعالجة والمصادر المحيطة، ولكن في النظام الموازي على نطاق واسع، يحتاج نظام إدارة الوظائف إلى إدارة توزيع كلا من الموارد الحاسوبية والاتصالات، وكذلك التعامل بأمان مع فشل الأجهزة الذي لا مفر منه عندما يكون هناك عشرات الآلاف من المعالجات موجودة.[56]
ورغم أن معظم الحواسيب العملاقة الحديثة تستخدم نظام التشغيل لينكس، إلا أن كل مُنتج قد وضع تغييراته الخاصة على النظام الذي يستخدمه، ولا يوجد هناك معيار ثابت للصناعة، ويرجع ذلك بشكل من الأشكال إلى حقيقة الاختلافات الموجودة في مكونات الأجهزة والتي تتطلب تغييرات لملائمة نظام التشغيل مع كل تصميم.[51][57]
أدوات البرمجيات وتمرير الرسائل

إن الأبنية الموازية للحواسيب العملاقة غالباً ما تحتاج لاستخدام تقنيات برمجة خاصة لاستغلال سرعتهم الفائقة. وتشمل أدوات البرمجيات الخاصة بالمعالجة الموزعة واجهات API تقليدية مثل MPI و PVM، VTL، وحلول البرمجيات القائمة على البرمجيات مفتوحة المصدر من مثل Beowulf. في السيناريوهات الأكثر شيوعاً، تستخدم البيئات مثل PVM و MPI الخاصة بالعناقيد المتصلة بحرية و OpenMP لإحكام استخدام ذاكرة آلات المشتركة. ويتطلب بذل جهد كبير من أجل تحسين خوارزمية لخصائص الربط الذي سيعمل عليها الجهاز، والهدف منذ ذلك هو منع أي وحدة من وحدات المعالجة المركزية من إضاعة الوقت في انتظار بيانات من العقد الأخرى. وتمتلك وحدات معالجة الرسومات العامة المئات من أنوية المعالجة ويتم برمجتها باستخدام نماذج البرمجة مثل CUDA.
الحوسبة العملاقة الموزعة
نهج الانتهازية (المناهج النفعية)

إن الحوسبة العملاقة الانتهازية هو شكل من أشكال شبكات الحوسبة الشبكية والتي بموجبها يقوم «حاسوب ظاهري عملاق» ذو آلات حوسبة عديدة متباعدة بتنفيذ مهام حوسبة كبيرة جداً. وقد تم تطبيق الحوسبة الشبكية على عدد من المشاكل الموازية الحرجة على نطاق واسع والتي تتطلب مقاييس أداء الحوسبة العملاقة. ومع ذلك، فإن مناهج الشبكة الأساسية والحوسبة السحابية التي تعتمد على الحوسبة التلقائية لا يمكن أن تعالج مهمات الحوسبة العملاقة التقليدية مثل المحاكاة الديناميكية للسوائل. إن أسرع نظام حوسبة شبكية هو مشروع الحوسبة الموزعة Folding@home. ويذكر أن Folding@home كانت تبلغ سرعته 8.1 بيتافلوب من قوة معالجة x86 وذلك في مارس 2012. من بين هذه السرعة هناك 5.8 بيتافلوب مساهمة من العملاء الذين يعملون على وحدات معالجة الرسومات المتنوعة، و 1.7 بيتافلوب تأتي من أنظمة البلاي ستيشن 3، والبقية تأتي من أنظمة وحدات المعالجة المركزية المختلفة.[59] وتستضيف منصة BOINC عدداً من مشاريع الحوسبة الموزعة. واعتباراً من مايو 2011، سجلت BOINC قوة معالجة بلغت أكثر من 5.5 بيتافلوب من خلال أكثر من 480.000 حاسوب نشط على الشبكة.[60] أما المشروع الأكثر نشاطاً (يقاس بواسطة قوة الحوسبة) MilkyWay@home، فقد سجل قوة معالجة أكثر من 700 تيرافلوب من خلال أكثر من 33.000 حاسوب نشط.[61] واعتباراً من مايو 2011م، قام Mersenne Prime التابع لمؤسسة GIMPS بتحقيق حوالي 60 تيرافلوب من خلال أكثر من 25.000 جهاز حاسوب مسجل.[62] ويقوم Internet PrimeNet Server بدعم نهج الحوسبة الشبكية الخاص بـ GIMPS، والذي يعتبر واحد من أقدم وأنجح مشاريع الحوسبة الشبكية منذ عام 1997. وفي2012م، صنع «سيمون كوكس» حاسوب عملاق يتكون من 64 جهاز Raspberry Pi. وقد أُطلق على الجهاز اسم Iridis-Pi. وقد بلغت تكلفة النظام بأكمله أقل من 2.500 جنيه استرليني (باستثناء المفاتيح) وبمجموع كلي من الذاكرة بلغ 1 تيرا بايت (بطاقات ذاكرة SD بسعة 16 جيجا بايت لكل جهاز Raspberry Pi).[63]
المناهج شبه الانتهازية (المناهج النفعية ظاهريا)
إن الحوسبة العملاقة الشبه انتهازية هي شكل من أشكال الحوسبة الموزعة والتي يقوم بموجبها «حاسوب ظاهري عملاق» ذو عدد كبير من الحواسيب صاحبة الشبكات المشتتة جغرافيا بأداء مهام حوسبة تتطلب قوة معالجة ضخمة.[64] وتهدف الحوسبة العملاقة الشبه انتهازية إلى توفير جودة أعلى للخدمة من الحوسبة الشبكية الانتهازية عن طريق تحقيق مزيد من السيطرة على توزيع المهام على المصادر المختلفة واستخدام تبادل المعلومات حول توافر وموثوقية الأنظمة الفردية داخل شبكة الحوسبة العملاقة. ومع ذلك، ينبغي تحقيق توزيع شبه الانتهازية الخاصة بطلب برامج الحوسبة المتوازية في الشبكات من خلال تنفيذ اتفاقيات توزيع الشبكات بحكمة، والأنظمة الفرعية المشاركة في التوزيع، وآليات توزيع الاتصالات المتعلقة بالطوبولوجيا، ومكتبات تمرير رسائل الخطأ والبيانات سابقة التكييف.[64]
قياس الأداء
القدرة مقابل السعة
تهدف الحواسيب العملاقة عموماً لتحقيق القدرة القصوى في قدرات الحوسبة بدلاً من سعة الحوسبة. وعادة ما يُعتقد أن قدرة الحوسبة تستخدم قوة الحوسبة القصوى لحل مشكلة كبيرة واحدة في أقصر وقت ممكن. وغالباً ما يكون نظام القدرة الحوسبية قادر على حل مشكلة ذات حجم أو تعقيد لا يمكن لأجهزة الحاسوب الأخرى حلها، على سبيل المثال تطبيق محاكاة معقدة جداً للطقس.[65] وفي المقابل، يُعتقد عادة أن سعة الحوسبة تستخدم قوة حوسبة ذات كفاءة غير مكلفة لحل عدد صغير من المشاكل الكبيرة نوعاً أو عدد كبير من المشاكل الصغيرة، على سبيل المثال، طلبات دخول العديد من المستخدمين لقاعدة بيانات أو موقع ويب. إن المعماريات التي تصلح لدعم العديد من المستخدمين من أجل المهام اليومية ربما يكون لديها الكثير من القدرات ولكنها لا تعتبر عادة حواسيب عملاقة، نظراً لأنها لا تستطيع حل مشكلة معقدة واحدة.[65]
مقاييس الأداء

بشكل عام، تقاس سرعة الحواسيب العملاقة وتقييمها عن طريق "FLOPS" (عمليات النقطة العائمة في الثانية) وليس من حيث MIPS أي (التعليمات في الثانية الواحدة)، كما هو الحال مع أجهزة الحاسوب المخصصة للأغراض العامة.[66] هذه القياسات عادة ما تُستخدم مع بادئة SI (سوابق النظام الدولي للوحدات) مثل تيرا-، جنباً إلى جنب مع الاختزال «تيرا فلوب» (1012 فلوب، تعني تيرا فلوب)، أو بيتا-، جنباً إلى جنب مع الاختزال «بيتا فلوب» (1015 فلوب، تعني بيتا فلوب). أما الحواسيب العملاقة بسرعة "Petascale" فيمكنها العمل بسرعة واحد كوادريليون (1015) (1000 تريليون) فلوب. ويعتبر Exascale هو أداء حوسبي في نطاق exaflops. وإكسافلوب هو واحد كوينتليون (1018) فلوب (مليون تيرا فلوب).
لا يمكن لرقم واحد أن يعكس الأداء الكلي لنظام الحاسوب، ومع ذلك، فإن هدف مؤشر Linpack هو تقريب مدى سرعة الحاسوب في حل المشاكل العددية، كما أنه يستخدم على نطاق واسع في الصناعة.[67] إن وحدة القياس FLOPS إما يتم نقلها بناءً على أداء النقطة العائمة النظري للمعالج (مشتق من مواصفات معالج الشركة المُصنعة ويتم إظهاره على شكل "Rpeak" في قوائم أفضل 500) والذي عادة ما يكون غير قابل للتحقيق عند تشغيل أحمال العمل الحقيقية، أو الإنتاجية القابلة للتحقيق، والمشتقة من معايير LINPACK ويتم عرضها كـ "Rmax" في قائمة أفضل 500. ويقوم مقياس LINPACK عادة بأداء تحليل LU لمصفوفة كبيرة. ويقوم أداء LINPACK بإعطاء بعض المؤشرات لأداء بعض المشاكل الحقيقية، ولكن لا يطابق بالضرورة متطلبات المعالجة لعديد من أحمال التشغيل الخاصة بالحواسيب العملاقة الأخرى، والتي على سبيل المثال قد تتطلب المزيد من مساحة الباندويث للذاكرة، أو قد تتطلب أداء أفضل للحوسبة، أو ربما تحتاج نظام I/O عالي الأداء لتحقيق مستويات عالية من الأداء.[67]
قائمة أفضل 500 (TOP500)

منذ عام 1993، صنفت أسرع الحواسيب العملاقة في قائمة TOP500 وفقاً لنتائجها في معايير LINPACK. القائمة لا تعتبر منحازة أو نهائية، ولكنها تعتبر تعريفا حاليا ذا مرجعية «لأسرع» حواسيب عملاقة متاحة في أي وقت من الأوقات. هذه هي القائمة الحالية لأجهزة الحاسوب التي ظهرت في أعلى قائمة [68] TOP500، وقد حصل "Peak speed" على تقييم "Rmax". وللمزيد من البيانات التاريخية انظر تاريخ الحوسبة العملاقة.
| Year | Supercomputer | فلوبس | Location |
|---|---|---|---|
| 2008 | آي بي إم عداء الطريق | 1.026 PFLOPS | مختبر لوس ألاموس الوطني، USA |
| 1.105 PFLOPS | |||
| 2009 | كراي جاغوار (حاسوب فائق) | 1.759 PFLOPS | مختبر أوك ردج الوطني، USA |
| 2010 | تيانهي-1A | 2.566 PFLOPS | تيانجين، الصين |
| 2011 | فوجيتسو حاسوب كيه | 10.51 PFLOPS | كوبه، اليابان |
| 2012 | كراي تيتان (حاسوب فائق) | 17.59 PFLOPS | أوك ريدج، USA |
| 2013 | الجامعة الوطنية لتكنولوجيا الدفاع تيانهي-2 | 33.86 PFLOPS | غوانزو، China |
لقد كان Sequoia هو أسرع حاسب عملاق في العالم بسرعة 16.32 بيتافلوب، والذي يستهلك 7890.0 كيلو وات حتي 29 أكتوبر 2012 عندما ظهر Titan على الساحة.[69][70]
تطبيقات الحواسيب العملاقة
يمكن تلخيص مراحل تطبيقات الحواسيب العملاقة في الجدول التالي:
| Decade | Uses and computer involved |
|---|---|
| 1970s | التنبؤ بالطقس، والبحوث الهوائية (كراي-1).[71] |
| 1980s | تحليل الأحتمالات،[72] نمذجة الحماية من الإشعاع[73] (CDC Cyber). |
| 1990s | Brute force code breaking (EFF DES cracker),[74] |
| 2000s | 3D nuclear test simulations as a substitute for legal conduct معاهدة الحد من انتشار الأسلحة النووية (ASCI Q).[75] |
| 2010s | Molecular Dynamics Simulation (تيانهي-1)[76] |
وقد استخدم حاسوب IBM Blue Gene/P في محاكاة عدد من الخلايا العصبية الاصطناعية بما يعادل حوالي 1% من القشرة الدماغية للإنسان، والتي تحتوي على 1.6 مليار خلية عصبية مع ما يقرب من 9 تريليون اتصال. وقد نجح نفس فريق البحث أيضاً في استخدام الحاسوب العملاق في محاكاة عدد من الخلايا العصبية الاصطناعية التي تعادل مجمل دماغ فأر.[77] ويعتمد التنبؤ بالأحوال الجوية في العصر الحديث أيضاً على أجهزة الحاسوب العملاقة. وتستخدم الإدارة الوطنية للمحيطات والغلاف الجوي أجهزة حاسوب عملاقة لسحق مئات الملايين من الملاحظات للمساعدة في جعل عملية التنبؤ بالطقس أكثر دقة.[78]
اتجاهات البحث والتطوير
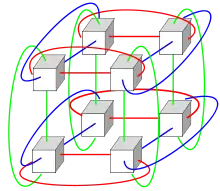
في 7 نوفمبر 2011، أعلنت شركة Fujitsu عن نظام متابعة بسرعة 32.2 بيتا فلوب خاص بجهاز K computer، والذي يُدعي PRIMEHPC FX10. وسوف يستخدم نفس أبعاد ربط الحيد السداسية ومعالج SPARC واحد فقط لكل عقدة.[79] وأعلنت الحكومة الصينية في 31 أكتوبر 2012، أنها تبني حاسوب عملاق بسرعة 100 بيتا فلوب يُدعي Tianhe-2، والمقرر الانتهاء منه عام 2015. وبالنظر إلى سرعة التقدم الحالية، يتوقع خبراء الصناعة أن الحواسيب العملاقة سوف تصل إلى 1 إكسا فلوب (1018) (واحد كوينتليون فلوب) بحلول 2018. وبالتزامن مع الإعلان عن حاسبهم العملاق، صرحت الصين أيضاً بوجود مخططات لديها للحصول على حاسوب عملاق بسرعة 1 إكسا فلوب بحلول 2018.[80] وباستخدام معمارية Intel MIC متعددة الأنوية، والتي تعتبر بمثابة رد إنتل على أنظمة وحدات معالجة الرسومات، تخطط SGI لتحقيق 500 ضعف زيادة في الأداء بحلول 2018، وذلك من أجل تحقيق 1 إكسا فلوب. كما أصبحت عينات رقائق MIC مع 32 نوي والتي تدمج بين وحدات معالجة الناقلات مع وحدة المعالجة المركزية القياسية متوفرة الآن.[81] وقد ذكرت الحكومة الهندية أيضاً عن طموحاتها في امتلاك حاسوب عملاق من فئة إكسا فلوب، والذي يأملون في الانتهاء منه في عام 2017.[82] وأشار «إريك ديبندياكتس» من مختبرات سانديا الوطنية في نظريته أن حاسوب zettaflop (1021) (واحد سكستليون فلوب) مطلوب من أجل تحقيق نمذجة كاملة للطقس، والتي يمكن أن تغطي أسبوعين كاملين بدقة.[83] ومثل هذا النظام ربما يتم بناؤه بحلول 2030.[84]
انظر أيضًا
مراجع
- "IBM Blue gene announcement"، 03.ibm.com، 26 يونيو 2007، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 09 يونيو 2012.
- Hoffman, Allan R. (1990)، Supercomputers: directions in technology and applications، National Academies، ص. 35–47، ISBN 0-309-04088-4، مؤرشف من الأصل في 10 أبريل 2022.
- Hill, Mark Donald؛ Jouppi؛ Sohi (1999)، Readings in computer architecture، ص. 40–49، ISBN 1-55860-539-8.
- Performance Modelling and Optimization of Memory Access on Cellular Computer Architecture Cyclops64 K Barner, GR Gao, Z Hu, Lecture Notes in Computer Science, 2005, Volume 3779, Network and Parallel Computing, Pages 132-143
- Analysis and performance results of computing betweenness centrality on IBM Cyclops64 by Guangming Tan, Vugranam C. Sreedhar and Guang R. Gao The Journal of Supercomputing Volume 56, Number 1, 1–24 September 2011
- Hardware software co-design of a multimedia SOC platform by Sao-Jie Chen, Guang-Huei Lin, Pao-Ann Hsiung, Yu-Hen Hu 2009 ISBN pages 70-72
- John Impagliazzo, John A. N. Lee (2004)، History of computing in education، ص. 172، ISBN 1-4020-8135-9، مؤرشف من الأصل في 30 ديسمبر 2016.
- Richard Sisson, Christian K. Zacher (2006)، The American Midwest: an interpretive encyclopedia، ص. 1489، ISBN 0-253-34886-2، مؤرشف من الأصل في 6 أكتوبر 2019.
- Hannan, Caryn (2008)، Wisconsin Biographical Dictionary، ص. 83–84، ISBN 1-878592-63-7، مؤرشف من الأصل في 29 ديسمبر 2016.
- Readings in computer architecture by Mark Donald Hill, Norman Paul Jouppi, Gurindar Sohi 1999 ISBN 978-1-55860-539-8 page 41-48
- Milestones in computer science and information technology by Edwin D. Reilly 2003 ISBN 1-57356-521-0 page 65
- Parallel computing for real-time signal processing and control by M. O. Tokhi, Mohammad Alamgir Hossain 2003 ISBN 978-1-85233-599-1 pages 201-202
- "TOP500 Annual Report 1994"، Netlib.org، 01 أكتوبر 1996، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 09 يونيو 2012.
- N. Hirose and M. Fukuda (1997)، "Numerical Wind Tunnel (NWT) and CFD Research at National Aerospace Laboratory"، Proceedings of HPC-Asia '97، IEEE Computer Society، doi:10.1109/HPC.1997.592130.
- H. Fujii, Y. Yasuda, H. Akashi, Y. Inagami, M. Koga, O. Ishihara, M. Kashiyama, H. Wada, T. Sumimoto, Architecture and performance of the Hitachi SR2201 massively parallel processor system, Proceedings of 11th International Parallel Processing Symposium, April 1997, Pages 233-241.
- Y. Iwasaki, The CP-PACS project, Nuclear Physics B - Proceedings Supplements, Volume 60, Issues 1-2, January 1998, Pages 246-254.
- A.J. van der Steen, Overview of recent supercomputers, Publication of the NCF, Stichting Nationale Computer Faciliteiten, the Netherlands, January 1997.
- Scalable input/output: achieving system balance by Daniel A. Reed 2003 ISBN 978-0-262-68142-1 page 182
- Xue-June Yang, Xiang-Ke Liao, et al in Journal of Computer Science and Technology، "The TianHe-1A Supercomputer: Its Hardware and Software"، ص. 344–351، مؤرشف من الأصل في 27 أبريل 2020، اطلع عليه بتاريخ أغسطس 2020.
{{استشهاد ويب}}: تحقق من التاريخ في:|تاريخ الوصول=(مساعدة)صيانة CS1: أسماء متعددة: قائمة المؤلفون (link) - The Supermen: Story of Seymour Cray and the Technical Wizards Behind the Supercomputer by Charles J. Murray 1997 ISBN 0-471-04885-2 pages 133-135
- Parallel Computational Fluid Dyynamics; Recent Advances and Future Directions edited by Rupak Biswas 2010 ISBN 1-60595-022-X page 401
- Supercomputing Research Advances by Yongge Huáng 2008 ISBN 1-60456-186-6 pages 313-314
- Computational science – ICCS 2005: 5th international conference edited by Vaidy S. Sunderam 2005, ISBN 3-540-26043-9, pages 60–67
- Knight, Will: "IBM creates world's most powerful computer", NewScientist.com news service, June 2007
- N. R. Agida؛ وآخرون (2005)، "Blue Gene/L Torus Interconnection Network | IBM Journal of Research and Development" (PDF)، Torus Interconnection Network، ص. 265، مؤرشف من الأصل (PDF) في 15 أغسطس 2011.
{{استشهاد ويب}}: Explicit use of et al. in:|مؤلف=(مساعدة) - Prickett, Timothy (31 مايو 2010)، "Top 500 supers – The Dawning of the GPUs"، =Theregister.co.uk، مؤرشف من الأصل في 20 يناير 2019.
{{استشهاد ويب}}: صيانة CS1: extra punctuation (link) - Hans Hacker et al in Facing the Multicore-Challenge: Aspects of New Paradigms and Technologies in Parallel Computing by Rainer Keller, David Kramer and Jan-Philipp Weiss (2010)، Considering GPGPU for HPC Centers: Is It Worth the Effort?، ص. 118–121، ISBN 3-642-16232-0، مؤرشف من الأصل في 5 فبراير 2020.
- Damon Poeter (, October 11, 2011)، "Cray's Titan Supercomputer for ORNL Could Be World's Fastest"، Pcmag.com، مؤرشف من الأصل في 20 يناير 2019.
{{استشهاد ويب}}: تحقق من التاريخ في:|تاريخ=(مساعدة) - Feldman, Michael (11 أكتوبر 2011)، "GPUs Will Morph ORNL's Jaguar Into 20-Petaflop Titan"، Hpcwire.com، مؤرشف من الأصل في 3 نوفمبر 2013.
- Timothy Prickett Morgan (11 أكتوبر 2011)، "Oak Ridge changes Jaguar's spots from CPUs to GPUs"، Theregister.co.uk، مؤرشف من الأصل في 20 يناير 2019.
- Condon, J.H. and K.Thompson, "Belle Chess Hardware", In Advances in Computer Chess 3 (ed.M.R.B.Clarke), Pergamon Press, 1982.
- Hsu, Feng-hsiung (2002)، "Behind Deep Blue: Building the Computer that Defeated the World Chess Champion"، دار نشر جامعة برنستون، ISBN 0-691-09065-3.
{{استشهاد بدورية محكمة}}: Cite journal requires|journal=(مساعدة) - C. Donninger, U. Lorenz. The Chess Monster Hydra. Proc. of 14th International Conference on Field-Programmable Logic and Applications (FPL), 2004, Antwerp – Belgium, LNCS 3203, pp. 927 – 932 نسخة محفوظة 27 أبريل 2020 على موقع واي باك مشين. [وصلة مكسورة]
- J Makino and M. Taiji, Scientific Simulations with Special Purpose Computers: The GRAPE Systems, Wiley. 1998.
- RIKEN press release, Completion of a one-petaflops computer system for simulation of molecular dynamics نسخة محفوظة 02 ديسمبر 2012 على موقع واي باك مشين. [وصلة مكسورة]
- Electronic Frontier Foundation (1998)، Cracking DES - Secrets of Encryption Research, Wiretap Politics & Chip Design، Oreilly & Associates Inc، ISBN 1-56592-520-3، مؤرشف من الأصل في 10 يناير 2020.
- "NVIDIA Tesla GPUs Power World's Fastest Supercomputer" (Press release)، Nvidia، 29 أكتوبر 2010، مؤرشف من الأصل في 2 مارس 2014.
- Balandin, Alexander A. (October 2009)، "Better Computing Through CPU Cooling"، Spectrum.ieee.org، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ أكتوبر 2020.
{{استشهاد ويب}}: تحقق من التاريخ في:|تاريخ الوصول=(مساعدة) - "The Green 500"، Green500.org، مؤرشف من الأصل في 17 مايو 2019.
- "Green 500 list ranks supercomputers"، iTnews Australia، مؤرشف من الأصل في 22 أكتوبر 2008.
- Wu-chun Feng (2003)، "Making a Case for Efficient Supercomputing | ACM Queue Magazine, Volume 1 Issue 7, 10 January 2003 doi 10.1145/957717.957772" (PDF)، مؤرشف من الأصل (PDF) في 30 مارس 2012.
- "IBM uncloaks 20 petaflops BlueGene/Q super"، The Register، 22 نوفمبر 2010، مؤرشف من الأصل في 28 أبريل 2019، اطلع عليه بتاريخ 25 نوفمبر 2010.
- Prickett, Timothy (15 يوليو 2011)، "''The Register'': IBM 'Blue Waters' super node washes ashore in August"، Theregister.co.uk، مؤرشف من الأصل في 12 أبريل 2019، اطلع عليه بتاريخ 09 يونيو 2012.
- "HPC Wire 2 July 2010"، Hpcwire.com، 02 يوليو 2010، مؤرشف من الأصل في 3 نوفمبر 2013، اطلع عليه بتاريخ 09 يونيو 2012.
- Martin LaMonica (10 مايو 2010)، "CNet 10 May 2010"، News.cnet.com، مؤرشف من الأصل في 1 نوفمبر 2013، اطلع عليه بتاريخ 09 يونيو 2012.
- "Government unveils world's fastest computer"، CNN، مؤرشف من الأصل في 10 يونيو 2008،
performing 376 million calculations for every watt of electricity used.
- "IBM Roadrunner Takes the Gold in the Petaflop Race"، مؤرشف من الأصل في 17 ديسمبر 2008.
- "Top500 Supercomputing List Reveals Computing Trends"، مؤرشف من الأصل في 20 يناير 2019،
IBM... BlueGene/Q system .. setting a record in power efficiency with a value of 1,680 MFLOPS/W, more than twice that of the next best system.
- "IBM Research A Clear Winner in Green 500"، مؤرشف من الأصل في 20 يناير 2019.
- "Green 500 list"، Green500.org، مؤرشف من الأصل في 26 مارس 2012، اطلع عليه بتاريخ 09 يونيو 2012.
- Encyclopedia of Parallel Computing by David Padua 2011 ISBN 0-387-09765-1 pages 426–429
- Knowing machines: essays on technical change by Donald MacKenzie 1998 ISBN 0-262-63188-1 page 149-151
- Euro-Par 2004 Parallel Processing: 10th International Euro-Par Conference 2004, by Marco Danelutto, Marco Vanneschi and Domenico Laforenza, ISBN 3-540-22924-8, page 835
- Euro-Par 2006 Parallel Processing: 12th International Euro-Par Conference, 2006, by Wolfgang E. Nagel, Wolfgang V. Walter and Wolfgang Lehner ISBN 3-540-37783-2 page
- An Evaluation of the Oak Ridge National Laboratory Cray XT3 by Sadaf R. Alam etal International Journal of High Performance Computing Applications February 2008 vol. 22 no. 1 52–80
- Open Job Management Architecture for the Blue Gene/L Supercomputer by Yariv Aridor et al. in Job scheduling strategies for parallel processing by Dror G. Feitelson 2005 ISBN 978-3-540-31024-2 pages 95–101
- "Top500 OS chart"، Top500.org، مؤرشف من الأصل في 5 مارس 2012، اطلع عليه بتاريخ 31 أكتوبر 2010.
- "Wide-angle view of the ALMA correlator"، ESO Press Release، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 13 فبراير 2013.
- "Folding@home: OS Statistics"، جامعة ستانفورد، مؤرشف من الأصل في 26 فبراير 2017، اطلع عليه بتاريخ 17 يونيو 2014.
{{استشهاد بدورية محكمة}}: Cite journal requires|journal=(مساعدة) نسخة محفوظة 26 فبراير 2017 على موقع واي باك مشين. - "BOINCstats: BOINC Combined"، بنية باركلي التحتية المفتوحة للحوسبة الشبكية، مؤرشف من الأصل في 04 مايو 2012، اطلع عليه بتاريخ 28 مايو 2011Note this link will give current statistics, not those on the date last accessed.
{{استشهاد بدورية محكمة}}: Cite journal requires|journal=(مساعدة)صيانة CS1: postscript (link) نسخة محفوظة 04 مايو 2012 على موقع واي باك مشين. - "BOINCstats: MilkyWay@home"، BOINC، مؤرشف من الأصل في 4 مايو 2012، اطلع عليه بتاريخ 28 مايو 2011Note this link will give current statistics, not those on the date last accessed
{{استشهاد بدورية محكمة}}: Cite journal requires|journal=(مساعدة)صيانة CS1: postscript (link) - "Internet PrimeNet Server Distributed Computing Technology for the Great Internet Mersenne Prime Search"، GIMPS، مؤرشف من الأصل في 25 مايو 2019، اطلع عليه بتاريخ 06 يونيو 2011.
- "Southampton engineers a Raspberry Pi Supercomputer :: University of Southampton"، Southampton.ac.uk، مؤرشف من الأصل في 5 ديسمبر 2015، اطلع عليه بتاريخ 20 أبريل 2013.
- Kravtsov, Valentin; Carmeli, David; Dubitzky, Werner; Orda, Ariel; Schuster, Assaf; Yoshpa, Benny، "Quasi-opportunistic supercomputing in grids, hot topic paper (2007)"، IEEE International Symposium on High Performance Distributed Computing، IEEE، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 04 أغسطس 2011.
- The Potential Impact of High-End Capability Computing on Four Illustrative Fields of Science and Engineering by Committee on the Potential Impact of High-End Computing on Illustrative Fields of Science and Engineering and National Research Council (28 October 2008) ISBN 0-309-12485-9 page 9
- Xingfu Wu (1999)، Performance Evaluation, Prediction and Visualization of Parallel Systems، ص. 114–117، ISBN 0-7923-8462-8، مؤرشف من الأصل في 5 فبراير 2020.
- Dongarra؛ Luszczek؛ Petitet (2003)، "The LINPACK Benchmark: past, present and future" (PDF)، Concurrency and Computation: Practice and Experience، John Wiley & Sons, Ltd.، ص. 803–820، مؤرشف من الأصل (PDF) في 20 يناير 2019
- Intel brochure – 11/91، "Directory page for Top500 lists. Result for each list since June 1993"، Top500.org، مؤرشف من الأصل في 27 أغسطس 2012، اطلع عليه بتاريخ 31 أكتوبر 2010.
- "TOP500 List - June 2012"، www.TOP500.org، 2012، مؤرشف من الأصل في 8 مارس 2019، اطلع عليه بتاريخ أكتوبر 2020.
{{استشهاد ويب}}: تحقق من التاريخ في:|تاريخ الوصول=(مساعدة)، الوسيط غير المعروف|شهر=تم تجاهله (مساعدة) - Titan supercomputer hits 20 petaflops of processing power PCWorld October 31 2012 نسخة محفوظة 03 يوليو 2017 على موقع واي باك مشين.
- "The Cray-1 Computer System" (PDF)، Cray Research, Inc، مؤرشف من الأصل (PDF) في 20 يناير 2019، اطلع عليه بتاريخ 25 مايو 2011.
- Joshi, Rajani R. (09 يونيو 1998)، "A new heuristic algorithm for probabilistic optimization"، Department of Mathematics and School of Biomedical Engineering, Indian Institute of Technology Powai, Bombay, India، مؤرشف من الأصل (Subscription required) في 22 أبريل 2009، اطلع عليه بتاريخ 01 يوليو 2008.
- "Abstract for SAMSY - Shielding Analysis Modular System"، OECD Nuclear Energy Agency, Issy-les-Moulineaux, France، مؤرشف من الأصل في 24 أكتوبر 2007، اطلع عليه بتاريخ 25 مايو 2011.
- "EFF DES Cracker Source Code"، Cosic.esat.kuleuven.be، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 08 يوليو 2011.
- "Disarmament Diplomacy: - DOE Supercomputing & Test Simulation Programme"، Acronym.org.uk، 22 أغسطس 2000، مؤرشف من الأصل في 8 مارس 2016، اطلع عليه بتاريخ 08 يوليو 2011.
- "China's Investment in GPU Supercomputing Begins to Pay Off Big Time!"، Blogs.nvidia.com، مؤرشف من الأصل في 15 مايو 2013، اطلع عليه بتاريخ 08 يوليو 2011.
- Kaku, Michio. فيزياء المستقبل (كتاب) (New York: Doubleday, 2011), 65.
- "Faster Supercomputers Aiding Weather Forecasts"، News.nationalgeographic.com، 28 أكتوبر 2010، مؤرشف من الأصل في 10 سبتمبر 2017، اطلع عليه بتاريخ 08 يوليو 2011.
- Fujitsu Unveils Post-K Supercomputer HPC Wire November 7 2011 نسخة محفوظة 12 ديسمبر 2011 على موقع واي باك مشين.
- Kan Michael (31 أكتوبر 2012)، "China is building a 100-petaflop supercomputer, InfoWorld, 31 October 2012"، infoworld.com، مؤرشف من الأصل في 23 أغسطس 2014، اطلع عليه بتاريخ 31 أكتوبر 2012.
- Agam Shah (20 يونيو 2011)، "SGI, Intel plan to speed supercomputers 500 times by 2018, ComputerWorld, 20 June 2011"، Computerworld.com، مؤرشف من الأصل في 23 أغسطس 2014، اطلع عليه بتاريخ 09 يونيو 2012.
- Dillow Clay (18 سبتمبر 2012)، "India Aims To Take The "World's Fastest Supercomputer" Crown By 2017, POPSCI, 9 September 2012"، popsci.com، مؤرشف من الأصل في 20 يناير 2019، اطلع عليه بتاريخ 31 أكتوبر 2012.
- DeBenedictis, Erik P. (2005)، "Reversible logic for supercomputing"، Proceedings of the 2nd conference on Computing frontiers، ص. 391–402، ISBN 1-59593-019-1.
- "IDF: Intel says Moore's Law holds until 2029"، Heise Online، 04 أبريل 2008، مؤرشف من الأصل في 08 ديسمبر 2013.
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تاريخ العلوم
بوابة تاريخ العلوم بوابة الولايات المتحدة
بوابة الولايات المتحدة بوابة إلكترونيات
بوابة إلكترونيات بوابة رحلات فضائية
بوابة رحلات فضائية بوابة تقنية المعلومات
بوابة تقنية المعلومات بوابة برمجة الحاسوب
بوابة برمجة الحاسوب بوابة لينكس
بوابة لينكس
| منظمات |
| ||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| تقنيات |
| ||||||||||||||||||||||||||||||||||||||||
| Linux adoption |
| ||||||||||||||||||||||||||||||||||||||||
| وسائل الإعلام |
| ||||||||||||||||||||||||||||||||||||||||
| أشخاص | |||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||
أحجام الحاسوب | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| صغري |
| ||||||||||||||
| متوسط | |||||||||||||||
| كبير | |||||||||||||||
| أخرى | |||||||||||||||
| |||||||||||||||