خوارزمية البحث الثنائي
في علم الحاسوب، خوارزمية البحث الثنائي (بالإنجليزية: Binary search algorithm)، المعروفة أيضًا باسم البحث المحدد بفاصل المنتصف،[1] أو البحث اللوغاريتمي،[2] أو القطع الثنائي،[3](1) هي خوارزمية بحث تجد موضع القيمة المستهدفة داخل مصفوفة مرتبة.[4][5] يقارن البحث الثنائي القيمة المستهدفة بالعنصر المتوسط من المصفوفة. إذا لم تكن متساوية، يتم التخلص من النصف الذي لا يمكن للهدف أن يكون فيه ويستمر البحث في النصف المتبقي؛ تتكرر العملية مرة أخرى مع أخذ العنصر المتوسط للمقارنة بالقيمة المستهدفة، حتى العثور على القيمة المستهدفة. إذا كانت نتيجة البحث أن النصف المتبقي فارغ من العناصر، فهذا يعني أن القيمة المُستهدفة غير موجودة في المصفوفة.
خوارزمية البحث الثنائي 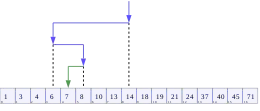 تصوُر خوارزمية البحث الثنائي حيث 7 هو القيمة المستهدفة
|
في أسوأ حالة يعمل البحث الثنائي في وقت لوغاريتمي، مُنجِزاً مقارنة، حيث هو عدد العناصر في المصفوفة، و هو تمثيل O الكبرى، و هو اللوغاريتم.[6] البحث الثنائي أسرع من البحث الخطي من خلال المصفوفات الصغيرة. مع ذلك، يجب ترتيب المصفوفة أولاً حتى تتمكن من تطبيق البحث الثنائي. هناك هياكل بيانات متخصصة مصممة للبحث السريع، مثل جداول التجزئة، والتي يمكن البحث عنها بكفاءة أكبر من البحث الثنائي. ومع ذلك، يمكن استخدام البحث الثنائي لحل مجموعة أكبر من المشاكل، مثل العثور على العنصر التالي الأصغر أو التالي الأكبر في المصفوفة بالنسبة للهدف حتى إذا لم يكن موجوداً في المصفوفة.




ثمة تطبيقات منوّعة للبحث الثنائي؛ على وجه الخصوص، يسرّع التتالي الجزئي عمليات البحث الثنائية عن قيمة واحدة في مصفوفات متعددة. وهو قادر على حل عدد من مشكلات البحث في الهندسة الحسابية وفي العديد من المجالات الأخرى بكفاءة عالية. يوسع البحثُ الأسّي البحثَ الثنائي ليشمل القوائم غير المحدودة، وتعتمد بنى بيانات شجرة البحث الثنائية والشجرة الثنائية على البحث الثنائي أيضاً.
خوارزمية العمل
الإجراءات
يعمل البحث الثنائي على المصفوفات المرتبة بهدف إيجاد موقع قيمة ما تُسمَّى القيمة المُستهدَفة أو القيمة الهدف. تبدأ العملية بمقارنة قيمة العنصر الموجود في منتصف المصفوفة بالقيمة المُستهدَفة، فإذا كانت هذه القيمة مُطابِقة لقيمة لعنصر، تُرجَع مرتبة العنصر في المصفوفة، وينتهي البحث. أَمَّا إذا كانت القيمة المُستهدَفة أقل من قيمة العنصر، فإن البحث سيستمر في النصف السفلي من المصفوفة. وأَمَّا إذا كانت القيمة المُستهدَفة أَصغر من قيمة العنصر، فإن البحث سيستمر في النصف العلوي من المصفوفة. يُحدد العنصر الموجود في منتصف نصف المصفوفة، وتعاد العملية السابقة حتى الوصول إلى القيمة المُستهدَفة أو انتهاء البحث دونَ ذلك، ويُقال عندها أن البحث غير ناجح أو أنه فَشِل في إيجاد القيمة المستهدفة في المصفوفة. في كل تكرار، تستبعد الخوارزمية النصف الذي لا يمكن أن توجد فيه القيمة المُستهدَفة.[7]
الإجراء الرئيس
إذا كانت مصفوفةً تحتوي على عنصر أو سجل هي: مرتبة بالشكل التالي: ، وإذا كانت القيمة المُستهدَفة هي ، فبالإمكان العثور على مرتبة القيمة المُستهدَفة في المصفوفة ، أي إنجاز بحثٍ ثُنائيّ، باستخدم الخوارزمية التالية:[7]




يتتبع هذا الإجراء التكراري حدود البحث باستخدام المتغيرين و اللّذين يُمثِّلان دائماً الحدين الأسفل والأعلى على الترتيب لجزء المصفوفة الذي تُطبَّق خوارزمية البحث الثنائي عليه. يمكن أيضاً التعبير عن الخوارزمية السابقة بالشيفرة التقريبية التالية، حيث تبقى أسماء وأنواع المتغيرات كما هي أعلاه، ويُمثِّل floor دالة الجزء الصحيح، وتشير الكلمة unsuccessful إلى قيمة رقمية محددة تُعبِّر عن فشل البحث.[7]


function binary_search(A, n, T) is
L := 0
R := n − 1
while L ≤ R do
m := floor((L + R) / 2)
if A[m] < T then
L := m + 1
else if A[m] > T then
R := m - 1
else:
return m
return unsuccessful
يمكن أيضاً أن تُستبدل دالة المتمم الصحيح الأعلى ceil بدالة الجزء الصحيح المُطبَّقة على القيمة . ولكن هذا قد يؤدي إلى إعطاء نتيجة مُغايرة إذا وجدت القيمة المُستهدَفة أكثر من مرة في المصفوفة.

إجراء بديل
في الإجراء الرئيس، ينجح البحث إذا كانت قيمة العنصر المتوسط تساوي القيمة المُستهدَفة () في كل تكرار. تتخلى بعض تنفيذات الخوارزمية عن إجراء هذا الفحص أثناء كل تكرار، ولا تنفّذه إلا عند بقاء عنصر واحد فقط، أي عندما يكون . ينتج عن هذا التغيير حلقة مقارنة أسرع بسبب استبعاد إجراء عملية المقارنة مرةً واحدةً عند كل تكرار. ولكن هذه الطريقة تتطلب إجراء تكرارٍ إضافي واحد في المتوسط.[8]


نشر هيرمان بوتينبروش أول تنفيذ للخوارزمية يتخلى عن إجراء فحص المساواة بالشكل السابق في عام 1962م.[8][9]
يمكن أيضاً التعبير عن الخوارزمية السابقة باستعمال الشيفرة التقريبية التالية:
function binary_search_alternative(A, n, T) is
L := 0
R := n − 1
while L != R do
m := ceil((L + R) / 2)
if A[m] > T then
R := m - 1
else:
L := m
if A[L] = T then
return L
return unsuccessful
التعامل مع العناصر المكررة
قد يُرجِع الإجراء مرتبة أي عنصر تكون قيمته مساويةً للقيمة المستهدفة، حتى ولو كان هناك عناصر مُكرَرة في المصفوفة. على سبيل المثال، إذا كانت المصفوفة التي يُراد البحث فيها هي: وكانت القيمة المستهدفة هي ، فإن الخوارزمية سُترجع العنصر الرابع، أي الذي تكون قيمة مرتبته 3، والخامس، أي الذي تكون قيمة مرتبته 4. سيعيد الإجراء الرئيس العنصر الرابع فقط في هذه الحالة. في بعض الأحيان، يكون من الضروري العثور على موقع العنصر الموجود في أقصى اليسار أو العنصر الموجود في أقصى اليمين ضمن مجموعة العناصر المكررة في المصفوفة. في المثال أعلاه، ومن أجل العناصر المكررة التي تكون قيمتها 4، فإنَّ العنصر الرابع هو العنصر الموجود في أقصى اليسار، في حين أن العنصر الخامس هو العنصر الموجود في أقصى اليمين. في الإجراء البديل، إذا وجدت مجموعة من العناصر المُكررة، فإن مرتبة العنصر الموجود في أقصى اليمين سيعاد دائماً.[9]


إجراء لإرجاع العنصر الموجود في أقصى اليسار
إذا كانت المصفوفة المُرتبة تحتوي على مجموعة من العناصر مكررة عددها ، يمكن استعمال الخوارزمية التالية لإرجاع العنصر الموجود في أقصى يسار مجموعة العناصر المرتبة:[10]
إذا كانت المتراجحة والشرط مُحققان، فإن هو العنصر الموجود في أقصى يسار مجموعة العناصر التي تساوي قيمة كل منها القيمة المستهدفة . حتى وإن كانت القيمة المُستهدفة غير موجودة في المصفوفة، فإن قيمة ، الناتجة عن تنفيذ الإجراء، ستمثل مرتبة القيمة المُستهدفة التي يجب أن تكون فيها، لو وجدت في المصفوفة، أو عدد عناصر المصفوفة التي كانت ستوجد قبل العنصر المُحدد بالقيمة المستهدفة.



يمكن أيضاً التعبير عن الخوارزمية السابقة بالشيفرة التقريبية التالية:
function binary_search_leftmost(A, n, T):
L := 0
R := n
while L < R:
m := floor((L + R) / 2)
if A[m] < T:
L := m + 1
else:
R := m
return L
إجراء لإرجاع العنصر الموجود في أقصى اليمين
إذا كانت المصفوفة المُرتبة تحتوي على مجموعة متكررة من العناصر عددها ، يمكن استعمال الخوارزمية التالية لإرجاع العنصر الموجود في أقصى يمين مجموعة العناصر المرتبة:[10]
إذا كانت المتراجحة والشرط مُتحققان، فإن هو العنصر الموجود في أقصى يمين مجموعة العناصر التي تساوي قيمة كل منها القيمة المستهدفة . حتى وإن كانت القيمة المُستهدفة غير موجودة في المصفوفة، فإن قيمة ، الناتجة عن تنفيذ الإجراء، ستمثِّل عدد عناصر المصفوفة التي كانت ستوجد بعد العنصر المُحدد بالقيمة المستهدفة، لو وُجِدَ.




يمكن أيضاً التعبير عن الخوارزمية السابقة بالشيفرة التقريبية التالية:
function binary_search_rightmost(A, n, T):
L := 0
R := n
while L < R:
m := floor((L + R) / 2)
if A[m] > T:
R := m
else:
L := m + 1
return R - 1
تطابقات تقريبية


تبحث الإجراءات السابقة عن التطابقات التامة بين القيمة المستهدفة وعناصر المصفوفة المُرَتَّبة، ثُمَّ تعيد موضع العنصر المتطابق في المصفوفة. وعلى أي حال، يمكن توسيع البحث الثنائي ليشمل البحث عن تطابقات تقريبية اعتماداً على فكرة أن البحث الثنائي يعمل على المصفوفات المُرتبة. على سبيل المثال، من أجل قيمة مستهدفة ما غير موجودة في المصوفة، يُمكن استخدام البحث الثنائي لحساب مرتبة القيمة، أي عدد عناصر المصفوفة ذوات القيم الأصغر منها، والمرتبة السابقة لها، أي مرتبة العنصر السابق الأصغر، والمرتبة اللاحقة لها، أي مرتبة العنصر التالي الأكبر، والجار الأقرب لها. يمكن أيضاً الاستعلام عن مجالٍ ما أي البحث عن عدد العناصر الموجودة بين قيمتين في المصفوفة باستخدام الاستعلامات سابقة الذكر.[11]
يمكن أيضاً تنفيذ استعلامات عن المرتبة بواسطة الإجراء الخاص بالعثور على العنصر الموجود في أقصى اليسار، حيث يُرجع عدد العناصر التي تكون قيمتها أقل من القيمة المستهدفة.[11] ويمكن تنفيذ استعلامات عن المرتبة السابقة باستخدام الاستعلامات عن المرتبة، فإذا كانت مرتبة القيمة المستهدفة هو ، فإن مرتبة القيمة السابقة هي .[12] أما فيما يخص استعلامات مرتبة القيمة اللاحقة، فبالإمكان استخدام الإجراء المُخصص للعثور على العنصر الموجود في أقصى اليمين لأجل ذلك، فإذا كانت نتيجة مرتبة القيمة المستهدفة هي ، فإن مرتبة القيمة اللاحقة لها هي .[12] يُحدد الجار الأقرب للقيمة المستهدفة بالنظر إلى المرتبتين السابقة واللاحقة لها، واختيار أقرب منهما. تٌنفَّذ الاستعلامات عن النطاق حسبَ ما يأتي: قي البداية تُحدد مرتبتي القيمتين، ثُمَّ يُحسَب عدد العناصر ذات القمية المساوية أو الأكبر من الأولى والأقل من القيمة الثانية بإيجاد الفرق بين المرتبتين.[12] يمكن تعديل هذا العدد نحو القيمة الصحيحة التالية أوالسابقة، أي التي تنقص أو تزيد بمقدار واحد، حسبَ طريقة تحديد بداية ونهاية النطاق، أي هل نقطة البداية ونقطة النهاية جزءٌ من النطاق أم لا، وهل تحتوي المصفوفة على عناصر تتطابق قيمتها مع نقاط النهاية أم لا.[13]



تقييم الأداء



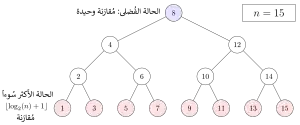
من حيث عدد المقارنات، يمكن تحليل أداء البحث الثنائي من خلال استعرض سير الإجراء على شجرة ثنائية. تكون العقدة الجذر في الشجرة هي العنصر المتوسط في المصفوفة. بعد ذلك، يكون العنصر المتوسط في النصف الأسفل من المصفوفة هو العقدة الفرعية اليسرى للجذر، والعنصر المتوسط في النصف الأعلى من المصفوفة هو العقدة الفرعية اليمنى للجذر. ثمَّ يُبنى ما تبقى من الشجرة الثنائية باتباع نفس الطريقة. عند تطبيق الإجراء، يبدَأ البحث من العقدة الجذر، وتكون هي العقدة المنظورة، وتقارن قيمتها مع القيمة المُستهدفة، فإذا كانت القيمة المُستهدَفة أكبر من قيمة العقدة المنظورة تصبح العقدة المنظورة التالية هي العقدة الفرعية اليمنى للجذر، وإذا كانت القيمة المُستهدفة أصغر من قيمة العقدة المنظورة فإن العقدة المنظورة التالية تصبح العقدة الفرعية اليسرى للجذر، وتكرر عملية المقالة والتحرك على فروع الشجرة الثنائية نحو اليمين أو اليسار حسبَ ما سبق، حتى تكون القيمة المُستهدفة مساوية للقيمة المنظورة، وعندها البحث يتوقف بنجاح.[6][14]
في أسوأ حالة، يكرر البحث الثنائي حلقة المقارنة مرَّة، حيث هو رمز دالة القسم الصحيح، وتعطي أكبر عدد صحيح يكون أصغر أو مساوٍ للقيمة التي تمرر لها، أي إذا مررنا 2.5 مثلاً، فإنها ستعيد القيمة 2. أمَّا فهي دالة اللوغاريتم الثنائي. ويعني الوصول إلى الحالة الأكثر سوءاً بلوغ أعمق مستوى للشجرة. في شجرة بحث ثنائي عدد عناصرها هناك دائماً مستوىً. ويمكن أيضاً الوصول إلى الحالة الأكثر سوءاً عندما تكون القيمة المستهدفة غير موجودة في المصفوفة.[15]




مع افتراض البحث عن كل عنصر موجود في المصفوفة فإن إجراء البحث الثنائي، فإن متوسط عدد مرات تكرار إجراء البحث الثنائي يُحسب بالعلاقة التالية:

ويساوي هذا تقريباً تكرار.

إذا لم تكن القيمة المستهدفة في المصفوفة، فإن عدد مرات تكرار الإجراء يُحسب وسطياً بالعلاقة:

وذلك على افتراض البحث عن كل عنصر موجود في المصفوفة.[14]
في أفضل الأحوال، تكون القيمة المستهدفة هي العنصر المتوسط للمصفوفة، وعندها ترجع مرتبة العنصر المتوسط بعد تكرار الإجراء مرة واحدة فقط.[16]
من حيث عدد مرات تكرار الإجراء، ليس هناك أي خوارزمية بحث أخرى، تعتمد على مقارنة العناصر فقط، لها قيمة أداء وسطية أفضل من خوارزمية البحث الثنائي، وكذا الأمر في الحالتين الفضلى والأكثر سوءاً. تحتوي شجرة المقارنة التي تمثل البحث الثنائي على أقل عدد ممكن من المستويات، فجميع المستويات فيها، ما خلا المستوى الأخير، تكون ممتلئة بالعناصر بسعتها القصوى،(3) وذلك لأن تقسيم المصفوفة إلى نصفين متساويين، أو قريبين من التساوي، تضمن أن تكون أحجام المصفوفات الفرعية الناتجة متساوياً أو شبه متساوٍ وبالتالي تكون الشجرة الثنائية التي تمثل المصفوفة متوازنة بأفضل صورة ممكنة. بناء على ما سبق، يكون عدد العناصر المُستبعَدة في كل تكرار أعظم ما يُمكن، ويقلل ذلك عدد مرات التكرار الوسطي اللازمة للعثور على القيمة المستهدفة، وكذا الأمر في الحالة الأكثر سوءاً. قد تعمل بعض خوارزميات البحث الأخرى التي تعتمد على المقارنة أسرع من حرازمية البحث الثنائي من أجل بعض القيم المستهدفة، ولكن متوسط أداء الخوارزمية، من أجل عناصر المصفوفة جميعها يكون ذات قيمة أكبر من تلك التي تحققها خوارزمية البحث الثنائي.[14]
تعقيد الفضاء
يتطلب البحث الثنائي استعمال ثلاثة مؤشرات للعناصر، قد تكون فهارس للمصفوفة أو مؤشرات لمواقع الذاكرة، وذلك بغض النظر عن حجم المصفوفة. بالإضافة لذلك، يتطلب البحث الثنائي بت على الأقل من أجل ترميز مؤشرٍ إلى عنصر ما في مصفوفة تحتوي عنصراً، ويحتاج أيضاً من مساحة التخزين من أجل المصفوفة السابقة نفسه.[17] لذلك، فإن تعقيد فضاء البحث الثنائي هو .


اشتقاق الحالة المتوسطة
يعتمد متوسط عدد التكرارات التي يقوم بها البحث الثنائي على احتمال وجود كل عنصر يجري البحث عنه. تختلف الحالة المتوسطة لعمليات البحث الناجحة عن تلك المرتبطة بعمليات البحث غير الناجحة. تُعرَّف الحالة المتوسطة لعمليات البحث الناجحة بأنها عدد التكرارات المطلوبة للبحث في كل عنصر في المصفوفة مرة واحدة بالضبط، مقسومةً على عدد العناصر فيها. أما الحالة المتوسطة لعمليات البحث غير الناجحة فهي عدد التكرارات المطلوبة للبحث عن عنصر ما في كل المجالات الفاصلة مرة واحدة بالضبط، مَقسُوماً على عدد الفواصل، أي .[14]

فيما يأتي، من أجل عمليات البحث الناجحة، سيُفترض أن البحث الثنائي يحصل بصورة متكافئة عن كل عنصر في المصفوفة، أمَّا من أجل عمليات البحث غير الناجحة، فسيُفترض أن البحث الثنائي يحصل بصورة متكافئة على الفواصل بين العناصر غير الموجودة في المصفوفة وعلى الفواصل بين العناصر غير الموجودة وتلك الموجودة في المصفوفة.
عمليات البحث الناجحة
في تمثيل الشجرة الثنائية، يمكن عرض بحث ثنائي ناجح على شكل مسار يبدأ من الجذر وينتهي عند العقدة المستهدفة، ويسمَّى بالمسار الداخلي نحو ذلك العنصر، ويكون طوله مساوياً لعدد الوصلات التي يمر بها المسار. أما طول المسار الداخل في المصفوفة فهو مجموع أطوال جميع المسارات الداخلية نحو العناصر الفريدة. أمَّا فيما يخص عدد التكرارات التي يقوم بها بحث ما، فإذا كان طول المسار الداخلي لعنصر ما هو وصلة، فإن عدد التكرارات المنجزة لبلوغه يكون وشاملاً التكرار الأول. اذا كان هناك عنصراً، وهو عدد صحيح موجب، وكان طول المسارات الداخلية هو ، فإن متوسط عدد التكرارات لعملية بحث ناجحة هو ، وقد أضيف واحد لجعل العلاقة تشمل التكرار الأول.[14]




بما أن خوارزمية البحث الثنائي هي الخوارزمية المثلى لعمليات البحث مع مقارنة، فإن بالإمكان اختزال هذه المسالة لحساب الطول الأصغر للمسار الداخلي في الأشجار الثنائية التي تضم عقدة، أي إلى ، وهو يُحسب باستعمال العلاقة:[18]

على سبيل المثال، في مصفوفة مكونة من سبعة عناصر، يتطلب البحث عن الجذر تكراراً واحداً فقط، ويتطلب البحث عن العنصرين الموجودين أسفل الجذر تكرارين لكل منها، ويتطلب البحث عن العناصر الأربعة الواقعة في المستوى الأعمق ثلاثة تكرارات لكل منها. وفي هذه الحالة، يكون طول المسار الداخلي في المصفوفة:[18]

أمَّا متوسط عدد التكرارات فيمكن أن يحسب وفق معادلة الحالة المتوسطة وتكون قيمته: .

ويمكن أيضاً تبسيط طول المسارات الداخلية أيضاً وفق ما يأتي:[14]

وإذا عُوِّضت القيمة السابقة لطول المسارات الداخلية في معادلة حساب متوسط عدد التكرارات لعملية بحث ناجحة، أي ، فإنها تؤول إلى الشكل التالي:[14]

من أجل عدد صحيح ما ، فإن هذه العلاقة تكافئ تلك المُستعملة لحساب الحالة المتوسطة في بحث ناجح.
عمليات البحث غير الناجحة
يمكن تمثيل عمليات البحث غير الناجحة من خلال توسيع الشجرة عن طريق إضافة عقد خارجية إليها، لتنتج شجرة ثنائية مُوسَّعة. إذا كان لدى عقدة داخلية ما، أي لدى عقدة موجودة في الشجرة، أقل من عقدتين فرعيتين، فتضاف عقدٌ فرعيةٌ خارجيةٌ لها، بحيث يكون لكل عقدة داخلية ابنان اثنان. بعد ذلك، يمكن تمثيل البحث الثنائي غير الناجح على شكل مسار إلى عقدة خارجية، يكون والدها هو العنصر الوحيد الذي بقي في أثناء التكرار الأخير.
يُعرَّف المسار الخارجي بأنه مسارٌ يبدأ من الجذر وينتهي في عقدة خارجية، وطول المسار الخارجي نحو عنصر ما بأنه عدد الوصلات فيه، وطول المسار الخارجي هو مجموع أطوال المسارات الخارجية نحو عناصر المصفوفة جميعها.
إذا كان هناك عنصر في المصفوفة، وهو عدد صحيح موجب، وإذا كان طول المسار الخارجي هو ، فإنَّ متوسط عدد التكرارات لعملية بحث غير ناجح يحسب بالعلاقة التالية:


قُسِّم طول المسار الخارجي على بدلًا من لأن هناك مساراً خارجياً، يمثل الفواصل بين عناصر المصفوفة نفسهم وبين عناصر المصفوفة والعناصر الخارجية.[14]
وبنفس الطريقة المتبعة مع عمليات البحث الناجحة، يمكن اختزال هذه المسألة لتحديد الطول الأدنى للمسار الخارجي لجميع الأشجار الثنائية من أجل عقدة وهو يساوي طول المسار الداخلي مضافاً له .[18] وبتعويض ذلك في المعادلة المستخدمة لحساب طول المسارات الداخلية تنتج المعادلة التالية لحساب طول المسار الخارجي:[14]


بتعويض القيمة الناتجة لطول المسار الخارجي في معادلة حساب متوسط عدد التكرارات لعملية بحث غير ناجح ، يمكن الحصول على المعادلة التالية:[14]


تقييم أداء الإجراء البديل
يؤدي كل تكرار لإجراء البحث الثنائي الموصوف في الأعلى إلى مقارنة واحدة أو مقارنتين اثنتين للتحقق فيما إذا كان العنصر المتوسط يساوي القيمة المستهدفة. على افتراض أن عملية البحث عن العناصر جميعها تحصل بصورة متكافئة، فإن كل تكرار سيؤدي إلى 1.5 مقارنة وسطياً.
هناك شكل من أشكال خوارزمية البحث الثنائي يتحقق فيما إذا كان العنصر المتوسط يساوي الهدف في نهاية البحث فقط. وسطياً، يلغي هذا الشكل نصف مقارنة من كل تكرار. يؤدي هذا إلى تقليل الوقت المستغرق في التكرار بشكل طفيف على معظم أجهزة الحاسوب. ومع ذلك، فإن هذه الخوارزمية تضمن أن يقوم البحث بالعدد الأقصى من التكرارات. وسطياً، يضاف تكرارٌ واحد إلى البحث، بسبب تنفيذ حلقة المقارنة مرة فقط في أسوأ الحالات. إن الزيادة الطفيفة في قيمة الكفاءة من أجل كل تكرار لا تعوّض التكرار الفائض الإجمالي في كل الحالات، بل فقط عندما يكون عدد العناصر كبيراً جداً.[19][20](4)
وقت التشغيل واستخدام ذاكرة التخزين المؤقت
يُدرس الوقت المطلوب لمقارنة عنصرين عند تحليل أداء البحث الثنائي أيضاً. في ما يخص الأعداد الصحيحة والسلاسل المحرفية، يزداد الوقت المطلوب خطياً مع زيادة طول ترميز العناصر، والذي يقاس عادةً بعدد البتات، على سبيل المثال، تتطلب مقارنة زوج من الأعداد الصحيحة دونَ إشارة التي يبلغ طولها 64 بتاً ضعف الوقت المطلوب لمقارنة زوج من الأعداد الصحيحة دونَ إشارة التي يبلغ طولها 32 بتاً. تحصل الحالة الأكثر سوءاً عندما يكون العددان الصحيحان اللذان تجري مقارنتهما متساويا القيمة. يكون لما سبق تأثير واضح عندما تكون أطوال ترميز العناصر كبيرة، مثل الأنواع الصحيحة الكبيرة أو السلاسل المحرفية الكبيرة، مما يجعل مقارنة العناصر مرتفعة الكلفة الزمنية. علاوة على ذلك، فعند مقارنة القيم التي تحتوي فاصلة متحركة، وهو التمثيل الرقمي الأكثر شيوعاً للأعداد الحقيقية، فإنَّ الكلفة الزمنية للمقارنة غالباً ما تكون أعلى من نظيرتها للأعداد الصحيحة أو السلاسل المحرفية القصيرة.
في معظم بنى الحاسوب، يحتوي المعالج ذاكرة تخزين مخبئية مُنفصلةً عن ذاكرة الوصول العشوائي. نظراً لوجود ذاكرة التخزين المخبئية داخل المعالج، فإنَّ الوصول إليها يكون سريعاً، ولكن حجمها يكون أصغر بكثير مقارنة بذاكرة الوصول العشوائي. لذلك، تقوم معظم المعالجات بتخزين مواقع الذاكرة التي جرى بلوغها إليها مؤخراً، إلى جانب مواقع الذاكرة القريبة منها. على سبيل المثال، عند الوصول إلى عنصر ما في مصفوفة، قد يُخزَّن العنصر نفسه في الذاكرة المخبئية إلى جانب العناصر المُخزنة بالقرب منه في ذاكرة الوصول العشوائي، مما يُسرِّع الوصول التتابعي إلى عناصر المصفوفة القريبة من ذلك الفهرس، وذلك بسبب محلية الإرجاع. في مصفوفة مرتبة، يمكن أن يقفز البحث الثنائي إلى مواقع الذاكرة البعيدة إذا كانت المصفوفة كبيرة، على عكس خوارزميات أخرى (مثل البحث الخطي والاستكشاف الخطي في جداول التجزئة) التي تصل إلى العناصر بالتسلسل. يضيف هذا قليلاً إلى وقت تشغيل البحث الثنائي عند استعمال البحث مع المصفوفات الكبيرة في معظم الأنظمة.[21]
مقارنة مع طرق بحث أخرى
إن استعمال المصفوفات المرتبة مع البحث الثنائي حلٌ غير فعال عندما تكون عمليات الإدراج والحذف في المصفوفة متداخلة مع الاسترجاع، ويستغرق ذلك زمناً هو لكل عملية من هذا القبيل. بالإضافة إلى ذلك، يمكن أن تؤدي المصفوفات التي المُرتَّبة إلى تعقيد استخدام الذاكرة خاصة عندما تحصل عملية إدراج العناصر في المصفوفة بشكل متكرر.[22] هناك بنى بيانات أخرى تدعم الإدراج والحذف بشكل أكثر كفاءة.

يمكن استخدام البحث الثنائي لإجراء تطابق تام وتعيين العضوية، أي تحديد فيما إذا كانت القيمة المستهدفة موجودة ضمن مجموعة من القيم. هناك بنى بيانات تدعم التطابق الدقيق وتعيين العضوية بصورة أسرع مقارنة مع البحث الثنائي. ومع ذلك، على عكس العديد من طرق البحث الأخرى، يمكن استخدام البحث الثنائي للتطابق التقريبي بصكلٍ فعال، وعادة ما تستغرق مثل هذه التطابقات زمناً هو بغض النظر عن نوع أو بنية القيم نفسها.[23] بالإضافة إلى ذلك، هناك بعض العمليات، مثل العثور على أصغر وأكبر عنصر في المصفوفة، والتي يمكن إجراؤها بكفاءة عالية في مصفوفة مرتبة.[11]

بحث خطي
البحث الخطي هو خوارزمية بحث بسيطة تتحقق من كل سجل حتى تجد القيمة المستهدفة. يُجرى البحث الخطي في قائمة مرتبطة، ما عمليات الإدخال والحذف بشكل أسرع من المصفوفة. البحث الثنائي أسرع من البحث الخطي في لمصفوفات المرتبة، إلا إذا كانت المصفوفة صغيرة. ولكن تطبيق البحث يحتاج إلى ترتيب المصفوفة أولاً،[24](5) وتتطلب جميع خوارزميات الترتيب المعتمدة على مقارنة العناصر، مثل الترتيب السريع والترتيب الدمجي، إنجاز مقارنات على الأقل في أسوأ الحالات.[25] على عكس البحث الخطي، يمكن استخدام البحث الثنائي لإنجاز تطابق تقريبي بصورة فعالة. ويمكن أيضاً القيام بعمليات، مثل العثور على أصغر وأكبر عنصر في المصفوفة، بكفاءة في مصفوفة مرتبة، ولكن ليس في مصفوفة غير مرتبة.[26]

الأشجار
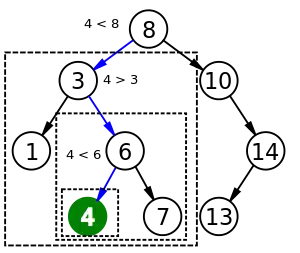
شجرة البحث الثنائية هي بنية بيانات شجرية تدعم مبدأ البحث الثنائي. تُنظَّم سجلات الشجرة بالترتيب، ويمكن البحث عن كل سجل فيها باستخدام خوارزمية مشابهة للبحث الثنائي، وتستغرق العملية متوسط الوقت اللوغاريتمي، وتتطلب عمليتا الإدراج والحذف في الأشجار الثنائية أيضاً متوسط الوقت اللوغاريتمي ذاته. يمكن أن تستغرق عمليات الإدخال والحذف في الأشجار الثنائية زمناً أقل من الزمن المستغرف لإنجاز هذه العمليات في المصفوفات المرتبة. بالإضافة لذلك، تحتفظ الأشجار الثنائية بالقدرة على تنفيذ جميع العمليات الممكنة على مصفوفة مرتبة، بما في ذلك استعلامات النطاق والاستعلامات التقريبية.[23][27]
عادةً ما يكون البحث الثنائي أكثر كفاءة من أشجار البحث الثنائية، والسبب في ذلك أن أشجار البحث الثنائي قد لا تكون متوازنة تماماً. ينطبق هذا أيضاً على أشجار البحث الثنائية المتوازنة وأشجار البحث الثنائية التي توازن بين عقدها، لأنها نادراً ما تنتج الشجرة ذات عدد أقل عدد ممكن من المستويات.(6) بصورة عامة، وباستثناء الأشجار التي توازن بين عقدها، تكون أشجار البحث الثنائية غير متوازنة وفيها بضعة عقد ذات عقدتين ابتنين، ويؤدي هذا إلى زيادة عدد المقارنات اللازمة لإنجاز البحث، ففي شجرة بحث ثنائية عدد عناصرها ، قد يبلغ متوسط عدد المقارنات وعدد المقارنات اللازم لإنجاز البحث في أسوء حالة مقارنة.بالإضافة لذلك، تحتاج أشجار البحث الثنائية إلى مساحة تخزين أكبر من المصفوفات المرتبة.[28]
تميل أشجار البحث الثنائية إلى إنجاز بحثٍ سريع في الذاكرة الخارجية المخزنة في الأقراص الصلبة، لأنَّ بالإمكان تنظيمها بكفاءة في أنظمة الملفات، وتُعمم شجرة بي هذه الطريقة في التنظيم. تُستخدَم أشجار بي بشكلٍ مُتكرر لتنظيم التخزين طويل الأمد مثل قواعد البيانات وأنظمة الملفات.[29][30]
تجزئة
جداول التجزئة هي بنية بيانات تَقرُن كل سجل بمفتاح فريد يُحسب باستخدام دلة التجزئة. عند تنفيذ المصفوفات الترابطية، تكون جداول التجزئة عموماً أسرع من البحث الثنائي في مصفوفة سجلات مرتبة.[31] تتطلب معظم تطبيقات جدول التجزئة زمناً ثابتاً مستهلكاً في المتوسط.[32](7) ومع ذلك، ليست التجزئة ذات فائدة لإيجاد التطابقات التقريبية، مثل حساب المفتاح التالي الأصغر التالي والمفتاح الأكبر التالي والمفتاح الأقرب، والمعلومة الوحيدة المستخلصة من بحثٍ فاشل هي أن القيمة المُستهدفة غير مقترنة مع أي سجل.[33] إنَّ البحث الثنائي مثاليٌ لمثل هذه التطابُقات، حيث ينجزها في وقت لوغاريتمي.[23]
خوارزميات تعيين العضوية
إن خوارزميات تعيين العضوية، هي مشكلة مرتبطة بعملية البحث، ويمكن استخدام أي خوارزمية بحث، مثل البحث الثنائي، من أجل تعيين العضوية أيضاً. هناك خوارزميات أخرى أكثر ملاءمة للعضوية المحددة، فمصفوفة البت مثلاً هي الأبسط والأكثر إفادة عندما يكون نطاق المفاتيح محدوداً، وهي تقوم بتخزين مجموعة من البتات المضغوط، حيث يمثل كل بت مفتاحاً واحداً في نطاق المفاتيح. هذه المصفوفات سريعة للغاية أيضاً، وتتطلب زمناً هو فقط.[34] يعالج النوع الأول من مصفوفة جودي مفاتيح بطول 64 بت بكفاءة.[35]

للحصول على نتائج تقريبية، تقوم مرشحات بلوم، وهي بنية بيانات احتمالية أخرى تستند إلى التجزئة، بتخزين مجموعة من المفاتيح عن طريق ترميزها باستخدام مصفوفة بت ودوال تجزئة متعددة. إنَّ مُرشِّحات بلوم أكثر فعالية من حيث المساحة مقارنة مع مصفوفات البت في معظم الحالات وليست أبطأ منها بكثير: حيث يستغرق إنجاز دالة تجزئة من أجل استعلامات العضوية زمناً هو فقط. ولكن مُرشِّحات بلوم تعاني من الأخطاء الإيجابية.[36](8)(9)


بنى بيانات أخرى
في بعض الحالات، تعطي بعض بنى البيانات مثل أشجار فان إيمد بواس، وأشجار الدمج، وأشجار تريس، ومصفوفات البت نتائج مُحسَّنة عند تطبيق البحث الثنائي أو العمليات الممكنة على المصفوفات المرتبة، مثل التطابقات التقريبية. والسبب في ذلك هو استفادة هذه البنى من خصائص محددة في المفاتيح، مثل صغر حجمها، فتعالجها بزمنٍ أصغر و تخزنها بمساحة أقل.[23] طالما يمكن الحصول على مفاتيح جاهزة، فإن تنفيذ هذه العمليات باستعمال البنى السابقة يكون أكثر كفاءةً من البحث الثنائي. تستخدم بعض البنى، مثل مصفوفات جودي، نهجاً مختلطاً للاستفادة من ميزات المفاتيح مع الحفاظ على الفعالية والقدرة على إنجاز التطابق التقريبي.[35]
اختلافات
البحث الثنائي المنتظم

يُخزِّن البحث الثنائي المنتظم الفرق بين فهرسي العنصر المتوسط في تكرارين متتابعين، بدلاً من الحدين الأسفل والأعلى، ويُحسب مسبقاً جدول بحث يضم هذه الفروق سلفاً. على سبيل المثال، إذا كانت المصفوفة المراد البحث فيها هي: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]، فإن العنصر المتوسط () سيكون 6. في هذه الحالة، يكون العنصر المتوسط من المصفوفة الفرعية اليسرى ([1, 2, 3, 4, 5]) هو 3 والعنصر المتوسط من المصفوفة الفرعية اليمنى ([7, 8, 9, 10, 11]) هو 9. سيُخزِّن البحث الثنائي المنتظم القيمة 3 حيث يبتعد كلا المؤشرين عن 6 بنفس المقدار.[37] لتقليل فضاء البحث، تضيف الخوارزمية التغيير السابق أو تطرحه من فهرس العنصر المتوسط. قد يكون البحث الثنائي الموحد أسرع في الأنظمة حيث يكون حساب نقطة المنتصف غير فعالٍ، مثل أجهزة الحاسوب العشرية.[38]
البحث الأسي

يوسِّع البحث الأسي البحث الثنائي ليشمل القوائم غير المحدودة. يبدأ البحث الأسي بالعثور على أول عنصر يكون مُؤَشِّره من مضاعفات العدد 2 وأكبر من القيمة المستهدفة. بعد ذلك، يُضبط هذا الفهرس ليكون حداً أعلى، ثمَّ يُطبَّق البحث الثنائي. يستغرق البحث تكراراً قبل بدء البحث الثنائي و تكراراً على الأكثر بعد بدء البحث الثنائي، حيث هو فهرس القيمة المستهدفة. يعمل البحث الأسي على القوائم المقيدة أيضاً، ولكنه يصبح تحسيناً للبحث الثنائي فقط في الحالة التي تكون فيها القيمة المستهدفة قريبة من بداية المصفوفة.[39]



البحث بالتقدير

يقوم البحث بالتقدير بتخمين موضع القيمة المستهدفة بدلاً من حساب نقطة المنتصف، مع مراعاة العنصرين الموجودين في الموقعين الأدنى والأعلى في المصفوفة بالإضافة إلى عدد العنصار فيها. يعمل البحث بالتقدير اعتماداً فكرة أن نقطة المنتصف ليست التخمين الأمثل في كثير من الحالات. على سبيل المثال، إذا كانت القيمة المستهدفة قريبة من قيمة العنصر ذو الترتيب الأعلى في المصفوفة، فمن المحتمل أن تكون موجودة بالقرب من نهاية المصفوفة.[40]
يمكن إنجاز البحث الخطي باستعمال البحث بالتقدير. إذاكانت مصفوفة حدها الأعلى هو وحدها الأدنى ، وكانت القيمة المُستهدفة هي ، فبالإمكان تقدير موقع الهدف حسب العلاقة: وهي حتماً قيمة تقع بين و. عند استخدام البحث الخطي، وإذا تم توزيع عناصر المصفوفة منتظم أو شبه منتظم، فإن البحث البحث بالتقدير يحتاج إلى مقارنة.[40][41][42]


عملياً، يكون البحث بالتقدير أبطأ من البحث الثنائي في المصفوفات الصغيرة، لأنه يتطلب إجراء حسابات إضافية. ينمو تعقيد الوقت في البحث بالتقدير بشكل أبطأ من نموه البحث الثنائي، ولكنه لا يكفي ليعوض الزمن اللازم لإجراء الحسابات الإضافية ما لم تكن المصفوفة كثيرة العناصر.[40]
التتالي الجزئي
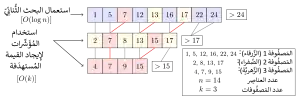
التتالي الجزئي هو تقنية تُسِّرع عمليات البحث الثنائية عن عنصر محدد في مصفوفات مرتبة متعددة. يتطلب البحث في كل مصفوقة على حدة زمناً هو ، حيث هو عدد المصفوفات. يختزل التتالي الجزئي هذا الزمن إلى من خلال تخزين معلومات محددة عن كل عنصر ومكانه في المصفوفات الأخرى.[43]


طُوِّر التتالي الجزئي في الأصل لحل العديد من مشكلات الهندسة الرياضية الحاسوبية بكفاءة، وطُبِّق لاحقاً في مجالات أخرى مثل استخراج البيانات والتوجيه في الإنترنت.[43]
التعميم على الرسوم البيانية
يُعمم البحث الثنائي من أجل الاستعمال مع أنواع محددة من الرسوم البيانية. إن أشجار البحث الثنائية هي إحدى هذه التعميمات، فعندما يُستعلم عن عقدة ما في الشجرة، تقوم الخوارزمية بتحديد العقدة حيث توجد القيمة المُستهدَفة، أو الشجرة الفرعية حيث توجد تلك العقدة. ويمكن أيضاً تعميم ما سبق على نحو أشمل كما سيأتي: من أجل رسم بياني ما غير موجَّهٍ ذي وزن إيجابي وعقدة ما مُستهدَفة فيه، فإنَّ استعلام الخوارزمية لعقدة ما في الرسم، إما أن يكشَف عن كونها مساوية للقيمة المُستهدَفة، أو يُحدد الوصلة التي تقود إلى أقصر مسار يصل بين العقدة المُستعلَمة والعقدة المُستهدفة. إن خوارزمية البحث الثنائي القياسية هي حالة بسيطة عن رسمٌ بياني وحيد المسار. بشكل مشابه، فإن أشجار البحث الثنائي هي الحالة التي تكون نتيجة استعلام عقدة لا تساوي قيمتها القيمة المُستهدفة هي شجرةٌ فرعية تقع إلى يمين العقدة المُستعملة أو إلى يسارها. أما فيما يخص الرسوم البيانية غير الموجَّهة ذات الأوزان الإيجابية، فإن هناك خوارزمية تُوجِد العقدة المُستهدَفة بعد استعلام في أسوأ الحالات.[44]
البحث الثنائي الضجيجي
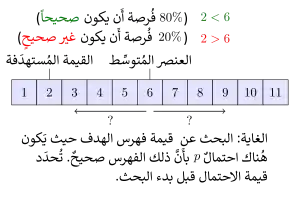
تقدم خوارزميات البحث الثنائي الضجيجية حلاً في الحالات التي لا يمكن فيها مقارنة عناصر المصفوفة بشكل موثوق. في هذه الحالات، ومن أجل كل زوج من العناصر، هناك احتمال أن تقوم الخوارزمية بإجراء مقارنة خاطئة. يمكن للبحث الثنائي الضجيجي أن يجد الموقع الصحيح للقيمة المُستهدَفة مع احتمال معين يتحكم في الوثوقية. يجب أن يقوم كل إجراء بحث ثنائي ضجيجي بعدد من المقارنات يبلغ مقارنة في المتوسط على الأقل، حيث هي دالة التحول الثنائي و هو احتمالية أن يعيدالإجراء موقعاً خاطئاً.[45]



يمكن اعتبار مشكلة البحث الثنائي الضجيجي حالة من لعبة ريناي وأولام،[46] وهي نوع متفرع من لعبة الأسئلة العشرين حيث يحتمل أن تكون الإجابات خاطئة.[47]
البحث الثنائي الكمي
تكون أجهزة الحاسوب التقليدية محدودة بالحالة الأكثر سوءاً التي تُنفِّذ تكراراً عند إجراء البحث الثنائي. لا تزال خوارزميات البحث الثنائي الكَميّ محدودة بالنسبة من أجل الاستعلامات، وه تمثل عدد التكرارات في الإجراء التقليدي، ولكن العامل الثابت ذو قيمة أقل من واحد، ما يؤمِّن تعقيداً زمنياً أقل في أجهزة الحواسيب الكمية.


يتطلب إجراء أي بحث ثنائي كمي دقيق، أي إجراء يعيد نتيجة صحيحة دائماً، تنفيذ استعلام على الأقل في الحالات الأكثر سوءاً، حيث هو اللوغاريتم الطبيعي.[48] هناك إجراء لبحث ثنائي كمي دقيق يُنفِّذ استعلاماً في أسوأ الحالات.[49] لغرض المقارنة، فإنَّ خوارزمية غروفر، وهي الخوارزمية الكمية المثلى للبحث في قائمة غير مرتبة من العناصر، تتطلب استعلاماً.[50]



نبذة تاريخية
تعود جذور فكرة ترتيب قائمة من العناصر للسماح بالبحث فيها بسرعة أكبر إلى العصور القديمة، وأقدم مثال معروف عن ذلك هو لوح إناكيبيت آنو من بابل الذي يعود إلى حوالي عام 200 قبل الميلاد. احتوى هذا اللوح حوالي 500 رقماً مكتوباً بنظام العد الستيني ومقابلاتها مرتبةً معجمياً، ما يُسهل البحث عن البنود. بالإضافة إلى ذلك، عُثر على العديد من قوائم الأسماء المرتبة حسب حرفها الأول في جزر بحر إيجة. وهناك أيضاً الكاثُولِيكون، وهو قاموس لاتيني أنجز عام 1286م، وكان أول عمل يصف قواعد ترتيب الكلمات أبجدياً، على عكس الأسلوب السابق الذي كان يقوم على ترتيب الأحرف الأولى فقط.[9]
في عام 1946م، أشار جون ماكلي للمرة الأولى إلى البحث الثنائي ضمن مجموعة محاضرات في مدرسة مور.[9] في عام 1957م، نشر ويليام ويزلي بيترسون الطريقة الأولى للبحث بالتقدير.[9][51] حتى عام 1960م، عملت جميع خوارزمية البحث الثنائي المنشورة على المصفوفات التي يكون طولها أقل من القيم الصحيحة مرفوعة لقوة اثنين فقط،(10) بعد ذلك نشر ديريك هنري ليمر خوارزمية بحث ثنائي عملت على المصفوفات جميعها.[52] في عام 1962م، قدم هيرمان بوتينبروش تنفيذ "الغول 60" لعملية البحث الثنائي الذي تضمن إجراء المقارنة للتحقق من مساواة العنصر للقيمة المُستهدفة في نهاية البحث، وسبّب هذا زيادةً في متوسط عدد التكرارات بمقدار واحد، ولكنه قلّل من عدد المقارنات لكل تكرار.[8] طوّر شاندرا من جامعة ستانفورد البحث الثنائي المنتظم عام 1971م.[9] في عام 1986م، قدّم برنارد شازيل وليونيداس جويباس التتابعي الجزئي بوصفه طريقة لحل العديد من مُشكلات البحث في الهندسة الحسابية.[43][53]
مشكلات التنفيذ
| على الرغم من أن الفكرة الأساسية للبحث الثنائي واضحة نسبيًا، إلا أن التفاصيل يمكن أن تكون صعبة بشكل مدهش | ||
عندما قدّم جون بنتلي البحث الثنائي كمسألة تتطلب حلاً في دورة للمبرمجين المحترفين، وجد أن 90% منهم قد فشلوا في توفير حل صحيح بعد عدة ساعات من العمل، ويرجع ذلك أساساً إلى التنفيذ غير السليم للخوارزمية والذي يُنتج فشلاً في التشغيل أو يُرجع قيماً خاطئة في حالات اختبار حدية نادرة.[54] تظهر دراسة نُشرت عام 1988م وشملت عشرين كتاباً عن البرمجة أن الشيفرة المصدرية الدقيقة لعملية البحث الثنائي موجودة فقط في خمسة منها.[55] بالإضافة إلى ذلك، فإن تنفيذ بنتلي الذاتي للبحث الثنائي، والذي نشره في كتابه الصادر عام 1986 بعنوان "جواهر البرمجة"، تضمَّن خطأ فيضٍ ظلَّ غير معروفٍ لأكثر من عشرين عاماً. وشمل تنفيذ مكتبة لغة البرمجة جافا الخاص بالبحث الثنائي خطأ الفيض نفسه لأكثر من تسع سنوات.[56]
في التنفيذ العملي للخوارزمية، غالباً ما تكون المتغيرات المستخدمة لتمثيل المؤشرات ذات حجم ثابت، وهذا قد يؤدي إلى حصول فيض حسابي عند التعامل مع المصفوفات ذات الأحجام بالغة الكبر. إذا حُسبت نقطة منتصف النطاق على أنها فإن قيمة قد تتجاوز نطاق الأعداد الصحيحة لنوع البيانات المستخدم لتخزين نقطة المنتصف، حتى لو كانت قيمتا و ضمن النطاق. إذا كانت قيمتا و غير سالبتين، يمكن تجنب ما سبق وحساب نقطة المنتصف باستعمال العلاقة .[57]


قد تحدث حلقة لا نهائية إذا لم يُعرَّف شروط الخروج من الحلقة بشكل صحيح. عندما تتجاوز قيمةُ قيمةَ ، يفشل البحث ويَلزم أن يُبلَّغ عن ذلك. بالإضافة إلى ذلك، يجب الخروج من الحلقة عند العثور على العنصر المُستهدَف، أمَّا في حالة التنفيذ حيث يُؤجَّل الفحص إلى النهاية، يجب التحقق من كون البحث ناجحاً أو فاشلاً في النهاية. وجد بنتلي أن معظم المبرمجين الذين نفذوا البحث الثنائي بشكل غير صحيح ارتكبوا خطأ ما في تحديد شروط الخروج.[9][58]
دعم المكتبة
تتضمن المكتبات المعيارية للعديد من لغات البرمجة إجراءات بحث ثنائية، منها على سبيل المثال:
- توفر لغة سي الدالة
()bsearchفي مكتبتها المعيارية، وهي دلة تُنفَّذ اعتماداً على البحث الثنائي، على الرغم من أن المعيار الرسمي لا يتطلب ذلك.[59] - توفر مكتبة النماذج القياسية في سي++ الدوال
()binary_searchو()lower_boundو()upper_boundو()equal_range.[60] - توفِّر مكتبة لغة دي القياسية المُسمَّاة فوبوس، في الوحدة
std.rangeنوعSortedRange(وهو يُرجع بواسطة الدوال()sortو()assumeSorted)، بالإضافة للدوال الأعضاء()containsو()equaleRangeو()equaleRangeو()lowerBoundو()trisect، التي تستخدم أيضاً تقنيات البحث الثنائي افتراضياً مع النطاقات التي توفر وصولاً عشوائياً.[61] - توفر كوبول فعل
SEARCH ALLلإجراء عمليات بحث ثنائية على جداول كوبول المرتبة.[62]
- تحتوي حزمة مكتبة غو القياسية للترتيب على دوال البحث
Search،SearchInts،SearchFloat64s، وSearchStrings، التي تُنفِّذ البحث الثنائي العام، وكذلك تطبيقات محددة للبحث في شرائح الأعداد الصحيحة وأرقام الفاصلة العشرية والسلاسل على التوالي.[63] - تقدِّم جافا مجموعة من الدوال الأعضاء التي تحمِّل الدالة
()binarySearchالثابتة بشكل زائد في أصنافالمصفوفاتوالمجموعاتفي حزمةjava.utilالقياسية لإجراء عمليات البحث الثنائية على مصفوفات جافا وعلى القوائمList، على التوالي.[64]
- تقدِّم مايكروسوفت دوت نت فريموورك إصدارات عامة ثابتة من خوارزمية البحث الثنائي في الأصناف الأساسية في مجموعتها. مثال على ذلك هو الدالة العضو
System.ArrayBinarySearch<T>(T[] array, T value).[65]
- بالنسبة إلى سي-الكائنية، يوفر إطار العمل المُسمَّى
NSArray -indexOfObject:inSortedRange:options:usingComparator:دالةً عضو في ماك أو إس إكس 10.6+.[66] يحتوي إطار عمل آبل فونديشين سي (بالإنجليزية: Apple Foundation C) الأساسي أيضاً على دالة()CFArrayBSearchValues.[67] - توفِّر بايثون وحدة
bisect.[68] - يتضمن صنف المصفوفة في روبي دالة عضو هي
bsearchتشمل على تطابق تقريبي.[69]
الهوامش
1. هذه الأسماء هي: (بالإنجليزية: Half-interval search, logarithmic search, and binary chop) على الترتيب.
2. المتحوِّلان هما الحرفان الأولان من كلمتي يسار (بالإنجليزية: Left) ويمين (بالإنجليزية: Right) على الترتيب.
3. يمكن تمثيل أي خوارزمية بحث تستند إلى المقارنات فقط باستخدام شجرة مقارنة ثنائية. المسار الداخلي هو أي مسار من الجذر إلى العقدة المدروسة. ليكن طول المسار الداخلي، أي مجموع أطوال جميع المسارات الداخلية. إذا كان من احتمال البحث عن كل العناصر متساوياً، فإن طول المسار الوسطي سيكون ، أو ببساطة واحد مضافاً إليه متوسط أطوال المسارات الداخلية في الشجرة كلها. وهذا صحيح لأن المسارات الداخلية تمثل العناصر التي تقارنها خوارزمية البحث مع الهدف. أمَّا أطوال هذه المسارات الداخلية فتُمثِّل عدد التكرارات بعد تجاوز العقدة الجذر. إن إضافة متوسط هذه الأطوال إلى تكرار واحد لازم لتجاوز العقدة الجذر يعطي طول المسار الوسطي. بناءً على ذلك، ولتقليل متوسط عدد المقارنات، يجب تصغير طول المسار الداخلي . لقد اتضح أن شجرة البحث الثنائي تقلل من طول المسار الداخلي، فقد أثبت دونالد نوث أن طول المسار الخارجي، أي طول المسار المار بجميع العقد التي تمتلك بالفعل ابنين، يَصغر عندما توجد العقد الخارجية، أي العقد التي لا أبناء لها، في مستويين متتاليين من الشجرة. ينطبق هذا أيضاً على المسارات الداخلية لأن طول المسار الداخلي مرتبط خطياً بطول المسار الخارجي . فيما يخص أي شجرة تضمُّ عقدة، فإن . عندما تحتوي كل الأشجار الفرعية على عدد متماثل من العقد، أو عندما تُقسَّم المصفوفة بالتساوي إلى نصفين بعد كل تكرار، فإنَّ العقد الخارجية وكذلك العقد الرئيسية الداخلية تقع داخل مستويين. ويترتب على ذلك أن البحث الثنائي يقلل من عدد المقارنات المتوسطة عندما يكون شجرة المقارنة أقل طول ممكن للمسار الداخلي.[14]




4. أظهر دونالد نوث على حاسوبه المُسمى ميكس (بالإنجليزية: MIX)، والذي صممه ليُمثِّل حاسوباً عادياً، أن متوسط وقت تشغيل هذا التنفيذ للبحث الناجح هو وحدة زمن مقارنةً مع وحدة زمن من أجل البحث الثنائي المنتظم. ينمو التعقيد الزمني لهذا التنفيذ بشكل أبطأ قليلاً، ولكن على حساب التعقيد الابتدائي المرتفع.[19]


5.أجرى دونالد نوث تحليلاً منهجياً لأداء الوقت لخوارزميتي البحث هاتين. في حاسوب ميكس، والذي صممه نوث لتمثيل حاسوب عادي، استغرق البحث الثنائي وسطياً وحدة زمنية من أجل بحث ناجح، بينما استغرق البحث الخطي مع عقدة رصد [الإنجليزية] في نهاية القائمة وحدة زمنية. للبحث الخطي تعقيد ابتدائي أقل لأنه يتطلب عميلات حسابية أقل، لكن تعقيده يتنمو ليتفوق بسرعة على البحث الثنائي. في حاسوب ميكس، يتفوق البحث الثنائي فقط على البحث الخطي باستخدام عقدة الرصد إذا كانت المتراجحة مُحققة.[14][70]



6. سيؤدي إدخال القيم وفق تتابع مُرتَّب أو في نمط المفتاح الأدنى والأعلى (بالإنجليزية: Lowest-highest key) إلى شجرة بحث ثنائية تزيد متوسط وقت البحث ووقت البحث في أسوأ الحالات.[71]
7. في بعض تطبيقات جدول التجزئة من الممكن إنجاز البحث خلال وقت ثابت مضمون.[72]
8. هذا لأن مجرد تعيين كل البتات التي تشير إليها وظائف التجزئة لمفتاح معين يمكن أن يؤثر في استعلامات المفاتيح الأخرى التي لها موقع تجزئة مشترك لواحدة أو أكثر من الوظائف.[73]
9. هناك تحسينات لمرشح بلوم تعمل على تحسين تعقيده أو تدعم الحذف، على سبيل المثال، يستعمل مرشحُ كوكو تجزئةَ كوكو من أجل اكتساب هذه الميزات.[73]
ملحق: مسرد المصطلحات الإنجليزية
مَسرد المفردات وفق الترتيب الأبجدي | |
الغول 60 |
Algol 60 |
وقت ثابت مستوفى |
Amortized constant time |
تطابق تقريبي |
Approximate match |
استعلام تقريبي |
Approximate query |
فيض حسابي |
Arithmetic overflow |
مصفوفة ترابطية |
Associative array |
شجرة بحث ثنائية متوازنة |
Balanced binary search tree |
تمثيل O الكبرى |
Big O notation |
قطع ثنائي |
Binary chop |
دالة التحول الثنائي |
Binary entropy function |
لوغاريتم ثنائي |
Binary logarithm |
بحث ثنائي |
Binary search |
شجرة بحث ثنائية |
Binary search tree |
طريقة التصنيف الثنائي |
Bisection method |
بت |
Bit |
مصفوفة بت |
Bit array |
مرشح بلوم |
Bloom filter |
قائمة محدودة |
Bounded list |
شجرة بي |
B-tree |
ذاكرة مخبئية |
Cache |
كاثوليكون |
Catholicon |
المتمم الصحيح الأعلى |
Ceiling |
دالة المتمم الصحيح الأعلى |
Ceiling function |
هندسة رياضية حاسوبية |
Computational geometry |
قيم دالة مستمرة |
Continuous function values |
استخراج البيانات |
Data mining |
بنية بيانات |
Data structure |
قاعدة بيانات |
Database |
حاسوب عشري |
Decimal computer |
حذف |
Deletion |
اشتقاق حالة متوسطة |
Derivation of average case |
حالة حدية |
Edge case |
تطابق تقريبي فعال |
Efficient approximate matching |
تطابق تام |
Exact matching |
بحث أسي |
Exponential search |
ذاكرة خارجية |
External memory |
إيجابيات مزيفة |
False positives |
نظام ملفات |
File system |
مصفوفة مرتبة منتهية العناصر |
Finite sorted array |
فاصلة متحركة |
Floating-point |
الجزء الصحيح لأي عدد صحيح |
Floor |
دالة الجزء الصحيح لأي عدد صحيح |
Floor function |
تتالي جزئي |
Fractional cascading |
شجرة الدمج |
Fusion trees |
التعميم على الرسوم البيانية |
Generalization to graphs |
خوارزمية غروفر |
Grover's algorithm |
البحث المحدد بفاصل المنتصف |
Half-Interval search |
قرص صلب |
Hard disk |
دالة تجزئة |
Hash function |
جدول تجزئة |
Hash table |
تجزئة |
Hashing |
جدول إناكيبيت آنو |
Inakibit-Anu tablet |
فهرس |
Index |
تكرار ابتدائي |
Initial iteration |
إدراج |
Insertion |
مسار داخلي |
Internal path |
بحث بالتقدير |
Interpolation search |
فاصل |
Interval |
إجراء تكراري |
Iterative procedure |
جافا |
Java |
مصفوفة جودي |
Judy array |
ترتيب معجمي |
Lexicographical order |
استيفاء خطي |
Linear interpolation |
سبر خطي |
Linear probing |
بحث خطي |
Linear search |
قائمة مرتبطة |
Linked list |
محلية المرجع |
Locality of reference |
بحث لوغاريتمي |
Logarithmic search |
وقت لوغاريتمي |
Logarithmic time |
جدول بحث |
Lookup table |
ترتيب دمجي |
Merge sort |
لوغاريتم طبيعي |
Natural logarithm |
الجار الأقرب |
Nearest neighbor |
بحث ثنائي ضجيجي |
Noisy binary search |
خطأ الفيض |
Overflow error |
مؤشر |
Pointer |
معالِج |
Processor |
شيفرة تقريبية |
Pseudocode |
خوارزمية كمومية |
Quantum algorithm |
بحث ثنائي كمومي |
Quantum binary search |
حواسيب كمومية |
Quantum computers |
حساب كمومي |
Quantum computing |
ترتيب سريع |
Quicksort |
ذاكرة الوصول العشوائي |
Random acess memory |
استعلام المجال |
Range query |
مرتبة |
Rank |
استعلام المرتبة |
Rank query
|
مقلوب عدد |
Reciprocals |
سجل |
Record |
لعبة ريناي وأولام |
Rényi-Ulam game |
إرجاع |
Return |
عقدة الجذر |
Root node |
خوارزمية بحث |
Search algorithm |
ضبط العضوية |
Set membership |
نظام عد ستيني |
Sexagesimal |
عقدة مفردة |
Single node |
مصفوفة مرتبة |
Sorted array |
خوارزمية ترتيب |
Sorting algorithm |
تعقيد الفضاء |
Space complexity |
اللاحق |
Successor |
سلسلة محرفية |
String |
بنية |
Structure |
دالة فرعية |
Subroutine |
قيمة مستهدفة / قيمة الهدف |
Target value |
تعقيد الزمن |
Time complexity |
شجرة |
Tree |
شجرة تري |
Tries |
رسم بياني غير موجه وموزون |
Undirected positively weighted graph |
بحث ثنائي منتظم |
Uniform binary search |
عدد صحيح بدون إشارة |
Unsigned integer |
شجرة فان إيمد بواس |
Van Emde Boas tree |
الحالة الأسوأ |
Worst case |

المراجع
- فهرس المراجع
- Louis F. Williams (أبريل 1976)، "A modification to the half-interval search (binary search) method"، Proceedings of the 14th annual Southeast regional conference، ACM، ص. 95–101، doi:10.1145/503561.503582، مؤرشف من الأصل في 2 يونيو 2020.
- Knuth 1998, Section: 6.2.1 ("Searching an ordered table"), subsection "Binary search"
- Butterfield & Ngondi 2016, p. 46.
- Cormen et al. 2009, p. 39.
- Eric Weisstein، "Binary Search"، mathworld (باللغة الإنجليزية)، مؤرشف من الأصل في 25 مايو 2020، اطلع عليه بتاريخ 4 يوليو 2020.
- Ivan Flores؛ George Madpis (1971)، "Average binary search length for dense ordered lists"، Communications of the ACM، Association for Computing Machinery، 14 (9): 602–603، doi:10.1145/362663.362752، ISSN 0001-0782، مؤرشف من الأصل في 2 يونيو 2020.
- Knuth 1998, Section:6.2.1:"Searching an ordered table", subsection:"Algorithm B".
- Bottenbruch, H. (1962)، "Structure and Use of ALGOL 60"، Journal of the ACM، Association for Computing Machinery ACM، 9 (2): 161–221، doi:10.1145/321119.321120، ISSN 0004-5411، مؤرشف من الأصل في 2 يونيو 2020.
- Knuth 1998, Section:6.2.1 "Searching an ordered table", subsection:"History and bibliography".
- Kasahara & Morishita 2006, pp. 8–9
- Sedgewick & Wayne 2011, Section:3.1, subsection:"Rank and selection".
- Goldman & Goldman 2008, pp. 461–463
- Sedgewick & Wayne 2011, Section:3.1, subsection:"Range queries".
- Knuth 1998, Section: 6.2.1 "Searching an ordered table", subsection: "Further analysis of binary search"
- Knuth 1998, Section: 6.2.1 "Searching an ordered table", subsection: "Theorem B"
- Chang 2003, p. 169.
- C. E. Shannon (1948)، "A mathematical theory of communication"، The Bell System Technical Journal، Nokia Bell Labs، 27 (3): 379–423، doi:10.1002/j.1538-7305.1948.tb01338.x، ISSN 0005-8580، مؤرشف من الأصل في 10 يوليو 2020.
- Knuth 1997, Section: 2.3.4.5 "Path length"
- Knuth 1998, section: 6.2.1 "Searching an ordered table", subsection "Exercise 23"
- Timothy J. Rolfe (1997)، "Analytic Derivation of Comparisons in Binary Search"، ACM SIGNUM Newsletter، Association for Computing Machinery ACM، 32 (4): 15–19، doi:10.1145/289251.289255، ISSN 0163-5778، مؤرشف من الأصل في 5 يوليو 2020.
- Paul-Virak Khuong؛ Pat Morin (2017)، "Array Layouts for Comparison-Based Searching"، ACM Journal of Experimental Algorithmics، Association for Computing Machinery ACM، 22 (1.3)، doi:10.1145/3053370، ISSN 1084-6654، مؤرشف من الأصل في 6 يوليو 2020.
- Knuth 1997, Subsection:2.2.2:"Sequential Allocation"
- Paul Beamea؛ Faith E.Fich (2002)، "Optimal Bounds for the Predecessor Problem and Related Problems"، Journal of Computer and System Sciences، Association for Computing Machinery ACM، 65 (1)، doi:10.1006/jcss.2002.1822، ISSN 0022-0000، مؤرشف من الأصل في 23 يوليو 2019.
- Knuth 1998, Section: 6.2.1 "Searching an ordered table".
- Knuth 1998, Section: 5.3.1 "Minimum-Comparison sorting".
- Sedgewick & Wayne 2011, Section: 3.2 "Ordered symbol tables".
- Sedgewick & Wayne 2011, Section: 3.2 "Binary Search Trees", subsection "Order-based methods and deletion".
- Sedgewick & Wayne 2011, Section: 3.5 "Applications", Subsection:"Which symbol-table implementation should I use?".
- Knuth 1998, Section:5.4.9 "Disks and Drums"
- Knuth 1998, Section:6.2.4 "Multiway trees"
- Knuth 1998, Sectiom: 6.4 "Hashing".
-
Martin Dietzfelbinger؛ Anna Karlin؛ Kurt Mehlhorn؛ Friedhelm Meyer auf der Heide؛ Hans Rohnert؛ Robert E. Tarjan (1994)، "Dynamic Perfect Hashing: Upper and Lower Bounds"، SIAM Journal on Computing، Society for Industrial and Applied Mathematics، 23 (4): 738–761، doi:10.1137/S0097539791194094، مؤرشف من الأصل في 6 يوليو 2020.
{{استشهاد بدورية محكمة}}: الوسيط غير المعروف|عدد المؤلفين=تم تجاهله (مساعدة) - Pat Morin، "Hash Tables" (PDF)، Computational geometry (باللغة الإنجليزية)، ص. 1، مؤرشف من الأصل (PDF) في 2 يونيو 2020، اطلع عليه بتاريخ 5 يوليو 2020.
- Knuth 2011, Section: 7.1.3 "Bitwise Tricks and Techniques".
- Alan Silverstein، "Judy IV Shop Manual" (PDF)، sourceforge (باللغة الإنجليزية)، ص. 80-81، مؤرشف من الأصل (PDF) في 2 يونيو 2020، اطلع عليه بتاريخ 5 يوليو 2020.
{{استشهاد ويب}}: النص "التاريخ 5 أغسطس 2002" تم تجاهله (مساعدة) - Burton H. Bloom (1970)، "Space/Time Trade-Offs in Hash Coding with Allowable Errors"، Communications of the ACM، Association for Computing Machinery ACM، 13 (7): 422–426، doi:10.1145/362686.362692، ISSN 0001-0782، مؤرشف من الأصل في 9 يونيو 2020.
- Knuth 1998, Section: 6.2.1 "Searching an ordered table", subsection: "An important variation".
- Knuth 1998, Section: 6.2.1 "Searching an ordered table", subsection: "Algorithm U".
- Moffat & Turpin 2002, p. 33.
- Knuth 1998, section: 6.2.1 "Searching an ordered table", subsection: "Interpolation search".
- Knuth 1998, section: 6.2.1 "Searching an ordered table", subsection: "Exercise 22".
- Yehoshua Perl؛ Alon Itai؛ Haim Avni (1978)، "Interpolation Search—a Log LogN Search"، Communications of the ACM، Association for Computing Machinery ACM، 21 (7): 550–553، doi:10.1145/359545.359557، ISSN 0001-0782، مؤرشف من الأصل في 5 يوليو 2020.
- Bernard Chazelle؛ Ding Liu (2001)، Lower bounds for intersection searching and fractional cascading in higher dimension، The Thirty-Third Annual ACM Symposium on Theory of Computing، Association for Computing Machinery ACM، ص. 322–329، doi:10.1145/380752.380818، ISBN 1581133499، مؤرشف من الأصل في 2 يونيو 2020.
- Ehsan Emamjomeh-Zadeh؛ David Kempe؛ Vikrant Singhal (2016)، Deterministic and Probabilistic Binary Search in Graphs، The forty-eighth annual ACM symposium on Theory of Computing، Association for Computing Machinery ACM، ص. 519–532، doi:10.1145/2897518.2897656، ISBN 9781450341325، مؤرشف من الأصل في 6 يوليو 2020.
-
- Michael Ben-Or؛ Avinatan Hassidim (2008)، The Bayesian Learner is Optimal for Noisy Binary Search (and Pretty Good for Quantum as Well)، 49th Annual IEEE Symposium on Foundations of Computer Science، The Institute of Electrical and Electronics Engineers IEEE، ص. 221–230، doi:10.1109/FOCS.2008.58، ISBN 978-0-7695-3436-7، ISSN 0272-5428، مؤرشف من الأصل في 01 أغسطس 2020.
- Andrzej Pelc (1989)، "Searching with known error probability"، Theoretical Computer Science، Elsevier، 63 (2): 185–202، doi:10.1016/0304-3975(89)90077-7، ISSN 0304-3975، مؤرشف من الأصل في 01 أغسطس 2020.
- R. L. Rivest؛ A. R. Meyer؛ D. J Kleitman (1978)، Coping with Errors in Binary Search Procedures (Preliminary Report)، The Tenth Annual ACM Symposium on Theory of Computing، Association for Computing Machinery ACM، ص. 227–232، doi:10.1145/800133.804351، ISBN 9781450374378، ISSN 0272-5428، مؤرشف من الأصل في 5 يوليو 2020.
- Andrzej Pelc (2002)، "Searching games with errors—fifty years of coping with liars"، Theoretical Computer Science، Elsevier، 270 (1): 71–109، doi:10.1016/S0304-3975(01)00303-6، ISSN 0304-3975، مؤرشف من الأصل في 23 يوليو 2019.
- Alfréd Rényi (1961)، "On a problem in information theory"، Magyar Tud. Akad. Mat. Kutató Int. Közl.، 6: 505–516، مؤرشف من الأصل في 5 يوليو 2020.
- Peter Høyer؛ Jan Neerbek؛ Yaoyun Shi (2002)، "Quantum complexities of ordered searching, sorting, and element distinctness"، Algorithmica، Springer، 34 (4): 429–448، doi:10.1007/s00453-002-0976-3، مؤرشف من الأصل في 5 يوليو 2020.
- Andrew M. Childs؛ Andrew J. Landahl؛ Pablo A. Parrilo (2007)، "Quantum algorithms for the ordered search problem via semidefinite programming"، PHYSICAL REVIEW A، APS Physics، 75 (3): 032335، doi:10.1103/PhysRevA.75.032335، ISSN 2469-9934، مؤرشف من الأصل في 2 يونيو 2018.
- Lov K.Grover (1996)، A Fast Quantum Mechanical Algorithm for Database Search، The twenty-eighth annual ACM symposium on Theory of Computing، Association for Computing Machinery ACM، ص. 212–219، doi:10.1145/237814.237866، ISBN 0897917855، مؤرشف من الأصل في 25 يونيو 2020.
- W. W. Peterson (1957)، "Addressing for Random-Access Storage"، IBM Journal of Research and Development، IBM، 1 (2): 130–146، doi:10.1147/rd.12.0130، مؤرشف من الأصل في 6 يوليو 2020.
- Richard Bellman؛ Marshall Hall Jr. (1960)، Teaching combinatorial tricks to a computer، Symposia in Applied Mathematics، American Mathematical Society AMS، ج. 10، ص. 180–181، doi:10.1090/psapm/010، ISBN 978-0-8218-1310-2، مؤرشف من الأصل في 8 يوليو 2020.
-
- Bernard Chazelle؛ Leonidas J. Guibas (1986)، "Fractional cascading: I. A data structuring technique"، Algorithmica، Springer، 1: 133–162، doi:10.1007/BF01840440، مؤرشف من الأصل في 07 أغسطس 2020.
- Bernard Chazelle؛ Leonidas J. Guibas (1986)، "Fractional cascading: II. Applications"، Algorithmica، Springer، 1: 163–191، doi:10.1007/BF01840441، مؤرشف من الأصل في 6 يوليو 2020.
- Bentley 2000, Section: 4.1 "The Challenge of Binary Search".
-
Textbook errors in binary searching، The nineteenth SIGCSE technical symposium on Computer science education (باللغة الإنجليزية)، Association for Computing Machinery ACM، 1988، ص. 190–194، doi:10.1145/52964.53012، ISBN 089791256X، مؤرشف من الأصل في 6 يوليو 2020.
{{استشهاد بمنشورات مؤتمر}}: النص "المؤلف1 Richard E.Pattis" تم تجاهله (مساعدة) - Joshua Bloch (2 يونيو 2006)، "Extra, Extra - Read All About It: Nearly All Binary Searches and Mergesorts are Broken"، Google AI Blog، مؤرشف من الأصل في 1 أبريل 2016، اطلع عليه بتاريخ 6 يوليو 2020.
{{استشهاد ويب}}: النص "اللغة en" تم تجاهله (مساعدة) - Salvatore Ruggieri (2003)، "On computing the semi-sum of two integers"، Information Processing Letters، Elsevier، 87 (2): 67–71، doi:10.1016/S0020-0190(03)00263-1، ISSN 0020-0190، مؤرشف من الأصل في 6 يوليو 2020.
- Bentley 2000, Section: 4.4 "Principles".
- "bsearch - binary search a sorted table"، opengroup.org (باللغة الإنجليزية)، مؤرشف من الأصل في 21 مارس 2016، اطلع عليه بتاريخ 6 يوليو 2020.
- Stroustrup 2013, p. 945.
- "std.range"، dlang.org (باللغة الإنجليزية)، مؤرشف من الأصل في 27 نوفمبر 2018، اطلع عليه بتاريخ 6 يوليو 2020.
- "COBOL ANSI-85, Programming Reference Manual, Volume 1: Basic Implementation" (PDF)، unisys (باللغة الإنجليزية)، أبريل 2015، ص. 8-6، مؤرشف من الأصل (PDF) في 25 يناير 2020، اطلع عليه بتاريخ 6 يوليو 2020.
- "Package sort"، golang (باللغة الإنجليزية)، أبريل 2015، مؤرشف من الأصل في 26 أبريل 2020، اطلع عليه بتاريخ 6 يوليو 2020.
-
- "Class Arrays"، Oracle (باللغة الإنجليزية)، مؤرشف من الأصل في 14 يونيو 2020، اطلع عليه بتاريخ 6 يوليو 2020.
- "Class Collections"، Oracle (باللغة الإنجليزية)، مؤرشف من الأصل في 14 يونيو 2020، اطلع عليه بتاريخ 6 يوليو 2020.
- "List<T>.BinarySearch Method"، microsoft (باللغة الإنجليزية)، مؤرشف من الأصل في 7 مايو 2016، اطلع عليه بتاريخ 6 يوليو 2020.
- "NSArray"، apple (باللغة الإنجليزية)، مؤرشف من الأصل في 11 مارس 2016، اطلع عليه بتاريخ 6 يوليو 2020.
- "CFArray"، apple (باللغة الإنجليزية)، مؤرشف من الأصل في 20 أبريل 2016، اطلع عليه بتاريخ 6 يوليو 2020.
- "8.6. bisect — Array bisection algorithm"، python (باللغة الإنجليزية)، مؤرشف من الأصل في 25 مارس 2018، اطلع عليه بتاريخ 6 يوليو 2020.
- Fitzgerald 2015, p. 152
- Knuth 1998, Answers to Exercises (Section: 6.2.1) for "Exercise 5".
- Knuth 1998, Subsection: 6.2.2:"Binary tree searching", subsection "But what about the worst case?".
- Knuth 1998, Section: 6.4 "Hashing", subsection "History".
-
Bin Fan؛ David G Andersen؛ Michael Kaminsky (2014)، "Cuckoo Filter: Practically Better Than Bloom"، The 10th ACM International on Conference on emerging Networking Experiments and Technologies، New York, NY, USA: Association for Computing Machinery ACM، doi:10.1145/2674005.2674994، ISBN 9781450332798، مؤرشف من الأصل في 7 يوليو 2020.
{{استشهاد بمنشورات مؤتمر}}: النص "الصفحات 75–88" تم تجاهله (مساعدة) - "A000225"، The OEIS Foundation. (باللغة الإنجليزية)، مؤرشف من الأصل في 8 يونيو 2016، اطلع عليه بتاريخ 7 يوليو 2020.
- المعلومات الكاملة للمراجع (مرتبة حسب سنة الإصدار)
- Donald Knuth (1997)، Fundamental algorithms. The Art of Computer Programming (باللغة الإنجليزية) (ط. الثالثة)، Wesley Professional، ISBN 978-0-201-89683-1.
- Donald Knuth (1998)، Sorting and searching. The Art of Computer Programming (باللغة الإنجليزية) (ط. الثانية)، Wesley Professional، ISBN 978-0-201-89685-5.
- Jon Bentley (2000)، Programming pearls (باللغة الإنجليزية) (ط. الثانية)، Addison-Wesley، ISBN 978-0-201-65788-3.
- Alistair Moffat؛ Andrew Turpin (2002)، Compression and coding algorithms (باللغة الإنجليزية)، Addison-Wesley Professional، doi:10.1007/978-1-4615-0935-6، ISBN 978-0-7923-7668-2.
- Shi-Kuo Chang (2003)، Data structures and algorithms. Software Engineering and Knowledge Engineering (باللغة الإنجليزية)، World Scientific، ISBN 978-981-238-348-8.
- Masahiro Kasahara؛ Shinichi Morishita (2006)، Large-scale genome sequence processing (باللغة الإنجليزية)، Imperial College Press، ISBN 978-1-86094-635-6.
- Sally A. Goldman؛ Kenneth J. Goldman (2008)، A practical guide to data structures and algorithms using Java (باللغة الإنجليزية)، CRC Press، ISBN 978-1-58488-455-2.
- Donald Knuth (2011)، Combinatorial algorithms. The Art of Computer Programming (باللغة الإنجليزية)، Addison-Wesley Professional، ISBN 978-0-201-03804-0.
- Robert Sedgewick؛ Kevin Wayne (2011)، Algorithms (باللغة الإنجليزية) (ط. الرابعة)، Addison-Wesley Professional، ISBN 978-0-321-57351-3.
- Bjarne Stroustrup (2013)، The C++ programming language (باللغة الإنجليزية) (ط. الرابعة)، Addison-Wesley Professional، ISBN 978-0-321-56384-2.
- Michael Fitzgerald (2015)، Ruby pocket reference (باللغة الإنجليزية)، O'Reilly Media، ISBN 978-1-4919-2601-7.
- Butterfield, Andrew؛ Ngondi, Gerard E. (2016)، A dictionary of computer science (باللغة الإنجليزية) (ط. السابعة)، Oxford University Press، ISBN 9780199688975.
- Thomas H., Cormen؛ Leiserson, Rivest؛ Ronald L., Gerard E.؛ Stein, Clifford (2016)، Introduction to algorithms (باللغة الإنجليزية) (ط. الثالثة)، MIT Press and McGraw-Hill، ISBN 978-0-262-03384-8.
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات