مجزئ يسار يمين
مجزئ يسار يمين في علوم الحاسب الآلي، هو مجزئ يقرأ الإدخال من اليسار إلى اليمين (كما ستظهر في العرض المرئي)، وتنتج استخلاص أقصى اليمين. مصطلح LR(k) parser يستخدم أيضاً ؛ حيث K تشير إلى عدد الغير مستهلك "look ahead" رموز المدخلات التي تستخدم في صنع القرارات التحليل. عادة ما تكون K هي 1 والعبارة LR parser عادة ما تستخدم للإشارة إلى هذه الحالة.
القواعد اللغوية لكثير من لغات البرمجة يمكن تحديدها بقواعد هي LR(1) أو ما يقارب ذلك،، ولهذا السبب LR parsers غالبا ما تستخدم من قبل برامج المترجم لإجراء تحليل القواعد اللغوية من شفرة المصدرsource code.
LR parser يمكن إنشاءه من قواعد السياق الحر context-free grammar من خلال برنامج يسمى parser generator (مولد المحلل) أو مكتوب بخط اليد من قبل المبرمج. قواعد السياق الحر context-free grammar يصنف كـ LR(k) إذا كان هناك محلل LR(k) له، على النحو الذي يحدده مولد المحلل parser generator.
ويقال أن LR parser لإجراء تحليل من أسفل إلى أعلى لأنه يحاول أستخلاص إنتاجات أعلى مستوى نحوي عن طريق البناء من الأوراق.
قواعد السياق الحر الحتمية deterministic context-free language هي لغة يوجد بها بعض قراعد LR(k) كل قواعد LR(k) k > 1 يمكن أن تحول ميكانيكيا إلى قواعد LR(1) لنفس اللغة، في حين أن قواعد LR(0) لنفس اللغة قد لا تكون موجودة، لغات LR(0) هي مجموعة فرعية مناسبة من تلك الحتمية.
LR parser مبنى على خوارزمية (أو لوغرتمية) التي يقودها جدول محلل parser table، تركيبة البيانات التي تحتوي على قواعد لغة الكمبيوتر التي يتم تحليلها. حتى المصطلح LR parser في الواقع يشير لفئة من المحلل التي يمكن أن تقوم بمعالجة تقريباً أي لغة برمجة، ما دام جدول المحلل متوفر للغة البرمجة. يتم إنشاء جدول المحلل بواسطة برنامج يسمى مولد المحلل parser generator.
LR parsing يمكن تعميمها كلغة سياق حر تعسفية تحلل بدون عقوبة للتشغيل، حتى لقواعد LR(k). هذا لان معظم لغات البرمجة يمكن التعبير عنها بقواعدLR(k). حيث أن K وثابت صغير (عادة يكون1). علما بأن تحليل القواعد الغير LR(k) هو أمر ضخم أبطأ (المكعب بدلا من التربيعي بالنسبة لطول الإدخال).
LR parsing يمكن أن تتعامل مع أكبر مجموعة من اللغات من LL parsing، وهي أيضا أفضل في التقرير عن الخطأ، أي أنه يكشف الأخطاء النحوية عندما لاتتفق المدخل مع القواعد في أقرب وقت ممكن. هذا على النقيض مع LL(k) (أو أسوأ من ذلك، محلل LL(*) parser) والتي قد تؤجل الكشف عن الخطأ إلى فرع مختلفة من القواعد بسبب التراجع، مما يؤدى الي صعوبة تحديد موقع الخطأ عبر المفارق في البادئات المشتركة الطويلة.
LR parsers صعب إنتاجها باليد، وعادة ما تنتج بمولد المحلل أو مترجم-مترجمcompiler-compiler. اعتمادا على كيفية إنشاء جدول التحليل، هذه المحللات يمكن أن تسمى محللات LR بسيطة simple LR parsers (SLR)، محللات LR النظر إلى الامام look-ahead LR parsers (LALR),، أو محللات LR المقننة canonical LR parsers. محللات LALR لديها قوة أعتراف لغوي بها أكثر من SLR. بينما المحللات LR المقننة canonical LR parsers لديها قوة أعتراف بها أكثر من LALR.
هندسة بناء محللات LR parsers
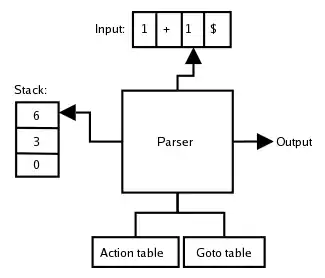
الشكل رقم 1. هندسة بناء محلل الجدول من أسفل إلى أعلى. من الناحية النظرية، LR Parser هو برنامج تكراري الذي يمكن أن يثبت صحته بحساب مباشر، ويمكن تنفيذه بشكل أكثر كفاءة (في الوقت المحدد) كمحلل تكراري تصاعدي recursive ascent parser، مجموعة من الوظائف المتبادلة المتكررة لكل قاعدة، تشبه كثيراً المحلل التكراري التنازلي recursive descent parser تقليدي، ومع ذلك، LR Parser يتم تقديمه وتنفيذه كآلات تخزين مكدسة مستندة على جدول، حيث مكدس الاستدعاءات call stack لمصدر البرنامج التكراري يقوم بالتلاعب بشكل صريح.
محلل الجدول المدفوع من الأسفل إلى الأعلى يمكن عرضه بشكل مبسط كما في الشكل 1 رقم. وفيما يلي وصف الاستخلاص أقصى اليمين من هذا المحلل.
الحالة العامة
المحلل هو آلة الحال وهو يتألف من : • مخزن مؤقت للمدخلات • المكدس حيث يتم تخزين قائمة من الأحوال التي كانت عليها • جدول الأنتقال الذي يحدد المكان الذي تنتقل اليه الحالة الجديدة • جدول الإجراءات الذي يعطي حكم القواعد لتطبيق المأخوذ من الحالة الراهنة والطرفية الحالية في تدفق المدخلات • مجموعة قواعد CFL
في حين LR parser يقرأ الإدخال من اليسار إلى اليمين لكنه يحتاج إلى إنتاج استخلاص أقصى اليمين، فإنه يستخدم التخفيضات، بدلا من الاشتقاقات لعملية الإدخال. وهذا هو، العمل الخوارزمي (اللوغارتمي) يعمل عن طريق خلق "التخفيض أقصى اليسار" من المدخلات. النتيجة النهائية، عندما تعكس، سيتم اشتقاق أقصى اليمين.
خوارزمية (لوغرتمية) محلل LR parsing تعمل كما يلي :
1. المكدس يبدأ من [0]. الحالة الراهنة سوف تكون دائما الحالة التي تقع في أعلى المكدس.
2. نظرا للحالة الراهنة والطرفية الطرفية الحالية في تدفق المدخلات إجراء يتم البحث عنه في جدول الإجراءات. وهناك أربع حالات : o a shift sn)إزاحة (sn:
- الطرفية الحالية تم إزالتها من تدفق الإدخال
- الحالة n تدفع إلى المكدس وتصبح الوضع الحالي
تخفيض a reduce rm :
- العدد m هو مكتوب إلى تدفق المخرجات
- لكل رمز في الجانب الأيمن من القاعدة m يتم إزالة حالة من المكدس (أي إذا كان الجانب الأيمن من القاعدة m تتكون من 3 رموز، 3 حالات فوقية يتم إزالتها من المكدس)
- إعطاء الحالة التي كانت فوقية في المكدس والجانب الايسر من القاعدة m يتم البحث عن حالة جديدة في جدول الأنتقال وتحقق الحالة الجديدة الحالية بدفعها داخل المكدس.
o an accept: تم قبول السلسلة o no action: تم عمل تقرير عن الخطأ في قواعد اللغة
3. الخطوة 2 يتم تكرارها حتى إما يتم قبول السلسلة أو عمل تقرير للخطأ في قواعد اللغة.
مثال البناء
انتبه ان الحالة العامة التي يجب أن تكون في المكدس هي(رقم، رمز، رقم).
لتفسير كيف يعمل، سوف نستخدم القواعد التالية الصغيرة التي تبدأ بالرمز |E : (1) E → E * B (2) E → E + B (3) E → B (4) B → 0 (5) B → 1
وتحليل المدخلات التالية : 1 + 1
العمل Action وجدول الأنتقال goto tables
جدولين التحليل LR(0) parsing لهذه القاعدة تبدو على النحو التالي :
| state | action' | goto | |||||
| * | + | 0 | 1 | $ | E | B | |
| 0 | s1 | s2 | 3 | 4 | |||
| 1 | r4 | r4 | r4 | r4 | r4 | ||
| 2 | r5 | r5 | r5 | r5 | r5 | ||
| 3 | s5 | s6 | acc | ||||
| 4 | r3 | r3 | r3 | r3 | r3 | ||
| 5 | s1 | s2 | 7 | ||||
| 6 | s1 | s2 | 8 | ||||
| 7 | r1 | r1 | r1 | r1 | r1 | ||
| 8 | r2 | r2 | r2 | r2 | r2 | ||
تتم فهرسة جدول الإجراءات من جانب حالة المحلل ومحطة طرفية (بما في ذلك طرفية خاصة $ التي تشير إلى نهاية تدفق المدخلات) وتحتوي على ثلاثة أنواع من الأعمال :
• shift,، التي تكتب 'sn' وتشير إلى أن الحالة القادمة هي n
• reduce، التي تكتب 'rm' وتشير إلى أنه ينبغي إجراء تخفيض في القاعدة النحوية m
• accept، والتي تكتب 'acc' وتشير إلى أن المحلل يقبل السلسلة في تدفق الإدخال.
يتم فهرسة جدول الانتقال إلى حالة من المحلل اللغوي والغير طرفية ويشير ببساطة إلى ماهية الحالة القادمة للمحلل التي ستتم إذا تم الاعتراف بمحطة غير طرفية معينة. هذا الجدول مهم لمعرفة كل حالة مقبلة بعد كل تخفيض. بعد التخفيض، يتم العثور على الحالة المقبلة من خلال النظر في مدخلات جدول الانتقال لأعلى المكدس (أي الحالة الحالية)، والقواد المخفضة LHS (أي غير الطرفية).
إجراءات التحليل
الجدول أدناه يوضح كل خطوة في هذه العملية. الحالة هنا تشير إلى البند في الجزء العلوي من المكدس (البند أقصى اليمين)، ويتم تحديد الإجراء التالي من خلال الإشارة إلى جدول الإجراءات أعلاه. لاحظ أيضا أن يتم إلحاق $ لسلسلة الإدخال للدلالة على نهاية التدفق.
| State | Input Stream | Output Stream | Stack | Next Action |
|---|---|---|---|---|
| 0 | 1+1$ | [0] | Shift 2 | |
| 2 | +1$ | [0,2] | Reduce 5 | |
| 4 | +1$ | 5 | [0,4] | Reduce 3 |
| 3 | +1$ | 5,3 | [0,3] | Shift 6 |
| 6 | 1$ | 5,3 | [0,3,6] | Shift 2 |
| 2 | $ | 5,3 | [0,3,6,2] | Reduce 5 |
| 8 | $ | 5,3,5 | [0,3,6,8] | Reduce 2 |
| 3 | $ | 5,3,5,2 | [0,3] | Accept |
تجول
محلل يبدأ مع المكدس تحتوي فقط على الحالة الأولي ('0') : [0]
الرمز الأول من سلسلة الإدخال التي يراها المحلل اللغوي هو '1'. من أجل معرفة ما الإجراء القادم هو العمل (shift إزاحة، reduceتخفيض, acceptقبول أو errorخطأ)، تتم فهرسة جدول الإجراءات مع الحالة الحالية (نتذكر أن "الحالة الراهنة" ليست سوى كل ما هو على أعلى المكدس)، والتي في هذه الحالة هو 0، ورمز الإدخال الحالي، وهو '1'. جدول الإجراءات يحدد التحول shift إلى الحالة 2، وهكذا تدفع الحالة 2 فوق المكدس (مرة أخرى، تذكر أن كل معلومات الحالة توجد في المكدس، لذلك "التحول إلى الحالة 2" هو نفس دفع 2 على المكدس). ينجم عن ذلك مكدس [0 '1' 2]
حيث الجزء العلوي من المكدس هة الحالة 2. من أجل التفسير نظهر أيضا الرمز (على سبيل المثال '1', B) التي تسببت الانتقال إلى الحالة القادمة، وعلى الرغم من ذلك بالمعنى الدقيق أنها ليست جزءا من المكدس.
في الحالة (2) جدول الإجراءات يقول انه بغض النظر عما هو طرفي نراه على تدفق المدخلات، ينبغي أ نخفض مع القاعدة اللغوية 5. إذا كان الجدول صحيح، هذا يعني أن المحلل قد تعرف على الجانب الأيمن من القاعدة 5، والتي في الواقع هي الحالة. في هذه الحالة نكتب 5 إلى تدفق المخرجات، ادفع حالة واحدة من المكدس (حيث الجانب الأيمن من القاعدة لديه رمز واحد)، وادفع على المكدس الحالة من الخلية في جدول الانتقال للحالة 0 و B، أي الحالة 4. ينجم عن ذلك المكدس: [0 B 4]
مع ذلك، في الحالة 4 جدول الإجراءات يقول إنه يجب علينا القيام بتخفيض للمادة 3. حتى نكتب 3 إلى تدفق الإخراج، ادفع حالة واحدة من المكدس، وابحث عن الحالة الجديدة في جدول الانتقال للحالة 0 وE، وهي الحالة 3. الناتج المكدس : [0 E 3]
الطرفية التالية التي يراها المحلل هي '+' ووفقا لجدول الإجراءات يجب أن تذهب بعد ذلك إلى الحالة (6) : [0 E 3 '+' 6]
لاحظ أن الناتج مكدس يمكن أن يفسرعلى أنه تاريخ حالة محدودة أوتوماتيكيا التي قرأت E الغير طرفية يليها '+' الطرفية. يتم تعريف جدول الانتقال لهذه الألية عن طريق إجراءات التحول shift actions في جدول الإجراءات والانتقالات في جدول الانتقالات.
الطرفية التالية هي الآن '1' وهذا يعني أن علينا إجراء التحول shift والانتقال إلى الحالة 2 : [0 E 3 '+' 6 '1' 2]
مثلما جاء في لاسابق '1' وهذه تخفض إلى B لإعطاء المكدس التالي : [0 E 3 '+' 6 B 8]
لاحظ مرة أخرى أن المكدس يتوافق مع قائمة الحالات الأوتوكاتيكية المحدودة التي قرأت E الغير طرفية، تليها '+' وثم B الغير طرفية. في الحالة 8 نقوم دائما بخفض للمادة 2. لاحظ أن أعلى 3 حالات على مكدس تتوافق مع الرموز الثلاثة في الجانب الأيمن من المادة 2. [0 E 3]
وأخيرا، نقرأ '
بناء جداول التحليل LR(0)
البنود
بناء جداول التحليل هذه قائم على مفهوم بنود LR(0) (وتسمى ببساطة البنود هنا) التي هي القواعد اللغوية الخاصة مع نقطة مميزة تضاف في مكان ما في الجانب الأيمن. على سبيل المثال القاعدة E → E + B لديها الأربعة بنود المقابلة التالية : E → • E + B E → E • + B E → E + • B E → E + B •
قواعد الشكل الذي ε →A لديها فقط بند واحد A → •. البند E → E • + B، على سبيل المثال، يشير إلى أن المحلل تعرف على السلسلة المقابلة لـE على تدفق المدخلات ويتوقع الآن أن تقرأ '+' متبوعة بسلسلة أخرى المقابلة لـ B
مجموعات البنود
عادة ليس من الممكن وصف حالة المحلل ذا البند الواحد لأنه قد لا يعرف مقدما أية قاعدة سوف يستخدمها للتخفيض. على سبيل المثال إذا كان هناك أيضا قاعدة E → E * B إذاً البنود E → E • + B و E → E • * B سوف تطبق على حد سواء بعد قراءة سلسلة مقابلة لـ E. ولذلك فإننا سوف نوصف حالة المحلل بمجموعة بنود، في هذه الحالة المجموعة { E → E • + B, E → E • * B }
تمديد مجموعة البند عن طريق التوسع في اللا طرفيات
بند مع نقطة قبل محطة غير طرفية، مثل E → E + • B، يشير إلى أن المحلل يتوقع أن تحليل B اللا طرفية بعد ذلك. لضمان ان مجموعة البند تتضمن كافة القواعد الممكنة حيث المحلل قد يكون في وسط التحليل، يجب أن تشمل جميع البنود التي تصف كيف B نفسها سيتم تحليلها. وهذا يعني أنه إذا كانت هناك قواعد مثل B → 1 و B → 0 حينها مجموعة البند يجب أن يتضمن أيضا البنود B → 1 و B → 0. وبصفة عامة هذا يمكن أن يصاغ هذه على النحو التالي :
إذا كان هناك بند من النموذج A → v • Bw في مجموعة بند وفي القواعد هناك قاعدة B → w' حينها البند B → • w' ينبغي أيضا أن يكون في مجموعة البند.
اختتام مجموعات البند
وهكذا، يمكن تمديد أي مجموعة من البنود بشكل متكرر عن طريق إضافة كافة البنود المناسبة حتى تكون كل المحطات اللا طرفية تسبقها نقاط يتم احتسابها. ويطلق على الحد الأدنى من التمديد اغلاق لمجموعة بند وتكتب بهذه الطريقة clos(I) حيث I هي مجموعة البند. مجموعات البند المغلقة هذه هي التي سوف نتخذها لحالات المحلل، على الرغم من أن فقط الوحدات التي بالفعل يمكن الوصول إليها من أو حالة البدء سوف تكون متضمنة في الجداول.
قواعد مضافة
قبل أن نبدأ في تحديد الانتقال بين مختلف الحالات، القواعد دائما مزاد عليها بقواعد إضافية (0) S → E
حيث S انه هو رمز بداية جديدة وE هو رمز البداية القديم. المحلل سوف يستخدم هذه القاعدة للتخفيض بالضبط متى يتم قبول سلسلة الإدخال.
على سبيل المثال سوف نتخذ نفس القاعدة كما في السابق ونزيد عليها : (0) S → E (1) E → E * B (2) E → E + B (3) E → B (4) B → 0 (5) B → 1 ولهذه القواعد المضافة سوف نحدد مجموعات البند والتحولات بينها.
بناء الجدول
العثور على مجموعات البند التي يمكن الوصول اليها والتحولات بينها
الخطوة الأولى في بناء الجداول تتكون من تحديد المراحل الانتقالية بين مجموعات البند المغلقة. وسيتم تحديد هذه التحولات كما لو أننا نظر إلى في أوتوكاتيكية محدودة التي يمكن أن تقرأ الطرفيات واللا طرفيات. حالة البداية لهذه الأوتوكاتيكية دائما اختتام البند الأول من المادة المضافة S → • E
مجموعة البند 0 S → • E + E → • E * B + E → • E + B + E → • B + B → • 0 + B → • 1 حرف "+" الكبير أمام بند يدل على البنود التي تمت إضافتها للإغلاق (وينبغي عدم الخلط بينها وبين مشغل رمز رياضي '+' وهو محطة طرفية). البنود الأصلية بدون علامة "+ تسمى النواة لمجموعة البند.
ابتداء من حالة البدء (S0) نحن الآن سوف نحدد جميع الحالات التي يمكن الوصول إليها من هذه الحالة. التحولات المحتملة لمجموعة البند يمكن إيجادها من خلال النظر في الرموز (المحطات الطرفية والغير طرفية) نجد بعد النقاط تماماً ; وفي حالة مجموعة البند 0 هذه هي المحطات الطرفية '0' و'1' وB وE المحطة الغير طرفية.للعثور على مجموعة البند التي يؤدى اليها الرمز x نتبع الإجراء التالي :
1. نأخذ المجموعة، S، من كافة البنود في مجموعة البند الحالي حيث توجد نقطة أمام بعض الرموز X.
2. لكل بند في S، انقل نقطة على يمين X.
3. إغلاق المجموعة الناتجة من البنود.
لطرفية '0' هذه النتائج في :
مجموعة بند 1 B → 0 • وللطرفية '1' في : مجموعة بند 2 B → 1 • وعلى الغير طرفية E في : مجموعة بند 3 S → E • E → E • * B E → E • + B وعلى الغير طرفية B في: مجموعة البند 4 E → B •
لاحظ أن الإغلاق لا يضيف بنود جديدة في جميع الحالات. نواصل هذه العملية حتى لا نجد مجموعات بند جديد. لمجموعات البند 1 و 2 و 4 لن تكون هناك انتقالات حين لا توجد النقطة أمام أي رمز. بالنسبة لمجموعة البند 3 نرى أن لنقطة أمام الطرفيات'*' و'+. لـ '*' الانتقال يذهب إلى :
مجموعة البند 5 E → E * • B + B → • 0 + B → • 1
ولـ '+' الانتقال يذهب إلى :
مجموعة البند 6 E → E + • B + B → • 0 + B → • 1 لمجموعة البند 5 يجب النظر في المحطات الطرفية '0' و'1' والمحطة الغير طرفية B للمحطات الطرفية، نرى أن الناتج المجموعات المغلقة تساويى البنود التي وجدت بالفعل 1 و 2 على التوالي. بالنسبة للمحطة الغير طرفية B الانتقال يذهب إلى :
مجموعة البند 7 E → E * B •
بالنسبة لمجموعة بند 6 يجب النظر في الطرفية '0' و'1' والمحطة الغير طرفية B سبق، مجموعات البند الناتجة عن المحطات الطرفية متساوية إلى مجموعات البند التي وجدت بالفعل 1 و 2. للمحطة الغير طرفية B الانتقال يذهب إلى : مجموعة البند 8 E → E + B •
مجموعات البند الأخيرة هذه لا يوجد رموز لها خلف لذا لا يوجد مجموعات بنود جديدة تضاف وانتهينا. والأوتوكاتيكية المحدودة، مع مجموعات البند كما توجد أدناه.
| Item Set | * | + | 0 | 1 | E | B |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | ||
| 1 | ||||||
| 2 | ||||||
| 3 | 5 | 6 | ||||
| 4 | ||||||
| 5 | 1 | 2 | 7 | |||
| 6 | 1 | 2 | 8 | |||
| 7 | ||||||
| 8 |
بناء جداول الإجراءات action tables والانتقالات goto tables
من هذا الجدول ومجموعة البند هذه التي وجدت نبني جداول الإجراءات وجداول الانتقال على النحو التالي :
1. يتم نسخ أعمدة المحطات الغير طرفية إلى جدول الانتقال goto
2. يتم نسخ أعمدة المحطات الطرفية إلى جدول الإجراءات كتحول
3. يتم إضافة عمود إضافي لل'
4. إذا كانت مجموعة البند i تحتوي على بند من النموذج A → w • and A → w هي القاعدة m مع m > 0 ثم الصف للحالة i في جدول الإجراءات يتم تعبئتة تماما مع إجراء الخفض rm.
يمكن للقارئ أن يتحقق من أن هذه النتائج واقعية في جدول العمل والانتقالات التي عرضت من قبل هنا.
ملاحظة حول LR(0) مقارنة بتحليل SLR و LALR
لاحظ ان الخطوة 4 الوحيدة من الإجراء أعلاه تنتج الإجراءات الخفض، وهكذا كل إجراءات الخفض يجب أن تشغل صف بأكمله في الجدول، مما يسبب حدوث الخفض بغض النظر عن الرمز التالي في تدفق الإدخال. هذا هو السبب أنها جداول تحليل LR(0) : لا تفعل أي استباق (وهذا هو، أنهم يستبقون رموز صفر) قبل تقريرأي خفض ستقوم به. القواعد التي تحتاج إلى استباق أمامي لتزل غموض التخفيضات تتطلب تحليل صف الجدول الذي يحتوي على إجراءات خفض في اعمدة مختلفة، والإجراء أعلاه غير قادر على خلق مثل هذه الصفوف.
التحسينات على إجراءات بناء الجدول LR(0) (مثل SLR و LALR) قادرون على بناء إجراءات الخفض التي لا تشغل الصفوف الكاملة. ولذلك، فهي قادرة على تحليل قواعد أكثر من محللات LR(0).
التعارضات في بناء الجداول
يتم بناء الأوتوكاتيكية في مثل هذه الطريقة مضمونة القطعية. ومع ذلك، عندما تضاف إجراءات الخفض إلى جدول الإجراءات ما يمكن أن يحدث هو أن الخانة نفسها يكون بها إجراء خفض وإجراءات التحول (تعارض إجراءات الخفض والتحول) (a shift-reduce conflict) أو مع إجراءان اثنين للخفض (تعارض إجراءات الخفض والخفض) (a reduce-reduce conflict). ومع ذلك، يمكن أن يتبين أنه عندما يحدث هذا فإن القواعد لا تكون قواعد LR(0). وثمة مثال صغير للقواعد الغير LR(0) مع تعارض إجراءات الخفض والتحول هو : (1) E → 1 E (2) E → 1 واحدة من مجموعات البند نجدها : مجموعة بند 1 E → 1 • E E → 1 • + E → • 1 E + E → • 1
هناك تعارض إجراءات الخفض والتحول في مجموعة هذا البند لأن في الخلية في جدول الإجراءات لمجموعة البند هذه والطرفية '1' سوف يكون هناك على حد سواء إجراء التحول إلى الحالة (1) وإجراء خفض للمادة 2.
وثمة مثال صغير القواعد الغير LR(0) مع تعارض إجراءات الخفض والخفض، هو : (1) E → A 1 (2) E → B 2 (3) A → 1 (4) B → 1
في هذه الحالة نحصل على مجموعة البند التالية: مجموعة بند 1 A → 1 • B → 1 •
هناك تعارض إجراءات الخفض والخفض في مجموعة البند هذه لأن في الخلايا في جدول الإجراءات لمجموعة البند هذه سوف يكون هناك إجراءان خفض للمادة 3 وواحد للمادة 4.
المثالين المذكورين أعلاه يمكن حلهما عن طريق السماح للمحلل باستخدام محلل المجموعة التالية (انظر محلل اللغة LL LL parser) من المحطة الغير طرفية A لتقرر استخدام واحدة من القواعد مثل قواعد الخفض ؛ انها سوف تستخدم فقط القاعدة A → w للتخفيض إذا كان الرمز التالي على تدفق الإدخال هي المجموعة التالية لـ A هذه النتائج في الحل تسمى محلل LR البسيط Simple LR parsers.
انظر أيضا
• Deterministic context-free grammar • Simple LR, Look-Ahead LR, Canonical LR and Generalized LR • LL parser
المراجع
- Compilers: Principles, Techniques, and Tools, ألفرد أهو, Sethi, جيفري أولمان, أديسون-ويسلي , 1986. ISBN 0-201-10088-6. An extensive discussion of LR parsing and the principal source for some sections in this article.
- CS.VU.nl, Parsing Techniques - A Practical Guide web page of book includes downloadable pdf.
- The Functional Treatment of Parsing (Boston: Kluwer Academic, 1993), R. Leermakers, ISBN 0-7923-9376-7
- The theory of parsing, translation, and compiling, Alfred V. Aho and Jeffrey D. Ullman, available from ACM.org
Further reading
- Chapman, Nigel P., LR Parsing: Theory and Practice, مطبعة جامعة كامبريدج, 1987. ISBN 0-521-30413-X
وصلات خارجية
- Parsing Simulator This simulator is used to generate parsing tables LR and to resolve the exercises of the book
- Internals of an LALR(1) parser generated by GNU Bison - Implementation issues
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات