3D sound synthesis
3D sound is most commonly defined as the daily human experience of sounds. The sounds arrive to the ears from every direction and varying distances, which contribute to the three-dimensional aural image humans hear. Scientists and engineers who work with 3D sound work to accurately synthesize the complexity of real-world sounds.
Purpose
Due to the presence of 3D sound in daily life and the widespread use of 3D sound localization, the application of 3D sound synthesis rose in popularity in fields such as games, home theaters and human aid systems. It is argued that the purpose of 3D sound synthesis is to interpret the information gathered from 3D sound, as it is hard to use information from 3D sound on its own.
Applications
An application of 3D sound synthesis is the sense of presence in a virtual environment, by producing more realistic environments and sensations in games, teleconferencing systems, and tele-ensemble systems. 3D sound can also be used to help those with sensory impairments, such as the visually impaired, and act as a substitute for other sensory feedback.
The 3D sound may include the location of a source in three-dimensional space, as well as the three-dimensional sound radiation characteristics of a sound source. [1]
Problem statement and basics
The three main problems in 3D sound synthesis are front-to-back reversals, intracranially heard sounds, and HRTF measurements.
Front-to-back reversals are sounds that are heard directly in front of a subject when it is located at the back, and vice versa. This problem can be lessened by accurate inclusion of the subject's head movement and pinna response. When these two are missed during the HRTF calculation, the reverse problem will occur. Another solution is the early echo response, which exaggerates the differences of sounds from different directions and strengthens the pinna effects to reduce the front-to-back reversal rates. [2][3]
Intracranially heard sounds are external sounds that seem to be heard inside a person's head. This can be resolved by adding reverberation cues.
HRTF measurements are the sound noises and linearity problems that occur. By using several primary auditory cues with a subject that is skilled in localization, an effective HRTF can be generated for most cases.
Methods
The three main methods used in the 3D sound synthesis are the head-related transfer function, sound rendering, and synthesizing 3D sound with speaker location.
Head-related transfer function

Head-related transfer function (HRTF) is a linear function based on the sound source position and considers other information humans use to localize the sounds, such as the interaural time difference, head shadow, pinna response, shoulder echo, head motion, early echo response, reverberation, and vision.
The system attempts to model the human acoustic system by using an array of microphones to record sounds in human ears, which allows for more accurate synthesis of 3D sounds. The HRTF is obtained by comparing these recordings to the original sounds. Then, the HRTF is used to develop pairs of Finite Impulse Response (FIR) filters for specific sound positions with each sound having two filters for left and right. In order to place a sound at a certain position in 3D space, the set of FIR filters that correspond to the position is applied to the incoming sound, yielding a spatial sound. [4] The computations involved in convolving the sound signal from a particular point in space is typically large, therefore lots of work is generally needed to reduce the complexity. One such work is based on combining Principal Component Analysis (PCA) and Balanced Model Truncation (BMT) together. PCA is a widely used method in data mining and data reduction, which was used in 3D sound synthesis prior to the BMT to reduce redundancy. The BMT is applied to lower the computation complexity.
Sound rendering
The method of sound rendering involves creating a sound world by attaching a characteristic sound to each object in the scene to synthesize it as a 3D sound. The sound sources can be obtained either by sampling or artificial methods. There are two distinct passes in the method. The first pass computes the propagation paths from each object to the microphone and the result is collected for the geometric transformations of the sound source. The transformation from the first step is controlled by both delay and attenuation. The second pass creates the final soundtrack of the sound objects after being created, modulated and summed.[5]
The rendering method, a simpler method than HRTF generation, uses the similarity between light and sound waves because sounds in space propagate in all directions. The sound waves reflect and refract just like light. The final sound heard is the integral of multi-path transmitted signals.
There are four steps to the processing procedure. The first step involves generating the characteristic sound in each object. The second step is when the sound is created and attached to the moving objects. The third step is to calculate the convolutions, which are related to the effect of reverberation. Sound rendering approximates this by using the wavelength of sound similar to the object so it diffuses in its reflections, providing a smoothing effect of the sound. The last step is applying the calculated convolutions to the sound sources in step two. These steps allow a simplified soundtracking algorithm to be used without making much difference.
Synthesizing 3D sound with speaker location
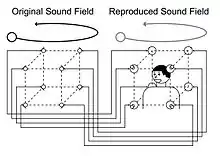
This method involves strategically placing eight speakers to simulate spatial sound, instead of attaching sampled sound to objects. [6] The first step consists of capturing the sound by using a cubic microphone array in the original sound field. The sound is then captured using the cubic loudspeaker array in the reproduced sound field. The listener, who is in the loudspeaker array, will feel that the sound is moving above their head when the sound is moving above the microphone array. [6]
The Wave field synthesis is a spatial audio rendering technique that synthesizes wavefronts by using Huygens–Fresnel principle. First, the original sound is recorded by microphone arrays and then loudspeaker arrays are used to reproduce the sound in the listening area. The arrays are placed along the boundaries of their own area where the microphones and the loudspeakers are placed as well. This technique allows multiple listeners to move in the listening area and still hear the same sound from all directions, which the binaural and crosstalk cancellation techniques cannot achieve. Generally, the sound reproduction systems using wave field synthesis place the loudspeakers in a line or around the listener in a 2D space.
References
- Ziemer, Tim (2020). Psychoacoustic Music Sound Field Synthesis. Current Research in Systematic Musicology. Vol. 7. Cham: Springer. p. 287. doi:10.1007/978-3-030-23033-3. ISBN 978-3-030-23033-3. S2CID 201136171.
- Burgess; David A (1992). "Techniques for low cost spatial audio". Proceedings of the 5th annual ACM symposium on User interface software and technology. pp. 53–59. CiteSeerX 10.1.1.464.4403. doi:10.1145/142621.142628. ISBN 978-0897915496. S2CID 7413673.
- Zhang, Ming; Tan, Kah-Chye; M.H.Er (1998). "A refined algorithm of 3-D sound synthesis". ICSP '98. 1998 Fourth International Conference on Signal Processing (Cat. No.98TH8344). Vol. 2. pp. 1408–1411 vol.2. doi:10.1109/ICOSP.1998.770884. ISBN 978-0-7803-4325-2. S2CID 57484436.
- Tonnesen, Cindy; Steinmetz, Joe. "3D Sound Synthesis".
- Takala; Tapio; James, Hahn (1992). "Sound rendering". Proceedings of the 19th annual conference on Computer graphics and interactive techniques. Vol. 26. pp. 211–220. doi:10.1145/133994.134063. ISBN 978-0897914796. S2CID 6252100.
- M. Naoe; T. Kimura; Y. Yamakata; M. Katsumoto (2008). "Performance Evaluation of 3D Sound Field Reproduction System Using a Few Loudspeakers and Wave Field Synthesis". 2008 Second International Symposium on Universal Communication. pp. 36–41. doi:10.1109/ISUC.2008.35. ISBN 978-0-7695-3433-6. S2CID 16506730.
{{cite book}}:|journal=ignored (help)