Alias method
In computing, the alias method is a family of efficient algorithms for sampling from a discrete probability distribution, published in 1974 by A. J. Walker.[1][2] That is, it returns integer values 1 ≤ i ≤ n according to some arbitrary probability distribution pi. The algorithms typically use O(n log n) or O(n) preprocessing time, after which random values can be drawn from the distribution in O(1) time.[3]
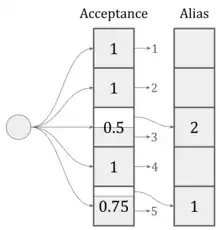
Operation
Internally, the algorithm consults two tables, a probability table Ui and an alias table Ki (for 1 ≤ i ≤ n). To generate a random outcome, a fair dice is rolled to determine an index into the two tables. Based on the probability stored at that index, a biased coin is then flipped, and the outcome of the flip is used to choose between a result of i and Ki.[4]
More concretely, the algorithm operates as follows:
- Generate a uniform random variate 0 ≤ x < 1.
- Let i = ⌊nx⌋ + 1 and y = nx + 1 − i. (This makes i uniformly distributed on {1, 2, ..., n} and y uniformly distributed on [0, 1).)
- If y < Ui, return i. This is the biased coin flip.
- Otherwise, return Ki.
An alternative formulation of the probability table, proposed by Marsaglia et al.[5] as the "square histogram" method, uses the condition x < Vi in the third step (where Vi = (Ui + i − 1)/n) instead of computing y.
Table generation
The distribution may be padded with additional probabilities pi = 0 to increase n to a convenient value, such as a power of two.
To generate the table, first initialize Ui = npi. While doing this, divide the table entries into three categories:
- The "overfull" group, where Ui > 1,
- The "underfull" group, where Ui < 1 and Ki has not been initialized, and
- The "exactly full" group, where Ui = 1 or Ki has been initialized.
If Ui = 1, the corresponding value Ki will never be consulted and is unimportant, but a value of Ki = i is sensible.
As long as not all table entries are exactly full, repeat the following steps:
- Arbitrarily choose an overfull entry Ui > 1 and an underfull entry Uj < 1. (If one of these exists, the other must, as well.)
- Allocate the unused space in entry j to outcome i, by setting Kj = i.
- Remove the allocated space from entry i by changing Ui = Ui − (1 − Uj) = Ui + Uj − 1.
- Entry j is now exactly full.
- Assign entry i to the appropriate category based on the new value of Ui.
Each iteration moves at least one entry to the "exactly full" category (and the last moves two), so the procedure is guaranteed to terminate after at most n−1 iterations. Each iteration can be done in O(1) time, so the table can be set up in O(n) time.
Vose[3]: 974 points out that floating-point rounding errors may cause the guarantee referred to in step 1 to be violated. If one category empties before the other, the remaining entries may have Ui set to 1 with negligible error. The solution accounting for floating point is sometimes called the Walker-Vose method or the Vose alias method.
The Alias structure is not unique.
As the lookup procedure is slightly faster if y < Ui (because Ki does not need to be consulted), one goal during table generation is to maximize the sum of the Ui. Doing this optimally turns out to be NP hard,[5]: 6 but a greedy algorithm comes reasonably close: rob from the richest and give to the poorest. That is, at each step choose the largest Ui and the smallest Uj. Because this requires sorting the Ui, it requires O(n log n) time.
Efficiency
Although the alias method is very efficient if generating a uniform deviate is itself fast, there are cases where it is far from optimal in terms of random bit usage. This is because it uses a full-precision random variate x each time, even when only a few random bits are needed.
One case arises when the probabilities are particularly well balanced, so many Ui = 1 and Ki is not needed. Generating y is a waste of time. For example if p1 = p2 = 1⁄2, then a 32-bit random variate x could be used to make 32 choices, but the alias method will only generate one.
Another case arises when the probabilities are strongly unbalanced, so many Ui ≈ 0. For example if p1 = 0.999 and p2 = 0.001, then the great majority of the time, only a few random bits are required to determine that case 1 applies. In such cases, the table method described by Marsaglia et al.[5]: 1–4 is more efficient. If we make many choices with the same probability we can on average require much less than one unbiased random bit. Using arithmetic coding techniques arithmetic we can approach the limit given by the binary entropy function.
Literature
- Donald Knuth, The Art of Computer Programming, Vol 2: Seminumerical Algorithms, section 3.4.1.
Implementations
- http://www.keithschwarz.com/darts-dice-coins/ Keith Schwarz: Detailed explanation, numerically stable version of Vose's algorithm, and link to Java implementation
- https://jugit.fz-juelich.de/mlz/ransampl Joachim Wuttke: Implementation as a small C library.
- https://gist.github.com/0b5786e9bfc73e75eb8180b5400cd1f8 Liam Huang's Implementation in C++
- https://github.com/joseftw/jos.weightedresult/blob/develop/src/JOS.WeightedResult/AliasMethodVose.cs C# implementation of Vose's algorithm.
- https://github.com/cdanek/KaimiraWeightedList C# implementation of Vose's algorithm without floating point instability.
References
- Walker, A. J. (April 1974). "New fast method for generating discrete random numbers with arbitrary frequency distributions". Electronics Letters. 10 (8): 127. Bibcode:1974ElL....10..127W. doi:10.1049/el:19740097.
- Walker, A. J. (September 1977). "An Efficient Method for Generating Discrete Random Variables with General Distributions". ACM Transactions on Mathematical Software. 3 (3): 253–256. doi:10.1145/355744.355749. S2CID 4522588.
- Vose, Michael D. (September 1991). "A linear algorithm for generating random numbers with a given distribution" (PDF). IEEE Transactions on Software Engineering. 17 (9): 972–975. CiteSeerX 10.1.1.398.3339. doi:10.1109/32.92917. Archived from the original (PDF) on 2013-10-29.
- "Darts, Dice, and Coins: Sampling from a Discrete Distribution". KeithSchwarz.com. 29 December 2011. Retrieved 2011-12-27.
- Marsaglia, George; Tsang, Wai Wan; Wang, Jingbo (2004-07-12), "Fast Generation of Discrete Random Variables", Journal of Statistical Software, 11 (3): 1–11, doi:10.18637/jss.v011.i03