Broadcast (parallel pattern)
Broadcast is a collective communication primitive in parallel programming to distribute programming instructions or data to nodes in a cluster. It is the reverse operation of reduction.[1] The broadcast operation is widely used in parallel algorithms, such as matrix-vector multiplication,[1] Gaussian elimination and shortest paths.[2]
The Message Passing Interface implements broadcast in MPI_Bcast.[3]
Definition
A message of length should be distributed from one node to all other nodes.
![{\displaystyle M[1..m]}](../I/c3e38b38a48f71cb8c1c43b0011a71a56a376f3b.svg)


is the time it takes to send one byte.

is the time it takes for a message to travel to another node, independent of its length.

Therefore, the time to send a package from one node to another is .[1]

is the number of nodes and the number of processors.

Binomial Tree Broadcast

With Binomial Tree Broadcast the whole message is sent at once. Each node that has already received the message sends it on further. This grows exponentially as each time step the amount of sending nodes is doubled. The algorithm is ideal for short messages but falls short with longer ones as during the time when the first transfer happens only one node is busy.
Sending a message to all nodes takes time which results in a runtime of


Message M
id := node number
p := number of nodes
if id > 0
blocking_receive M
for (i := ceil(log_2(p)) - 1; i >= 0; i--)
if (id % 2^(i+1) == 0 && id + 2^i <= p)
send M to node id + 2^i
Linear Pipeline Broadcast
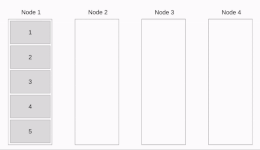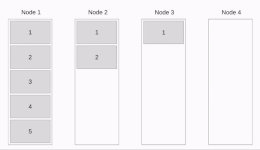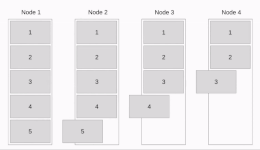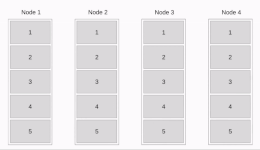
The message is split up into packages and send piecewise from node to node . The time needed to distribute the first message piece is whereby is the time needed to send a package from one processor to another.





Sending a whole message takes .

Optimal is to choose resulting in a runtime of approximately


The run time is dependent on not only message length but also the number of processors that play roles. This approach shines when the length of the message is much larger than the amount of processors.
Message M := [m_1, m_2, ..., m_n]
id = node number
for (i := 1; i <= n; i++) in parallel
if (id != 0)
blocking_receive m_i
if (id != n)
send m_i to node id + 1
Pipelined Binary Tree Broadcast
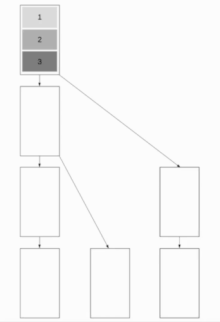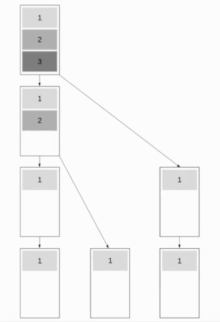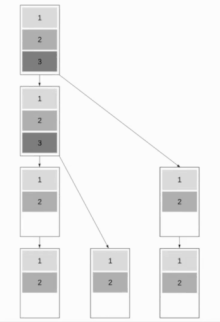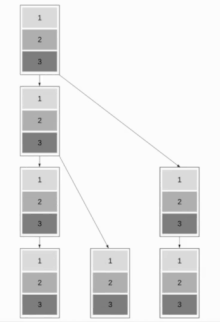
This algorithm combines Binomial Tree Broadcast and Linear Pipeline Broadcast, which makes the algorithm work well for both short and long messages. The aim is to have as many nodes work as possible while maintaining the ability to send short messages quickly. A good approach is to use Fibonacci trees for splitting up the tree, which are a good choice as a message cannot be sent to both children at the same time. This results in a binary tree structure.
We will assume in the following that communication is full-duplex. The Fibonacci tree structure has a depth of about whereby the golden ratio.


The resulting runtime is . Optimal is .


This results in a runtime of .

Message M := [m_1, m_2, ..., m_k]
for i = 1 to k
if (hasParent())
blocking_receive m_i
if (hasChild(left_child))
send m_i to left_child
if (hasChild(right_child))
send m_i to right_child
Two Tree Broadcast (23-Broadcast)

Definition
This algorithm aims to improve on some disadvantages of tree structure models with pipelines. Normally in tree structure models with pipelines (see above methods), leaves receive just their data and cannot contribute to send and spread data.
The algorithm concurrently uses two binary trees to communicate over. Those trees will be called tree A and B. Structurally in binary trees there are relatively more leave nodes than inner nodes. Basic Idea of this algorithm is to make a leaf node of tree A be an inner node of tree B. It has also the same technical function in opposite side from B to A tree. This means, two packets are sent and received by inner nodes and leaves in different steps.
Tree construction
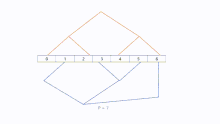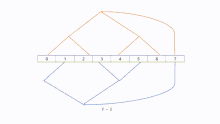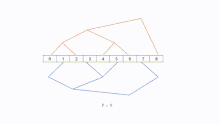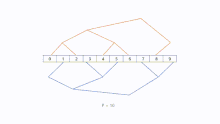
The number of steps needed to construct two parallel-working binary trees is dependent on the amount of processors. Like with other structures one processor can is the root node who sends messages to two trees. It is not necessary to set a root node, because it is not hard to recognize that the direction of sending messages in binary tree is normally top to bottom. There is no limitation on the number of processors to build two binary trees. Let the height of the combined tree be h = ⌈log(p + 2)⌉. Tree A and B can have a height of . Especially, if the number of processors correspond to , we can make both sides trees and a root node.


To construct this model efficiently and easily with a fully built tree, we can use two methods called "Shifting" and "Mirroring" to get second tree. Let assume tree A is already modeled and tree B is supposed to be constructed based on tree A. We assume that we have processors ordered from 0 to .
Shifting

The "Shifting" method, first copies tree A and moves every node one position to the left to get tree B. The node, which will be located on -1, becomes a child of processor .

Mirroring
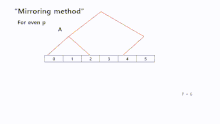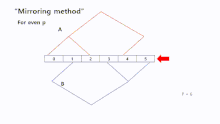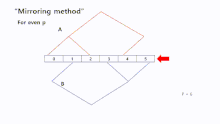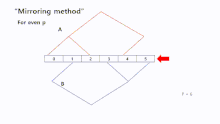
"Mirroring" is ideal for an even number of processors. With this method tree B can be more easily constructed by tree A, because there are no structural transformations in order to create the new tree. In addition, a symmetric process makes this approach simple. This method can also handle an odd number of processors, in this case, we can set processor as root node for both trees. For the remaining processors "Mirroring" can be used.
Coloring
We need to find a schedule in order to make sure that no processor has to send or receive two messages from two trees in a step. The edge, is a communication connection to connect two nodes, and can be labelled as either 0 or 1 to make sure that every processor can alternate between 0 and 1-labelled edges. The edges of A and B can be colored with two colors (0 and 1) such that
- no processor is connected to its parent nodes in A and B using edges of the same color-
- no processor is connected to its children nodes in A or B using edges of the same color.[7]
In every even step the edges with 0 are activated and edges with 1 are activated in every odd step.
Time complexity
In this case the number of packet k is divided in half for each tree. Both trees are working together the total number of packets (upper tree + bottom tree)

In each binary tree sending a message to another nodes takes steps until a processor has at least a packet in step . Therefore, we can calculate all steps as .



The resulting run time is . (Optimal )


This results in a run time of .

ESBT-Broadcasting (Edge-disjoint Spanning Binomial Trees)
In this section, another broadcasting algorithm with an underlying telephone communication model will be introduced. A Hypercube creates network system with . Every node is represented by binary depending on the number of dimensions. Fundamentally ESBT(Edge-disjoint Spanning Binomial Trees) is based on hypercube graphs, pipelining( messages are divided by packets) and binomial trees. The Processor cyclically spreads packets to roots of ESBTs. The roots of ESBTs broadcast data with binomial tree. To leave all of from , steps are required, because all packets are distributed by . It takes another d steps until the last leaf node receives the packet. In total steps are necessary to broadcast message through ESBT.





The resulting run time is . .


This results in a run time of .

See also
References
- Kumar, Vipin (2002). Introduction to Parallel Computing (2nd ed.). Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc. pp. 185, 151, 66. ISBN 9780201648652.
- Bruck, J.; Cypher, R.; Ho, C-T. (1992). "Multiple message broadcasting with generalized Fibonacci trees". [1992] Proceedings of the Fourth IEEE Symposium on Parallel and Distributed Processing. pp. 424–431. doi:10.1109/SPDP.1992.242714. ISBN 0-8186-3200-3. S2CID 2846661.
- MPI: A Message-Passing Interface StandardVersion 3.0, Message Passing Interface Forum, pp. 148, 2012
- Michael Ikkert, T. Kieritz, P. Sanders Parralele Algorithme - Script (German), Karlsruhe Institute of Technology, pp. 29-32, 2009
- Michael Ikkert, T. Kieritz, P. Sanders Parralele Algorithme - Script (German), Karlsruhe Institute of Technology, pp.33-37, 2009
- P. Sanders (German), Karlsruhe Institute of Technology, pp. 82-96, 2018
- Sanders, Peter; Speck, Jochen; Träff, Jesper Larsson (2009). "Two-tree algorithms for full bandwidth broadcast, reduction and scan". Parallel Computing. 35 (12): 581–594. doi:10.1016/j.parco.2009.09.001. ISSN 0167-8191.
- Michael Ikkert, T. Kieritz, P. Sanders Parralele Algorithme - Script (German), Karlsruhe Institute of Technology, pp.40-42, 2009
- P. Sanders (German), Karlsruhe Institute of Technology, pp. 101-104, 2018