CATH database
The CATH Protein Structure Classification database is a free, publicly available online resource that provides information on the evolutionary relationships of protein domains. It was created in the mid-1990s by Professor Christine Orengo and colleagues including Janet Thornton and David Jones,[2] and continues to be developed by the Orengo group at University College London. CATH shares many broad features with the SCOP resource, however there are also many areas in which the detailed classification differs greatly.[3][4][5][6]
| Content | |
|---|---|
| Description | Protein Structure Classification |
| Contact | |
| Research center | University College London |
| Laboratory | Institute of Structural and Molecular Biology |
| Primary citation | Dawson et al. (2016) [1] |
| Release date | 1997 |
| Access | |
| Website | cathdb |
| Download URL | cathdb |
| Miscellaneous | |
| Data release frequency | CATH-B is released daily. Official releases are approximately annual. |
| Version | 4.3 |
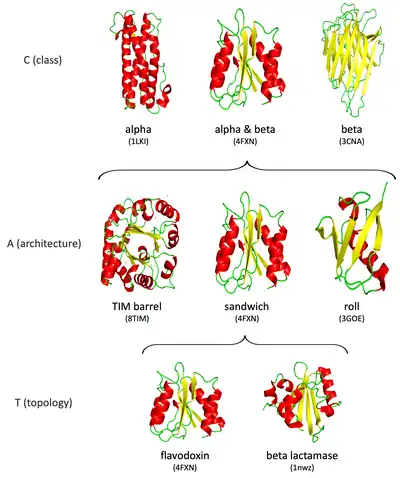
Hierarchical organization
Experimentally determined protein three-dimensional structures are obtained from the Protein Data Bank and split into their consecutive polypeptide chains, where applicable. Protein domains are identified within these chains using a mixture of automatic methods and manual curation.
The domains are then classified within the CATH structural hierarchy: at the Class (C) level, domains are assigned according to their secondary structure content, i.e. all alpha, all beta, a mixture of alpha and beta, or little secondary structure; at the Architecture (A) level, information on the secondary structure arrangement in three-dimensional space is used for assignment; at the Topology/fold (T) level, information on how the secondary structure elements are connected and arranged is used; assignments are made to the Homologous superfamily (H) level if there is good evidence that the domains are related by evolution[2] i.e. they are homologous.
| # | Level | Description |
|---|---|---|
| 1 | Class | the overall secondary-structure content of the domain. (Equivalent to the SCOP Class) |
| 2 | Architecture | high structural similarity but no evidence of homology. |
| 3 | Topology/fold | a large-scale grouping of topologies which share particular structural features (Equivalent to the 'fold' level in SCOP) |
| 4 | Homologous superfamily | indicative of a demonstrable evolutionary relationship. (Equivalent to SCOP superfamily) |
Additional sequence data for domains with no experimentally determined structures are provided by CATH's sister resource, Gene3D, which are used to populate the homologous superfamilies. Protein sequences from UniProtKB and Ensembl are scanned against CATH HMMs to predict domain sequence boundaries and make homologous superfamily assignments.
Releases
The CATH team aim to provide official releases of the CATH classification every 12 months. This release process is important because it allows for the provision of internal validation, extra annotations and analysis. However, it can mean that there is a time delay between new structures appearing in the PDB and the latest official CATH release,
In order to address this issue: CATH-B provides a limited amount of information to the very latest domain annotations (e.g., domain boundaries and superfamily classifications).
The latest release of CATH-Gene3D (v4.3) was released in December 2020 and consists of:
Open-source software
CATH is an open source software project, with developers developing and maintaining a number of open-source tools.[7] CATH maintains a todo list on GitHub to allow external users to create and keep track of issues relating to the CATH protein structure classification.
References
- Dawson NL, Lewis TE, Das S, Lees JG, Lee D, Ashford P, et al. (January 2017). "CATH: an expanded resource to predict protein function through structure and sequence". Nucleic Acids Research. 45 (D1): D289–D295. doi:10.1093/nar/gkw1098. PMC 5210570. PMID 27899584.
- Orengo CA, Michie AD, Jones S, Jones DT, Swindells MB, Thornton JM (August 1997). "CATH--a hierarchic classification of protein domain structures". Structure. London, England. 5 (8): 1093–108. doi:10.1016/s0969-2126(97)00260-8. PMID 9309224.
- "CATH: Protein Structure Classification Database at UCL". Cathdb.info. Retrieved 9 March 2017.
- "CATH". Cathdb.info. Retrieved 9 March 2017.
- "CATH Database (@CATHDatabase)". Twitter. Retrieved 9 March 2017.
- Pearl FM, Bennett CF, Bray JE, Harrison AP, Martin N, Shepherd A, et al. (January 2003). "The CATH database: an extended protein family resource for structural and functional genomics". Nucleic Acids Research. 31 (1): 452–455. doi:10.1093/nar/gkg062. PMC 165509. PMID 12520050.
- "Tools". cathdb.info. Retrieved 18 December 2016.