Cache hierarchy
Cache hierarchy, or multi-level caches, refers to a memory architecture that uses a hierarchy of memory stores based on varying access speeds to cache data. Highly requested data is cached in high-speed access memory stores, allowing swifter access by central processing unit (CPU) cores.
Cache hierarchy is a form and part of memory hierarchy and can be considered a form of tiered storage.[1] This design was intended to allow CPU cores to process faster despite the memory latency of main memory access. Accessing main memory can act as a bottleneck for CPU core performance as the CPU waits for data, while making all of main memory high-speed may be prohibitively expensive. High-speed caches are a compromise allowing high-speed access to the data most-used by the CPU, permitting a faster CPU clock.[2]
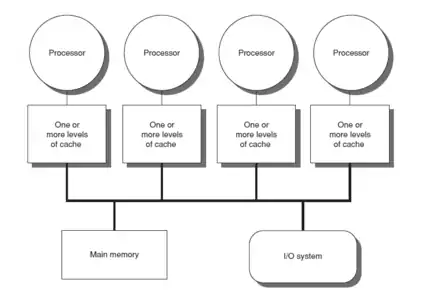
Background
In the history of computer and electronic chip development, there was a period when increases in CPU speed outpaced the improvements in memory access speed.[3] The gap between the speed of CPUs and memory meant that the CPU would often be idle.[4] CPUs were increasingly capable of running and executing larger amounts of instructions in a given time, but the time needed to access data from main memory prevented programs from fully benefiting from this capability.[5] This issue motivated the creation of memory models with higher access rates in order to realize the potential of faster processors.[6]
This resulted in the concept of cache memory, first proposed by Maurice Wilkes, a British computer scientist at the University of Cambridge in 1965. He called such memory models "slave memory".[7] Between roughly 1970 and 1990, papers and articles by Anant Agarwal, Alan Jay Smith, Mark D. Hill, Thomas R. Puzak, and others discussed better cache memory designs. The first cache memory models were implemented at the time, but even as researchers were investigating and proposing better designs, the need for faster memory models continued. This need resulted from the fact that although early cache models improved data access latency, with respect to cost and technical limitations it was not feasible for a computer system's cache to approach the size of main memory. From 1990 onward, ideas such as adding another cache level (second-level), as a backup for the first-level cache were proposed. Jean-Loup Baer, Wen-Hann Wang, Andrew W. Wilson, and others have conducted research on this model. When several simulations and implementations demonstrated the advantages of two-level cache models, the concept of multi-level caches caught on as a new and generally better model of cache memories. Since 2000, multi-level cache models have received widespread attention and are currently implemented in many systems, such as the three-level caches that are present in Intel's Core i7 products.[8]
Multi-level cache
Accessing main memory for each instruction execution may result in slow processing, with the clock speed depending on the time required to find and fetch the data. In order to hide this memory latency from the processor, data caching is used.[9] Whenever the data is required by the processor, it is fetched from the main memory and stored in the smaller memory structure called a cache. If there is any further need of that data, the cache is searched first before going to the main memory.[10] This structure resides closer to the processor in terms of the time taken to search and fetch data with respect to the main memory.[11] The advantages of using cache can be proven by calculating the average access time (AAT) for the memory hierarchy with and without the cache.[12]
Average access time (AAT)
Caches, being small in size, may result in frequent misses – when a search of the cache does not provide the sought-after information – resulting in a call to main memory to fetch data. Hence, the AAT is affected by the miss rate of each structure from which it searches for the data.[13]

AAT for main memory is given by Hit time main memory. AAT for caches can be given by
- Hit timecache + (Miss ratecache × Miss Penaltytime taken to go to main memory after missing cache).
The hit time for caches is less than the hit time for the main memory, so the AAT for data retrieval is significantly lower when accessing data through the cache rather than main memory.[14]
Trade-offs
While using the cache may improve memory latency, it may not always result in the required improvement for the time taken to fetch data due to the way caches are organized and traversed. For example, direct-mapped caches that are the same size usually have a higher miss rate than fully associative caches. This may also depend on the benchmark of the computer testing the processor and on the pattern of instructions. But using a fully associative cache may result in more power consumption, as it has to search the whole cache every time. Due to this, the trade-off between power consumption (and associated heat) and the size of the cache becomes critical in the cache design.[13]
Evolution
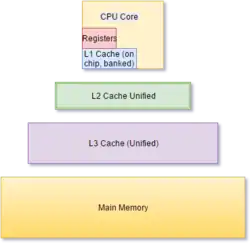
In the case of a cache miss, the purpose of using such a structure will be rendered useless and the computer will have to go to the main memory to fetch the required data. However, with a multiple-level cache, if the computer misses the cache closest to the processor (level-one cache or L1) it will then search through the next-closest level(s) of cache and go to main memory only if these methods fail. The general trend is to keep the L1 cache small and at a distance of 1–2 CPU clock cycles from the processor, with the lower levels of caches increasing in size to store more data than L1, hence being more distant but with a lower miss rate. This results in a better AAT.[15] The number of cache levels can be designed by architects according to their requirements after checking for trade-offs between cost, AATs, and size.[16][17]
Performance gains
With the technology-scaling that allowed memory systems able to be accommodated on a single chip, most modern day processors have up to three or four cache levels.[18] The reduction in the AAT can be understood by this example, where the computer checks AAT for different configurations up to L3 caches.
Example: main memory = 50 ns, L1 = 1 ns with 10% miss rate, L2 = 5 ns with 1% miss rate, L3 = 10 ns with 0.2% miss rate.
- No cache, AAT = 50 ns
- L1 cache, AAT = 1 ns + (0.1 × 50 ns) = 6 ns
- L1–2 caches, AAT = 1 ns + (0.1 × [5 ns + (0.01 × 50 ns)]) = 1.55 ns
- L1–3 caches, AAT = 1 ns + (0.1 × [5 ns + (0.01 × [10 ns + (0.002 × 50 ns)])]) = 1.5101 ns
Disadvantages
- Cache memory comes at an increased marginal cost than main memory and thus can increase the cost of the overall system.[19]
- Cached data is stored only so long as power is provided to the cache.
- Increased on-chip area required for memory system.[20]
- Benefits may be minimized or eliminated in the case of a large programs with poor temporal locality, which frequently access the main memory.[21]
Properties
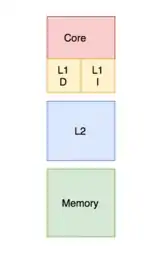
Banked versus unified
In a banked cache, the cache is divided into a cache dedicated to instruction storage and a cache dedicated to data. In contrast, a unified cache contains both the instructions and data in the same cache.[22] During a process, the L1 cache (or most upper-level cache in relation to its connection to the processor) is accessed by the processor to retrieve both instructions and data. Requiring both actions to be implemented at the same time requires multiple ports and more access time in a unified cache. Having multiple ports requires additional hardware and wiring, leading to a significant structure between the caches and processing units.[23] To avoid this, the L1 cache is often organized as a banked cache which results in fewer ports, less hardware, and generally lower access times.[13]
Modern processors have split caches, and in systems with multilevel caches higher level caches may be unified while lower levels split.[24]
Inclusion policies
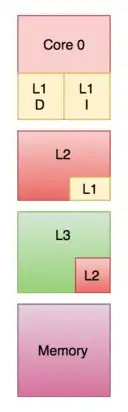
Whether a block present in the upper cache layer can also be present in the lower cache level is governed by the memory system's inclusion policy, which may be inclusive, exclusive or non-inclusive non-exclusive (NINE).[25]
With an inclusive policy, all the blocks present in the upper-level cache have to be present in the lower-level cache as well. Each upper-level cache component is a subset of the lower-level cache component. In this case, since there is a duplication of blocks, there is some wastage of memory. However, checking is faster.[25]
Under an exclusive policy, all the cache hierarchy components are completely exclusive, so that any element in the upper-level cache will not be present in any of the lower cache components. This enables complete usage of the cache memory. However, there is a high memory-access latency.[26]
The above policies require a set of rules to be followed in order to implement them. If none of these are forced, the resulting inclusion policy is called non-inclusive non-exclusive (NINE). This means that the upper-level cache may or may not be present in the lower-level cache.[21]
Write policies
There are two policies which define the way in which a modified cache block will be updated in the main memory: write through and write back.[25]
In the case of write through policy, whenever the value of the cache block changes, it is further modified in the lower-level memory hierarchy as well.[27] This policy ensures that the data is stored safely as it is written throughout the hierarchy.
However, in the case of the write back policy, the changed cache block will be updated in the lower-level hierarchy only when the cache block is evicted. A "dirty bit" is attached to each cache block and set whenever the cache block is modified.[28] During eviction, blocks with a set dirty bit will be written to the lower-level hierarchy. Under this policy, there is a risk for data-loss as the most recently changed copy of a datum is only stored in the cache and therefore some corrective techniques must be observed.
In case of a write where the byte is not present in the cache block, the byte may be brought to the cache as determined by a write allocate or write no-allocate policy.[25] Write allocate policy states that in case of a write miss, the block is fetched from the main memory and placed in the cache before writing.[29] In the write no-allocate policy, if the block is missed in the cache it will write in the lower-level memory hierarchy without fetching the block into the cache.[30]
The common combinations of the policies are "write block", "write allocate", and "write through write no-allocate".
Shared versus private
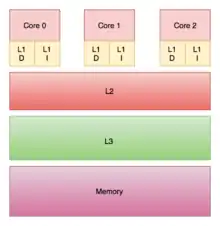
A private cache is assigned to one particular core in a processor, and cannot be accessed by any other cores. In some architectures, each core has its own private cache; this creates the risk of duplicate blocks in a system's cache architecture, which results in reduced capacity utilization. However, this type of design choice in a multi-layer cache architecture can also be good for a lower data-access latency.[25][31][32]
A shared cache is a cache which can be accessed by multiple cores.[33] Since it is shared, each block in the cache is unique and therefore has a larger hit rate as there will be no duplicate blocks. However, data-access latency can increase as multiple cores try to access the same cache.[34]
In multi-core processors, the design choice to make a cache shared or private impacts the performance of the processor.[35] In practice, the upper-level cache L1 (or sometimes L2)[36][37] is implemented as private and lower-level caches are implemented as shared. This design provides high access rates for the high-level caches and low miss rates for the lower-level caches.[35]
Recent implementation models
Intel Broadwell microarchitecture (2014)
- L1 cache (instruction and data) – 64 kB per core
- L2 cache – 256 kB per core
- L3 cache – 2 MB to 6 MB shared
- L4 cache – 128 MB of eDRAM (Iris Pro models only)[36]
Intel Kaby Lake microarchitecture (2016)
- L1 cache (instruction and data) – 64 kB per core
- L2 cache – 256 kB per core
- L3 cache – 2 MB to 8 MB shared[37]
AMD Zen microarchitecture (2017)
- L1 cache – 32 kB data & 64 kB instruction per core, 4-way
- L2 cache – 512 kB per core, 4-way inclusive
- L3 cache – 4 MB local & remote per 4-core CCX, 2 CCXs per chiplet, 16-way non-inclusive. Up to 16 MB on desktop CPUs and 64 MB on server CPUs
AMD Zen 2 microarchitecture (2019)
- L1 cache – 32 kB data & 32 kB instruction per core, 8-way
- L2 cache – 512 kB per core, 8-way inclusive
- L3 cache – 16 MB local per 4-core CCX, 2 CCXs per chiplet, 16-way non-inclusive. Up to 64 MB on desktop CPUs and 256 MB on server CPUs
IBM POWER7 (2010)
- L1 cache (instruction and data) – each 64-banked, each bank has 2rd+1wr ports 32 kB, 8-way associative, 128B block, write through
- L2 cache – 256 kB, 8-way, 128B block, write back, inclusive of L1, 2 ns access latency
- L3 cache – 8 regions of 4 MB (total 32 MB), local region 6 ns, remote 30 ns, each region 8-way associative, DRAM data array, SRAM tag array[39]
See also
References
- Hennessy, John L; Patterson, David A; Asanović, Krste; Bakos, Jason D; Colwell, Robert P; Bhattacharjee, Abhishek; Conte, Thomas M; Duato, José; Franklin, Diana; Goldberg, David; Jouppi, Norman P; Li, Sheng; Muralimanohar, Naveen; Peterson, Gregory D; Pinkston, Timothy Mark; Ranganathan, Prakash; Wood, David Allen; Young, Clifford; Zaky, Amr (2011). Computer Architecture: a Quantitative Approach (Sixth ed.). ISBN 978-0128119051. OCLC 983459758.
- "Cache: Why Level It" (PDF).
- Ronald D. Miller; Lars I. Eriksson; Lee A Fleisher, 2014. Miller's Anesthesia E-Book. Elsevier Health Sciences. p. 75. ISBN 978-0-323-28011-2.
- Albert Y. Zomaya, 2006. Handbook of Nature-Inspired and Innovative Computing: Integrating Classical Models with Emerging Technologies. Springer Science & Business Media. p. 298. ISBN 978-0-387-40532-2.
- Richard C. Dorf, 2018. Sensors, Nanoscience, Biomedical Engineering, and Instruments: Sensors Nanoscience Biomedical Engineering. CRC Press. p. 4. ISBN 978-1-4200-0316-1.
- David A. Patterson; John L. Hennessy, 2004. Computer Organization and Design: The Hardware/Software Interface, Third Edition. Elsevier. p. 552. ISBN 978-0-08-050257-1.
- "Sir Maurice Vincent Wilkes | British computer scientist". Encyclopædia Britannica. Retrieved 2016-12-11.
- Berkeley, John L. Hennessy, Stanford University, and David A. Patterson, University of California. "Memory Hierarchy Design - Part 6. The Intel Core i7, fallacies, and pitfalls". EDN. Retrieved 2022-10-13.
{{cite news}}: CS1 maint: multiple names: authors list (link) - Shane Cook, 2012. CUDA Programming: A Developer's Guide to Parallel Computing with GPUs. Newnes. pp. 107–109. ISBN 978-0-12-415988-4.
- Bruce Hellingsworth; Patrick Hall; Howard Anderson; 2001. Higher National Computing. Routledge. pp. 30–31. ISBN 978-0-7506-5230-8.
- Reeta Sahoo, Gagan Sahoo. Infomatic Practices. Saraswati House Pvt Ltd. pp. 1–. ISBN 978-93-5199-433-6.
- Phillip A. Laplante; Seppo J. Ovaska; 2011. Real-Time Systems Design and Analysis: Tools for the Practitioner. John Wiley & Sons. pp. 94–95. ISBN 978-1-118-13659-1.
- Hennessey and Patterson. Computer Architecture: A Quantitative Approach. Morgan Kaufmann. ISBN 9780123704900.
- Cetin Kaya Koc, 2008. Cryptographic Engineering. Springer Science & Business Media. pp. 479–480. ISBN 978-0-387-71817-0.
- David A. Patterson; John L. Hennessy; 2008. Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann. pp. 489–492. ISBN 978-0-08-092281-2.
- Harvey G. Cragon, 2000. Computer Architecture and Implementation. Cambridge University Press. pp. 95–97. ISBN 978-0-521-65168-4.
- Baker Mohammad, 2013. Embedded Memory Design for Multi-Core and Systems on Chip. Springer Science & Business Media. pp. 11–14. ISBN 978-1-4614-8881-1.
- Gayde, William. "How CPUs are Designed and Built". Techspot. Retrieved 17 August 2019.
- Vojin G. Oklobdzija, 2017. Digital Design and Fabrication. CRC Press. p. 4. ISBN 978-0-8493-8604-6.
- "Memory Hierarchy".
- Solihin, Yan (2016). Fundamentals of Parallel Multicore Architecture. Chapman and Hall. pp. Chapter 5: Introduction to Memory Hierarchy Organization. ISBN 9781482211184.
- Yan Solihin, 2015. Fundamentals of Parallel Multicore Architecture. CRC Press. p. 150. ISBN 978-1-4822-1119-1.
- Steve Heath, 2002. Embedded Systems Design. Elsevier. p. 106. ISBN 978-0-08-047756-5.
- Alan Clements, 2013. Computer Organization & Architecture: Themes and Variations. Cengage Learning. p. 588. ISBN 1-285-41542-6.
- Solihin, Yan (2009). Fundamentals of Parallel Computer Architecture. Solihin Publishing. pp. Chapter 6: Introduction to Memory Hierarchy Organization. ISBN 9780984163007.
- "Performance Evaluation of Exclusive Cache Hierarchies" (PDF).
- David A. Patterson; John L. Hennessy; 2017. Computer Organization and Design RISC-V Edition: The Hardware Software Interface. Elsevier Science. pp. 386–387. ISBN 978-0-12-812276-1.
- Stefan Goedecker; Adolfy Hoisie; 2001. Performance Optimization of Numerically Intensive Codes. SIAM. p. 11. ISBN 978-0-89871-484-5.
- Harvey G. Cragon, 1996. Memory Systems and Pipelined Processors. Jones & Bartlett Learning. p. 47. ISBN 978-0-86720-474-2.
- David A. Patterson; John L. Hennessy; 2007. Computer Organization and Design, Revised Printing, Third Edition: The Hardware/Software Interface. Elsevier. p. 484. ISBN 978-0-08-055033-6.
- "Software Techniques for Shared-Cache Multi-Core Systems". 2018-05-24.
- "An Adaptive Shared/Private NUCA Cache Partitioning Scheme for Chip Multiprocessors" (PDF). Archived from the original (PDF) on 2016-10-19.
- Akanksha Jain; Calvin Lin; 2019. Cache Replacement Policies. Morgan & Claypool Publishers. p. 45. ISBN 978-1-68173-577-1.
- David Culler; Jaswinder Pal Singh; Anoop Gupta; 1999. Parallel Computer Architecture: A Hardware/Software Approach. Gulf Professional Publishing. p. 436. ISBN 978-1-55860-343-1.
- Stephen W. Keckler; Kunle Olukotun; H. Peter Hofstee; 2009. Multicore Processors and Systems. Springer Science & Business Media. p. 182. ISBN 978-1-4419-0263-4.
- "Intel Broadwell Microarchitecture".
- "Intel Kaby Lake Microrchitecture".
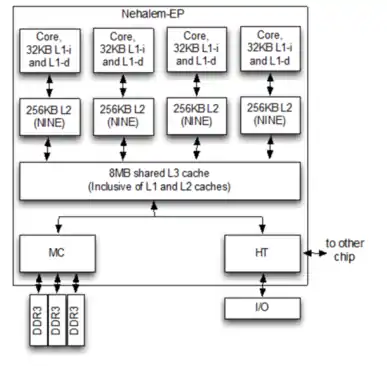
- "The Architecture of the Nehalem Processor and Nehalem-EP SMP Platforms" (PDF). Archived from the original (PDF) on 2014-08-11.
- "IBM Power7".