Catastrophic interference
Catastrophic interference, also known as catastrophic forgetting, is the tendency of an artificial neural network to abruptly and drastically forget previously learned information upon learning new information.[1][2] Neural networks are an important part of the network approach and connectionist approach to cognitive science. With these networks, human capabilities such as memory and learning can be modeled using computer simulations.
| Part of a series on |
| Machine learning and data mining |
|---|
 |
Catastrophic interference is an important issue to consider when creating connectionist models of memory. It was originally brought to the attention of the scientific community by research from McCloskey and Cohen (1989),[1] and Ratcliff (1990).[2] It is a radical manifestation of the 'sensitivity-stability' dilemma[3] or the 'stability-plasticity' dilemma.[4] Specifically, these problems refer to the challenge of making an artificial neural network that is sensitive to, but not disrupted by, new information.
Lookup tables and connectionist networks lie on the opposite sides of the stability plasticity spectrum.[5] The former remains completely stable in the presence of new information but lacks the ability to generalize, i.e. infer general principles, from new inputs. On the other hand, connectionist networks like the standard backpropagation network can generalize to unseen inputs, but they are very sensitive to new information. Backpropagation models can be analogized to human memory insofar as they mirror the human ability to generalize but these networks often exhibit less stability than human memory. Notably, these backpropagation networks are susceptible to catastrophic interference. This is an issue when modelling human memory, because unlike these networks, humans typically do not show catastrophic forgetting.[6]
History of catastrophic interference
The term catastrophic interference was originally coined by McCloskey and Cohen (1989) but was also brought to the attention of the scientific community by research from Ratcliff (1990).[2]
The Sequential Learning Problem: McCloskey and Cohen (1989)
McCloskey and Cohen (1989) noted the problem of catastrophic interference during two different experiments with backpropagation neural network modelling.
- Experiment 1: Learning the ones and twos addition facts
In their first experiment they trained a standard backpropagation neural network on a single training set consisting of 17 single-digit ones problems (i.e., 1 + 1 through 9 + 1, and 1 + 2 through 1 + 9) until the network could represent and respond properly to all of them. The error between the actual output and the desired output steadily declined across training sessions, which reflected that the network learned to represent the target outputs better across trials. Next, they trained the network on a single training set consisting of 17 single-digit twos problems (i.e., 2 + 1 through 2 + 9, and 1 + 2 through 9 + 2) until the network could represent, respond properly to all of them. They noted that their procedure was similar to how a child would learn their addition facts. Following each learning trial on the twos facts, the network was tested for its knowledge on both the ones and twos addition facts. Like the ones facts, the twos facts were readily learned by the network. However, McCloskey and Cohen noted the network was no longer able to properly answer the ones addition problems even after one learning trial of the twos addition problems. The output pattern produced in response to the ones facts often resembled an output pattern for an incorrect number more closely than the output pattern for a correct number. This is considered to be a drastic amount of error. Furthermore, the problems 2+1 and 2+1, which were included in both training sets, even showed dramatic disruption during the first learning trials of the twos facts.
- Experiment 2: Replication of Barnes and Underwood (1959) study[7]
In their second connectionist model, McCloskey and Cohen attempted to replicate the study on retroactive interference in humans by Barnes and Underwood (1959). They trained the model on A-B and A-C lists and used a context pattern in the input vector (input pattern), to differentiate between the lists. Specifically the network was trained to respond with the right B response when shown the A stimulus and A-B context pattern and to respond with the correct C response when shown the A stimulus and the A-C context pattern. When the model was trained concurrently on the A-B and A-C items then the network readily learned all of the associations correctly. In sequential training the A-B list was trained first, followed by the A-C list. After each presentation of the A-C list, performance was measured for both the A-B and A-C lists. They found that the amount of training on the A-C list in Barnes and Underwood study that lead to 50% correct responses, lead to nearly 0% correct responses by the backpropagation network. Furthermore, they found that the network tended to show responses that looked like the C response pattern when the network was prompted to give the B response pattern. This indicated that the A-C list apparently had overwritten the A-B list. This could be likened to learning the word dog, followed by learning the word stool and then finding that you think of the word stool when presented with the word dog.
McCloskey and Cohen tried to reduce interference through a number of manipulations including changing the number of hidden units, changing the value of the learning rate parameter, overtraining on the A-B list, freezing certain connection weights, changing target values 0 and 1 instead 0.1 and 0.9. However none of these manipulations satisfactorily reduced the catastrophic interference exhibited by the networks.
Overall, McCloskey and Cohen (1989) concluded that:
- at least some interference will occur whenever new learning alters the weights involved representing
- the greater the amount of new learning, the greater the disruption in old knowledge
- interference was catastrophic in the backpropagation networks when learning was sequential but not concurrent
Constraints Imposed by Learning and Forgetting Functions: Ratcliff (1990)
Ratcliff (1990) used multiple sets of backpropagation models applied to standard recognition memory procedures, in which the items were sequentially learned.[2] After inspecting the recognition performance models he found two major problems:
- Well-learned information was catastrophically forgotten as new information was learned in both small and large backpropagation networks.
Even one learning trial with new information resulted in a significant loss of the old information, paralleling the findings of McCloskey and Cohen (1989).[1] Ratcliff also found that the resulting outputs were often a blend of the previous input and the new input. In larger networks, items learned in groups (e.g. AB then CD) were more resistant to forgetting than were items learned singly (e.g. A then B then C...). However, the forgetting for items learned in groups was still large. Adding new hidden units to the network did not reduce interference.
- Discrimination between the studied items and previously unseen items decreased as the network learned more.
This finding contradicts with studies on human memory, which indicated that discrimination increases with learning. Ratcliff attempted to alleviate this problem by adding 'response nodes' that would selectively respond to old and new inputs. However, this method did not work as these response nodes would become active for all inputs. A model which used a context pattern also failed to increase discrimination between new and old items.
Proposed solutions
The main cause of catastrophic interference seems to be overlap in the representations at the hidden layer of distributed neural networks.[8][9][10] In a distributed representation, each input tends to create changes in the weights of many of the nodes. Catastrophic forgetting occurs because when many of the weights where "knowledge is stored" are changed, it is unlikely for prior knowledge to be kept intact. During sequential learning, the inputs become mixed, with the new inputs being superimposed on top of the old ones.[9] Another way to conceptualize this is by visualizing learning as a movement through a weight space.[11] This weight space can be likened to a spatial representation of all of the possible combinations of weights that the network could possess. When a network first learns to represent a set of patterns, it finds a point in the weight space that allows it to recognize all of those patterns.[10] However, when the network then learns a new set of patterns, it will move to a place in the weight space for which the only concern is the recognition of the new patterns.[10] To recognize both sets of patterns, the network must find a place in the weight space suitable for recognizing both the new and the old patterns.
Below are a number of techniques which have empirical support in successfully reducing catastrophic interference in backpropagation neural networks:
Orthogonality
Many of the early techniques in reducing representational overlap involved making either the input vectors or the hidden unit activation patterns orthogonal to one another. Lewandowsky and Li (1995)[12] noted that the interference between sequentially learned patterns is minimized if the input vectors are orthogonal to each other. Input vectors are said to be orthogonal to each other if the pairwise product of their elements across the two vectors sum to zero. For example, the patterns [0,0,1,0] and [0,1,0,0] are said to be orthogonal because (0×0 + 0×1 + 1×0 + 0×0) = 0. One of the techniques which can create orthogonal representations at the hidden layers involves bipolar feature coding (i.e., coding using -1 and 1 rather than 0 and 1).[10] Orthogonal patterns tend to produce less interference with each other. However, not all learning problems can be represented using these types of vectors and some studies report that the degree of interference is still problematic with orthogonal vectors.[2]
Node sharpening technique
According to French (1991),[8] catastrophic interference arises in feedforward backpropagation networks due to the interaction of node activations, or activation overlap, that occurs in distributed representations at the hidden layer. Neural networks that employ very localized representations do not show catastrophic interference because of the lack of overlap at the hidden layer. French therefore suggested that reducing the value of activation overlap at the hidden layer would reduce catastrophic interference in distributed networks. Specifically he proposed that this could be done through changing the distributed representations at the hidden layer to 'semi-distributed' representations. A 'semi-distributed' representation has fewer hidden nodes that are active, and/or a lower activation value for these nodes, for each representation, which will make the representations of the different inputs overlap less at the hidden layer. French recommended that this could be done through 'activation sharpening', a technique which slightly increases the activation of a certain number of the most active nodes in the hidden layer, slightly reduces the activation of all the other units and then changes the input-to-hidden layer weights to reflect these activation changes (similar to error backpropagation).
Novelty rule
Kortge (1990)[13] proposed a learning rule for training neural networks, called the 'novelty rule', to help alleviate catastrophic interference. As its name suggests, this rule helps the neural network to learn only the components of a new input that differ from an old input. Consequently, the novelty rule changes only the weights that were not previously dedicated to storing information, thereby reducing the overlap in representations at the hidden units. In order to apply the novelty rule, during learning the input pattern is replaced by a novelty vector that represents the components that differ. When the novelty rule is used in a standard backpropagation network there is no, or lessened, forgetting of old items when new items are presented sequentially.[13] However, a limitation is that this rule can only be used with auto-encoder or auto-associative networks, in which the target response for the output layer is identical to the input pattern.
Pre-training networks
McRae and Hetherington (1993)[9] argued that humans, unlike most neural networks, do not take on new learning tasks with a random set of weights. Rather, people tend to bring a wealth of prior knowledge to a task and this helps to avoid the problem of interference. They showed that when a network is pre-trained on a random sample of data prior to starting a sequential learning task that this prior knowledge will naturally constrain how the new information can be incorporated. This would occur because a random sample of data from a domain that has a high degree of internal structure, such as the English language, training would capture the regularities, or recurring patterns, found within that domain. Since the domain is based on regularities, a newly learned item will tend to be similar to the previously learned information, which will allow the network to incorporate new data with little interference with existing data. Specifically, an input vector that follows the same pattern of regularities as the previously trained data should not cause a drastically different pattern of activation at the hidden layer or drastically alter weights.
Rehearsal
Robins (1995)[14] described that catastrophic forgetting can be prevented by rehearsal mechanisms. This means that when new information is added, the neural network is retrained on some of the previously learned information. In general, however, previously learned information may not be available for such retraining. A solution for this is "pseudo-rehearsal", in which the network is not retrained on the actual previous data but on representations of them. Several methods are based upon this general mechanism.
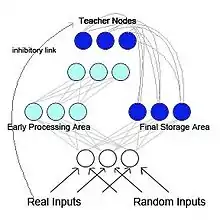
Pseudo-recurrent networks
French (1997) proposed a pseudo-recurrent backpropagation network (see Figure 2).[5] In this model the network is separated into two functionally distinct but interacting sub-networks. This model is biologically inspired and is based on research from McClelland et al. (1995)[15] McClelland and colleagues suggested that the hippocampus and neocortex act as separable but complementary memory systems, with the hippocampus for short term memory storage and the neocortex for long term memory storage. Information initially stored in the hippocampus can be "transferred" to the neocortex by means of reactivation or replay. In the pseudo-recurrent network, one of the sub-networks acts as an early processing area, akin to the hippocampus, and functions to learn new input patterns. The other sub-network acts as a final-storage area, akin to the neocortex. However, unlike in the McClelland et al. (1995) model, the final-storage area sends internally generated representation back to the early processing area. This creates a recurrent network. French proposed that this interleaving of old representations with new representations is the only way to reduce radical forgetting. Since the brain would most likely not have access to the original input patterns, the patterns that would be fed back to the neocortex would be internally generated representations called pseudo-patterns. These pseudo-patterns are approximations of previous inputs[14] and they can be interleaved with the learning of new inputs.
Self-refreshing memory
Inspired by[14] and independently of[5] Ans and Rousset (1997)[16] also proposed a two-network artificial neural architecture with memory self-refreshing that overcomes catastrophic interference when sequential learning tasks are carried out in distributed networks trained by backpropagation. The principle is to learn new external patterns concurrently with internally generated pseudopatterns, or 'pseudo-memories', that reflect the previously learned information. What mainly distinguishes this model from those that use classical pseudorehearsal[14][5] in feedforward multilayer networks is a reverberating process that is used for generating pseudopatterns. After a number of activity re-injections from a single random seed, this process tends to go up to nonlinear network attractors that are more suitable for capturing optimally the deep structure of knowledge distributed within connection weights than the single feedforward pass of activity used in pseudo-rehearsal. The memory self-refreshing procedure turned out to be very efficient in transfer processes[17] and in serial learning of temporal sequences of patterns without catastrophic forgetting.[18]
Generative replay
In recent years, pseudo-rehearsal has re-gained in popularity thanks to the progress in the capabilities of deep generative models. When such deep generative models are used to generate the "pseudo-data" to be rehearsed, this method is typically referred to as generative replay.[19] Such generative replay can effectively prevent catastrophic forgetting, especially when the replay is performed in the hidden layers rather than at the input level.[20][21]
Spontaneous replay
The insights into the mechanisms of memory consolidation during the sleep processes in human and animal brain led to other biologically inspired approaches. While declarative memories are in the classical picture consolidated by hippocampo-neocortical dialog during NREM phase of sleep (see above), some types of procedural memories were suggested not to rely on the hippocampus and involve REM phase of the sleep (e.g.[22], but see[23] for the complexity of the topic). This inspired models where internal representations (memories) created by previous learning are spontaneously replayed during sleep-like periods in the network itself[24][25] (i.e. without help of secondary network performed by generative replay approaches mentioned above).
Latent learning
Latent Learning is a technique used by Gutstein & Stump (2015)[26] to mitigate catastrophic interference by taking advantage of transfer learning. This approach tries to find optimal encodings for any new classes to be learned, so that they are least likely to catastrophically interfere with existing responses. Given a network that has learned to discriminate among one set of classes using Error Correcting Output Codes (ECOC)[27] (as opposed to 1 hot codes), optimal encodings for new classes are chosen by observing the network's average responses to them. Since these average responses arose while learning the original set of classes without any exposure to the new classes, they are referred to as 'Latently Learned Encodings'. This terminology borrows from the concept of Latent Learning, as introduced by Tolman in 1930.[28] In effect, this technique uses transfer learning to avoid catastrophic interference, by making a network's responses to new classes as consistent as possible with existing responses to classes already learned.
Elastic weight consolidation
Kirkpatrick et al. (2017)[29] proposed elastic weight consolidation (EWC), a method to sequentially train a single artificial neural network on multiple tasks. This technique supposes that some weights of the trained neural network are more important for previously learned tasks than others. During training of the neural network on a new task, changes to the weights of the network are made less likely the greater their importance. To estimate the importance of the network weights, EWC uses probabilistic mechanisms, in particular the Fisher information matrix, but this can be done in other ways as well.[30][31][32]
References
- McCloskey, Michael; Cohen, Neal J. (1989). Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. Psychology of Learning and Motivation. Vol. 24. pp. 109–165. doi:10.1016/S0079-7421(08)60536-8. ISBN 978-0-12-543324-2.
- Ratcliff, Roger (1990). "Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions". Psychological Review. 97 (2): 285–308. doi:10.1037/0033-295x.97.2.285. PMID 2186426. S2CID 18556305.
- Hebb, Donald Olding (1949). The Organization of Behavior: A Neuropsychological Theory. Wiley. ISBN 978-0-471-36727-7. OCLC 569043119.
- Carpenter, Gail A.; Grossberg, Stephen (1 December 1987). "ART 2: self-organization of stable category recognition codes for analog input patterns". Applied Optics. 26 (23): 4919–4930. Bibcode:1987ApOpt..26.4919C. doi:10.1364/AO.26.004919. PMID 20523470.
- French, Robert M (December 1997). "Pseudo-recurrent Connectionist Networks: An Approach to the 'Sensitivity-Stability' Dilemma". Connection Science. 9 (4): 353–380. doi:10.1080/095400997116595.
- González, Oscar C; Sokolov, Yury; Krishnan, Giri P; Delanois, Jean Erik; Bazhenov, Maxim (4 August 2020). "Can sleep protect memories from catastrophic forgetting?". eLife. 9: e51005. doi:10.7554/eLife.51005. PMC 7440920. PMID 32748786.
- Barnes, Jean M.; Underwood, Benton J. (August 1959). "'Fate' of first-list associations in transfer theory". Journal of Experimental Psychology. 58 (2): 97–105. doi:10.1037/h0047507. PMID 13796886.
- French, Robert M. (1991). Using Semi-Distributed Representations to Overcome Catastrophic Forgetting in Connectionist Networks (PDF). Proceedings of the 13th Annual Cognitive Science Society Conference. New Jersey: Lawrence Erlbaum. pp. 173–178. CiteSeerX 10.1.1.1040.3564.
- "Catastrophic Interference is Eliminated in Pre-Trained Networks". Proceedings of the Fifteenth Annual Conference of the Cognitive Science Society: June 18 to 21, 1993, Institute of Cognitive Science, University of Colorado-Boulder. Psychology Press. 1993. pp. 723–728. ISBN 978-0-8058-1487-3.
- French, R (1 April 1999). "Catastrophic forgetting in connectionist networks". Trends in Cognitive Sciences. 3 (4): 128–135. doi:10.1016/S1364-6613(99)01294-2. PMID 10322466. S2CID 2691726.
- Lewandowsky, Stephan (1991). "Gradual unlearning and catastrophic interference: a comparison of distributed architectures". In Hockley, William E.; Lewandowsky, Stephan (eds.). Relating Theory and Data: Essays on Human Memory in Honor of Bennet B. Murdock. Psychology Press. pp. 445–476. ISBN 978-1-317-76013-9.
- Lewandowsky, Stephan; Li, Shu-Chen (1995). "Catastrophic interference in neural networks". Interference and Inhibition in Cognition. pp. 329–361. doi:10.1016/B978-012208930-5/50011-8. ISBN 978-0-12-208930-5.
- Kortge, C. A. (1990). Episodic memory in connectionist networks. In: The Twelfth Annual Conference of the Cognitive Science Society, (pp. 764-771). Hillsdale, NJ: Lawrence Erlbaum.
- Robins, Anthony (June 1995). "Catastrophic Forgetting, Rehearsal and Pseudorehearsal". Connection Science. 7 (2): 123–146. doi:10.1080/09540099550039318. S2CID 22882861.
- McClelland, James L.; McNaughton, Bruce L.; O'Reilly, Randall C. (July 1995). "Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory". Psychological Review. 102 (3): 419–457. doi:10.1037/0033-295X.102.3.419. PMID 7624455. S2CID 2832081.
- Ans, Bernard; Rousset, Stéphane (December 1997). "Avoiding catastrophic forgetting by coupling two reverberating neural networks". Comptes Rendus de l'Académie des Sciences, Série III. 320 (12): 989–997. Bibcode:1997CRASG.320..989A. doi:10.1016/S0764-4469(97)82472-9.
- Ans, Bernard; Rousset, Stéphane (March 2000). "Neural networks with a self-refreshing memory: Knowledge transfer in sequential learning tasks without catastrophic forgetting". Connection Science. 12 (1): 1–19. doi:10.1080/095400900116177. S2CID 7019649.
- Ans, Bernard; Rousset, Stéphane; French, Robert M.; Musca, Serban (June 2004). "Self-refreshing memory in artificial neural networks: learning temporal sequences without catastrophic forgetting". Connection Science. 16 (2): 71–99. doi:10.1080/09540090412331271199. S2CID 13462914.
- Mocanu, Decebal Constantin; Torres Vega, Maria; Eaton, Eric; Stone, Peter; Liotta, Antonio (18 October 2016). "Online Contrastive Divergence with Generative Replay: Experience Replay without Storing Data". arXiv:1610.05555 [cs.LG].
- Shin, Hanul; Lee, Jung Kwon; Kim, Jaehong; Kim, Jiwon (December 2017). Continual learning with deep generative replay. NIPS'17: Proceedings of the 31st International Conference on Neural Information Processing Systems. Curran Associates. pp. 2994–3003. ISBN 978-1-5108-6096-4.
- van de Ven, Gido M.; Siegelmann, Hava T.; Tolias, Andreas S. (13 August 2020). "Brain-inspired replay for continual learning with artificial neural networks". Nature Communications. 11 (1): 4069. Bibcode:2020NatCo..11.4069V. doi:10.1038/s41467-020-17866-2. PMC 7426273. PMID 32792531.
- McDevitt, Elizabeth A.; Duggan, Katherine A.; Mednick, Sara C. (2015-07-01). "REM sleep rescues learning from interference". Neurobiology of Learning and Memory. REM Sleep and Memory. 122: 51–62. doi:10.1016/j.nlm.2014.11.015. ISSN 1074-7427. PMC 4704701. PMID 25498222.
- MacDonald, Kevin J.; Cote, Kimberly A. (2021-10-01). "Contributions of post-learning REM and NREM sleep to memory retrieval". Sleep Medicine Reviews. 59: 101453. doi:10.1016/j.smrv.2021.101453. ISSN 1087-0792.
- Golden, Ryan; Delanois, Jean Erik; Sanda, Pavel; Bazhenov, Maxim (2022-11-18). "Sleep prevents catastrophic forgetting in spiking neural networks by forming a joint synaptic weight representation". PLOS Computational Biology. 18 (11): e1010628. doi:10.1371/journal.pcbi.1010628. ISSN 1553-7358. PMC 9674146. PMID 36399437.
- Tadros, Timothy; Krishnan, Giri P.; Ramyaa, Ramyaa; Bazhenov, Maxim (2022-12-15). "Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks". Nature Communications. 13 (1): 7742. doi:10.1038/s41467-022-34938-7. ISSN 2041-1723. PMC 9755223. PMID 36522325.
- Gutstein, Steven; Stump, Ethan (2015). "Reduction of catastrophic forgetting with transfer learning and ternary output codes". 2015 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. doi:10.1109/IJCNN.2015.7280416. ISBN 978-1-4799-1960-4. S2CID 18745466.
- Dietterich, T. G.; Bakiri, G. (1 January 1995). "Solving Multiclass Learning Problems via Error-Correcting Output Codes". Journal of Artificial Intelligence Research. 2: 263–286. doi:10.1613/jair.105. S2CID 47109072.
- Tolman, E.C.; Honzik, C.H. (1930). "'Insight' in Rats". Publications in Psychology. University of California. 4: 215–232.
- Kirkpatrick, James; Pascanu, Razvan; Rabinowitz, Neil; Veness, Joel; Desjardins, Guillaume; Rusu, Andrei A.; Milan, Kieran; Quan, John; Ramalho, Tiago; Grabska-Barwinska, Agnieszka; Hassabis, Demis; Clopath, Claudia; Kumaran, Dharshan; Hadsell, Raia (14 March 2017). "Overcoming catastrophic forgetting in neural networks". Proceedings of the National Academy of Sciences. 114 (13): 3521–3526. arXiv:1612.00796. Bibcode:2017PNAS..114.3521K. doi:10.1073/pnas.1611835114. PMC 5380101. PMID 28292907.
- Zenke, Friedemann; Poole, Ben; Ganguli, Surya (2017). "Continual Learning Through Synaptic Intelligence". Proceedings of Machine Learning Research. 70: 3987–3995. arXiv:1703.04200. PMC 6944509. PMID 31909397.
- Aljundi, Rahaf; Babiloni, Francesca; Elhoseiny, Mohamed; Rohrbach, Marcus; Tuytelaars, Tinne (2018). "Memory Aware Synapses: Learning What (Not) to Forget". Computer Vision – ECCV 2018. Lecture Notes in Computer Science. Vol. 11207. pp. 144–161. arXiv:1711.09601. doi:10.1007/978-3-030-01219-9_9. ISBN 978-3-030-01218-2. S2CID 4254748.
- Kutalev, Alexey (2020). "Natural Way to Overcome Catastrophic Forgetting in Neural Networks". Modern Information Technologies and IT-Education. 16 (2): 331–337. arXiv:2005.07107. doi:10.25559/SITITO.16.202002.331-337. S2CID 218628670.