Cholesky decomposition
In linear algebra, the Cholesky decomposition or Cholesky factorization (pronounced /ʃəˈlɛski/ shə-LES-kee) is a decomposition of a Hermitian, positive-definite matrix into the product of a lower triangular matrix and its conjugate transpose, which is useful for efficient numerical solutions, e.g., Monte Carlo simulations. It was discovered by André-Louis Cholesky for real matrices, and posthumously published in 1924.[1] When it is applicable, the Cholesky decomposition is roughly twice as efficient as the LU decomposition for solving systems of linear equations.[2]
Statement
The Cholesky decomposition of a Hermitian positive-definite matrix A, is a decomposition of the form

where L is a lower triangular matrix with real and positive diagonal entries, and L* denotes the conjugate transpose of L. Every Hermitian positive-definite matrix (and thus also every real-valued symmetric positive-definite matrix) has a unique Cholesky decomposition.[3]
The converse holds trivially: if A can be written as LL* for some invertible L, lower triangular or otherwise, then A is Hermitian and positive definite.
When A is a real matrix (hence symmetric positive-definite), the factorization may be written

where L is a real lower triangular matrix with positive diagonal entries.[4][5][6]
Positive semidefinite matrices
If a Hermitian matrix A is only positive semidefinite, instead of positive definite, then it still has a decomposition of the form A = LL* where the diagonal entries of L are allowed to be zero.[7] The decomposition need not be unique, for example:

However, if the rank of A is r, then there is a unique lower triangular L with exactly r positive diagonal elements and n−r columns containing all zeroes.[8]
Alternatively, the decomposition can be made unique when a pivoting choice is fixed. Formally, if A is an n × n positive semidefinite matrix of rank r, then there is at least one permutation matrix P such that P A PT has a unique decomposition of the form P A PT = L L* with , where L1 is an r × r lower triangular matrix with positive diagonal.[9]

LDL decomposition
A closely related variant of the classical Cholesky decomposition is the LDL decomposition,

where L is a lower unit triangular (unitriangular) matrix, and D is a diagonal matrix. That is, the diagonal elements of L are required to be 1 at the cost of introducing an additional diagonal matrix D in the decomposition. The main advantage is that the LDL decomposition can be computed and used with essentially the same algorithms, but avoids extracting square roots.[10]
For this reason, the LDL decomposition is often called the square-root-free Cholesky decomposition. For real matrices, the factorization has the form A = LDLT and is often referred to as LDLT decomposition (or LDLT decomposition, or LDL′). It is reminiscent of the eigendecomposition of real symmetric matrices, A = QΛQT, but is quite different in practice because Λ and D are not similar matrices.
The LDL decomposition is related to the classical Cholesky decomposition of the form LL* as follows:

Conversely, given the classical Cholesky decomposition of a positive definite matrix, if S is a diagonal matrix that contains the main diagonal of , then A can be decomposed as where



- (this rescales each column to make diagonal elements 1),


If A is positive definite then the diagonal elements of D are all positive. For positive semidefinite A, an decomposition exists where the number of non-zero elements on the diagonal D is exactly the rank of A.[11] Some indefinite matrices for which no Cholesky decomposition exists have an LDL decomposition with negative entries in D: it suffices that the first n−1 leading principal minors of A are non-singular.[12]
Example
Here is the Cholesky decomposition of a symmetric real matrix:

And here is its LDLT decomposition:

Geometric interpretation
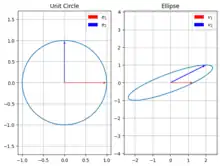



The Cholesky decomposition is equivalent to a particular choice of conjugate axes of an ellipsoid.[13] In detail, let the ellipsoid be defined as , then by definition, a set of vectors are conjugate axes of the ellipsoid iff . Then, the ellipsoid is precisely




where maps the basis vector , and is the unit sphere in n dimensions. That is, the ellipsoid is a linear image of the unit sphere.



Define the matrix , then is equivalent to . Different choices of the conjugate axes correspond to different decompositions.
![{\displaystyle V:=[v_{1}|v_{2}|\cdots |v_{n}]}](../I/41bc54f9a425fc60149fb1c4396380f5e4e6f7ff.svg)

The Cholesky decomposition corresponds to choosing to be parallel to the first axis, to be within the plane spanned by the first two axes, and so on. This makes an upper-triangular matrix. Then, there is , where is lower-triangular.



Similarly, principal component analysis corresponds to choosing to be perpendicular. Then, let and , and there is where is an orthogonal matrix. This then yields .





Applications
The Cholesky decomposition is mainly used for the numerical solution of linear equations . If A is symmetric and positive definite, then can be solved by first computing the Cholesky decomposition , then solving for y by forward substitution, and finally solving for x by back substitution.




An alternative way to eliminate taking square roots in the decomposition is to compute the LDL decomposition , then solving for y, and finally solving .



For linear systems that can be put into symmetric form, the Cholesky decomposition (or its LDL variant) is the method of choice, for superior efficiency and numerical stability. Compared to the LU decomposition, it is roughly twice as efficient.[2]
Linear least squares
Systems of the form Ax = b with A symmetric and positive definite arise quite often in applications. For instance, the normal equations in linear least squares problems are of this form. It may also happen that matrix A comes from an energy functional, which must be positive from physical considerations; this happens frequently in the numerical solution of partial differential equations.
Non-linear optimization
Non-linear multi-variate functions may be minimized over their parameters using variants of Newton's method called quasi-Newton methods. At iteration k, the search steps in a direction defined by solving for , where is the step direction, is the gradient, and is an approximation to the Hessian matrix formed by repeating rank-1 updates at each iteration. Two well-known update formulas are called Davidon–Fletcher–Powell (DFP) and Broyden–Fletcher–Goldfarb–Shanno (BFGS). Loss of the positive-definite condition through round-off error is avoided if rather than updating an approximation to the inverse of the Hessian, one updates the Cholesky decomposition of an approximation of the Hessian matrix itself .[14]




Monte Carlo simulation
The Cholesky decomposition is commonly used in the Monte Carlo method for simulating systems with multiple correlated variables. The covariance matrix is decomposed to give the lower-triangular L. Applying this to a vector of uncorrelated samples u produces a sample vector Lu with the covariance properties of the system being modeled.[15]
The following simplified example shows the economy one gets from the Cholesky decomposition: suppose the goal is to generate two correlated normal variables and with given correlation coefficient . To accomplish that, it is necessary to first generate two uncorrelated Gaussian random variables and , which can be done using a Box–Muller transform. Given the required correlation coefficient , the correlated normal variables can be obtained via the transformations and .







Kalman filters
Unscented Kalman filters commonly use the Cholesky decomposition to choose a set of so-called sigma points. The Kalman filter tracks the average state of a system as a vector x of length N and covariance as an N × N matrix P. The matrix P is always positive semi-definite and can be decomposed into LLT. The columns of L can be added and subtracted from the mean x to form a set of 2N vectors called sigma points. These sigma points completely capture the mean and covariance of the system state.
Matrix inversion
The explicit inverse of a Hermitian matrix can be computed by Cholesky decomposition, in a manner similar to solving linear systems, using operations ( multiplications).[10] The entire inversion can even be efficiently performed in-place.


A non-Hermitian matrix B can also be inverted using the following identity, where BB* will always be Hermitian:

Computation
There are various methods for calculating the Cholesky decomposition. The computational complexity of commonly used algorithms is O(n3) in general. The algorithms described below all involve about (1/3)n3 FLOPs (n3/6 multiplications and the same number of additions) for real flavors and (4/3)n3 FLOPs for complex flavors,[16] where n is the size of the matrix A. Hence, they have half the cost of the LU decomposition, which uses 2n3/3 FLOPs (see Trefethen and Bau 1997).
Which of the algorithms below is faster depends on the details of the implementation. Generally, the first algorithm will be slightly slower because it accesses the data in a less regular manner.
The Cholesky algorithm
The Cholesky algorithm, used to calculate the decomposition matrix L, is a modified version of Gaussian elimination.
The recursive algorithm starts with i := 1 and
- A(1) := A.
At step i, the matrix A(i) has the following form:

where Ii−1 denotes the identity matrix of dimension i − 1.
If the matrix Li is defined by

(note that ai,i > 0 since A(i) is positive definite), then A(i) can be written as

where

Note that bi b*i is an outer product, therefore this algorithm is called the outer-product version in (Golub & Van Loan).
This is repeated for i from 1 to n. After n steps, A(n+1) = I is obtained, and hence, the lower triangular matrix L sought for is calculated as

The Cholesky–Banachiewicz and Cholesky–Crout algorithms

If the equation
![{\displaystyle {\begin{aligned}\mathbf {A} =\mathbf {LL} ^{T}&={\begin{pmatrix}L_{11}&0&0\\L_{21}&L_{22}&0\\L_{31}&L_{32}&L_{33}\\\end{pmatrix}}{\begin{pmatrix}L_{11}&L_{21}&L_{31}\\0&L_{22}&L_{32}\\0&0&L_{33}\end{pmatrix}}\\[8pt]&={\begin{pmatrix}L_{11}^{2}&&({\text{symmetric}})\\L_{21}L_{11}&L_{21}^{2}+L_{22}^{2}&\\L_{31}L_{11}&L_{31}L_{21}+L_{32}L_{22}&L_{31}^{2}+L_{32}^{2}+L_{33}^{2}\end{pmatrix}},\end{aligned}}}](../I/1698aea6d96c9be0ed8606821c0e07abc9487154.svg)
is written out, the following is obtained:

and therefore the following formulas for the entries of L:


For complex and real matrices, inconsequential arbitrary sign changes of diagonal and associated off-diagonal elements are allowed. The expression under the square root is always positive if A is real and positive-definite.
For complex Hermitian matrix, the following formula applies:


So it now is possible to compute the (i, j) entry if the entries to the left and above are known. The computation is usually arranged in either of the following orders:
- The Cholesky–Banachiewicz algorithm starts from the upper left corner of the matrix L and proceeds to calculate the matrix row by row.
for (i = 0; i < dimensionSize; i++) {
for (j = 0; j <= i; j++) {
float sum = 0;
for (k = 0; k < j; k++)
sum += L[i][k] * L[j][k];
if (i == j)
L[i][j] = sqrt(A[i][i] - sum);
else
L[i][j] = (1.0 / L[j][j] * (A[i][j] - sum));
}
}
The above algorithm can be succinctly expressed as combining a dot product and matrix multiplication in vectorized programming languages such as Fortran as the following,
do i = 1, size(A,1)
L(i,i) = sqrt(A(i,i) - dot_product(L(i,1:i-1), L(i,1:i-1)))
L(i+1:,i) = (A(i+1:,i) - matmul(conjg(L(i,1:i-1)), L(i+1:,1:i-1))) / L(i,i)
end do
where conjg refers to complex conjugate of the elements.
- The Cholesky–Crout algorithm starts from the upper left corner of the matrix L and proceeds to calculate the matrix column by column.
for (j = 0; j < dimensionSize; j++) { float sum = 0; for (k = 0; k < j; k++) { sum += L[j][k] * L[j][k]; } L[j][j] = sqrt(A[j][j] - sum); for (i = j + 1; i < dimensionSize; i++) { sum = 0; for (k = 0; k < j; k++) { sum += L[i][k] * L[j][k]; } L[i][j] = (1.0 / L[j][j] * (A[i][j] - sum)); } }
The above algorithm can be succinctly expressed as combining a dot product and matrix multiplication in vectorized programming languages such as Fortran as the following,
do i = 1, size(A,1)
L(i,i) = sqrt(A(i,i) - dot_product(L(1:i-1,i), L(1:i-1,i)))
L(i,i+1:) = (A(i,i+1:) - matmul(conjg(L(1:i-1,i)), L(1:i-1,i+1:))) / L(i,i)
end do
where conjg refers to complex conjugate of the elements.
Either pattern of access allows the entire computation to be performed in-place if desired.
Stability of the computation
Suppose that there is a desire to solve a well-conditioned system of linear equations. If the LU decomposition is used, then the algorithm is unstable unless some sort of pivoting strategy is used. In the latter case, the error depends on the so-called growth factor of the matrix, which is usually (but not always) small.
Now, suppose that the Cholesky decomposition is applicable. As mentioned above, the algorithm will be twice as fast. Furthermore, no pivoting is necessary, and the error will always be small. Specifically, if Ax = b, and y denotes the computed solution, then y solves the perturbed system (A + E)y = b, where

Here ||·||2 is the matrix 2-norm, cn is a small constant depending on n, and ε denotes the unit round-off.
One concern with the Cholesky decomposition to be aware of is the use of square roots. If the matrix being factorized is positive definite as required, the numbers under the square roots are always positive in exact arithmetic. Unfortunately, the numbers can become negative because of round-off errors, in which case the algorithm cannot continue. However, this can only happen if the matrix is very ill-conditioned. One way to address this is to add a diagonal correction matrix to the matrix being decomposed in an attempt to promote the positive-definiteness.[17] While this might lessen the accuracy of the decomposition, it can be very favorable for other reasons; for example, when performing Newton's method in optimization, adding a diagonal matrix can improve stability when far from the optimum.
LDL decomposition
An alternative form, eliminating the need to take square roots when A is symmetric, is the symmetric indefinite factorization[18]
![{\displaystyle {\begin{aligned}\mathbf {A} =\mathbf {LDL} ^{\mathrm {T} }&={\begin{pmatrix}1&0&0\\L_{21}&1&0\\L_{31}&L_{32}&1\\\end{pmatrix}}{\begin{pmatrix}D_{1}&0&0\\0&D_{2}&0\\0&0&D_{3}\\\end{pmatrix}}{\begin{pmatrix}1&L_{21}&L_{31}\\0&1&L_{32}\\0&0&1\\\end{pmatrix}}\\[8pt]&={\begin{pmatrix}D_{1}&&(\mathrm {symmetric} )\\L_{21}D_{1}&L_{21}^{2}D_{1}+D_{2}&\\L_{31}D_{1}&L_{31}L_{21}D_{1}+L_{32}D_{2}&L_{31}^{2}D_{1}+L_{32}^{2}D_{2}+D_{3}.\end{pmatrix}}.\end{aligned}}}](../I/6d868f0fc4a5a5f40e7e850e5b160e9b4db76333.svg)
The following recursive relations apply for the entries of D and L:


This works as long as the generated diagonal elements in D stay non-zero. The decomposition is then unique. D and L are real if A is real.
For complex Hermitian matrix A, the following formula applies:


Again, the pattern of access allows the entire computation to be performed in-place if desired.
Block variant
When used on indefinite matrices, the LDL* factorization is known to be unstable without careful pivoting;[19] specifically, the elements of the factorization can grow arbitrarily. A possible improvement is to perform the factorization on block sub-matrices, commonly 2 × 2:[20]
![{\displaystyle {\begin{aligned}\mathbf {A} =\mathbf {LDL} ^{\mathrm {T} }&={\begin{pmatrix}\mathbf {I} &0&0\\\mathbf {L} _{21}&\mathbf {I} &0\\\mathbf {L} _{31}&\mathbf {L} _{32}&\mathbf {I} \\\end{pmatrix}}{\begin{pmatrix}\mathbf {D} _{1}&0&0\\0&\mathbf {D} _{2}&0\\0&0&\mathbf {D} _{3}\\\end{pmatrix}}{\begin{pmatrix}\mathbf {I} &\mathbf {L} _{21}^{\mathrm {T} }&\mathbf {L} _{31}^{\mathrm {T} }\\0&\mathbf {I} &\mathbf {L} _{32}^{\mathrm {T} }\\0&0&\mathbf {I} \\\end{pmatrix}}\\[8pt]&={\begin{pmatrix}\mathbf {D} _{1}&&(\mathrm {symmetric} )\\\mathbf {L} _{21}\mathbf {D} _{1}&\mathbf {L} _{21}\mathbf {D} _{1}\mathbf {L} _{21}^{\mathrm {T} }+\mathbf {D} _{2}&\\\mathbf {L} _{31}\mathbf {D} _{1}&\mathbf {L} _{31}\mathbf {D} _{1}\mathbf {L} _{21}^{\mathrm {T} }+\mathbf {L} _{32}\mathbf {D} _{2}&\mathbf {L} _{31}\mathbf {D} _{1}\mathbf {L} _{31}^{\mathrm {T} }+\mathbf {L} _{32}\mathbf {D} _{2}\mathbf {L} _{32}^{\mathrm {T} }+\mathbf {D} _{3}\end{pmatrix}},\end{aligned}}}](../I/4fbf0e24f33c7f7d431f83dad4a5fc95e2b0b3cc.svg)
where every element in the matrices above is a square submatrix. From this, these analogous recursive relations follow:


This involves matrix products and explicit inversion, thus limiting the practical block size.
Updating the decomposition
A task that often arises in practice is that one needs to update a Cholesky decomposition. In more details, one has already computed the Cholesky decomposition of some matrix , then one changes the matrix in some way into another matrix, say , and one wants to compute the Cholesky decomposition of the updated matrix: . The question is now whether one can use the Cholesky decomposition of that was computed before to compute the Cholesky decomposition of .




Rank-one update
The specific case, where the updated matrix is related to the matrix by , is known as a rank-one update.

Here is a function[21] written in Matlab syntax that realizes a rank-one update:
function [L] = cholupdate(L, x)
n = length(x);
for k = 1:n
r = sqrt(L(k, k)^2 + x(k)^2);
c = r / L(k, k);
s = x(k) / L(k, k);
L(k, k) = r;
if k < n
L((k+1):n, k) = (L((k+1):n, k) + s * x((k+1):n)) / c;
x((k+1):n) = c * x((k+1):n) - s * L((k+1):n, k);
end
end
end
A rank-n update is one where for a matrix one updates the decomposition such that . This can be achieved by successively performing rank-one updates for each of the columns of .


Rank-one downdate
A rank-one downdate is similar to a rank-one update, except that the addition is replaced by subtraction: . This only works if the new matrix is still positive definite.

The code for the rank-one update shown above can easily be adapted to do a rank-one downdate: one merely needs to replace the two additions in the assignment to r and L((k+1):n, k) by subtractions.
Adding and removing rows and columns
If a symmetric and positive definite matrix is represented in block form as

and its upper Cholesky factor

then for a new matrix , which is the same as but with the insertion of new rows and columns,

Now there is an interest in finding the Cholesky factorization of , which can be called , without directly computing the entire decomposition.


Writing for the solution of , which can be found easily for triangular matrices, and for the Cholesky decomposition of , the following relations can be found:




These formulas may be used to determine the Cholesky factor after the insertion of rows or columns in any position, if the row and column dimensions are appropriately set (including to zero). The inverse problem,
with known Cholesky decomposition

and the desire to determine the Cholesky factor

of the matrix with rows and columns removed,

yields the following rules:

Notice that the equations above that involve finding the Cholesky decomposition of a new matrix are all of the form , which allows them to be efficiently calculated using the update and downdate procedures detailed in the previous section.[22]

Proof for positive semi-definite matrices
Proof by limiting argument
The above algorithms show that every positive definite matrix has a Cholesky decomposition. This result can be extended to the positive semi-definite case by a limiting argument. The argument is not fully constructive, i.e., it gives no explicit numerical algorithms for computing Cholesky factors.
If is an positive semi-definite matrix, then the sequence consists of positive definite matrices. (This is an immediate consequence of, for example, the spectral mapping theorem for the polynomial functional calculus.) Also,



in operator norm. From the positive definite case, each has Cholesky decomposition . By property of the operator norm,



The holds because equipped with the operator norm is a C* algebra. So is a bounded set in the Banach space of operators, therefore relatively compact (because the underlying vector space is finite-dimensional). Consequently, it has a convergent subsequence, also denoted by , with limit . It can be easily checked that this has the desired properties, i.e. , and is lower triangular with non-negative diagonal entries: for all and ,







Therefore, . Because the underlying vector space is finite-dimensional, all topologies on the space of operators are equivalent. So tends to in norm means tends to entrywise. This in turn implies that, since each is lower triangular with non-negative diagonal entries, is also.

Proof by QR decomposition
Let be a positive semi-definite Hermitian matrix. Then it can be written as a product of its square root matrix, . Now QR decomposition can be applied to , resulting in , where is unitary and is upper triangular. Inserting the decomposition into the original equality yields . Setting completes the proof.







Generalization
The Cholesky factorization can be generalized to (not necessarily finite) matrices with operator entries. Let be a sequence of Hilbert spaces. Consider the operator matrix


acting on the direct sum

where each

is a bounded operator. If A is positive (semidefinite) in the sense that for all finite k and for any

there is , then there exists a lower triangular operator matrix L such that A = LL*. One can also take the diagonal entries of L to be positive.

Implementations in programming libraries
- C programming language: the GNU Scientific Library provides several implementations of Cholesky decomposition.
- Maxima computer algebra system: function
choleskycomputes Cholesky decomposition. - GNU Octave numerical computations system provides several functions to calculate, update, and apply a Cholesky decomposition.
- The LAPACK library provides a high performance implementation of the Cholesky decomposition that can be accessed from Fortran, C and most languages.
- In Python, the function
choleskyfrom thenumpy.linalgmodule performs Cholesky decomposition. - In Matlab, the
cholfunction gives the Cholesky decomposition. Note thatcholuses the upper triangular factor of the input matrix by default, i.e. it computes where is upper triangular. A flag can be passed to use the lower triangular factor instead. - In R, the
cholfunction gives the Cholesky decomposition. - In Julia, the
choleskyfunction from theLinearAlgebrastandard library gives the Cholesky decomposition. - In Mathematica, the function "
CholeskyDecomposition" can be applied to a matrix. - In C++, multiple linear algebra libraries support this decomposition:
- The Armadillo (C++ library) supplies the command
cholto perform Cholesky decomposition. - The Eigen library supplies Cholesky factorizations for both sparse and dense matrices.
- In the ROOT package, the
TDecompCholclass is available.
- The Armadillo (C++ library) supplies the command


- In Analytica, the function
Decomposegives the Cholesky decomposition. - The Apache Commons Math library has an implementation which can be used in Java, Scala and any other JVM language.
See also
Notes
- Benoit (1924). "Note sur une méthode de résolution des équations normales provenant de l'application de la méthode des moindres carrés à un système d'équations linéaires en nombre inférieur à celui des inconnues (Procédé du Commandant Cholesky)". Bulletin Géodésique (in French). 2: 66–67. doi:10.1007/BF03031308.
- Press, William H.; Saul A. Teukolsky; William T. Vetterling; Brian P. Flannery (1992). Numerical Recipes in C: The Art of Scientific Computing (second ed.). Cambridge University England EPress. p. 994. ISBN 0-521-43108-5. Retrieved 2009-01-28.
- Golub & Van Loan (1996, p. 143), Horn & Johnson (1985, p. 407), Trefethen & Bau (1997, p. 174).
- Horn & Johnson (1985, p. 407).
- "matrices - Diagonalizing a Complex Symmetric Matrix". MathOverflow. Retrieved 2020-01-25.
- Schabauer, Hannes; Pacher, Christoph; Sunderland, Andrew G.; Gansterer, Wilfried N. (2010-05-01). "Toward a parallel solver for generalized complex symmetric eigenvalue problems". Procedia Computer Science. ICCS 2010. 1 (1): 437–445. doi:10.1016/j.procs.2010.04.047. ISSN 1877-0509.
- Golub & Van Loan (1996, p. 147).
- Gentle, James E. (1998). Numerical Linear Algebra for Applications in Statistics. Springer. p. 94. ISBN 978-1-4612-0623-1.
- Higham, Nicholas J. (1990). "Analysis of the Cholesky Decomposition of a Semi-definite Matrix". In Cox, M. G.; Hammarling, S. J. (eds.). Reliable Numerical Computation. Oxford, UK: Oxford University Press. pp. 161–185. ISBN 978-0-19-853564-5.
- Krishnamoorthy, Aravindh; Menon, Deepak (2011). "Matrix Inversion Using Cholesky Decomposition". 1111: 4144. arXiv:1111.4144. Bibcode:2011arXiv1111.4144K.
{{cite journal}}: Cite journal requires|journal=(help) - So, Anthony Man-Cho (2007). A Semidefinite Programming Approach to the Graph Realization Problem: Theory, Applications and Extensions (PDF) (PhD). Theorem 2.2.6.
- Golub & Van Loan (1996, Theorem 4.1.3)
- Pope, Stephen B. "Algorithms for ellipsoids." Cornell University Report No. FDA (2008): 08-01.
- Arora, J.S. Introduction to Optimum Design (2004), p. 327. https://books.google.com/books?id=9FbwVe577xwC&pg=PA327
- Matlab randn documentation. mathworks.com.
- ?potrf Intel® Math Kernel Library
- Fang, Haw-ren; O'Leary, Dianne P. (8 August 2006). "Modified Cholesky Algorithms: A Catalog with New Approaches" (PDF).
{{cite journal}}: Cite journal requires|journal=(help) - Watkins, D. (1991). Fundamentals of Matrix Computations. New York: Wiley. p. 84. ISBN 0-471-61414-9.
- Nocedal, Jorge (2000). Numerical Optimization. Springer.
- Fang, Haw-ren (24 August 2007). "Analysis of Block LDLT Factorizations for Symmetric Indefinite Matrices".
{{cite journal}}: Cite journal requires|journal=(help) - Based on: Stewart, G. W. (1998). Basic decompositions. Philadelphia: Soc. for Industrial and Applied Mathematics. ISBN 0-89871-414-1.
- Osborne, M. (2010), Appendix B.
References
- Dereniowski, Dariusz; Kubale, Marek (2004). "Cholesky Factorization of Matrices in Parallel and Ranking of Graphs". 5th International Conference on Parallel Processing and Applied Mathematics (PDF). Lecture Notes on Computer Science. Vol. 3019. Springer-Verlag. pp. 985–992. doi:10.1007/978-3-540-24669-5_127. ISBN 978-3-540-21946-0. Archived from the original (PDF) on 2011-07-16.
- Golub, Gene H.; Van Loan, Charles F. (1996). Matrix Computations (3rd ed.). Baltimore: Johns Hopkins. ISBN 978-0-8018-5414-9.
- Horn, Roger A.; Johnson, Charles R. (1985). Matrix Analysis. Cambridge University Press. ISBN 0-521-38632-2.
- S. J. Julier and J. K. Uhlmann. "A General Method for Approximating Nonlinear Transformations of ProbabilityDistributions".
- S. J. Julier and J. K. Uhlmann, "A new extension of the Kalman filter to nonlinear systems", in Proc. AeroSense: 11th Int. Symp. Aerospace/Defence Sensing, Simulation and Controls, 1997, pp. 182–193.
- Trefethen, Lloyd N.; Bau, David (1997). Numerical linear algebra. Philadelphia: Society for Industrial and Applied Mathematics. ISBN 978-0-89871-361-9.
- Osborne, Michael (2010). Bayesian Gaussian Processes for Sequential Prediction, Optimisation and Quadrature (PDF) (thesis). University of Oxford.
- Ruschel, João Paulo Tarasconi, Bachelor degree "Parallel Implementations of the Cholesky Decomposition on CPUs and GPUs" Universidade Federal Do Rio Grande Do Sul, Instituto De Informatica, 2016, pp. 29-30.
External links
History of science
- Sur la résolution numérique des systèmes d'équations linéaires, Cholesky's 1910 manuscript, online and analyzed on BibNum (in French and English) [for English, click 'A télécharger']
Information
- "Cholesky factorization", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Cholesky Decomposition, The Data Analysis BriefBook
- Cholesky Decomposition on www.math-linux.com
- Cholesky Decomposition Made Simple on Science Meanderthal
Computer code
- LAPACK is a collection of FORTRAN subroutines for solving dense linear algebra problems (DPOTRF, DPOTRF2, details performance)
- ALGLIB includes a partial port of the LAPACK to C++, C#, Delphi, Visual Basic, etc. (spdmatrixcholesky, hpdmatrixcholesky)
- libflame is a C library with LAPACK functionality.
- Notes and video on high-performance implementation of Cholesky factorization at The University of Texas at Austin.
- Cholesky : TBB + Threads + SSE is a book explaining the implementation of the CF with TBB, threads and SSE (in Spanish).
- library "Ceres Solver" by Google.
- LDL decomposition routines in Matlab.
- Armadillo is a C++ linear algebra package
- Rosetta Code is a programming chrestomathy site. on page topic.
- AlgoWiki is an open encyclopedia of algorithms’ properties and features of their implementations on page topic
- Intel® oneAPI Math Kernel Library Intel-Optimized Math Library for Numerical Computing ?potrf, ?potrs