Compact letter display
Compact Letter Display (CLD) is a statistical method to clarify the output of multiple hypothesis testing when using the ANOVA and Tukey's range tests. CLD can also be applied following the Duncan's new multiple range test (which is similar to Tukey's range test). CLD facilitates the identification of variables, or factors, that have statistically different means (or averages) vs. the ones that do not have statistically different means (or averages).
The basic technique of compact letter display is to label variables by one or more letters, so that variables are statistically indistinguishable if and only if they share at least one letter. The problem of doing so, using as few distinct letters as possible can be represented combinatorially as the problem of computing an edge clique cover of a graph representing pairs of indistinguishable variables.[1]
As well as marking distinguishability in this way, CLD also ranks variables, or factors, by their respective mean (or average) in descending order. The CLD methodology can be applied to tabular data (spreadsheet, data frame) or visual data (box plot and bar chart).
The basics of CLD
CLD identifies the variables that are statistically different vs. the ones that are not
Each variable that shares a mean that is not statistically different from another one will share the same letter.[2][3][4] For example:
”a” “ab” “b”
The above indicates that the first variable “a” has a mean (or average) that is statistically different from the third one “b”. But, the second variable “ab” has a mean that is not statistically different from either the first or the third variable. Let's look at another example:
”a” “ab” “bc” “c”
The above indicates that the first variable “a” has a mean (or average) that is statistically different from the third variable “bc” and the fourth one “c”. But, this first variable “a” is not statistically different from the second one “ab”.
Given the structure of the Roman alphabet, the CLD methodology could readily compare up to 26 different variables, or factors. This constraint is typically much higher than the vast majority of multiple hypothesis testing conducted using ANOVA and Tukey's range tests.
CLD ranks the variables in descending mean (or average) order
So, the variable with the highest mean (or average) will be named “a” (if it is statistically different from all the others, otherwise it may be called "ab", etc.). And, the variable with the lowest mean (or average) will have the highest letter among the tested variables.[2][3][4]
A CLD example
We are going to test if the average rainfall in five West Coast cities is statistically different. These cities are:
- Eugene (OR)
- Portland (OR)
- San Francisco (CA)
- Seattle (WA)
- Spokane (WA)
The data is annual rainfall inches (1951 – 2021).
The data source is the NOAA.
First, we will improve the tabular data using CLD.
Next, we will improve the visual data using CLD.
Improving tabular data with CLD
Here are the five West Coast cities rainfall data before applying CLD methodology.
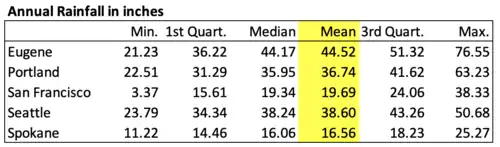
As shown above, the rainfall data for the five West Coast cities is sorted in alphabetical order. This order is not informative. It is challenging to figure out which cities' respective mean or average are different from each other.
Next, we reproduce the same table but we sort the cities using the CLD methodology after we would have conducted a Tukey's range test.
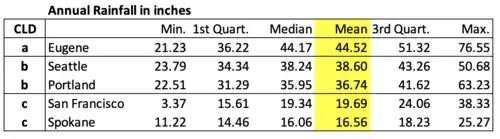
The above table using the CLD methodology is far more informative. It has ranked the cities by their respective mean or average rainfall in descending order. And, it has also grouped the cities that have similar mean-rainfall (not statistically different using an alpha value of 0.05).
As shown, Seattle and Portland have mean rainfall levels that are not statistically different from each other. They are both classified "b". Also, San Francisco and Spokane have mean rainfall levels that are not statistically different from each other. They are both classified "c." But, Eugene's mean rainfall level is statistically different and higher than either Seattle & Portland or San Francisco & Spokane. And, Seattle & Portland have mean rainfall levels that are statistically different and higher than San Francisco & Spokane.
Improving visual data with CLD
Here is a first box plot with cities just sorted in alphabetical order from left to right.
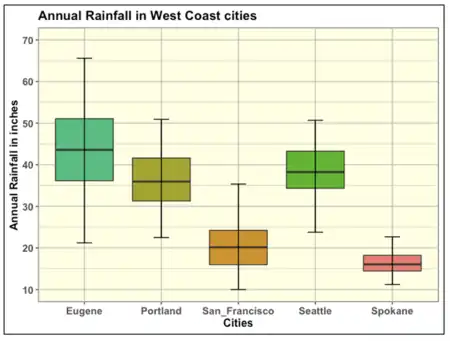
The box plot above is not entirely clear. It is hard to distinguish the cities that are somewhat similar (average or mean is not statistically different) vs. the ones that are dissimilar (average or mean is statistically different). Now, let's view the same boxplot using the CLD methodology.
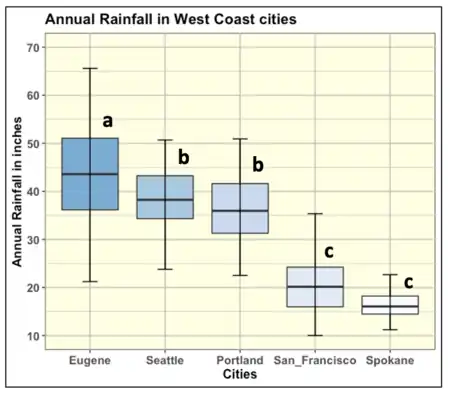
The box plot above, using the CLD methodology, is now far more informative. The cities are sorted in descending order from left to right. The color density is tiered with the cities having higher rainfall being colored with more dense or opaque tones; meanwhile, the cities with lower rainfall have less dense or more transparent tones. Additionally, we can readily identify the cities that have similar rainfall means (not statistically different) such as Seattle & Portland hat are both identified with the "b" letter. Additionally, San Francisco & Eugene also have similar rainfall means as they are both identified with the "c" letter. On the other hand, Eugene has the highest mean rainfall level of them all; and, it is statistically different (higher) than all other cities as it is the only city identified with the letter "a".
The benefits of CLD
In the absence of the CLD methodology, the main underlying way of identifying statistical difference in means between paired variables is the mentioned Tukey's range test. The latter is a very informative test catered to an audience of statisticians. Outside of such a specialized audience, the test output as shown below is rather challenging to interpret.
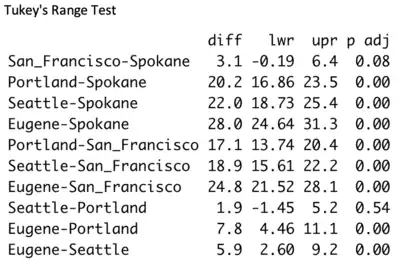
The Tukey's range test uncovered that San Francisco & Spokane did not have statistically different rainfall mean (at the alpha = 0.05 level) with a p-value of 0.08. Seattle & Portland also did not have statistically different rainfall mean, with a difference associated with a p-value of 0.54.
As shown earlier, it is a lot easier to convey the differentiation between cities rainfall mean using the CLD methodology. And, the CLD enhanced information can be readily interpreted by a far wider audience than doing otherwise (communicating the results without using the CLD methodology, including communicating the result of the Tukey's range test directly).
How to construct a boxplot in R with Compact Letter Display
References
- Gramm, Jens; Guo, Jiong; Hüffner, Falk; Niedermeier, Rolf; Piepho, Hans-Peter; Schmid, Ramona (2008). "Algorithms for compact letter displays: Comparison and evaluation". Computational Statistics & Data Analysis. 52 (2): 725–736. doi:10.1016/j.csda.2006.09.035. MR 2418523.
- "Compact Letter Display (CLD)". schmidtpaul.github.io. Retrieved 2022-09-04.
- Piepho, Hans-Peter (2004-06-01). "An Algorithm for a Letter-Based Representation of All-Pairwise Comparisons". Journal of Computational and Graphical Statistics. 13 (2): 456–466. doi:10.1198/1061860043515. ISSN 1061-8600. S2CID 122068627.
- Piepho, Hans-Peter (March 2018). "Letters in Mean Comparisons: What They Do and Don't Mean". Researchgate.com. Retrieved September 3, 2022.
- "Compact Letter Displays". John Quensen's blog. 2020-01-15. Retrieved 2022-09-04.
- "cld: Set up a compact letter display of all pair-wise comparisons in multcomp: Simultaneous Inference in General Parametric Models". rdrr.io. Retrieved 2022-09-04.
Further reading
- Gramm, Jens; Guo, Jiong; Hüffner, Falk; Niedermeier, Rolf; Piepho, Hans-Peter; Schmid, Ramona (2007-10-15). "Algorithms for compact letter displays: Comparison and evaluation". Computational Statistics & Data Analysis. 52 (2): 725–736. doi:10.1016/j.csda.2006.09.035. ISSN 0167-9473.
- Greenwood, Mark; Banner, Katharine. "Multiple (pair-wise) comparisons using Tukey's HSD and the compact letter display - Mark Greenwood and Katharine Banner". Montana State University (MSU) Library. Retrieved 2022-09-05.