Comparison of different machine translation approaches
Machine translation (MT) algorithms may be classified by their operating principle. MT may be based on a set of linguistic rules, or on large bodies (corpora) of already existing parallel texts. Rule-based methodologies may consist in a direct word-by-word translation, or operate via a more abstract representation of meaning: a representation either specific to the language pair, or a language-independent interlingua. Corpora-based methodologies rely on machine learning and may follow specific examples taken from the parallel texts, or may calculate statistical probabilities to select a preferred option out of all possible translations.
Rule-based and corpus-based machine translation
Rule-based machine translation (RBMT) is generated on the basis of morphological, syntactic, and semantic analysis of both the source and the target languages. Corpus-based machine translation (CBMT) is generated on the analysis of bilingual text corpora. The former belongs to the domain of rationalism and the latter empiricism. Given large-scale and fine-grained linguistic rules, RBMT systems are capable of producing translations with reasonable quality, but constructing the system is very time-consuming and labor-intensive because such linguistic resources need to be hand-crafted, frequently referred to as knowledge acquisition problem. Moreover, it is of great difficulty to correct the input or add new rules to the system to generate a translation. By contrast, adding more examples to a CBMT system can improve the system since it is based on the data, though the accumulation and management of the huge bilingual data corpus can also be costly.
Direct, transfer and interlingual machine translation
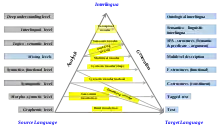
The direct, transfer-based machine translation and interlingual machine translation methods of machine translation all belong to RBMT but differ in the depth of analysis of the source language and the extent to which they attempt to reach a language-independent representation of meaning or intent between the source and target languages. Their dissimilarities can be obviously observed through the Vauquois Triangle (see illustration), which illustrates these levels of analysis.
Starting with the shallowest level at the bottom, direct transfer is made at the word level. Depending on finding direct correspondences between source language and target language lexical units, DMT is a word-by-word translation approach with some simple grammatical adjustments. A DMT system is designed for a specific source and target language pair and the translation unit of which is usually a word. Translation is then performed on representations of the source sentence structure and meaning respectively through syntactic and semantic transfer approaches.
A transfer-based machine translation system involves three stages. The first stage makes analysis of the source text and converts it into abstract representations; the second stage converts those into equivalent target language-oriented representations; and the third generates the final target text. The representation is specific for each language pair. The transfer strategy can be viewed as “a practical compromise between the efficient use of resources of interlingual systems, and the ease of implementation of direct systems” .
Finally, at the interlingual level, the notion of transfer is replaced by the interlingua. The IMT operates over two phases: analyzing the SL text into an abstract universal language-independent representation of meaning, i.e. the interlingua, which is the phase of analysis; generating this meaning using the lexical units and the syntactic constructions of the TL, which is the phase of synthesis. Theoretically, the higher the triangle, the less cost the analysis and synthesis. For example, to translate one SL to N TLs, (1+N) steps are needed using an interlingua compared to N steps of transfer. But to translate all the languages, only 2N steps are needed by the IMT approach compared to N² by the TBMT approach, which is a significant reduction. Though no transfer component has to be created for each language pair by adopting the approach of IMT, the definition of an interlingua is of great difficulty and even maybe impossible for a wider domain.
Statistical and example-based machine translation
Statistical machine translation (SMT) is generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora. The initial model of SMT, based on Bayes Theorem, proposed by Brown et al. takes the view that every sentence in one language is a possible translation of any sentence in the other and the most appropriate is the translation that is assigned the highest probability by the system. Example-based machine translation (EBMT) is characterized by its use of bilingual corpus with parallel texts as its main knowledge, in which translation by analogy is the main idea. There are four tasks in EBMT: example acquisition, example base and management, example application and synthesis.
Both belonging to CBMT, sometimes referred to as data-driven MT, EBMT and SMT have something in common which distinguish them from RBMT. First, they both use a bitext as the fundamental data source. Second, they are both empirical with the principle of machine learning instead of rational with the principle of linguists writing rules. Third, they both can be improved by getting more data. Fourth, new language pairs can be developed just by finding suitable parallel corpus data, if possible. Apart from these similarities, there are also some dissimilarities. SMT essentially uses statistical data such as parameters and probabilities derived from the bitext, in which preprocessing the data is essential and even if the input is in the training data, the same translation is not guaranteed to occur. By contrast, EBMT uses the bitext as its primary data source, in which preprocessing the data is optional and if the input is in the example set, the same translation is to occur.
References
- Nano Gough and Andy Way. 2004. "Example-Based Controlled Translation". In Proceedings of the Ninth EAMT Workshop, Valletta, Malta, pp. 73–81.
- Jean, Senellart (2006). "Boosting linguistic rule-based MT system with corpus-based approaches".
{{cite journal}}: Cite journal requires|journal=(help) - A, Lampert (2004). "Interlingua in Machine Translation". Technical Report.
- Reshef, Shilon (2011). "Transfer-based Machine Translation between morphologically-rich and resource-poor languages: The case of Hebrew and Arabic".
{{cite journal}}: Cite journal requires|journal=(help) - Somers, H. (1999). "Review Article: Example-based Machine Translation". Machine Translation. 14 (2): 113–157. doi:10.1023/a:1008109312730. S2CID 17733262.
- Trujillo, A. (1999). Translation Engines: Techniques for Machine Translation. London: Springer. ISBN 9781447105879.
- Andy, Way; Nano Gough (2005). "Comparing Example-Based and Statistical Machine Translation". Natural Language Engineering.