Contraction hierarchies
In computer science, the method of contraction hierarchies is a speed-up technique for finding the shortest-path in a graph. The most intuitive applications are car-navigation systems: a user wants to drive from to using the quickest possible route. The metric optimized here is the travel time. Intersections are represented by vertices, the road sections connecting them by edges. The edge weights represent the time it takes to drive along this segment of the road. A path from to is a sequence of edges (road sections); the shortest path is the one with the minimal sum of edge weights among all possible paths. The shortest path in a graph can be computed using Dijkstra's algorithm but, given that road networks consist of tens of millions of vertices, this is impractical.[1] Contraction hierarchies is a speed-up method optimized to exploit properties of graphs representing road networks.[2] The speed-up is achieved by creating shortcuts in a preprocessing phase which are then used during a shortest-path query to skip over "unimportant" vertices.[2] This is based on the observation that road networks are highly hierarchical. Some intersections, for example highway junctions, are "more important" and higher up in the hierarchy than for example a junction leading into a dead end. Shortcuts can be used to save the precomputed distance between two important junctions such that the algorithm doesn't have to consider the full path between these junctions at query time. Contraction hierarchies do not know about which roads humans consider "important" (e.g. highways), but they are provided with the graph as input and are able to assign importance to vertices using heuristics.


Contraction hierarchies are not only applied to speed-up algorithms in car-navigation systems but also in web-based route planners, traffic simulation, and logistics optimization.[3][1][4] Implementations of the algorithm are publicly available as open source software.[5][6][7][8][9]
Algorithm
The contraction hierarchies (CH) algorithm is a two-phase approach to the shortest path problem consisting of a preprocessing phase and a query phase. As road networks change rather infrequently, more time (seconds to hours) can be used to once precompute some calculations before queries are to be answered. Using this precomputed data, many queries can be answered taking very little time (microseconds) each.[1][3] CHs rely on shortcuts to achieve this speedup. A shortcut connects two vertices and not adjacent in the original graph. Its edge weight is the sum of the edge weights on the shortest - path.


Consider two large cities connected by a highway. Between these two cities, there is a multitude of junctions leading to small villages and suburbs. Most drivers want to get from one city to the other – maybe as part of a larger route – and not take one of the exits on the way. In the graph representing this road layout, each intersection is represented by a node and edges are created between neighboring intersections. To calculate the distance between these two cities, the algorithm has to traverse all the edges along the way, adding up their length. Precomputing this distance once and storing it in an additional edge created between the two large cities will save calculations each time this highway has to be evaluated in a query. This additional edge is called a "shortcut" and has no counterpart in the real world. The contraction hierarchies algorithm has no knowledge about road types but is able to determine which shortcuts have to be created using the graph alone as input.



Preprocessing phase
The CH algorithm relies on shortcuts created in the preprocessing phase to reduce the search space – that is the number of vertices CH has to look at, at query time. To achieve this, iterative vertex contractions are performed. When contracting a vertex it is temporarily removed from the graph , and a shortcut is created between each pair of neighboring vertices if the shortest path from to contains .[2] The process of determining if the shortest path between and contains is called witness search. It can be performed for example by computing a path from to using a forward search using only not yet contracted nodes.[3]





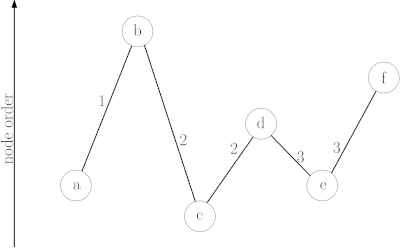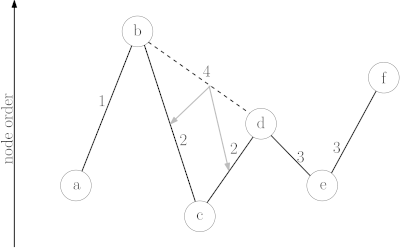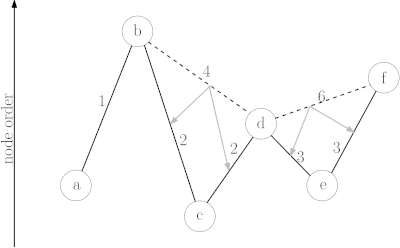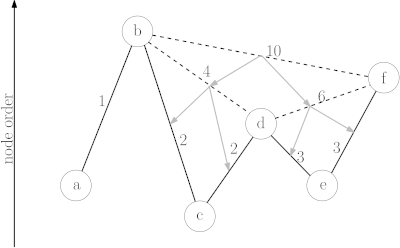








Node order
The vertices of the input graph have to be contracted in a way which minimizes the number of edges added to the graph by contractions. As optimal node ordering is NP-complete,[10] heuristics are used.[2]
Bottom-up and top-down heuristics exist. On one hand, the computationally cheaper bottom-up heuristics decide the order in which to contract the vertices in a greedy fashion; this means the order is not known in advance but rather the next node is selected for contraction after the previous contraction has been completed. Top-down heuristics on the other hand precompute the whole node ordering before the first node is contracted. This yields better results but needs more preprocessing time.[2]
In bottom-up heuristics, a combination of factors is used to select the next vertex for contraction. As the number of shortcuts is the primary factor that determines preprocessing and query runtime, we want to keep it as small as possible. The most important term by which to select the next node for contraction is therefore the net number of edges added when contracting a node . This is defined as where is the number of shortcuts that would be created if were to be contracted and is the number of edges incident to . Using this criterion alone, a linear path would result in a linear hierarchy (many levels) and no created shortcuts. By considering the number of nearby vertices that are already contracted, a uniform contraction and a flat hierarchy (less levels) is achieved. This can, for example, be done by maintaining a counter for each node that is incremented each time a neighboring vertex is contracted. Nodes with lower counters are then preferred to nodes with higher counters.[11]




Top-down heuristics, on the other hand, yield better results but need more preprocessing time. They classify vertices that are part of many shortest paths as more important than those that are only needed for a few shortest paths. This can be approximated using nested dissections.[2] To compute a nested dissection, one recursively separates a graph into two parts, which are themselves then separated into two parts and so on. That is, find a subset of nodes which when removed from the graph separate into two disjunct pieces of approximately equal size such that . Place all nodes last in the node ordering and then recursively compute the nested dissection for and ,[12] the intuition being that all queries from one half of the graph to the other half of the graph need to pass through the small separator and therefore nodes in this separator are of high importance. Nested dissections can be efficiently calculated on road networks because of their small separators.[13]






Query phase
In the query phase, a bidirectional search is performed starting from the starting node and the target node on the original graph augmented by the shortcuts created in the preprocessing phase.[2] The most important vertex on the shortest path between and will be either or themselves or more important than both and . Therefore, the vertex minimizing is on the shortest path in the original graph and holds.[2] This, in combination with how shortcuts are created, means that both forward and backward search only need to relax edges leading to more important nodes (upwards) in the hierarchy which keeps the search space small.[3] In all up-(down-up)-down paths, the inner (down-up) can be skipped, because a shortcut has been created in the preprocessing stage.



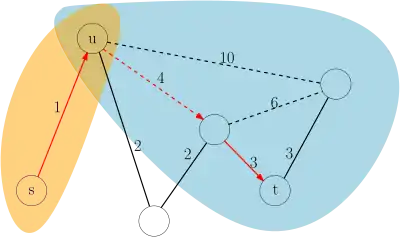
Path retrieval
A CH query, as described above, yields the time or distance from to but not the actual path. To obtain the list of edges (roads) on the shortest path, the shortcuts taken have to be unpacked. Each shortcut is the concatenation of two edges: either two edges of the original graph, or two shortcuts, or one original edge and one shortcut. Storing the middle vertex of each shortcut during contraction enables linear-time recursive unpacking of the shortest route.[2][3]
Customized contraction hierarchies
If the edge weights are changed more often than the network topology, CH can be extended to a three-phase approach by including a customization phase between the preprocessing and query phase. This can be used for example to switch between shortest distance and shortest time or include current traffic information as well as user preferences like avoiding certain types of roads (ferries, highways, ...). In the preprocessing phase, most of the runtime is spent on computing the order in which the nodes are contracted.[3] This sequence of contraction operations in the preprocessing phase can be saved for when they are later needed in the customization phase. Each time the metric is customized, the contractions can then be efficiently applied in the stored order using the custom metric.[2] Additionally, depending on the new edge weights it may be necessary to recompute some shortcuts.[3] For this to work, the contraction order has to be computed using metric-independent nested dissections.[1]
Extensions and applications
CHs as described above search for a shortest path from one starting node to one target node. This is called one-to-one shortest path and is used for example in car-navigation systems. Other applications include matching GPS traces to road segments and speeding up traffic simulators which have to consider the likely routes taken by all drivers in a network. In route prediction one tries to estimate where a vehicle is likely headed by calculating how well its current and past positions agree with a shortest path from its starting point to any possible target. This can be efficiently done using CHs.[2]
In one-to-many scenarios, a starting node and a set of target nodes are given and the distance for all has to be computed. The most prominent application for one-to-many queries are point-of-interest searches. Typical examples include finding the closest gas station, restaurant or post office using actual travel time instead of geographical distance as metric.[2]



In the many-to-many shortest path scenario, a set of starting nodes and a set of target nodes are given and the distance for all has to be computed. This is used for example in logistic applications.[2] CHs can be extended to many-to-many queries in the following manner. First, perform a backward upward search from each . For each vertex scanned during this search, one stores in a bucket . Then, one runs a forward upward search from each , checking for each non-empty bucket, whether the route over the corresponding vertex improves any best distance. That is, if for any .[2][3]








Some applications even require one-to-all computations, i.e., finding the distances from a source vertex to all other vertices in the graph. As Dijkstra's algorithm visits each edge exactly once and therefore runs in linear time it is theoretically optimal. Dijkstra's algorithm, however, is hard to parallelize and is not cache-optimal because of its bad locality. CHs can be used for a more cache-optimal implementation. For this, a forward upward search from followed by a downward scan over all nodes in the shortcut-enriched graph is performed. The later operation scans through memory in a linear fashion, as the nodes are processed in decreasing order of importance and can therefore be placed in memory accordingly.[14] Note, that this is possible because the order in which the nodes are processed in the second phase is independent of the source node .[2]
In production, car-navigation systems should be able to compute fastest travel routes using predicted traffic information and display alternative routes. Both can be done using CHs.[2] The former is called routing with time-dependent networks where the travel time of a given edge is no longer constant but rather a function of the time of day when entering the edge. Alternative routes need to be smooth-looking, significantly different from the shortest path but not significantly longer.[2]
CHs can be extended to optimize multiple metrics at the same time; this is called multi-criteria route planning. For example, one could minimize both travel cost and time. Another example are electric vehicles for which the available battery charge constrains the valid routes as the battery may not run empty.[2]
Theory
A number of bounds have been established on the preprocessing and query performance of contraction hierarchies. In the following let be the number of vertices in the graph, the number of edges, the highway dimension, the graph diameter, is the tree-depth and is the tree-width.






The first analysis of contraction hierarchy performance relies in part on a quantity known as the highway dimension. While the definition of this quantity is technical, intuitively a graph has a small highway dimension if for every there is a sparse set of vertices such that every shortest path of length greater than includes a vertex from . Calculating the exact value of the highway dimension is NP-hard[15][16] and W[1]-hard,[17] but for grids it is known that the highway dimension .[18]




An alternative analysis was presented in the Customizable Contraction Hierarchy line of work. Query running times can be bounded by . As the tree-depth can be bounded in terms of the tree-width, is also a valid upper bound. The main source is [19] but the consequences for the worst case running times are better detailed in.[20]


Preprocessing Performance
| Algorithm | Year | Time Complexity |
|---|---|---|
| Randomized Processing[21] | 2015 |

Query Performance
| Algorithm/Analysis Technique | Year | Time Complexity | Notes |
|---|---|---|---|
| Bounded Growth Graphs[22] | 2018 | ||
| Customizable Contraction Hierarchies[19][20] | 2013-2018 | or . | is the tree-depth and is the tree-width |
| Randomized Processing[21] | 2015 | Exact, no O-notation; works with high probability | |
| Modified SHARC[18] | 2010 | Polynomial preprocessing | |
| Modified SHARC[18] | 2010 | Superpolynomial preprocessing |





References
- Dibbelt, Julian; Strasser, Ben; Wagner, Dorothea (5 April 2016). "Customizable Contraction Hierarchies". Journal of Experimental Algorithmics. 21 (1): 1–49. arXiv:1402.0402. doi:10.1145/2886843. S2CID 5247950.
- Bast, Hannah; Delling, Daniel; Goldberg, Andrew V.; Müller-Hannemann, Matthias; Pajor, Thomas; Sanders, Peter; Wagner, Dorothea; Werneck, Renato F. (2016). "Route Planning in Transportation Networks". Algorithm Engineering. Lecture Notes in Computer Science. Vol. 9220. pp. 19–80. arXiv:1504.05140. doi:10.1007/978-3-319-49487-6_2. ISBN 978-3-319-49486-9. S2CID 14384915.
- Geisberger, Robert; Sanders, Peter; Schultes, Dominik; Vetter, Christian (2012). "Exact Routing in Large Road Networks Using Contraction Hierarchies". Transportation Science. 46 (3): 388–404. doi:10.1287/trsc.1110.0401.
- Delling, Daniel; Sanders, Peter; Schultes, Dominik; Wagner, Dorothea (2009). "Engineering Route Planning Algorithms". Algorithmics of Large and Complex Networks. Lecture Notes in Computer Science. Vol. 5515. pp. 117–139. doi:10.1007/978-3-642-02094-0_7. ISBN 978-3-642-02093-3.
- "OSRM – Open Source Routing Machine".
- "Wiki – OpenTripPlanner".
- "Web – GraphHopper".
- "GitHub – Tempus". GitHub. 9 September 2021.
- "GitHub – RoutingKit". GitHub. 24 January 2022.
- Bauer, Reinhard; Delling, Daniel; Sanders, Peter; Schieferdecker, Dennis; Schultes, Dominik; Wagner, Dorothea (2010-03-01). "Combining hierarchical and goal-directed speed-up techniques for dijkstra's algorithm". Journal of Experimental Algorithmics. 15: 2.1. doi:10.1145/1671970.1671976. ISSN 1084-6654. S2CID 1661292.
- Geisberger, Robert; Sanders, Peter; Schultes, Dominik; Delling, Daniel (2008). "Contraction Hierarchies: Faster and Simpler Hierarchical Routing in Road Networks". In McGeoch, Catherine C. (ed.). Experimental Algorithms. Lecture Notes in Computer Science. Vol. 5038. Springer Berlin Heidelberg. pp. 319–333. doi:10.1007/978-3-540-68552-4_24. ISBN 9783540685524. S2CID 777101.
- Bauer, Reinhard; Columbus, Tobias; Rutter, Ignaz; Wagner, Dorothea (2016-09-13). "Search-space size in contraction hierarchies". Theoretical Computer Science. 645: 112–127. doi:10.1016/j.tcs.2016.07.003. ISSN 0304-3975.
- Delling, Daniel; Goldberg, Andrew V.; Razenshteyn, Ilya; Werneck, Renato F. (May 2011). "Graph Partitioning with Natural Cuts". 2011 IEEE International Parallel & Distributed Processing Symposium. pp. 1135–1146. CiteSeerX 10.1.1.385.1580. doi:10.1109/ipdps.2011.108. ISBN 978-1-61284-372-8. S2CID 6884123.
- Delling, Daniel; Goldberg, Andrew V.; Nowatzyk, Andreas; Werneck, Renato F. (2011). "PHAST: Hardware-Accelerated Shortest Path Trees". 2011 IEEE International Parallel & Distributed Processing Symposium. pp. 921–931. doi:10.1109/ipdps.2011.89. ISBN 978-1-61284-372-8. S2CID 1419921.
- Feldmann, Andreas Emil; Fung, Wai Shing; Könemann, Jochen; Post, Ian (2018-01-01). "A $(1+\varepsilon)$-Embedding of Low Highway Dimension Graphs into Bounded Treewidth Graphs". SIAM Journal on Computing. 47 (4): 1667–1704. doi:10.1137/16M1067196. ISSN 0097-5397. S2CID 11339698.
- Blum, Johannes (2019). "Hierarchy of Transportation Network Parameters and Hardness Results". In Jansen, Bart M. P.; Telle, Jan Arne (eds.). 14th International Symposium on Parameterized and Exact Computation (IPEC 2019). Leibniz International Proceedings in Informatics. Vol. 148. Dagstuhl, Germany: Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik. pp. 4:1–4:15. doi:10.4230/LIPIcs.IPEC.2019.4. ISBN 978-3-95977-129-0. S2CID 166228480.
- Blum, Johannes; Disser, Yann; Feldmann, Andreas Emil; Gupta, Siddharth; Zych-Pawlewicz, Anna (2022). "On Sparse Hitting Sets: From Fair Vertex Cover to Highway Dimension". In Dell, Holger; Nederlof, Jesper (eds.). 17th International Symposium on Parameterized and Exact Computation (IPEC 2022). Leibniz International Proceedings in Informatics. Vol. 249. Dagstuhl, Germany: Schloss Dagstuhl – Leibniz-Zentrum für Informatik. pp. 5:1–5:23. doi:10.4230/LIPIcs.IPEC.2022.5. ISBN 978-3-95977-260-0.
- Abraham, Ittai; Fiat, Amos; Goldberg, Andrew (2010). Highway dimension, shortest paths, and provably efficient algorithms (PDF). Proceedings of the 2010 annual ACM-SIAM symposium on discrete algorithms. doi:10.1137/1.9781611973075.64.
- Dibbelt, Julian; Strasser, Ben; Wagner, Dorothea (2016). "Customizable Contraction Hierarchies". ACM Journal of Experimental Algorithmics. 21: 1–49. arXiv:1402.0402. doi:10.1145/2886843. S2CID 5247950.
- Hamann, Michael; Strasser, Ben (2018). "Graph Bisection with Pareto Optimization". ACM Journal of Experimental Algorithmics. 23: 1–34. arXiv:1504.03812. doi:10.1145/3173045. S2CID 3395784.
- Funke, Stefan; Storandt, Sabine (2015). "Provable Efficiency of Contraction Hierarchies with Randomized Preprocessing". Algorithms and Computation. Lecture Notes in Computer Science. Vol. 9472. pp. 479–490. doi:10.1007/978-3-662-48971-0_41. ISBN 978-3-662-48971-0.
- Blum, Johannes; Funke, Stefan; Storandt, Sabine (2018). Sublinear Search Spaces for Shortest Path Planning in Grid and Road Networks (PDF). AAAI.