DNA-encoded chemical library
DNA-encoded chemical libraries (DECL) is a technology for the synthesis and screening on an unprecedented scale of collections of small molecule compounds. DECL is used in medicinal chemistry to bridge the fields of combinatorial chemistry and molecular biology. The aim of DECL technology is to accelerate the drug discovery process and in particular early phase discovery activities such as target validation and hit identification.
DECL technology involves the conjugation of chemical compounds or building blocks to short DNA fragments that serve as identification bar codes and in some cases also direct and control the chemical synthesis. The technique enables the mass creation and interrogation of libraries via affinity selection, typically on an immobilized protein target. A homogeneous method for screening DNA-encoded libraries (DELs) has recently been developed which uses water-in-oil emulsion technology to isolate, count and identify individual ligand-target complexes in a single-tube approach. In contrast to conventional screening procedures such as high-throughput screening, biochemical assays are not required for binder identification, in principle allowing the isolation of binders to a wide range of proteins historically difficult to tackle with conventional screening technologies. So, in addition to the general discovery of target specific molecular compounds, the availability of binders to pharmacologically important, but so-far “undruggable” target proteins opens new possibilities to develop novel drugs for diseases that could not be treated so far. In eliminating the requirement to initially assess the activity of hits it is hoped and expected that many of the high affinity binders identified will be shown to be active in independent analysis of selected hits, therefore offering an efficient method to identify high quality hits and pharmaceutical leads.
DNA-encoded chemical libraries and display technologies
Until recently, the application of molecular evolution in the laboratory had been limited to display technologies involving biological molecules, where small molecules lead discovery was considered beyond this biological approach. DELs have opened the field of display technology to include non-natural compounds such as small molecules, extending the application of molecular evolution and natural selection to the identification of small molecule compounds of desired activity and function. DNA encoded chemical libraries bear resemblance to biological display technologies such as antibody phage display technology, yeast display, mRNA display and aptamer SELEX. In antibody phage display, antibodies are physically linked to phage particles that bear the gene coding for the attached antibody, which is equivalent to a physical linkage of a “phenotype” (the protein) and a “genotype” (the gene encoding for the protein ).[1] Phage-displayed antibodies can be isolated from large antibody libraries by mimicking molecular evolution: through rounds of selection (on an immobilized protein target), amplification and translation.[2] In DELs the linkage of a small molecule to an identifier DNA code allows the facile identification of binding molecules. DELs are subjected to affinity selection procedures on an immobilized target protein of choice, after which non-binders are removed by washing steps, and binders can subsequently be amplified by polymerase chain reaction (PCR) and identified by virtue of their DNA code (e.g.by DNA sequencing). In evolution-based DEL technologies hits can be further enriched by performing rounds of selection, PCR amplification and translation in analogy to biological display systems such as antibody phage display. This makes it possible to work with much larger libraries.
History
“Synthesize a multi-component mixture of compounds in a single process and screen it also a single process”. This is the principle of combinatorial chemistry invented by Prof. Furka Á. (Eötvös Loránd University Budapest Hungary) in 1982, and described it including the method of synthesis of combinatorial libraries and that of a deconvolution strategy in a document notarized in the same year.[3] Motivations that led to the invention had been published in 2002.[4] DNA encoded chemical libraries (DECLs) are synthesized by the combinatorial chemistry principle and it clearly agrees with their application.[5]
The concept of DNA-encoding was first described in a theoretical paper by Brenner and Lerner in 1992 in which was proposed to link each molecule of a chemically synthesized entity to a particular oligonucleotide sequence constructed in parallel and to use this encoding genetic tag to identify and enrich active compounds.[6] In 1993 the first practical implementation of this approach was presented by S. Brenner and K. Janda and similarly by the group of M.A. Gallop.[7][8] Brenner and Janda suggested to generate individual encoded library members by an alternating parallel combinatorial synthesis of the heteropolymeric chemical compound and the appropriate oligonucleotide sequence on the same bead in a “split-&-pool”-based fashion (see below).[7]
Since unprotected DNA is restricted to a narrow window of conventional reaction conditions, until the end of the 1990s a number of alternative encoding strategies were envisaged (i.e. MS-based compound tagging, peptide encoding, haloaromatic tagging, encoding by secondary amines, semiconductor devices.), mainly to avoid inconvenient solid phase DNA synthesis and to create easily screenable combinatorial libraries in high-throughput fashion.[9] However, the selective amplificability of DNA greatly facilitates library screening and it becomes indispensable for the encoding of organic compounds libraries of this unprecedented size. Consequently, at the beginning of the 2000s DNA-combinatorial chemistry experienced a revival.
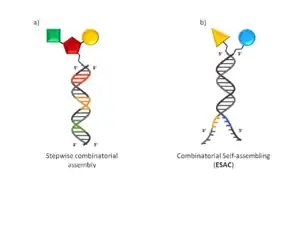
The beginning of the millennium saw the introduction of several independent developments in DEL technology. These technologies can be classified under two general categories: non-evolution-based and evolution-based DEL technologies capable of molecular evolution. The first category benefits from the ability to use off the shelf reagents and therefore enables rather straightforward library generation. Hits can be identified by DNA sequencing, however DNA translation and therefore molecular evolution is not feasible by these methods. The split and pool approaches developed by researchers at Praecis Pharmaceuticals (now owned by GlaxoSmithKline), Nuevolution (Copenhagen, Denmark) and ESAC technology developed in the laboratory of Prof D. Neri (Institute of Pharmaceutical Science, Zurich, Switzerland) fall under this category. ESAC technology sets itself apart being a combinatorial self-assembling approach which resembles fragment based hit discovery (Fig 1b). Here DNA annealing enables discrete building block combinations to be sampled, but no chemical reaction takes place between them. Examples of evolution-based DEL technologies are DNA-routing developed by Prof. D.R. Halpin and Prof. P.B. Harbury (Stanford University, Stanford, CA), DNA-templated synthesis developed by Prof. D. Liu (Harvard University, Cambridge, MA) and commercialized by Ensemble Therapeutics (Cambridge, MA) and YoctoReactor technology.[10] developed and commercialized by Vipergen (Copenhagen, Denmark). These technologies are described in further detail below. DNA-templated synthesis and YoctoReactor technology require the prior conjugation of chemical building blocks (BB) to a DNA oligonucleotide tag before library assembly, therefore more upfront work is required before library assembly. Furthermore, the DNA tagged BBs enable the generation of a genetic code for synthesized compounds and artificial translation of the genetic code is possible: That is the BB's can be recalled by the PCR-amplified genetic code, and the library compounds can be regenerated. This, in turn, enables the principle of Darwinian natural selection and evolution to be applied to small molecule selection in direct analogy to biological display systems; through rounds of selection, amplification and translation.
Non-evolution based technologies
Combinatorial libraries
Combinatorial libraries are special multi-component compound mixtures that are synthesized in a single stepwise process. They differ from collection of individual compounds as well as from a series of compounds prepared by parallel synthesis. Combinatorial libraries have important features.
″ Mixtures are used in their synthesis. The use of mixtures ensures the very high efficiency of the process. Both reactants could be mixtures but for practical reasons the split-mix procedure is used: one mixture is divided into portions that are coupled with the BBs.[11][12] The mixtures are so important that there is no combinatorial library without using a mixture in the synthesis, and if a mixture is used in a process inevitably combinatorial library forms.
″ Components of the libraries need to be present in nearly equal molar quantities. In order to achieve this as closely as possible the mixtures are divided into equal portions and after pooling a thorough mixing is needed.
″ Since the structure of components is unknown deconvolution methods need to be used in screening. For this reason, encoding methods had been developed. Coding molecules are attached to the beads of the solid support that record the coupled BBs and their sequence. One of these methods is encoding by DNA oligomers.
″ It is a remarkable feature of combinatorial libraries that the whole compound mixture can be screened in a single process.
Since both the synthesis and screening are very efficient procedures the use of combinatorial libraries in pharmaceutical research leads to enormous savings.
In solid phase combinatorial synthesis only a single compound forms in each bead. For this reason, the number of components in the library can't exceed the number of beads of the solid support. This means that the number of components in such libraries is limited. This restraint was eliminated by Harbury and Halpin. In their synthesis of DELs, the solid support is omitted and BBs are attached directly to the encoding DNA oligomers.[13] This new approach helps to increase practically unlimitedly the number of components of DNA encoded combinatorial libraries (DECLs).
Split-&-Pool DNA Encoding
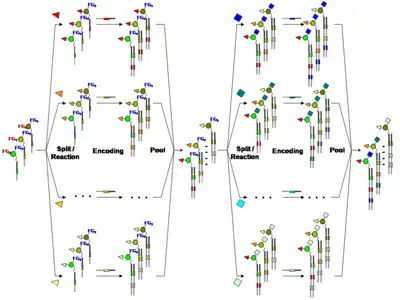
In order to apply combinatorial chemistry for the synthesis of DNA-encoded chemical libraries, a Split-&-Pool approach was pursued.[11][12] Initially a set of unique DNA-oligonucleotides (n) each containing a specific coding sequence is chemically conjugated to a corresponding set of small organic molecules. Consequently, the oligonucleotide-conjugate compounds are mixed ("Pool") and divided ("Split") into a number of groups (m). In appropriate conditions a second set of building blocks (m) are coupled to the first one and a further oligonucleotide which is coding for the second modification is enzymatically introduced before mixing again. This “split-&-pool” steps can be iterated a number of times (r) increasing at each round the library size in a combinatorial manner (i.e. (n x m)r). Alternatively, peptide nucleic acids have been used to encode libraries prepared by "split-&-pool" method.[14] A benefit of PNA-encoding is that the chemistry can be performed by standard SPPS.[15]
Stepwise coupling of coding DNA fragments to nascent organic molecules
A promising strategy for the construction of DNA-encoded libraries is represented by the use of multifunctional building blocks covalently conjugated to an oligonucleotide serving as a “core structure” for library synthesis. In a ‘pool-and-split’ fashion a set of multifunctional scaffolds undergo orthogonal reactions with series of suitable reactive partners. Following each reaction step, the identity of the modification is encoded by an enzymatic addition of DNA segment to the original DNA “core structure”.[16][17] The use of N-protected amino acids covalently attached to a DNA fragment allow, after a suitable deprotection step, a further amide bond formation with a series of carboxylic acids or a reductive amination with aldehydes. Similarly, diene carboxylic acids used as scaffolds for library construction at the 5’-end of amino modified oligonucleotide, could be subjected to a Diels-Alder reaction with a variety of maleimide derivatives. After completion of the desired reaction step, the identity of the chemical moiety added to the oligonucleotide is established by the annealing of a partially complementary oligonucleotide and by a subsequent Klenow fill-in DNA-polymerization, yielding a double stranded DNA fragment. The synthetic and encoding strategies described above enable the facile construction of DNA-encoded libraries of a size up to 104 member compounds carrying two sets of “building blocks”. However the stepwise addition of at least three independent sets of chemical moieties to a tri-functional core building block for the construction and encoding of a very large DNA-encoded library (comprising up to 106 compounds) can also be envisaged.[16](Fig.2)
Encoded self-assembling chemical libraries
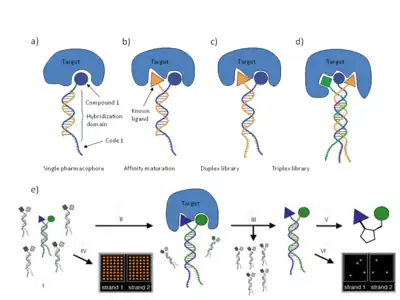
Encoded Self-Assembling Chemical (ESAC) libraries rely on the principle that two sublibraries of a size of x members (e.g. 103) containing a constant complementary hybridization domain can yield a combinatorial DNA-duplex library after hybridization with a complexity of x2 uniformly represented library members (e.g. 106).[18] Each sub-library member would consist of an oligonucleotide containing a variable, coding region flanked by a constant DNA sequence, carrying a suitable chemical modification at the oligonucleotide extremity.[18] The ESAC sublibraries can be used in at least four different embodiments.[18]
- A sub-library can be paired with a complementary oligonucleotide and used as a DNA encoded library displaying a single covalently linked compound for affinity-based selection experiments.
- A sub-library can be paired with an oligonucleotide displaying a known binder to the target, thus enabling affinity maturation strategies.
- Two individual sublibraries can be assembled combinatorially and used for the de novo identification of bindentate binding molecules.
- Three different sublibraries can be assembled to form a combinatorial triplex library.
Preferential binders isolated from an affinity-based selection can be PCR-amplified and decoded on complementary oligonucleotide microarrays[19] or by concatenation of the codes, subcloning and sequencing.[18] The individual building blocks can eventually be conjugated using suitable linkers to yield a drug-like high-affinity compound. The characteristics of the linker (e.g. length, flexibility, geometry, chemical nature and solubility) influence the binding affinity and the chemical properties of the resulting binder.(Fig.3)
Bio-panning experiments on HSA of a 600-member ESAC library allowed the isolation of the 4-(p-iodophenyl)butanoic moiety. The compound represents the core structure of a series of portable albumin binding molecules and of Albufluor a recently developed fluorescein angiographic contrast agent currently under clinical evaluation.[20]
ESAC technology has been used for the isolation of potent inhibitors of bovine trypsin and for the identification of novel inhibitors of stromelysin-1 (MMP-3), a matrix metalloproteinase involved in both physiological and pathological tissue remodeling processes, as well as in disease processes, such as arthritis and metastasis.[21]
Evolution-based technologies
DNA-routing
In 2004, D.R. Halpin and P.B. Harbury presented a novel intriguing method for the construction of DNA-encoded libraries. For the first time the DNA-conjugated templates served for both encoding and programming the infrastructure of the “split-&-pool” synthesis of the library components.[22] The design of Halpin and Harbury enabled alternating rounds of selection, PCR amplification and diversification with small organic molecules, in complete analogy to phage display technology. The DNA-routing machinery consists of a series of connected columns bearing resin-bound anticodons, which could sequence-specifically separate a population of DNA-templates into spatially distinct locations by hybridization.[22] According to this split-and-pool protocol a peptide combinatorial library DNA-encoded of 106 members was generated.[23]
DNA-templated synthesis
In 2001 David Liu and co-workers showed that complementary DNA oligonucleotides can be used to assist certain synthetic reactions, which do not efficiently take place in solution at low concentration.[24][25] A DNA-heteroduplex was used to accelerate the reaction between chemical moieties displayed at the extremities of the two DNA strands. Furthermore, the "proximity effect", which accelerates bimolecular reaction, was shown to be distance-independent (at least within a distance of 30 nucleotides).[24][25] In a sequence-programmed fashion oligonucleotides carrying one chemical reactant group were hybridized to complementary oligonucleotide derivatives carrying a different reactive chemical group. The proximity conferred by the DNA hybridization drastically increases the effective molarity of the reaction reagents attached to the oligonucleotides, enabling the desired reaction to occur even in an aqueous environment at concentrations which are several orders of magnitude lower than those needed for the corresponding conventional organic reaction not DNA-templated.[26] Using a DNA-templated set-up and sequence-programmed synthesis Liu and co-workers generated a 64-member compound DNA encoded library of macrocycles.[27]
3-Dimensional proximity-based technology (YoctoReactor technology)
The YoctoReactor (yR) is a 3D proximity-driven approach which exploits the self-assembling nature of DNA oligonucleotides into 3, 4 or 5-way junctions to direct small molecule synthesis at the center of the junction. Figure 5 illustrates the basic concept with a 4-way DNA junction.
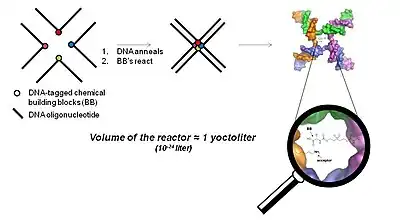
The center of the DNA junction constitutes a volume on the order of a yoctoliter, hence the name YoctoReactor. This volume contains a single molecule reaction yielding reaction concentrations in the high mM range. The effective concentration facilitated by the DNA greatly accelerates chemical reactions that otherwise would not take place at the actual concentration several orders of magnitude lower.
Building a yR library
Figure 6 illustrates the generation of a yR library using a 3-way DNA junction.
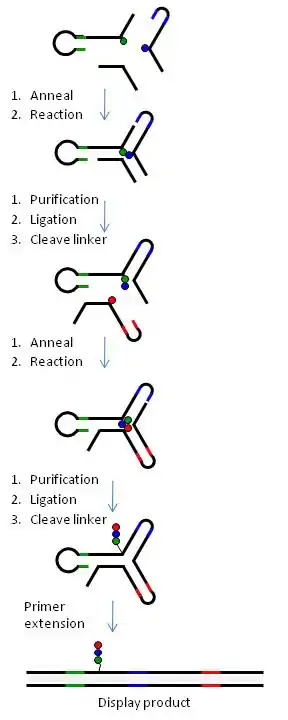
In summary, chemical building-blocks (BB) are attached via cleavable or non-cleavable linkers to three types of bispecific DNA oligonucleotides (oligo-BBs) representing each arm of the yR. To facilitate synthesis in a combinatorial manner, the oligo-BBs are designed such that the DNA contains (a) the code for an attached BB at the distal end of the oligo (colored lines) and (b) areas of constant DNA sequence (black lines) to bring about the self-assembly of the DNA into a 3-way junction (independently of the BB) and the subsequent chemical reaction. Chemical reactions are performed via a stepwise procedure and after each step the DNA is ligated and the product purified by polyacryamide gel electrophoresis. Cleavable linkers (BB-DNA) are used for all but one position yielding a library of small molecules with a single covalent link to the DNA code. Table 1 outlines how libraries of different sizes can be generated using yR technology.

The yR design approach provides an unvarying reaction site with regard to both (a) distance between reactants and (b) sequence environment surrounding the reaction site. Furthermore, the intimate connection between the code and the BB on the oligo-BB moieties which are mixed combinatorially in a single pot confers a high fidelity to the encoding of the library. The code of the synthesized products, furthermore, is not preset, but rather is assembled combinatorially and synthesized in synchronicity with the innate product.
Homogeneous screening of yoctoreactor libraries
A homogeneous method for screening yoctoreactor libraries (yR) has recently been developed which uses water-in-oil emulsion technology to isolate individual ligand-target complexes. Called Binder Trap Enrichment (BTE), ligands to a protein target are identified by trapping binding pairs (DNA-labelled protein target and yR ligand) in emulsion droplets during dissociation dominated kinetics. Once trapped, the target and ligand DNA are joined by ligation, thus preserving the binding information.
Hereafter, identification of hits is essentially a counting exercise: information on binding events is deciphered by sequencing and counting the joined DNA - selective binders are counted with a much higher frequency than random binders. This is possible because random trapping of target and ligand is "diluted" by the high number of water droplets in the emulsion. The low noise and background signal characteristic of BTE is attributed to the "dilution" of the random signal, the lack of surface artifacts and the high fidelity of the yR library and screening method. Screening is performed in a single tube method. Biologically active hits are identified in a single round of BTE characterized by a low false positive rate.
BTE mimics the non-equilibrium nature of in vivo ligand-target interactions and offers the unique possibility to screen for target specific ligands based on ligand-target residence time because the emulsion, which traps the binding complex, is formed during a dynamic dissociation phase.
Decoding of DNA-encoded chemical libraries
Following selection from DNA-encoded chemical libraries, the decoding strategy for the fast and efficient identification of the specific binding compounds is crucial for the further development of the DEL technology. So far, Sanger-sequencing-based decoding, microarray-based methodology and high-throughput sequencing techniques represented the main methodologies for the decoding of DNA-encoded library selections.
Sanger sequencing-based decoding
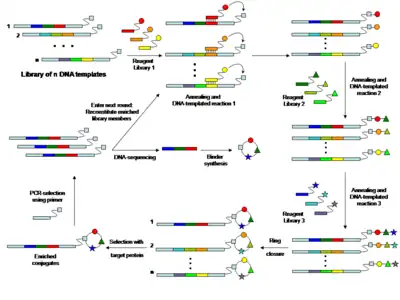
Although many authors implicitly envisaged a traditional Sanger sequencing-based decoding,[7][8][18][23][27] the number of codes to sequence simply according to the complexity of the library is definitely an unrealistic task for a traditional Sanger sequencing approach. Nevertheless, the implementation of Sanger sequencing for decoding DNA-encoded chemical libraries in high-throughput fashion was the first to be described.[18] After selection and PCR amplification of the DNA-tags of the library compounds, concatamers containing multiple coding sequences were generated and ligated into a vector. Following Sanger sequencing of a representative number of the resulting colonies revealed the frequencies of the codes present in the DNA-encoded library sample before and after selection.[18]
Microarray-based decoding
A DNA microarray is a device for high-throughput investigations widely used in molecular biology and in medicine. It consists of an arrayed series of microscopic spots (‘features’ or ‘locations’) containing few picomoles of oligonucleotides carrying a specific DNA sequence. This can be a short section of a gene or other DNA element that are used as probes to hybridize a DNA or RNA sample under suitable conditions. Probe-target hybridization is usually detected and quantified by fluorescence-based detection of fluorophore-labeled targets to determine relative abundance of the target nucleic acid sequences. Microarray has been used for the successfully decoding of ESAC DNA-encoded libraries[18] and PNA-encoded libraries.[28] The coding oligonucleotides representing the individual chemical compounds in the library, are spotted and chemically linked onto the microarray slides, using a BioChip Arrayer robot. Subsequently, the oligonucleotide tags of the binding compounds isolated from the selection are PCR amplified using a fluorescent primer and hybridized onto the DNA-microarray slide. Afterwards, microarrays are analyzed using a laser scan and spot intensities detected and quantified. The enrichment of the preferential binding compounds is revealed comparing the spots intensity of the DNA-microarray slide before and after selection.[18]
Decoding by high throughput sequencing
According to the complexity of the DNA encoded chemical library (typically between 103 and 106 members), a conventional Sanger sequencing based decoding is unlikely to be usable in practice, due both to the high cost per base for the sequencing and to the tedious procedure involved.[29] High throughput sequencing technologies exploited strategies that parallelize the sequencing process displacing the use of capillary electrophoresis and producing thousands or millions of sequences at once. In 2008 was described the first implementation of a high-throughput sequencing technique originally developed for genome sequencing (i.e. "454 technology") to the fast and efficient decoding of a DNA encoded chemical library comprising 4000 compounds.[16] This study led to the identification of novel chemical compounds with submicromolar dissociation constants towards streptavidin and definitely shown the feasibility to construct, perform selections and decode DNA-encoded libraries containing millions of chemical compounds.[16]
See also
References
- Smith GP (June 1985). "Filamentous fusion phage: novel expression vectors that display cloned antigens on the virion surface". Science. 228 (4705): 1315–7. Bibcode:1985Sci...228.1315S. doi:10.1126/science.4001944. PMID 4001944.
- Hoogenboom HR (2002). "Overview of antibody phage-display technology and its applications". Antibody Phage Display. Methods in Molecular Biology. Vol. 178. pp. 1–37. doi:10.1385/1-59259-240-6:001. ISBN 978-1-59259-240-1. PMID 11968478.
- Furka Á. Tanulmány, gyógyászatilag hasznosítható peptidek szisztematikus felkutatásának lehetőségéről. Study on the possibility of systematic searching for pharmaceutically useful peptides) https://mersz.hu/mod/object.php?objazonosito=matud202006_f42772_i2
- Furka Á (2002). Combinatorial Chemistry 20 years on.., Drug DiscovToday 7; 1-4.
- Goodnow, Robert A. Jr. (2014). A HANDBOOK FORDNA-ENCODEDCHEMISTRYTheory and Applicationsfor Exploring ChemicalSpace and Drug Discovery. Waltham, MA, USA: John Wiley & Sons, Inc., Hoboken, New Jersey. pp. 2–13.
- Brenner S, Lerner RA (June 1992). "Encoded combinatorial chemistry". Proceedings of the National Academy of Sciences of the United States of America. 89 (12): 5381–3. Bibcode:1992PNAS...89.5381B. doi:10.1073/pnas.89.12.5381. PMC 49295. PMID 1608946.
- Nielsen J, Brenner S, Janda KD (1993). "Synthetic methods for the implementation of encoded combinatorial chemistry". Journal of the American Chemical Society. 115 (21): 9812–9813. doi:10.1021/ja00074a063.
- Needels MC, Jones DG, Tate EH, Heinkel GL, Kochersperger LM, Dower WJ, Barrett RW, Gallop MA (November 1993). "Generation and screening of an oligonucleotide-encoded synthetic peptide library". Proceedings of the National Academy of Sciences of the United States of America. 90 (22): 10700–4. Bibcode:1993PNAS...9010700N. doi:10.1073/pnas.90.22.10700. PMC 47845. PMID 7504279.
- Mukund S. Chorghade (2006). Drug discovery and development. New York: Wiley-Interscience. pp. 129–167. ISBN 978-0-471-39848-6.
- Heitner TR, Hansen NJ (November 2009). "Streamlining hit discovery and optimization with a yoctoliter scale DNA reactor". Expert Opinion on Drug Discovery. 4 (11): 1201–13. doi:10.1517/17460440903206940. PMID 23480437. S2CID 20881306.
- Á. Furka, F. Sebestyén, M. Asgedom, G. Dibó, Cornucopia of peptides by synthesis In Highlights of Modern Biochemistry, Proceedings of the 14th International Congress of Biochemistry, VSP. Utrecht, The Netherlands, 1988, Vol. 5, p 47.
- Furka Á, Sebestyén F, Asgedom M, Dibó G ( 1991) General method for rapid synthesis of multicomponent peptide mixtures. Int J Peptide Protein Res 37; 487-93.
- Harbury DR, Halpin DR (2000) WO 00/23458.
- Winssinger N, Damoiseaux R, Tully DC, Geierstanger BH, Burdick K, Harris JL (October 2004). "PNA-encoded protease substrate microarrays". Chemistry & Biology. 11 (10): 1351–60. doi:10.1016/j.chembiol.2004.07.015. PMID 15489162.
- Zambaldo C, Barluenga S, Winssinger N (June 2015). "PNA-encoded chemical libraries". Current Opinion in Chemical Biology. 26: 8–15. doi:10.1016/j.cbpa.2015.01.005. PMID 25621730.
- Mannocci L, Zhang Y, Scheuermann J, Leimbacher M, De Bellis G, Rizzi E, Dumelin C, Melkko S, Neri D (November 2008). "High-throughput sequencing allows the identification of binding molecules isolated from DNA-encoded chemical libraries". Proceedings of the National Academy of Sciences of the United States of America. 105 (46): 17670–5. Bibcode:2008PNAS..10517670M. doi:10.1073/pnas.0805130105. PMC 2584757. PMID 19001273.
- Buller F, Mannocci L, Zhang Y, Dumelin CE, Scheuermann J, Neri D (November 2008). "Design and synthesis of a novel DNA-encoded chemical library using Diels-Alder cycloadditions". Bioorganic & Medicinal Chemistry Letters. 18 (22): 5926–31. doi:10.1016/j.bmcl.2008.07.038. PMID 18674904.
- Melkko S, Scheuermann J, Dumelin CE, Neri D (May 2004). "Encoded self-assembling chemical libraries". Nature Biotechnology. 22 (5): 568–74. doi:10.1038/nbt961. PMID 15097996. S2CID 24806778.
- Lovrinovic M, Niemeyer CM (May 2005). "DNA microarrays as decoding tools in combinatorial chemistry and chemical biology". Angewandte Chemie. 44 (21): 3179–83. doi:10.1002/anie.200500645. PMID 15861437.
- Dumelin CE, Trüssel S, Buller F, Trachsel E, Bootz F, Zhang Y, Mannocci L, Beck SC, Drumea-Mirancea M, Seeliger MW, Baltes C, Müggler T, Kranz F, Rudin M, Melkko S, Scheuermann J, Neri D (2008). "A portable albumin binder from a DNA-encoded chemical library". Angewandte Chemie. 47 (17): 3196–201. doi:10.1002/anie.200704936. PMID 18366035.
- Melkko S, Zhang Y, Dumelin CE, Scheuermann J, Neri D (2007). "Isolation of high-affinity trypsin inhibitors from a DNA-encoded chemical library". Angewandte Chemie. 46 (25): 4671–4. doi:10.1002/anie.200700654. PMID 17497616.
- Halpin DR, Harbury PB (July 2004). "DNA display I. Sequence-encoded routing of DNA populations". PLOS Biology. 2 (7): E173. doi:10.1371/journal.pbio.0020173. PMC 434148. PMID 15221027.

- Halpin DR, Harbury PB (July 2004). "DNA display II. Genetic manipulation of combinatorial chemistry libraries for small-molecule evolution". PLOS Biology. 2 (7): E174. doi:10.1371/journal.pbio.0020174. PMC 434149. PMID 15221028.
- Gartner ZJ, Liu DR (July 2001). "The generality of DNA-templated synthesis as a basis for evolving non-natural small molecules". Journal of the American Chemical Society. 123 (28): 6961–3. doi:10.1021/ja015873n. PMC 2820563. PMID 11448217.
- Calderone CT, Puckett JW, Gartner ZJ, Liu DR (November 2002). "Directing otherwise incompatible reactions in a single solution by using DNA-templated organic synthesis". Angewandte Chemie. 41 (21): 4104–8. doi:10.1002/1521-3773(20021104)41:21<4104::AID-ANIE4104>3.0.CO;2-O. PMID 12412096.
- Li X, Liu DR (September 2004). "DNA-templated organic synthesis: nature's strategy for controlling chemical reactivity applied to synthetic molecules". Angewandte Chemie. 43 (37): 4848–70. doi:10.1002/anie.200400656. PMID 15372570.
- Gartner ZJ, Tse BN, Grubina R, Doyon JB, Snyder TM, Liu DR (September 2004). "DNA-templated organic synthesis and selection of a library of macrocycles". Science. 305 (5690): 1601–5. Bibcode:2004Sci...305.1601G. doi:10.1126/science.1102629. PMC 2814051. PMID 15319493.
- Harris J, Mason DE, Li J, Burdick KW, Backes BJ, Chen T, Shipway A, Van Heeke G, Gough L, Ghaemmaghami A, Shakib F, Debaene F, Winssinger N (October 2004). "Activity profile of dust mite allergen extract using substrate libraries and functional proteomic microarrays". Chemistry & Biology. 11 (10): 1361–72. doi:10.1016/j.chembiol.2004.08.008. PMID 15489163.
- Sanger F, Nicklen S, Coulson AR (December 1977). "DNA sequencing with chain-terminating inhibitors". Proceedings of the National Academy of Sciences of the United States of America. 74 (12): 5463–7. Bibcode:1977PNAS...74.5463S. doi:10.1073/pnas.74.12.5463. PMC 431765. PMID 271968.