DNA shuffling
DNA shuffling, also known as molecular breeding, is an in vitro random recombination method to generate mutant genes for directed evolution and to enable a rapid increase in DNA library size.[1][3][4][5][6][7][8][9] Three procedures for accomplishing DNA shuffling are molecular breeding which relies on homologous recombination or the similarity of the DNA sequences, restriction enzymes which rely on common restriction sites, and nonhomologous random recombination which requires the use of hairpins.[1] In all of these techniques, the parent genes are fragmented and then recombined.[1][4]
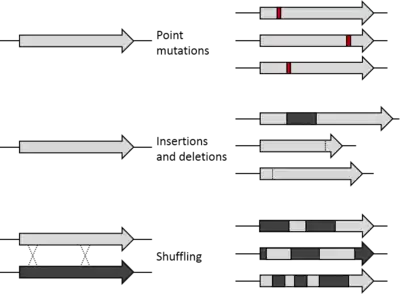
DNA shuffling utilizes random recombination as opposed to site-directed mutagenesis in order to generate proteins with unique attributes or combinations of desirable characteristics encoded in the parent genes such as thermostability and high activity.[1][8] The potential for DNA shuffling to produce novel proteins is exemplified by the figure shown on the right which demonstrates the difference between point mutations, insertions and deletions, and DNA shuffling.[1] Specifically, this figure shows the use of DNA shuffling on two parent genes which enables the generation of recombinant proteins that have a random combination of sequences from each parent gene.[1] This is distinct from point mutations in which one nucleotide has been changed, inserted, or deleted and insertions or deletions where a sequence of nucleotides has been added or removed, respectively.[1][2] As a result of the random recombination, DNA shuffling is able to produce proteins with new qualities or multiple advantageous features derived from the parent genes.[1][4]
In 1994, Willem P.C. Stemmer published the first paper on DNA shuffling.[7] Since the introduction of the technique, DNA shuffling has been applied to protein and small molecule pharmaceuticals, bioremediation, vaccines, gene therapy, and evolved viruses.[3][10][11][12] Other techniques which yield similar results to DNA shuffling include random chimeragenesis on transient templates (RACHITT), random printing in vitro recombination (RPR), and the staggered extension process (StEP).[4][7][13]
History
DNA shuffling by molecular breeding was first reported in 1994 by Willem P.C. Stemmer.[1][7] He started by fragmenting the β-lactamase gene that had been amplified with the polymerase chain reaction (PCR) by using DNase I, which randomly cleaves DNA.[14][15] He then completed a modified PCR reaction where primers were not employed which resulted in the annealing of homologous fragments or fragments with similar sequences.[14] Finally, these fragments were amplified by PCR.[14] Stemmer reported that the use of DNA shuffling in combination with backcrossing resulted in the elimination of non-essential mutations and an increase in the production of the antibiotic cefotaxime.[14] He also emphasized the potential for molecular evolution with DNA shuffling.[16] Specifically, he indicated the technique could be used to modify proteins.[16]
DNA shuffling has since been applied to generate libraries of hybrid or chimeric genes and has inspired family shuffling which is defined as the use of related genes in DNA shuffling.[17][18][19] Additionally, DNA shuffling has been applied to protein and small molecule pharmaceuticals, bioremediation, gene therapy, vaccines, and evolved viruses.[3][10][11][12][20]
Procedures
Molecular breeding
First, DNase I is used to fragment a set of parent genes into segments of double stranded DNA ranging from 10-50 bp to more than 1 kbp.[4][16] This is followed by a PCR without primers.[14] In the PCR, DNA fragments with sufficiently overlapping sequences will anneal to each other and then be extended by DNA polymerase.[1][4][5][7][14][16][21] The PCR extension will not occur unless there are DNA sequences of high similarity.[1] The important factors influencing the sequences synthesized in DNA shuffling are the DNA polymerase, salt concentrations, and annealing temperature.[10] For example, the use of Taq polymerase for amplification of a 1 kbp fragment in a PCR of 20 cycles results in 33% to 98% of the products containing one or more mutations.[21]
Multiple cycles of PCR extension can be used to amplify the fragments.[1][4][5][7][14][16][21] The addition of primers that are designed to be complementary to the ends of the extended fragments are added to further amplify the sequences with another PCR.[1][14][21] Primers may be chosen to have additional sequences added on to their 5’ ends, such as sequences for restriction enzyme recognition sites which are needed for ligation into a cloning vector.[1][14]
It is possible to recombine portions of the parent genes to generate hybrids or chimeric forms with unique properties, hence the term DNA shuffling.[22] The disadvantage of molecular breeding is the requirement for the similarity between the sequences, which has inspired the development of other procedures for DNA shuffling.[1]
Restriction enzymes
Restriction enzymes are employed to fragment the parent genes.[1][21] The fragments are then joined together through ligation which can be accomplished with DNA ligase.[1] For example, if two parent genes have three restriction sites fourteen different full-length gene hybrids can be created.[1] The number of unique full-length hybrids is determined by the fact that a gene with three restriction sites can be broken up into four fragments.[1] Thus, there are two options for each of the four positions minus the combinations that would recreate the two parent genes yielding 24 - 2 = 14 different full-length hybrid genes.[1]
The main difference between DNA shuffling with restriction enzymes and molecular breeding is molecular breeding relies on the homology of the sequences for the annealing of the strands and PCR for extension whereas by using restriction enzymes, fragment ends that can be ligated are created.[1] The main advantages of using restriction enzymes include control over the number of recombination events and lack of PCR amplification requirement.[1][23] The main disadvantage is the requirement of common restriction enzyme sites.[1]
Nonhomologous random recombination
In order to generate segments ranging from 10-50 bp to more than 1 kb, DNase I is utilized.[4][16][24] The ends of the fragments are made blunt by adding T4 DNA polymerase.[1][24] Blunting the fragments is important for combining the fragments as incompatible sticky-ends, or overhangs, prevent end joining.[1][25][26] Hairpins with a specific restriction site are then added to the mixture of fragments.[1][24] Next, T4 DNA ligase is employed to ligate the fragments to form extended sequences.[1][24] The ligation of the hairpins to the fragments limits the length of the extended sequences by preventing the addition of more fragments.[1] Finally, in order to remove the hairpin loops, a restriction enzyme is utilized.[1][24]
Nonhomologous random recombination differs from molecular breeding as homology of the ligated sequences is not necessary which is an advantage.[1] However, because this process recombines the fragments randomly it is probable that a large fraction of the recombined DNA sequences will not have the desired characteristics which is a disadvantage.[1] Nonhomologous random recombination also differs from the use of restriction enzymes for DNA shuffling as common restriction enzyme sites on the parent genes are not required and the use of hairpins is necessary which demonstrates an advantage and disadvantage of nonhomologous random recombination over the use of restriction enzymes, respectively.[1]
Applications
Protein and small molecule pharmaceuticals
Since DNA shuffling enables the recombination of genes, protein activities can be enhanced.[3][20] For example, DNA shuffling has been used to increase the potency of phage-displayed recombinant interferons on murine and human cells.[3] Additionally, the improvement of green fluorescent protein (GFP) was accomplished with DNA shuffling by molecular breeding as a 45-fold greater signal than the standard for whole cell fluorescence was obtained.[20] Furthermore, the synthesis of diverse genes can also result in the production of proteins with novel attributes.[1] Therefore, DNA shuffling has been used to develop proteins to detoxify chemicals.[3][27] For example, the homologous recombination method of DNA shuffling by molecular breeding has been utilized to enhance the detoxification of atrazine and arsenate.[3][27]
Bioremediation
DNA shuffling has also been used to improve the degradation of biological pollutants.[12][28] Specifically, a recombinant E. coli strain has been created with the use of DNA shuffling by molecular breeding for the bioremediation of trichloroethylene (TCE), a potential carcinogen, which is less susceptible to toxic epoxide intermediates.[12][21][28]
Vaccines
The ability to select desirable recombinants with DNA shuffling has been used in combination with screening strategies to enhance vaccine candidates against infections with an emphasis on improving immunogenicity, vaccine production, stability, and cross-reactivity to multiple strains of pathogens.[3][10] Some vaccine candidates for Plasmodium falciparum, dengue virus, encephalitic alphaviruses (including: VEEV, WEEV, and EEEV), human immunodeficiency virus-1 (HIV-1), and hepatitis B virus (HBV) have been investigated.[10]
Gene therapy and evolved viruses
The requirements for human gene therapies include high purity, high-titer, and stability.[11] DNA shuffling allows for the fabrication of retroviral vectors with these attributes.[11] For example, DNA shuffling with molecular breeding was applied to six ecotropic murine leukemia virus (MLV) strains which resulted in the compilation of an extensive library of recombinant retrovirus and the identification of multiple clones with increased stability.[11] Furthermore, the application of DNA shuffling by molecular breeding on multiple parent adeno-associated virus (AAV) vectors was employed to generate a library of ten million chimeras.[29] The advantageous attributes obtained include increased resistance to human intravenous immunoglobulin (IVIG) and the production of cell tropism in the novel viruses.[29]
Comparison to other techniques
While DNA shuffling has become a useful technique for random recombination, other methods including RACHITT, RPR, and StEP have also been developed for this purpose.[4][13] Below are some advantages and disadvantages of these other methods for recombination.[4][7][13]
RACHITT
In RACHITT, fragments of single stranded (ss) parent genes are annealed onto a ss template resulting in decreased mismatching which is an advantage.[13] Additionally, RACHIIT enables genes with low sequence similarity to be recombined.[7] However, a major disadvantage is the preparation of the ss fragments of the parent genes and ss template.[7][13]
RPR
RPR makes use of random primers.[30] These random primers are annealed to template DNA and are then extended by the Klenow fragment.[30] Next, the templates are removed and the fragments are assembled by homology in a process similar to PCR.[30] Some major benefits include the smaller requirement for parent genes due to the use of ss templates and increased sequence diversity by mispriming and misincorporation.[7][30] One disadvantage of RPR is the preparation of the template.[30]
StEP
In StEP, brief cycles of primer annealing to a template and extension by polymerase are employed to generate full-length sequences.[31][32] The main advantages of StEP are the simplicity of the method and the lack of fragment purification.[7][13] The disadvantages of StEP include that it is time consuming and requires sequence homology.[7][13]
See also
References
- Glick BR (2017). Molecular biotechnology : principles and applications of recombinant DNA. Cheryl L. Patten (Fifth ed.). Washington, DC. ISBN 978-1-55581-936-1. OCLC 975991667.
{{cite book}}: CS1 maint: location missing publisher (link) - Levi T, Sloutskin A, Kalifa R, Juven-Gershon T, Gerlitz O (2020-07-14). "Efficient In Vivo Introduction of Point Mutations Using ssODN and a Co-CRISPR Approach". Biological Procedures Online. 22 (1): 14. doi:10.1186/s12575-020-00123-7. PMC 7362497. PMID 32684853.
- Patten PA, Howard RJ, Stemmer WP (December 1997). "Applications of DNA shuffling to pharmaceuticals and vaccines". Current Opinion in Biotechnology. 8 (6): 724–733. doi:10.1016/S0958-1669(97)80127-9. PMID 9425664.
- Cirino PC, Qian S (2013-01-01), Zhao H (ed.), "Chapter 2 - Protein Engineering as an Enabling Tool for Synthetic Biology", Synthetic Biology, Boston: Academic Press, pp. 23–42, doi:10.1016/b978-0-12-394430-6.00002-9, ISBN 978-0-12-394430-6
- Clark DP, Pazdernik NJ (2016), "Protein Engineering", Biotechnology, Elsevier, pp. 365–392, doi:10.1016/b978-0-12-385015-7.00011-9, ISBN 978-0-12-385015-7
- Kamada H (2013-01-01), Park K, Tsunoda SI (eds.), "5 - Generating functional mutant proteins to create highly bioactive anticancer biopharmaceuticals", Biomaterials for Cancer Therapeutics, Woodhead Publishing, pp. 95–112, doi:10.1533/9780857096760.2.95, ISBN 978-0-85709-664-7
- Bioprocessing for value-added products from renewable resources : new technologies and applications. Shang-Tian Yang (1st ed.). Amsterdam: Elsevier. 2007. ISBN 978-0-444-52114-9. OCLC 162587118.
{{cite book}}: CS1 maint: others (link) - Arkin M (2001-01-01), "In vitro Mutagenesis", in Brenner S, Miller JH (eds.), Encyclopedia of Genetics, New York: Academic Press, pp. 1010–1014, doi:10.1006/rwgn.2001.0714, ISBN 978-0-12-227080-2
- Marshall SH (November 2002). "DNA shuffling: induced molecular breeding to produce new generation long-lasting vaccines". Biotechnology Advances. 20 (3–4): 229–238. doi:10.1016/s0734-9750(02)00015-0. PMID 14550030.
- Locher CP, Paidhungat M, Whalen RG, Punnonen J (April 2005). "DNA shuffling and screening strategies for improving vaccine efficacy". DNA and Cell Biology. 24 (4): 256–263. doi:10.1089/dna.2005.24.256. PMID 15812242.
- Powell SK, Kaloss MA, Pinkstaff A, McKee R, Burimski I, Pensiero M, et al. (December 2000). "Breeding of retroviruses by DNA shuffling for improved stability and processing yields". Nature Biotechnology. 18 (12): 1279–1282. doi:10.1038/82391. PMID 11101807. S2CID 1865270.
- Rui L, Kwon YM, Reardon KF, Wood TK (May 2004). "Metabolic pathway engineering to enhance aerobic degradation of chlorinated ethenes and to reduce their toxicity by cloning a novel glutathione S-transferase, an evolved toluene o-monooxygenase, and gamma-glutamylcysteine synthetase". Environmental Microbiology. 6 (5): 491–500. doi:10.1111/j.1462-2920.2004.00586.x. PMID 15049922.
- Kurtzman AL, Govindarajan S, Vahle K, Jones JT, Heinrichs V, Patten PA (August 2001). "Advances in directed protein evolution by recursive genetic recombination: applications to therapeutic proteins". Current Opinion in Biotechnology. 12 (4): 361–370. doi:10.1016/S0958-1669(00)00228-7. PMID 11551464.
- Stemmer WP (August 1994). "Rapid evolution of a protein in vitro by DNA shuffling". Nature. 370 (6488): 389–391. Bibcode:1994Natur.370..389S. doi:10.1038/370389a0. PMID 8047147. S2CID 4363498.
- "DNase I (RNase-free) | NEB". www.neb.com. Retrieved 2021-10-30.
- Stemmer WP (October 1994). "DNA shuffling by random fragmentation and reassembly: in vitro recombination for molecular evolution". Proceedings of the National Academy of Sciences of the United States of America. 91 (22): 10747–10751. Bibcode:1994PNAS...9110747S. doi:10.1073/pnas.91.22.10747. PMC 45099. PMID 7938023.
- Kikuchi M, Ohnishi K, Harayama S (2000-02-08). "An effective family shuffling method using single-stranded DNA". Gene. 243 (1): 133–137. doi:10.1016/S0378-1119(99)00547-8. ISSN 0378-1119. PMID 10675621.
- Crameri A, Raillard SA, Bermudez E, Stemmer WP (January 1998). "DNA shuffling of a family of genes from diverse species accelerates directed evolution". Nature. 391 (6664): 288–291. Bibcode:1998Natur.391..288C. doi:10.1038/34663. PMID 9440693. S2CID 4352696.
- Coco WM, Levinson WE, Crist MJ, Hektor HJ, Darzins A, Pienkos PT, et al. (April 2001). "DNA shuffling method for generating highly recombined genes and evolved enzymes". Nature Biotechnology. 19 (4): 354–359. doi:10.1038/86744. PMID 11283594. S2CID 35360374.
- Crameri A, Whitehorn EA, Tate E, Stemmer WP (March 1996). "Improved green fluorescent protein by molecular evolution using DNA shuffling". Nature Biotechnology. 14 (3): 315–319. doi:10.1038/nbt0396-315. PMID 9630892. S2CID 22803570.
- Zhao H, Arnold FH (March 1997). "Optimization of DNA shuffling for high fidelity recombination". Nucleic Acids Research. 25 (6): 1307–1308. doi:10.1093/nar/25.6.1307. PMC 146579. PMID 9092645.
- Bacher JM, Reiss BD, Ellington AD (July 2002). "Anticipatory evolution and DNA shuffling". Genome Biology. 3 (8): REVIEWS1021. doi:10.1186/gb-2002-3-8-reviews1021. PMC 139397. PMID 12186650.
- Engler C, Gruetzner R, Kandzia R, Marillonnet S (2009-05-14). "Golden gate shuffling: a one-pot DNA shuffling method based on type IIs restriction enzymes". PLOS ONE. 4 (5): e5553. Bibcode:2009PLoSO...4.5553E. doi:10.1371/journal.pone.0005553. PMC 2677662. PMID 19436741.
- Bittker JA, Le BV, Liu JM, Liu DR (May 2004). "Directed evolution of protein enzymes using nonhomologous random recombination". Proceedings of the National Academy of Sciences of the United States of America. 101 (18): 7011–7016. Bibcode:2004PNAS..101.7011B. doi:10.1073/pnas.0402202101. PMC 406457. PMID 15118093.
- Zhu S, Peng A (June 2016). "Non-homologous end joining repair in Xenopus egg extract". Scientific Reports. 6 (1): 27797. Bibcode:2016NatSR...627797Z. doi:10.1038/srep27797. PMC 4914968. PMID 27324260.
- Ogiwara H, Kohno T (2011-12-14). "Essential factors for incompatible DNA end joining at chromosomal DNA double strand breaks in vivo". PLOS ONE. 6 (12): e28756. Bibcode:2011PLoSO...628756O. doi:10.1371/journal.pone.0028756. PMC 3237495. PMID 22194904.
- Crameri A, Dawes G, Rodriguez E, Silver S, Stemmer WP (May 1997). "Molecular evolution of an arsenate detoxification pathway by DNA shuffling". Nature Biotechnology. 15 (5): 436–438. doi:10.1038/nbt0597-436. PMID 9131621. S2CID 25669058.
- Canada KA, Iwashita S, Shim H, Wood TK (January 2002). "Directed evolution of toluene ortho-monooxygenase for enhanced 1-naphthol synthesis and chlorinated ethene degradation". Journal of Bacteriology. 184 (2): 344–349. doi:10.1128/JB.184.2.344-349.2002. PMC 139589. PMID 11751810.
- Koerber JT, Jang JH, Schaffer DV (October 2008). "DNA shuffling of adeno-associated virus yields functionally diverse viral progeny". Molecular Therapy. 16 (10): 1703–1709. doi:10.1038/mt.2008.167. PMC 2683895. PMID 18728640.
- Esteban O, Woodyer RD, Zhao H (2003). "In vitro DNA recombination by random priming". In Arnold FH, Georgiou G (eds.). Directed Evolution Library Creation. Methods in Molecular Biology. Vol. 231. Totowa, NJ: Humana Press. pp. 99–104. doi:10.1385/1-59259-395-x:99. ISBN 978-1-59259-395-8. PMID 12824607.
- Zhao H, Giver L, Shao Z, Affholter JA, Arnold FH (March 1998). "Molecular evolution by staggered extension process (StEP) in vitro recombination". Nature Biotechnology. 16 (3): 258–261. doi:10.1038/nbt0398-258. PMID 9528005. S2CID 20490024.
- Aguinaldo AM, Arnold FH (2003). "Staggered extension process (StEP) in vitro recombination". In Arnold FH, Georgiou G (eds.). Directed Evolution Library Creation. Methods in Molecular Biology. Vol. 231. Totowa, NJ: Humana Press. pp. 105–110. doi:10.1385/1-59259-395-X:105. ISBN 978-1-59259-395-8. PMID 12824608.