DataOps
DataOps is a set of practices, processes and technologies that combines an integrated and process-oriented perspective on data with automation and methods from agile software engineering to improve quality, speed, and collaboration and promote a culture of continuous improvement in the area of data analytics.[1] While DataOps began as a set of best practices, it has now matured to become a new and independent approach to data analytics.[2] DataOps applies to the entire data lifecycle[3] from data preparation to reporting, and recognizes the interconnected nature of the data analytics team and information technology operations.[4]
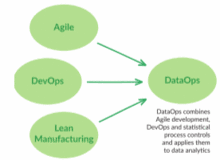
DataOps incorporates the Agile methodology to shorten the cycle time of analytics development in alignment with business goals. [3]
DevOps focuses on continuous delivery by leveraging on-demand IT resources and by automating test and deployment of software. This merging of software development and IT operations has improved velocity, quality, predictability and scale of software engineering and deployment. Borrowing methods from DevOps, DataOps seeks to bring these same improvements to data analytics.[4]
DataOps utilizes statistical process control (SPC) to monitor and control the data analytics pipeline. With SPC in place, the data flowing through an operational system is constantly monitored and verified to be working. If an anomaly occurs, the data analytics team can be notified through an automated alert.[5]
DataOps is not tied to a particular technology, architecture, tool, language or framework. Tools that support DataOps promote collaboration, orchestration, quality, security, access and ease of use.[6]
History
DataOps was first introduced by Lenny Liebmann, Contributing Editor, InformationWeek, in a blog post on the IBM Big Data & Analytics Hub titled "3 reasons why DataOps is essential for big data success" on June 19, 2014.[7] The term DataOps was later popularized by Andy Palmer of Tamr and Steph Locke.[8][4] DataOps is a moniker for "Data Operations."[3] 2017 was a significant year for DataOps with significant ecosystem development, analyst coverage, increased keyword searches, surveys, publications, and open source projects.[9] Gartner named DataOps on the Hype Cycle for Data Management in 2018.[10]
Goals and philosophy
The volume of data is forecast to grow at a rate of 32% CAGR to 180 Zettabytes by the year 2025 (Source: IDC).[6] DataOps seeks to provide the tools, processes, and organizational structures to cope with this significant increase in data.[6] Automation streamlines the daily demands of managing large integrated databases, freeing the data team to develop new analytics in a more efficient and effective way.[11][4] DataOps seeks to increase velocity, reliability, and quality of data analytics.[12] It emphasizes communication, collaboration, integration, automation, measurement and cooperation between data scientists, analysts, data/ETL (extract, transform, load) engineers, information technology (IT), and quality assurance/governance.
Implementation
Toph Whitmore at Blue Hill Research offers these DataOps leadership principles for the information technology department:[2]
- “Establish progress and performance measurements at every stage of the data flow. Where possible, benchmark data-flow cycle times.
- Define rules for an abstracted semantic layer. Ensure everyone is “speaking the same language” and agrees upon what the data (and metadata) is and is not.
- Validate with the “eyeball test”: Include continuous-improvement -oriented human feedback loops. Consumers must be able to trust the data, and that can only come with incremental validation.
- Automate as many stages of the data flow as possible including BI, data science, and analytics.
- Using benchmarked performance information, identify bottlenecks and then optimize for them. This may require investment in commodity hardware, or automation of a formerly-human-delivered data-science step in the process.
- Establish governance discipline, with a particular focus on two-way data control, data ownership, transparency, and comprehensive data lineage tracking through the entire workflow.
- Design process for growth and extensibility. The data flow model must be designed to accommodate volume and variety of data. Ensure enabling technologies are priced affordably to scale with that enterprise data growth.”
References
- Ereth, Julian (2018). "DataOps-Towards a Definition" (PDF). Proceedings of LWDA 2018: 109.
- "DataOps – It's a Secret". www.datasciencecentral.com. Retrieved 2017-04-05.
- "What is DataOps (data operations)? - Definition from WhatIs.com". SearchDataManagement. Retrieved 2017-04-05.
- "From DevOps to DataOps, By Andy Palmer - Tamr Inc". Tamr Inc. 2015-05-07. Retrieved 2017-03-21.
- DataKitchen (2017-03-07). "Lean Manufacturing Secrets that You Can Apply to Data Analytics". Medium. Retrieved 2017-08-24.
- "What is DataOps? | Nexla: Scalable Data Operations Platform for the Machine Learning Age". www.nexla.com. Retrieved 2017-09-07.
- "3 reasons why DataOps is essential for big data success". IBM Big Data & Analytics Hub. Retrieved 2018-08-10.
- Mango Solutions: #DataOps - it's a thing (honest), retrieved 2021-06-28
- DataKitchen (2017-12-19). "2017: The Year of DataOps". data-ops. Retrieved 2018-01-24.
- "Gartner Hype Cycle for Data Management Positions Three Technologies in the Innovation Trigger Phase in 2018". Gartner. Retrieved 2019-07-19.
- "5 trends driving Big Data in 2017". CIO Dive. Retrieved 2017-09-07.
- "Unravel Data Advances Application Performance Management for Big Data". Database Trends and Applications. 2017-03-10. Retrieved 2017-09-07.
- "DataOpticon - YouTube". www.youtube.com. Retrieved 2021-06-28.
- "DataOps Summit". www.dataopssummit-sf.com. Retrieved 2021-06-28.
- Intelligence, Corinium Global. "DataOps Champions Online 2021 | Corinium". dco-dataops.coriniumintelligence.com. Retrieved 2021-06-28.