Data grid
A data grid is an architecture or set of services that gives individuals or groups of users the ability to access, modify and transfer extremely large amounts of geographically distributed data for research purposes.[1] Data grids make this possible through a host of middleware applications and services that pull together data and resources from multiple administrative domains and then present it to users upon request. The data in a data grid can be located at a single site or multiple sites where each site can be its own administrative domain governed by a set of security restrictions as to who may access the data.[2] Likewise, multiple replicas of the data may be distributed throughout the grid outside their original administrative domain and the security restrictions placed on the original data for who may access it must be equally applied to the replicas.[3] Specifically developed data grid middleware is what handles the integration between users and the data they request by controlling access while making it available as efficiently as possible. The adjacent diagram depicts a high level view of a data grid.

Middleware
Middleware provides all the services and applications necessary for efficient management of datasets and files within the data grid while providing users quick access to the datasets and files.[4] There is a number of concepts and tools that must be available to make a data grid operationally viable. However, at the same time not all data grids require the same capabilities and services because of differences in access requirements, security and location of resources in comparison to users. In any case, most data grids will have similar middleware services that provide for a universal name space, data transport service, data access service, data replication and resource management service. When taken together, they are key to the data grids functional capabilities.
Universal namespace
Since sources of data within the data grid will consist of data from multiple separate systems and networks using different file naming conventions, it would be difficult for a user to locate data within the data grid and know they retrieved what they needed based solely on existing physical file names (PFNs). A universal or unified name space makes it possible to create logical file names (LFNs) that can be referenced within the data grid that map to PFNs.[5] When an LFN is requested or queried, all matching PFNs are returned to include possible replicas of the requested data. The end user can then choose from the returned results the most appropriate replica to use. This service is usually provided as part of a management system known as a Storage Resource Broker (SRB).[6] Information about the locations of files and mappings between the LFNs and PFNs may be stored in a metadata or replica catalogue.[7] The replica catalogue would contain information about LFNs that map to multiple replica PFNs.
Data transport service
Another middleware service is that of providing for data transport or data transfer. Data transport will encompass multiple functions that are not just limited to the transfer of bits, to include such items as fault tolerance and data access.[8] Fault tolerance can be achieved in a data grid by providing mechanisms that ensures data transfer will resume after each interruption until all requested data is received.[9] There are multiple possible methods that might be used to include starting the entire transmission over from the beginning of the data to resuming from where the transfer was interrupted. As an example, GridFTP provides for fault tolerance by sending data from the last acknowledged byte without starting the entire transfer from the beginning.
The data transport service also provides for the low-level access and connections between hosts for file transfer.[10] The data transport service may use any number of modes to implement the transfer to include parallel data transfer where two or more data streams are used over the same channel or striped data transfer where two or more steams access different blocks of the file for simultaneous transfer to also using the underlying built-in capabilities of the network hardware or specifically developed protocols to support faster transfer speeds.[11] The data transport service might optionally include a network overlay function to facilitate the routing and transfer of data as well as file I/O functions that allow users to see remote files as if they were local to their system. The data transport service hides the complexity of access and transfer between the different systems to the user so it appears as one unified data source.
Data access service
Data access services work hand in hand with the data transfer service to provide security, access controls and management of any data transfers within the data grid.[12] Security services provide mechanisms for authentication of users to ensure they are properly identified. Common forms of security for authentication can include the use of passwords or Kerberos (protocol). Authorization services are the mechanisms that control what the user is able to access after being identified through authentication. Common forms of authorization mechanisms can be as simple as file permissions. However, need for more stringent controlled access to data is done using Access Control Lists (ACLs), Role-Based Access Control (RBAC) and Tasked-Based Authorization Controls (TBAC).[13] These types of controls can be used to provide granular access to files to include limits on access times, duration of access to granular controls that determine which files can be read or written to. The final data access service that might be present to protect the confidentiality of the data transport is encryption.[14] The most common form of encryption for this task has been the use of SSL while in transport. While all of these access services operate within the data grid, access services within the various administrative domains that host the datasets will still stay in place to enforce access rules. The data grid access services must be in step with the administrative domains access services for this to work.
Data replication service
To meet the needs for scalability, fast access and user collaboration, most data grids support replication of datasets to points within the distributed storage architecture.[15] The use of replicas allows multiple users faster access to datasets and the preservation of bandwidth since replicas can often be placed strategically close to or within sites where users need them. However, replication of datasets and creation of replicas is bound by the availability of storage within sites and bandwidth between sites. The replication and creation of replica datasets is controlled by a replica management system. The replica management system determines user needs for replicas based on input requests and creates them based on availability of storage and bandwidth.[16] All replicas are then cataloged or added to a directory based on the data grid as to their location for query by users. In order to perform the tasks undertaken by the replica management system, it needs to be able to manage the underlying storage infrastructure. The data management system will also ensure the timely updates of changes to replicas are propagated to all nodes.
Replication update strategy
There are a number of ways the replication management system can handle the updates of replicas. The updates may be designed around a centralized model where a single master replica updates all others, or a decentralized model, where all peers update each other.[16] The topology of node placement may also influence the updates of replicas. If a hierarchy topology is used then updates would flow in a tree like structure through specific paths. In a flat topology it is entirely a matter of the peer relationships between nodes as to how updates take place. In a hybrid topology consisting of both flat and hierarchy topologies updates may take place through specific paths and between peers.
Replication placement strategy
There are a number of ways the replication management system can handle the creation and placement of replicas to best serve the user community. If the storage architecture supports replica placement with sufficient site storage, then it becomes a matter of the needs of the users who access the datasets and a strategy for placement of replicas.[17] There have been numerous strategies proposed and tested on how to best manage replica placement of datasets within the data grid to meet user requirements. There is not one universal strategy that fits every requirement the best. It is a matter of the type of data grid and user community requirements for access that will determine the best strategy to use. Replicas can even be created where the files are encrypted for confidentiality that would be useful in a research project dealing with medical files.[18] The following section contains several strategies for replica placement.
Dynamic replication
Dynamic replication is an approach to placement of replicas based on popularity of the data.[19] The method has been designed around a hierarchical replication model. The data management system keeps track of available storage on all nodes. It also keeps track of requests (hits) for which data clients (users) in a site are requesting. When the number of hits for a specific dataset exceeds the replication threshold it triggers the creation of a replica on the server that directly services the user’s client. If the direct servicing server known as a father does not have sufficient space, then the father’s father in the hierarchy is then the target to receive a replica and so on up the chain until it is exhausted. The data management system algorithm also allows for the dynamic deletion of replicas that have a null access value or a value lower than the frequency of the data to be stored to free up space. This improves system performance in terms of response time, number of replicas and helps load balance across the data grid. This method can also use dynamic algorithms that determine whether the cost of creating the replica is truly worth the expected gains given the location.[16]
Adaptive replication
This method of replication like the one for dynamic replication has been designed around a hierarchical replication model found in most data grids. It works on a similar algorithm to dynamic replication with file access requests being a prime factor in determining which files should be replicated. A key difference, however, is the number and frequency of replica creations is keyed to a dynamic threshold that is computed based on request arrival rates from clients over a period of time.[20] If the number of requests on average exceeds the previous threshold and shows an upward trend, and storage utilization rates indicate capacity to create more replicas, more replicas may be created. As with dynamic replication, the removal of replicas that have a lower threshold that were not created in the current replication interval can be removed to make space for the new replicas.
Fair-share replication
Like the adaptive and dynamic replication methods before, fair-share replication is based on a hierarchical replication model. Also, like the two before, the popularity of files play a key role in determining which files will be replicated. The difference with this method is the placement of the replicas is based on access load and storage load of candidate servers. A candidate server may have sufficient storage space but be servicing many clients for access to stored files. Placing a replicate on this candidate could degrade performance for all clients accessing this candidate server. Therefore, placement of replicas with this method is done by evaluating each candidate node for access load to find a suitable node for the placement of the replica. If all candidate nodes are equivalently rated for access load, none or less accessed than the other, then the candidate node with the lowest storage load will be chosen to host the replicas. Similar methods to the other described replication methods are used to remove unused or lower requested replicates if needed. Replicas that are removed might be moved to a parent node for later reuse should they become popular again.
Other replication
The above three replica strategies are but three of many possible replication strategies that may be used to place replicas within the data grid where they will improve performance and access. Below are some others that have been proposed and tested along with the previously described replication strategies.[21]
- Static – uses a fixed replica set of nodes with no dynamic changes to the files being replicated.
- Best Client – Each node records number of requests per file received during a preset time interval; if the request number exceeds the set threshold for a file a replica is created on the best client, one that requested the file the most; stale replicas are removed based on another algorithm.
- Cascading – Is used in a hierarchical node structure where requests per file received during a preset time interval is compared against a threshold. If the threshold is exceeded a replica is created at the first tier down from the root, if the threshold is exceeded again a replica is added to the next tier down and so on like a waterfall effect until a replica is placed at the client itself.
- Plain Caching – If the client requests a file it is stored as a copy on the client.
- Caching plus Cascading – Combines two strategies of caching and cascading.
- Fast Spread – Also used in a hierarchical node structure this strategy automatically populates all nodes in the path of the client that requests a file.
Tasks scheduling and resource allocation
Such characteristics of the data grid systems as large scale and heterogeneity require specific methods of tasks scheduling and resource allocation. To resolve the problem, majority of systems use extended classic methods of scheduling.[22] Others invite fundamentally different methods based on incentives for autonomous nodes, like virtual money or reputation of a node. Another specificity of data grids, dynamics, consists in the continuous process of connecting and disconnecting of nodes and local load imbalance during an execution of tasks. That can make obsolete or non-optimal results of initial resource allocation for a task. As a result, much of the data grids utilize execution-time adaptation techniques that permit the systems to reflect to the dynamic changes: balance the load, replace disconnecting nodes, use the profit of newly connected nodes, recover a task execution after faults.
Resource management system (RMS)
The resource management system represents the core functionality of the data grid. It is the heart of the system that manages all actions related to storage resources. In some data grids it may be necessary to create a federated RMS architecture because of different administrative policies and a diversity of possibilities found within the data grid in place of using a single RMS. In such a case the RMSs in the federation will employ an architecture that allows for interoperability based on an agreed upon set of protocols for actions related to storage resources.[23]
RMS functional capabilities
- Fulfillment of user and application requests for data resources based on type of request and policies; RMS will be able to support multiple policies and multiple requests concurrently
- Scheduling, timing and creation of replicas
- Policy and security enforcement within the data grid resources to include authentication, authorization and access
- Support systems with different administrative policies to inter-operate while preserving site autonomy
- Support quality of service (QoS) when requested if feature available
- Enforce system fault tolerance and stability requirements
- Manage resources, i.e. disk storage, network bandwidth and any other resources that interact directly or as part of the data grid
- Manage trusts concerning resources in administrative domains, some domains may place additional restrictions on how they participate requiring adaptation of the RMS or federation.
- Supports adaptability, extensibility, and scalability in relation to the data grid.
Topology
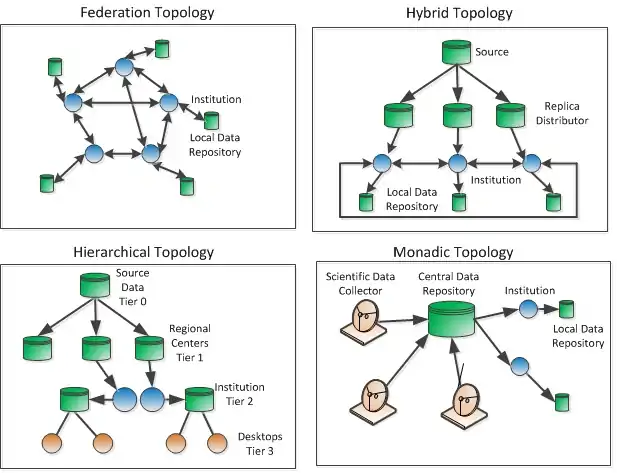
Data grids have been designed with multiple topologies in mind to meet the needs of the scientific community. On the right are four diagrams of various topologies that have been used in data grids.[24] Each topology has a specific purpose in mind for where it will be best utilized. Each of these topologies is further explained below.
Federation topology is the choice for institutions that wish to share data from already existing systems. It allows each institution control over their data. When an institution with proper authorization requests data from another institution it is up to the institution receiving the request to determine if the data will go to the requesting institution. The federation can be loosely integrated between institutions, tightly integrated or a combination of both.
Monadic topology has a central repository that all collected data is fed into. The central repository then responds to all queries for data. There are no replicas in this topology as compared to others. Data is only accessed from the central repository which could be by way of a web portal. One project that uses this data grid topology is the Network for Earthquake Engineering Simulation (NEES) in the United States.[25] This works well when all access to the data is local or within a single region with high speed connectivity.
Hierarchical topology lends itself to collaboration where there is a single source for the data and it needs to be distributed to multiple locations around the world. One such project that will benefit from this topology would be CERN that runs the Large Hadron Collider that generates enormous amounts of data. This data is located at one source and needs to be distributed around the world to organizations that are collaborating in the project.
Hybrid Topology is simply a configuration that contains an architecture consisting of any combination of the previous mentioned topologies. It is used mostly in situations where researchers working on projects want to share their results to further research by making it readily available for collaboration.
History
The need for data grids was first recognized by the scientific community concerning climate modeling, where terabyte and petabyte sized data sets were becoming the norm for transport between sites.[10] More recent research requirements for data grids have been driven by the Large Hadron Collider (LHC) at CERN, the Laser Interferometer Gravitational Wave Observatory (LIGO), and the Sloan Digital Sky Survey (SDSS). These examples of scientific instruments produce large amounts of data that need to be accessible by large groups of geographically dispersed researchers.[26][27] Other uses for data grids involve governments, hospitals, schools and businesses where efforts are taking place to improve services and reduce costs by providing access to dispersed and separate data systems through the use of data grids.[28]
From its earliest beginnings, the concept of a Data Grid to support the scientific community was thought of as a specialized extension of the “grid” which itself was first envisioned as a way to link super computers into meta-computers.[29] However, that was short lived and the grid evolved into meaning the ability to connect computers anywhere on the web to get access to any desired files and resources, similar to the way electricity is delivered over a grid by simply plugging in a device. The device gets electricity through its connection and the connection is not limited to a specific outlet. From this the data grid was proposed as an integrating architecture that would be capable of delivering resources for distributed computations. It would also be able to service numerous to thousands of queries at the same time while delivering gigabytes to terabytes of data for each query. The data grid would include its own management infrastructure capable of managing all aspects of the data grids performance and operation across multiple wide area networks while working within the existing framework known as the web.[30]
The data grid has also been defined more recently in terms of usability; what must a data grid be able to do in order for it to be useful to the scientific community. Proponents of this theory arrived at several criteria.[31] One, users should be able to search and discover applicable resources within the data grid from amongst its many datasets. Two, users should be able to locate datasets within the data grid that are most suitable for their requirement from amongst numerous replicas. Three, users should be able to transfer and move large datasets between points in a short amount of time. Four, the data grid should provide a means to manage multiple copies of datasets within the data grid. And finally, the data grid should provide security with user access controls within the data grid, i.e. which users are allowed to access which data.
The data grid is an evolving technology that continues to change and grow to meet the needs of an expanding community. One of the earliest programs begun to make data grids a reality was funded by the Defense Advanced Research Projects Agency (DARPA) in 1997 at the University of Chicago.[32] This research spawned by DARPA has continued down the path to creating open source tools that make data grids possible. As new requirements for data grids emerge projects like the Globus Toolkit will emerge or expand to meet the gap. Data grids along with the "Grid" will continue to evolve.
Notes
- Allcock, Bill; Chervenak, Ann; Foster, Ian; et al. Data Grid tools: enabling science on big distributed data
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. A taxonomy of data grids for distributed data sharing - management and processing p.37
- Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit. Adaptive replica placement in hierarchical data grids. p.15
- Padala, Pradeep. A survey of data middleware for Grid systems p.1
- Padala, Pradeep. A survey of data middleware for Grid systems
- Arcot, Rajasekar; Wan, Michael; Moore, Reagan; Schroeder, Wayne; Kremenek. Storage resource broker – managing distributed data in a grid
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. A taxonomy of data grids for distributed data sharing - management and processing p.11
- Coetzee, Serena. Reference model for a data grid approach to address data in a dynamic SDI p.16
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. A taxonomy of data grids for distributed data sharing - management and processing p.21
- Allcock, Bill; Foster,Ian; Nefedova, Veronika; Chervenak, Ann; Deelman, Ewa; Kesselman, Carl. High-performance remote access to climate simulation data: A challenge problem for data grid technologies.
- Izmailov, Rauf; Ganguly, Samrat; Tu, Nan. Fast parallel file replication in data grid p.2
- Raman, Vijayshankar; Narang, Inderpal; Crone, chris; Hass, Laura; Malaika, Susan. Services for data access and data processing on grids
- Thomas, R. K. and Sandhu R. S. Task-based authorization controls (tbac): a family of models for active and enterprise-oriented authorization management
- Sreelatha, Malempati. Grid based approach for data confidentiality. p.1
- Chervenak, Ann; Schuler, Robert; Kesselman, Carl; Koranda, Scott; Moe, Brian. Wide area data replication for scientific collaborations
- Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa. Data replication strategies in grid environments
- Padala, Pradeep. A survey of data middleware for Grid systems
- Kranthi, G. and Rekha, D. Shashi. Protected data objects replication in data grid p.40
- Belalem, Ghalem and Meroufel, Bakhta. Management and placement of replicas in a hierarchical data grid
- Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit. Adaptive replica placement in hierarchical data grids
- Ranganathan, Kavitha and Foster, Ian. Identifying dynamic replication strategies for a high performance data grid
- Epimakhov, Igor; Hameurlain, Abdelkader ; Dillon, Tharam; Morvan, Franck. Resource Scheduling Methods for Query Optimization in Data Grid Systems
- Krauter, Klaus; Buyya, Rajkumar; Maheswaran, Muthucumaru. A taxonomy and survey of grid resource management systems for distributed computing
- Zhu, Lichun. Metadata management in grid database federation
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. A taxonomy of data grids for distributed data sharing - management and processing p.16
- Allcock, Bill; Chervenak, Ann; Foster, Ian; et al. p.571
- Tierney, Brian L. Data grids and data grid performance issues. p.7
- Thibodeau, P. Governments plan data grid projects
- Heingartner, douglas. The grid: the next-gen internet
- Heingartner, douglas. The grid: the next-gen internet
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. A taxonomy of data grids for distributed data sharing - management and processing p.1
- Globus. About the globus toolkit
References
- Allcock, Bill; Chervenak, Ann; Foster, Ian; Kesselman, Carl; Livny, Miron (2005). "Data Grid tools: enabling science on big distributed data". Journal of Physics: Conference Series. 16 (1): 571–575. Bibcode:2005JPhCS..16..571A. CiteSeerX 10.1.1.379.4325. doi:10.1088/1742-6596/16/1/079. S2CID 250673712.
- Allcock, Bill; Foster, Ian; Nefedova, Veronika l; Chervenak, Ann; Deelman, Ewa; Kesselman, Carl; Lee, Jason; Sim, Alex; Shoshani, Arie; Drach, Bob; Williams, Dean (2001). "High-performance remote access to climate simulation data: A challenge problem for data grid technologies". ACM Press. CiteSeerX 10.1.1.64.6603.
{{cite journal}}: Cite journal requires|journal=(help)
- Arcot, Rajasekar; Wan, Michael; Moore, Reagan; Schroeder, Wayne; Kremenek, George. "Storage resource broker – managing distributed data in a grid". Archived from the original on May 7, 2006. Retrieved April 28, 2012.
- Belalem, Ghalem; Meroufel, Bakhta (2011). "Management and placement of replicas in a hierarchical data grid". International Journal of Distributed and Parallel Systems. 2 (6): 23–30. doi:10.5121/ijdps.2011.2603. Retrieved April 28, 2012.
- Chervenak, A.; Foster, I.; Kesselman, C.; Salisbury, C.; Tuecke, S. (2001). "The data grid: towards an architecture for the distributed management and analysis of large scientific datasets" (PDF). Journal of Network and Computer Applications. 23 (3): 187–200. CiteSeerX 10.1.1.32.6963. doi:10.1006/jnca.2000.0110. Retrieved April 11, 2012.
- Chervenak, Ann; Schuler, Robert; Kesselman, Carl; Koranda, Scott; Moe, Brian (November 14, 2005). "Wide area data replication for scientific collaborations" (PDF). IEEE. Retrieved April 25, 2012.
- Coetzee, Serena (2012). "Reference model for a data grid approach to address data in a dynamic SDI". GeoInformatica. 16 (1): 111–129. doi:10.1007/s10707-011-0129-4. hdl:2263/18263. S2CID 19837152.
- Epimakhov, Igor; Hameurlain, Abdelkader; Dillon, Tharam; Morvan, Franck (2011). "Resource Scheduling Methods for Query Optimization in Data Grid Systems". Advances in Databases and Information Systems. 15th International Conference, ADBIS 2011. Vienna, Austria: Springer Berlin Heidelberg. pp. 185–199. doi:10.1007/978-3-642-23737-9_14.
- Globus (2012). "About the globus toolkit". Globus. Retrieved May 27, 2012.
- Heingartner, Douglas (March 8, 2001). "The Grid: The Next-Gen Internet". Wired. Archived from the original on May 4, 2012. Retrieved May 13, 2012.
- Izmailov, Rauf; Ganguly, Samrat; Tu, Nan (2004). "Fast parallel file replication in data grid" (PDF). Archived from the original (PDF) on April 21, 2012. Retrieved May 10, 2012.
- Kranthi, G. Aruna; Rekha, D. Shashi (2012). "Protected data objects replication in data grid". International Journal of Network Security & Its Applications. 4 (1): 29–41. doi:10.5121/ijnsa.2012.4103. ISSN 0975-2307.
- Krauter, Klaus; Buyya, Rajkumar; Maheswaran, Muthucumaru (2002). "A taxonomy and survey of grid resource management systems for distributed computing". Software: Practice and Experience. 32 (2): 135–164. CiteSeerX 10.1.1.38.2122. doi:10.1002/spe.432. S2CID 816774.
- Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa (2002). "Data replication strategies in grid environments". Fifth International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP’02). Press. pp. 378–383. CiteSeerX 10.1.1.11.5473.
- Padala, Pradeep. "A survey of data middleware for Grid systems". CiteSeerX 10.1.1.114.1901.
{{cite journal}}: Cite journal requires|journal=(help)
- Raman, Vijayshankar; Narang, Inderpal; Crone, Chris; Hass, Laura; Malaika, Susan (February 9, 2003). "Services for data access and data processing on grids" (PDF). Retrieved May 10, 2012.
- Ranganathan, Kavitha; Foster, Ian (2001). "Identifying dynamic replication strategies for a high performance data grid". In Proc. of the International Grid Computing Workshop. pp. 75–86. CiteSeerX 10.1.1.20.6836. doi:10.1007/3-540-45644-9_8.
- Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit (2010). "Adaptive replica placement in hierarchical data grids". Journal of Physics: Conference Series. 256 (1): 1–18. Bibcode:2010JPhCS.256a2020S. doi:10.1088/1742-6596/256/1/012020.
- Sreelatha, Malempati (2011). "Grid based approach for data confidentiality". International Journal of Computer Applications. 25 (9): 1–5. Bibcode:2011IJCA...25i...1M. CiteSeerX 10.1.1.259.4326. doi:10.5120/3063-4186. ISSN 0975-8887.
- Thibodeau, P. (May 30, 2005). "Governments plan data grid projects". Computerworld. 39 (42): 14. ISSN 0010-4841. Retrieved April 28, 2012.
- Thomas, R. K.; Sandhu, R. S. (1997). "Task-based authorization controls (tbac): a family of models for active and enterprise-oriented authorization management" (PDF). Retrieved April 28, 2012.
- Tierney, Brian L. (2000). "Data grids and data grid performance issues" (PDF). Retrieved April 28, 2012.
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri (2006). "A taxonomy of data grids for distributed data sharing, management and processing" (PDF). ACM Computing Surveys. 38 (1): 1–60. arXiv:cs/0506034. CiteSeerX 10.1.1.59.6924. doi:10.1145/1132952.1132955. S2CID 1379579. Retrieved April 10, 2012.
- Zhu, Lichun. "Metadata management in grid database federation" (PDF). Retrieved May 15, 2012.
Further reading
- Allcock, W. (April 2003). "Gridftp: protocol extensions to ftp for the grid" (PDF). Argonne National Laboratory. Retrieved April 20, 2012.
- Allcock, W.; Bresnahan, J.; Kettimuthu, R.; Link, M.; Dumitrescu, C.; Raicu, I.; Foster, I. (November 2005). "The globus striped gridftp framework and server" (PDF). ACM Press. Retrieved April 20, 2012.
- Foster, Ian; Kesselman, Carl; Tuecke, Steven (2001). "The anatomy of the grid enabling scalable virtual organizations" (PDF). International Journal of High Performance Computing Applications. 15 (3): 200–222. arXiv:cs/0103025. Bibcode:2001cs........3025F. CiteSeerX 10.1.1.24.9069. doi:10.1177/109434200101500302. S2CID 28969310. Retrieved April 10, 2012.
- Foster, Ian; Kesselman, Carl; Nick, Jeffrey M.; Tuecke, Steven (June 22, 2002). "The physiology of the grid: an open grid services architecture for distributed systems integration". Archived from the original on March 22, 2008. Retrieved May 10, 2012.
- Hancock, B. (2009). "A simple data grid using the inferno operating system". Library Hi Tech. 27 (3): 382–392. doi:10.1108/07378830910988513.
- Hoschek, W.; McCance, G. (October 10, 2001). "Grid enabled relational database middleware" (PDF). Global Grid Forum. Archived from the original (PDF) on January 28, 2006. Retrieved April 22, 2012.
- Kunszt, Peter Z.; Guy, Leanne P. (July 7, 2002). "The open grid services architecture and data grids" (PDF). Retrieved May 10, 2012.
- Moore, Reagan W. "Evolution of data grid concepts" (PDF). Archived from the original (PDF) on February 12, 2014. Retrieved May 10, 2012.
- Rajkumar, Kettimuthu; Allcock, William; Liming, Lee; Navarro, John-Paul; Foster, Ian (March 30, 2007). "GridCopy moving data fast on the grid" (PDF). International parallel and distributed processing symposium (IPDPS 2007). Long Beach: IEEE International. pp. 1–6. Retrieved April 29, 2012.
- Thenmozhi, N.; Madheswaran, M. (2011). "Content based data transfer mechanism for efficient bulk data transfer in grid computing environment". International Journal of Grid Computing & Applications. 2 (4): 49–62. doi:10.5121/ijgca.2011.2405. ISSN 2229-3949. Retrieved April 28, 2012.
- Tu, Manghui; Li, Peng; I-Ling, Yen; Thuraisingham, Bhavani; Khan, Latifur (2010). "Secure data objects replication in data grid" (PDF). IEEE Transactions on Dependable and Secure Computing. 7 (1): 50–64. doi:10.1109/tdsc.2008.19. S2CID 8934783. Retrieved April 26, 2012.