Sensitivity index
The sensitivity index or discriminability index or detectability index is a dimensionless statistic used in signal detection theory. A higher index indicates that the signal can be more readily detected.
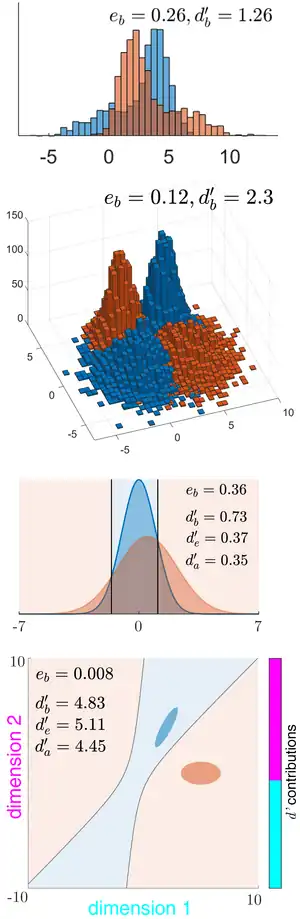


Definition
The discriminability index is the separation between the means of two distributions (typically the signal and the noise distributions), in units of the standard deviation.
Equal variances/covariances
For two univariate distributions and with the same standard deviation, it is denoted by ('dee-prime'):



- .

In higher dimensions, i.e. with two multivariate distributions with the same variance-covariance matrix , (whose symmetric square-root, the standard deviation matrix, is ), this generalizes to the Mahalanobis distance between the two distributions:


- ,

where is the 1d slice of the sd along the unit vector through the means, i.e. the equals the along the 1d slice through the means.[1]


For two bivariate distributions with equal variance-covariance, this is given by:
- ,

where is the correlation coefficient, and here and , i.e. including the signs of the mean differences instead of the absolute.[1]



is also estimated as [2].: 7

Unequal variances/covariances
When the two distributions have different standard deviations (or in general dimensions, different covariance matrices), there exist several contending indices, all of which reduce to for equal variance/covariance.
Bayes discriminability index
This is the maximum (Bayes-optimal) discriminability index for two distributions, based on the amount of their overlap, i.e. the optimal (Bayes) error of classification by an ideal observer, or its complement, the optimal accuracy :

- ,[1]

where is the inverse cumulative distribution function of the standard normal. The Bayes discriminability between univariate or multivariate normal distributions can be numerically computed [1] (Matlab code), and may also be used as an approximation when the distributions are close to normal.

is a positive-definite statistical distance measure that is free of assumptions about the distributions, like the Kullback-Leibler divergence . is asymmetric, whereas is symmetric for the two distributions. However, does not satisfy the triangle inequality, so it is not a full metric. [1]



In particular, for a yes/no task between two univariate normal distributions with means and variances , the Bayes-optimal classification accuracies are:[1]


- ,

where denotes the non-central chi-squared distribution, , and . The Bayes discriminability




can also be computed from the ROC curve of a yes/no task between two univariate normal distributions with a single shifting criterion. It can also be computed from the ROC curve of any two distributions (in any number of variables) with a shifting likelihood-ratio, by locating the point on the ROC curve that is farthest from the diagonal. [1]
For a two-interval task between these distributions, the optimal accuracy is ( denotes the generalized chi-squared distribution), where .[1] The Bayes discriminability .




RMS sd discriminability index
A common approximate (i.e. sub-optimal) discriminability index that has a closed-form is to take the average of the variances, i.e. the rms of the two standard deviations: [3] (also denoted by ). It is times the -score of the area under the receiver operating characteristic curve (AUC) of a single-criterion observer. This index is extended to general dimensions as the Mahalanobis distance using the pooled covariance, i.e. with as the common sd matrix.[1]




![{\displaystyle \mathbf {S} _{\text{rms}}=\left[\left(\mathbf {\Sigma } _{a}+\mathbf {\Sigma } _{b}\right)/2\right]^{\frac {1}{2}}}](../I/751c0effb8334352548839baaa59734cd99d3170.svg)
Average sd discriminability index
Another index is , extended to general dimensions using as the common sd matrix.[1]


Comparison of the indices
It has been shown that for two univariate normal distributions, , and for multivariate normal distributions, still.[1]


Thus, and underestimate the maximum discriminability of univariate normal distributions. can underestimate by a maximum of approximately 30%. At the limit of high discriminability for univariate normal distributions, converges to . These results often hold true in higher dimensions, but not always.[1] Simpson and Fitter [3] promoted as the best index, particularly for two-interval tasks, but Das and Geisler [1] have shown that is the optimal discriminability in all cases, and is often a better closed-form approximation than , even for two-interval tasks.


The approximate index , which uses the geometric mean of the sd's, is less than at small discriminability, but greater at large discriminability.[1]

Contribution to discriminability by each dimension
In general, the contribution to the total discriminability by each dimension or feature may be measured using the amount by which the discriminability drops when that dimension is removed. If the total Bayes discriminability is and the Bayes discriminability with dimension removed is , we can define the contribution of dimension as . This is the same as the individual discriminability of dimension when the covariance matrices are equal and diagonal, but in the other cases, this measure more accurately reflects the contribution of a dimension than its individual discriminability.[1]



See also
References
- Das, Abhranil (2020). "A method to integrate and classify normal distributions". arXiv:2012.14331 [stat.ML].
- MacMillan, N.; Creelman, C. (2005). Detection Theory: A User's Guide. Lawrence Erlbaum Associates. ISBN 9781410611147.
- Simpson, A. J.; Fitter, M. J. (1973). "What is the best index of detectability?". Psychological Bulletin. 80 (6): 481–488. doi:10.1037/h0035203.
- Wickens, Thomas D. (2001). Elementary Signal Detection Theory. OUP USA. ch. 2, p. 20. ISBN 0-19-509250-3.