Distributional semantics
Distributional semantics is a research area that develops and studies theories and methods for quantifying and categorizing semantic similarities between linguistic items based on their distributional properties in large samples of language data. The basic idea of distributional semantics can be summed up in the so-called distributional hypothesis: linguistic items with similar distributions have similar meanings.
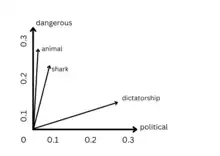
Distributional hypothesis
The distributional hypothesis in linguistics is derived from the semantic theory of language usage, i.e. words that are used and occur in the same contexts tend to purport similar meanings.[1]
The underlying idea that "a word is characterized by the company it keeps" was popularized by Firth in the 1950s.[2]
The distributional hypothesis is the basis for statistical semantics. Although the Distributional Hypothesis originated in linguistics,[3] it is now receiving attention in cognitive science especially regarding the context of word use.[4]
In recent years, the distributional hypothesis has provided the basis for the theory of similarity-based generalization in language learning: the idea that children can figure out how to use words they've rarely encountered before by generalizing about their use from distributions of similar words.[5][6]
The distributional hypothesis suggests that the more semantically similar two words are, the more distributionally similar they will be in turn, and thus the more that they will tend to occur in similar linguistic contexts.
Whether or not this suggestion holds has significant implications for both the data-sparsity problem in computational modeling,[7] and for the question of how children are able to learn language so rapidly given relatively impoverished input (this is also known as the problem of the poverty of the stimulus).
Distributional semantic modeling in vector spaces
Distributional semantics favor the use of linear algebra as a computational tool and representational framework. The basic approach is to collect distributional information in high-dimensional vectors, and to define distributional/semantic similarity in terms of vector similarity.[8] Different kinds of similarities can be extracted depending on which type of distributional information is used to collect the vectors: topical similarities can be extracted by populating the vectors with information on which text regions the linguistic items occur in; paradigmatic similarities can be extracted by populating the vectors with information on which other linguistic items the items co-occur with. Note that the latter type of vectors can also be used to extract syntagmatic similarities by looking at the individual vector components.
The basic idea of a correlation between distributional and semantic similarity can be operationalized in many different ways. There is a rich variety of computational models implementing distributional semantics, including latent semantic analysis (LSA),[9][10] Hyperspace Analogue to Language (HAL), syntax- or dependency-based models,[11] random indexing, semantic folding[12] and various variants of the topic model.[13]
Distributional semantic models differ primarily with respect to the following parameters:
- Context type (text regions vs. linguistic items)
- Context window (size, extension, etc.)
- Frequency weighting (e.g. entropy, pointwise mutual information,[14] etc.)
- Dimension reduction (e.g. random indexing, singular value decomposition, etc.)
- Similarity measure (e.g. cosine similarity, Minkowski distance, etc.)
Distributional semantic models that use linguistic items as context have also been referred to as word space, or vector space models.[15][16]
Beyond Lexical Semantics
While distributional semantics typically has been applied to lexical items—words and multi-word terms—with considerable success, not least due to its applicability as an input layer for neurally inspired deep learning models, lexical semantics, i.e. the meaning of words, will only carry part of the semantics of an entire utterance. The meaning of a clause, e.g. "Tigers love rabbits.", can only partially be understood from examining the meaning of the three lexical items it consists of. Distributional semantics can straightforwardly be extended to cover larger linguistic item such as constructions, with and without non-instantiated items, but some of the base assumptions of the model need to be adjusted somewhat. Construction grammar and its formulation of the lexical-syntactic continuum offers one approach for including more elaborate constructions in a distributional semantic model and some experiments have been implemented using the Random Indexing approach.[17]
Compositional distributional semantic models extend distributional semantic models by explicit semantic functions that use syntactically based rules to combine the semantics of participating lexical units into a compositional model to characterize the semantics of entire phrases or sentences. This work was originally proposed by Stephen Clark, Bob Coecke, and Mehrnoosh Sadrzadeh of Oxford University in their 2008 paper, "A Compositional Distributional Model of Meaning".[18] Different approaches to composition have been explored—including neural models—and are under discussion at established workshops such as SemEval.[19]
Applications
Distributional semantic models have been applied successfully to the following tasks:
- finding semantic similarity between words and multi-word expressions;
- word clustering based on semantic similarity;
- automatic creation of thesauri and bilingual dictionaries;
- word sense disambiguation;
- expanding search requests using synonyms and associations;
- defining the topic of a document;
- document clustering for information retrieval;
- data mining and named entities recognition;
- creating semantic maps of different subject domains;
- paraphrasing;
- sentiment analysis;
- modeling selectional preferences of words.
Software
See also
References
- Harris 1954
- Firth 1957
- Sahlgren 2008
- McDonald & Ramscar 2001
- Gleitman 2002
- Yarlett 2008
- Wishart, Ryder; Prokopidis, Prokopis (2017). Topic Modelling Experiments on Hellenistic Corpora (PDF). Proceedings of the Workshop on Corpora in the Digital Humanities 17. S2CID 9191936.
- Rieger 1991
- Deerwester et al. 1990
- Landauer, Thomas K.; Dumais, Susan T. (1997). "A solution to Plato's problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge". Psychological Review. 104 (2): 211–240. doi:10.1037/0033-295x.104.2.211.
- Padó & Lapata 2007
- De Sousa Webber, Francisco (2015). "Semantic Folding Theory And its Application in Semantic Fingerprinting". arXiv:1511.08855 [cs.AI].
- Jordan, Michael I.; Ng, Andrew Y.; Blei, David M. (2003). "Latent Dirichlet Allocation". Journal of Machine Learning Research. 3 (Jan): 993–1022.
- Church, Kenneth Ward; Hanks, Patrick (1989). "Word association norms, mutual information, and lexicography". Proceedings of the 27th Annual Meeting on Association for Computational Linguistics. Morristown, NJ, USA: Association for Computational Linguistics: 76–83. doi:10.3115/981623.981633.
- Schütze 1993
- Sahlgren 2006
- Karlgren, Jussi; Kanerva, Pentti (July 2019). "High-dimensional distributed semantic spaces for utterances". Natural Language Engineering. 25 (4): 503–517. arXiv:2104.00424. doi:10.1017/S1351324919000226. S2CID 201141249.
- Clark, Stephen; Coecke, Bob; Sadrzadeh, Mehrnoosh (2008). "A compositional distributional model of meaning" (PDF). Proceedings of the Second Quantum Interaction Symposium: 133–140.
- "SemEval-2014, Task 1".
Sources
- Harris, Z. (1954). "Distributional structure". Word. 10 (23): 146–162. doi:10.1080/00437956.1954.11659520.
- Firth, J.R. (1957). "A synopsis of linguistic theory 1930-1955". Studies in Linguistic Analysis: 1–32. Reprinted in F.R. Palmer, ed. (1968). Selected Papers of J.R. Firth 1952-1959. London: Longman.
- Sahlgren, Magnus (2008). "The Distributional Hypothesis" (PDF). Rivista di Linguistica. 20 (1): 33–53.
- McDonald, S.; Ramscar, M. (2001). "Testing the distributional hypothesis: The influence of context on judgements of semantic similarity". Proceedings of the 23rd Annual Conference of the Cognitive Science Society. pp. 611–616. CiteSeerX 10.1.1.104.7535.
- Gleitman, Lila R. (2002). "Verbs of a feather flock together II". The Legacy of Zellig Harris. Current Issues in Linguistic Theory. Vol. 1. pp. 209–229. doi:10.1075/cilt.228.17gle. ISBN 978-90-272-4736-0.
- Yarlett, D. (2008). Language Learning Through Similarity-Based Generalization (PDF) (PhD thesis). Stanford University. Archived from the original (PDF) on 2014-04-19. Retrieved 2012-07-12.
- Rieger, Burghard B. (1991). On Distributed Representations in Word Semantics (PDF) (Report). ICSI Berkeley 12-1991. CiteSeerX 10.1.1.37.7976.
- Deerwester, Scott; Dumais, Susan T.; Furnas, George W.; Landauer, Thomas K.; Harshman, Richard (1990). "Indexing by Latent Semantic Analysis" (PDF). Journal of the American Society for Information Science. 41 (6): 391–407. CiteSeerX 10.1.1.33.2447. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9. Archived from the original (PDF) on 2012-07-17.
- Padó, Sebastian; Lapata, Mirella (2007). "Dependency-based construction of semantic space models". Computational Linguistics. 33 (2): 161–199. doi:10.1162/coli.2007.33.2.161. S2CID 7747235.
- Schütze, Hinrich (1993). "Word Space". Advances in Neural Information Processing Systems 5. pp. 895–902. CiteSeerX 10.1.1.41.8856.
- Sahlgren, Magnus (2006). The Word-Space Model (PDF) (PhD thesis). Stockholm University.
- Thomas Landauer; Susan T. Dumais. "A Solution to Plato's Problem: The Latent Semantic Analysis Theory of Acquisition, Induction, and Representation of Knowledge". Retrieved 2007-07-02.
- Kevin Lund; Curt Burgess; Ruth Ann Atchley (1995). Semantic and associative priming in a high-dimensional semantic space. Cognitive Science Proceedings. pp. 660–665.
- Kevin Lund; Curt Burgess (1996). "Producing high-dimensional semantic spaces from lexical co-occurrence". Behavior Research Methods, Instruments, and Computers. 28 (2): 203–208. doi:10.3758/bf03204766.