Durability (database systems)
In database systems, durability is the ACID property that guarantees that the effects of transactions that have been committed will survive permanently, even in case of failures,[1] including incidents and catastrophic events. For example, if a flight booking reports that a seat has successfully been booked, then the seat will remain booked even if the system crashes.[2]
Formally, a database system ensures the durability property if it tolerates three types of failures: transaction, system, and media failures.[1] In particular, a transaction fails if its execution is interrupted before all its operations have been processed by the system.[3] These kinds of interruptions can be originated at the transaction level by data-entry errors, operator cancellation, timeout, or application-specific errors, like withdrawing money from a bank account with insufficient funds.[1] At the system level, a failure occurs if the contents of the volatile storage are lost, due, for instance, to system crashes, like out-of-memory events.[3] At the media level, where media means a stable storage that withstands system failures, failures happen when the stable storage, or part of it, is lost.[3] These cases are typically represented by disk failures.[1]
Thus, to be durable, the database system should implement strategies and operations that guarantee that the effects of transactions that have been committed before the failure will survive the event (even by reconstruction), while the changes of incomplete transactions, which have not been committed yet at the time of failure, will be reverted and will not affect the state of the database system. These behaviours are proven to be correct when the execution of transactions has respectively the resilience and recoverability properties.[3]
Mechanisms
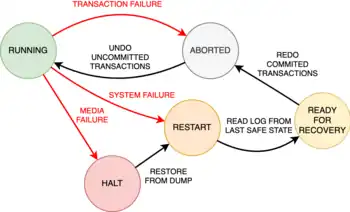
In transaction-based systems, the mechanisms that assure durability are historically associated with the concept of reliability of systems, as proposed by Jim Gray in 1981.[1] This concept includes durability, but it also relies on aspects of the atomicity and consistency properties.[4] Specifically, a reliability mechanism requires primitives that explicitly state the beginning, the end, and the rollback of transactions,[1] which are also implied for the other two aforementioned properties. In this article, only the mechanisms strictly related to durability have been considered. These mechanisms are divided into three levels: transaction, system, and media level. This can be seen as well for scenarios where failures could happen and that have to be considered in the design of database systems to address durability.[3]
Transaction level
Durability against failures that occur at transaction level, such as canceled calls and inconsistent actions that may be blocked before committing by constraints and triggers, is guaranteed by the serializability property of the execution of transactions. The state generated by the effects of precedently committed transactions is available in main memory and, thus, is resilient, while the changes carried by non-committed transactions can be undone. In fact, thanks to serializability, they can be discerned from other transactions and, therefore, their changes are discarded.[3] In addition, it is relevant to consider that in-place changes, which overwrite old values without keeping any kind of history are discouraged.[1] There exist multiple approaches that keep track of the history of changes, such as timestamp-based solutions[5] or logging and locking.[1]
System level
At system level, failures happen, by definition,[3] when the contents of the volatile storage are lost. This can occur in events like system crashes or power outages. Existing database systems use volatile storage (i.e. the main memory of the system) for different purposes: some store their whole state and data in it, even without any durability guarantee; others keep the state and the data, or part of them, in memory, but also use the non-volatile storage for data; other systems only keep the state in main memory, while keeping all the data on disk.[6] The reason behind the choice of having volatile storage, which is subject to this type of failure, and non-volatile storage, is found in the performance differences of the existing technologies that are used to implement these kinds of storage. However, the situation is likely to evolve as the popularity of non-volatile memories (NVM) technologies grows.[7]
In systems that include non-volatile storage, durability can be achieved by keeping and flushing an immutable sequential log of the transactions to such non-volatile storage before acknowledging commitment. Thanks to their atomicity property, the transactions can be considered the unit of work in the recovery process that guarantees durability while exploiting the log. In particular, the logging mechanism is called write-ahead log (WAL) and allows durability by buffering changes to the disk before they are synchronized from the main memory. In this way, by reconstruction from the log file, all committed transactions are resilient to system-level failures, because they can be redone. Non-committed transactions, instead, are recoverable, since their operations are logged to non-volatile storage before they effectively modify the state of the database.[8] In this way, the partially executed operations can be undone without affecting the state of the system. After that, those transactions that were incomplete can be redone. Therefore, the transaction log from non-volatile storage can be reprocessed to recreate the system state right before any later system-level failure. It is worth mentioning that logging is done as a combination of tracking data and operations (i.e. transactions) for performance reasons.[9]
Media level
At media level, failure scenarios affect non-volatile storage, like hard disk drives, solid-state drives, and other types of storage hardware components.[8] To guarantee durability at this level, the database system shall rely on stable memory, which is a memory that is completely and ideally failure-resistant. This kind of memory can be achieved with mechanisms of replication and robust writing protocols.[4]
Many tools and technologies are available to provide a logical stable memory, such as the mirroring of disks, and their choice depends on the requirements of the specific applications.[4] In general, replication and redundancy strategies and architectures that behave like stable memory are available at different levels of the technology stack. In this way, even in case of catastrophic events where the storage hardware is damaged, data loss can be prevented.[10] At this level, there is a strong bond between durability and system and data recovery, in the sense that the main goal is to preserve the data, not necessarily in online replicas, but also as offline copies.[4] These last techniques fall into the categories of backup, data loss prevention, and disaster recovery.[11]
Therefore, in case of media failure, the durability of transactions is guaranteed by the ability to reconstruct the state of the database from the log files stored in the stable memory, in any way it was implemented in the database system.[8] There exist several mechanisms to store and reconstruct the state of a database system that improves the performance, both in terms of space and time, compared to managing all the log files created from the beginning of the database system. These mechanisms often include incremental dumping, differential files, and checkpoints.[12]
Distributed databases
In distributed transactions, ensuring durability requires additional mechanisms to preserve a consistent state sequence across all database nodes. This means, for example, that a single node may not be enough to decide to conclude a transaction by committing it. In fact, the resources used in that transaction may be on other nodes, where other transactions are occurring concurrently. Otherwise, in case of failure, if consistency could not be guaranteed, it would be impossible to acknowledge a safe state of the database for recovery. For this reason, all participating nodes must coordinate before a commit can be acknowledged. This is usually done by a two-phase commit protocol.[13]
In addition, in distributed databases, even the protocols for logging and recovery shall address the issues of distributed environments, such as deadlocks, that could prevent the resilience and recoverability of transactions and, thus, durability.[13] A widely adopted family of algorithms that ensures these properties is Algorithms for Recovery and Isolation Exploiting Semantics (ARIES).[8]
References
- Gray, Jim (1981). "The transaction concept: Virtues and limitations" (PDF). VLDB. 81: 144–154.
- "ACID Compliance: What It Means and Why You Should Care". MariaDB. 29 July 2018. Retrieved 22 September 2021.
- Hadzilacos, Vassos (1988). "A theory of reliability in database systems". Journal of the ACM. 35 (1): 121–145. doi:10.1145/42267.42272. ISSN 0004-5411. S2CID 7052304.
- Atzeni, Paolo, ed. (1999). Database systems: concepts, languages & architectures. New York: McGraw-Hill. pp. 311–320. ISBN 978-0-07-709500-0.
- Svobodova, L. (1980). "MANAGEMENT OF OBJECT HISTORIES IN THE SWALLOW REPOSITORY". Mit/LCS Tr-243. USA.
- Petrov, Oleksandr (2019). Database internals: a deep dive into how distributed data systems work (1st ed.). Beijing Boston Farnham Sebastopol Tokyo: O'Reilly. pp. 40–42. ISBN 978-1-4920-4034-7.
- Arulraj, Joy; Pavlo, Andrew (2017-05-09). "How to Build a Non-Volatile Memory Database Management System". Proceedings of the 2017 ACM International Conference on Management of Data. SIGMOD '17. New York, NY, USA: Association for Computing Machinery. pp. 1753–1758. doi:10.1145/3035918.3054780. ISBN 978-1-4503-4197-4. S2CID 648876.
- Petrov, Oleksandr (2019). Database internals: a deep dive into how distributed data systems work (1st ed.). Beijing Boston Farnham Sebastopol Tokyo: O'Reilly. pp. 185–195. ISBN 978-1-4920-4034-7.
- Mohan, C.; Haderle, Don; Lindsay, Bruce; Pirahesh, Hamid; Schwarz, Peter (1992-03-01). "ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging". ACM Transactions on Database Systems. 17 (1): 94–162. doi:10.1145/128765.128770. ISSN 0362-5915. S2CID 8759704.
- Eich, Margaret H. (1987-02-01). "A classification and comparison of main memory database recovery techniques". 1987 IEEE Third International Conference on Data Engineering. IEEE. pp. 332–339. doi:10.1109/ICDE.1987.7272398. ISBN 978-0-8186-0762-2. S2CID 207773738.
- Choy, Manhoi; Leong, Hong Va; Wong, Man Hon (2000). "Disaster recovery techniques for database systems". Communications of the ACM. 43 (11es): 6. doi:10.1145/352515.352521. ISSN 0001-0782. S2CID 14781378.
- Verhofstad, Joost S. M. (1978-06-01). "Recovery Techniques for Database Systems". ACM Computing Surveys. 10 (2): 167–195. doi:10.1145/356725.356730. S2CID 8847522.
- Mohan, C.; Haderle, Don; Lindsay, Bruce; Pirahesh, Hamid; Schwarz, Peter (1992-03-01). "ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging". ACM Transactions on Database Systems. 17 (1): 94–162. doi:10.1145/128765.128770. ISSN 0362-5915. S2CID 8759704.
Further reading
- Campbell, Laine; Majors, Charity (2017). Database Reliability Engineering. O'Reilly Media, Inc. ISBN 9781491926215.
- Taylor, C.A.; Gittens, M.S.; Miranskyy, A.V. (June 2008). "A case study in database reliability: Component types, usage profiles, and testing". Proceedings of the 1st international workshop on Testing database systems. pp. 1–6. doi:10.1145/1385269.1385283. ISBN 9781605582337. S2CID 16101765.