Entity linking
In natural language processing, entity linking, also referred to as named-entity linking (NEL),[1] named-entity disambiguation (NED), named-entity recognition and disambiguation (NERD) or named-entity normalization (NEN)[2] is the task of assigning a unique identity to entities (such as famous individuals, locations, or companies) mentioned in text. For example, given the sentence "Paris is the capital of France", the idea is to determine that "Paris" refers to the city of Paris and not to Paris Hilton or any other entity that could be referred to as "Paris". Entity linking is different from named-entity recognition (NER) in that NER identifies the occurrence of a named entity in text but it does not identify which specific entity it is (see Differences from other techniques).
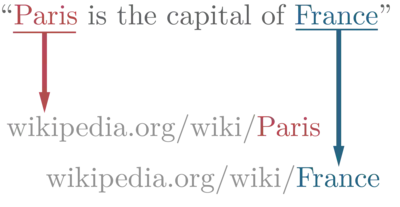
Introduction
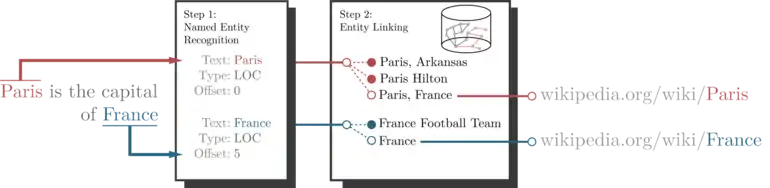
In entity linking, words of interest (names of persons, locations and companies) are mapped from an input text to corresponding unique entities in a target knowledge base. Words of interest are called named entities (NEs), mentions, or surface forms. The target knowledge base depends on the intended application, but for entity linking systems intended to work on open-domain text it is common to use knowledge-bases derived from Wikipedia (such as Wikidata or DBpedia).[2][3] In this case, each individual Wikipedia page is regarded as a separate entity. Entity linking techniques that map named entities to Wikipedia entities are also called wikification.[4]
Considering again the example sentence "Paris is the capital of France", the expected output of an entity linking system will be Paris and France. These uniform resource locators (URLs) can be used as unique uniform resource identifiers (URIs) for the entities in the knowledge base. Using a different knowledge base will return different URIs, but for knowledge bases built starting from Wikipedia there exist one-to-one URI mappings.[5]
In most cases, knowledge bases are manually built,[6] but in applications where large text corpora are available, the knowledge base can be inferred automatically from the available text.[7]
Entity linking is a critical step to bridge web data with knowledge bases, which is beneficial for annotating the huge amount of raw and often noisy data on the Web and contributes to the vision of the Semantic Web.[8] In addition to entity linking, there are other critical steps including but not limited to event extraction,[9] and event linking[10] etc.
Applications
Entity linking is beneficial in fields that need to extract abstract representations from text, as it happens in text analysis, recommender systems, semantic search and chatbots. In all these fields, concepts relevant to the application are separated from text and other non-meaningful data.[11][12]
For example, a common task performed by search engines is to find documents that are similar to one given as input, or to find additional information about the persons that are mentioned in it. Consider a sentence that contains the expression "the capital of France": without entity linking, the search engine that looks at the content of documents would not be able to directly retrieve documents containing the word "Paris", leading to so-called false negatives (FN). Even worse, the search engine might produce spurious matches (or false positives (FP)), such as retrieving documents referring to "France" as a country.
Many approaches orthogonal to entity linking exist to retrieve documents similar to an input document. For example, latent semantic analysis (LSA) or comparing document embeddings obtained with doc2vec. However, these techniques do not allow the same fine-grained control that is offered by entity linking, as they will return other documents instead of creating high-level representations of the original one. For example, obtaining schematic information about "Paris", as presented by Wikipedia infoboxes would be much less straightforward, or sometimes even unfeasible, depending on the query complexity.[13]
Moreover, entity linking has been used to improve the performance of information retrieval systems[2] and to improve search performance on digital libraries.[14] Entity linking is also a key input for semantic search.[15]
Challenges in entity linking
An entity linking system has to deal with a number of challenges before being performant in real-life applications. Some of these issues are intrinsic to the task of entity linking,[16] such as text ambiguity, while others, such as scalability and execution time, become relevant when considering real-life usage of such systems.
- Name variations: the same entity might appear with textual representations. Sources of these variations include abbreviations (New York, NY), aliases (New York, Big Apple), or spelling variations and errors (New yokr).
- Ambiguity: the same mention can often refer to many different entities, depending on the context, as many entity names tend to be polysemous (i.e. have multiple meanings). The word Paris, among other things, could be referring to the French capital or to Paris Hilton. In some cases (as in the capital of France), there is no textual similarity between the mention text and the actual target entity (Paris).
- Absence: sometimes, some named entities might not have a correct entity link in the target knowledge base. This might happen when dealing with very specific or unusual entities, or when processing documents about recent events, in which there might be mentions of persons or events that do not have yet a corresponding entity in the knowledge base. Another common situation in which there are missing entities is when using domain-specific knowledge bases (for example, a biology knowledge base or a movie database). In all these cases, the entity linking system should return a
NILentity link. Understanding when to return aNILprediction is not straightforward, and many different approaches have been proposed; for example, by thresholding some kind of confidence score in the entity linking system, or by adding an additionalNILentity to the knowledge base, which is treated in the same way as the other entities. Moreover, in some cases providing a wrong, but related, entity link prediction might be better than no result at all from the perspective of an end user.[16] - Scalability and Speed: it is desirable for an industrial entity linking system to provide results in a reasonable time, and often in real-time. This requirement is critical for search engines, chat-bots and for entity linking systems offered by data-analytics platforms. Ensuring low execution time can be challenging when using large knowledge bases or when processing large documents.[17] For example, Wikipedia contains nearly 9 million entities and more than 170 million relationships among them.
- Evolving Information: an entity linking system should also deal with evolving information, and easily integrate updates in the knowledge base. The problem of evolving information is sometimes connected to the problem of missing entities, for example when processing recent news articles in which there are mentions of events that do not have a corresponding entry in the knowledge base due to their novelty.[18]
- Multiple Languages: an entity linking system might support queries performed in multiple languages. Ideally, the accuracy of the entity linking system should not be influenced by the input language, and entities in the knowledge base should be the same across different languages.[19]
Differences from other techniques
Entity linking is also known as named-entity disambiguation (NED), and is deeply connected to Wikification and record linkage.[20] Definitions are often blurry and vary slightly among different authors: Alhelbawy et al.[21] consider entity linking as a broader version of NED, as NED should assume that the entity that correctly matches a certain textual named entity mention is in the knowledge base. Entity linking systems might deal with cases in which no entry for the named entity is available in the reference knowledge base. Other authors do not make such distinction, and use the two names interchangeably.[22][23]
- Wikification is the task of linking textual mentions to entities in Wikipedia (generally, limiting the scope to the English Wikipedia in case of cross-lingual wikification).
- Record linkage (RL) is considered a broader field than entity linking, and consists in finding records, across multiple and often heterogeneous data-sets, that refer to the same entity.[14] Record linkage is a key component to digitalize archives, and to join multiple knowledge bases.[14]
- Named-entity recognition locates and classifies named entities in unstructured text into pre-defined categories such as the names, organizations, locations, and more. For example, the following sentence:
Paris is the capital of France.
- would be processed by an NER system to obtain the following output:
[Paris]City is the capital of [France]Country.
- Named-entity recognition is usually a preprocessing step of an entity linking system, as it can be useful to know in advance which words should be linked to entities of the knowledge base.
- Coreference resolution understands whether multiple words in a text refer to the same entity. It can be useful, for example, to understand the word a pronoun refers to. Consider the following example:
Paris is the capital of France. It is also the largest city in France.
- In this example, a coreference resolution algorithm would identify that the pronoun It refers to Paris, and not to France or to another entity. A notable distinction compared to entity linking is that Coreference Resolution does not assign any unique identity to the words it matches, but it simply says whether they refer to the same entity or not. In that sense, predictions from a coreference resolution system could be useful to a subsequent entity linking component.
Approaches to entity linking
Entity linking has been a hot topic in industry and academia for the last decade. However, as of today most existing challenges are still unsolved, and many entity linking systems, with widely different strengths and weaknesses, have been proposed.[24]
Broadly speaking, modern entity linking systems can be divided into two categories:
- Text-based approaches, which make use of textual features extracted from large text corpora (e.g. Term frequency–Inverse document frequency (Tf–Idf), word co-occurrence probabilities, etc...).[25][16]
- Graph-based approaches, which exploit the structure of knowledge graphs to represent the context and the relation of entities.[3][26]
Often entity linking systems cannot be strictly categorized in either category, but they make use of knowledge graphs that have been enriched with additional textual features extracted, for example, from the text corpora that were used to build the knowledge graphs themselves.[22][23]
Text-based entity linking
The seminal work by Cucerzan in 2007 proposed one of the first entity linking systems that appeared in the literature, and tackled the task of wikification, linking textual mentions to Wikipedia pages.[25] This system partitions pages as entity, disambiguation, or list pages, used to assign categories to each entity. The set of entities present in each entity page is used to build the entity's context. The final entity linking step is a collective disambiguation performed by comparing binary vectors obtained from hand-crafted features, and from each entity's context. Cucerzan's entity linking system is still used as baseline for many recent works.[27]
The work of Rao et al. is a well-known paper in the field of entity linking.[16] The authors propose a two-step algorithm to link named entities to entities in a target knowledge base. First, a set of candidate entities is chosen using string matching, acronyms, and known aliases. Then the best link among the candidates is chosen with a ranking support vector machine (SVM) that uses linguistic features.
Recent systems, such as the one proposed by Tsai et al.,[20] employ word embeddings obtained with a skip-gram model as language features, and can be applied to any language as long as a large corpus to build word embeddings is provided. Similarly to most entity linking systems, the linking is done in two steps, with an initial candidate entities selection and a linear ranking SVM as second step.
Various approaches have been tried to tackle the problem of entity ambiguity. In the seminal approach of Milne and Witten, supervised learning is employed using the anchor texts of Wikipedia entities as training data.[28] Other approaches also collected training data based on unambiguous synonyms.[29]
Graph-based entity linking
Modern entity linking systems do not limit their analysis to textual features generated from input documents or text corpora, but employ large knowledge graphs created from knowledge bases such as Wikipedia. These systems extract complex features which take advantage of the knowledge graph topology, or leverage multi-step connections between entities, which would be hidden by simple text analysis. Moreover, creating multilingual entity linking systems based on natural language processing (NLP) is inherently difficult, as it requires either large text corpora, often absent for many languages, or hand-crafted grammar rules, which are widely different among languages. Han et al. propose the creation of a disambiguation graph (a subgraph of the knowledge base which contains candidate entities).[3] This graph is employed for a purely collective ranking procedure that finds the best candidate link for each textual mention.
Another famous entity linking approach is AIDA, which uses a series of complex graph algorithms, and a greedy algorithm that identifies coherent mentions on a dense subgraph by also considering context similarities and vertex importance features to perform collective disambiguation.[26]
Graph ranking (or vertex ranking) denotes algorithms such as PageRank (PR) and Hyperlink-Induced Topic Search (HITS), with the goal to assign a score to each vertex that represents its relative importance in the overall graph. The entity linking system presented in Alhelbawy et al. employs PageRank to perform collective entity linking on a disambiguation graph, and to understand which entities are more strongly related with each other and would represent a better linking.[21]
Mathematical entity linking
Mathematical expressions (symbols and formulae) can be linked to semantic entities (e.g., Wikipedia articles[30] or Wikidata items[31]) labeled with their natural language meaning. This is essential for disambiguation, since symbols may have different meanings (e.g., "E" can be "energy" or "expectation value", etc.).[32][31] The math entity linking process can be facilitated and accelerated through annotation recommendation, e.g., using the "AnnoMathTeX" system that is hosted by Wikimedia.[33][34][35]
To facilitate the reproducibility of Mathematical Entity Linking (MathEL) experiments, the benchmark MathMLben was created.[36][37] It contains formulae from Wikipedia, the arXiV and the NIST Digital Library of Mathematical Functions (DLMF). Formulae entries in the benchmark are labeled and augmented by Wikidata markup.[31] Furthermore, for two large corporae from the arXiv[38] and zbMATH[39] repository distributions of mathematical notation were examined. Mathematical Objects of Interest (MOI) are identified as potential candidates for MathEL.[40]
Besides linking to Wikipedia, Schubotz[37] and Scharpf et al.[31] describe linking mathematical formula content to Wikidata, both in MathML and LaTeX markup. To extend classical citations by mathematical, they call for a Formula Concept Discovery (FCD) and Formula Concept Recognition (FCR) challenge to elaborate automated MathEL. Their FCD approach yields a recall of 68% for retrieving equivalent representations of frequent formulae, and 72% for extracting the formula name from the surrounding text on the NTCIR[41] arXiv dataset.[35]
See also
References
- Hachey, Ben; Radford, Will; Nothman, Joel; Honnibal, Matthew; Curran, James R. (2013-01-01). "Artificial Intelligence, Wikipedia and Semi-Structured ResourcesEvaluating Entity Linking with Wikipedia". Artificial Intelligence. 194: 130–150. doi:10.1016/j.artint.2012.04.005.
- M. A. Khalid, V. Jijkoun and M. de Rijke (2008). The impact of named entity normalization on information retrieval for question answering. Proc. ECIR.
- Han, Xianpei; Sun, Le; Zhao, Jun (2011). "Collective entity linking in web text". Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM. pp. 765–774. doi:10.1145/2009916.2010019. ISBN 9781450307574. S2CID 14428938.
- Rada Mihalcea and Andras Csomai (2007)Wikify! Linking Documents to Encyclopedic Knowledge. Proc. CIKM.
- "Wikipedia Links". 4 May 2023.
- Wikidata
- Aaron M. Cohen (2005). Unsupervised gene/protein named entity normalization using automatically extracted dictionaries. Proc. ACL-ISMB Workshop on Linking Biological Literature, Ontologies and Databases: Mining Biological Semantics, pp. 17–24.
- Shen W, Wang J, Han J. Entity linking with a knowledge base: Issues, techniques, and solutions[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 27(2): 443-460.
- Chang Y C, Chu C H, Su Y C, et al. PIPE: a protein–protein interaction passage extraction module for BioCreative challenge[J]. Database, 2016, 2016.
- Lou P, Jimeno Yepes A, Zhang Z, et al. BioNorm: deep learning-based event normalization for the curation of reaction databases[J]. Bioinformatics, 2020, 36(2): 611-620.
- Slawski, Bill (16 September 2015). "How Google Uses Named Entity Disambiguation for Entities with the Same Names".
- Zhou, Ming; Lv, Weifeng; Ren, Pengjie; Wei, Furu; Tan, Chuanqi (2017). "Entity Linking for Queries by Searching Wikipedia Sentences". Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. pp. 68–77. arXiv:1704.02788. doi:10.18653/v1/D17-1007. S2CID 1125678.
- Le, Quoc; Mikolov, Tomas (2014). "Distributed Representations of Sentences and Documents". Proceedings of the 31st International Conference on International Conference on Machine Learning. 32: II–1188–II–1196. arXiv:1405.4053.
- Hui Han, Hongyuan Zha, C. Lee Giles, "Name disambiguation in author citations using a K-way spectral clustering method," ACM/IEEE Joint Conference on Digital Libraries 2005 (JCDL 2005): 334-343, 2005
- STICS
- Rao, Delip; McNamee, Paul; Dredze, Mark (2013). "Entity Linking: Finding Extracted Entities in a Knowledge Base". Multi-source, Multilingual Information Extraction and Summarization. Theory and Applications of Natural Language Processing. Springer Berlin Heidelberg. pp. 93–115. doi:10.1007/978-3-642-28569-1_5. ISBN 978-3-642-28568-4. S2CID 6420241.
- Parravicini, Alberto; Patra, Rhicheek; Bartolini, Davide B.; Santambrogio, Marco D. (2019). "Fast and Accurate Entity Linking via Graph Embedding". Proceedings of the 2nd Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA). ACM. pp. 10:1–10:9. doi:10.1145/3327964.3328499. hdl:11311/1119019. ISBN 9781450367899. S2CID 195357229.
- Hoffart, Johannes; Altun, Yasemin; Weikum, Gerhard (2014). "Discovering emerging entities with ambiguous names". Proceedings of the 23rd international conference on World wide web. ACM. pp. 385–396. doi:10.1145/2566486.2568003. ISBN 9781450327442. S2CID 7562986.
- Doermann, David S.; Oard, Douglas W.; Lawrie, Dawn J.; Mayfield, James; McNamee, Paul (2011). "Cross-Language Entity Linking". S2CID 3801685.
{{cite journal}}: Cite journal requires|journal=(help) - Tsai, Chen-Tse; Roth, Dan (2016). "Cross-lingual Wikification Using Multilingual Embeddings". Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Vol. Proceedings of NAACL-HLT 2016. pp. 589–598. doi:10.18653/v1/N16-1072. S2CID 15156124.
- Alhelbawy, Ayman; Gaizauskas, Robert (August 2014). "Collective Named Entity Disambiguation using Graph Ranking and Clique Partitioning Approaches". Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers (Dublin City University and Association for Computational Linguistics): 1544–1555.
{{cite journal}}: Cite journal requires|journal=(help) - Zwicklbauer, Stefan; Seifert, Christin; Granitzer, Michael (2016). "Robust and Collective Entity Disambiguation through Semantic Embeddings". Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval (PDF). ACM. pp. 425–434. doi:10.1145/2911451.2911535. ISBN 9781450340694. S2CID 207237647.
- Hachey, Ben; Radford, Will; Nothman, Joel; Honnibal, Matthew; Curran, James R. (2013). "Evaluating Entity Linking with Wikipedia". Artif. Intell. 194: 130–150. doi:10.1016/j.artint.2012.04.005. ISSN 0004-3702.
- Ji, Heng; Nothman, Joel; Hachey, Ben; Florian, Radu (2015). "Overview of TAC-KBP2015 Tri-lingual Entity Discovery and Linking". TAC.
- Cucerzan, Silviu (June 2007). "Large-Scale Named Entity Disambiguation Based on Wikipedia Data". Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL): 708–716.
{{cite journal}}: Cite journal requires|journal=(help) - Weikum, Gerhard; Thater, Stefan; Taneva, Bilyana; Spaniol, Marc; Pinkal, Manfred; Fürstenau, Hagen; Bordino, Ilaria; Yosef, Mohamed Amir; Hoffart, Johannes (2011). "Robust Disambiguation of Named Entities in Text". Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing: 782–792.
- Kulkarni, Sayali; Singh, Amit; Ramakrishnan, Ganesh; Chakrabarti, Soumen (2009). Collective annotation of Wikipedia entities in web text. Proc. 15th ACM SIGKDD Int'l Conf. on Knowledge Discovery and Data Mining (KDD). doi:10.1145/1557019.1557073. ISBN 9781605584959.
- David Milne and Ian H. Witten (2008). Learning to link with Wikipedia. Proc. CIKM.
- Zhang, Wei; Jian Su; Chew Lim Tan (2010). "Entity Linking Leveraging Automatically Generated Annotation". Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010).
- Giovanni Yoko Kristianto; Goran Topic; Akiko Aizawa; et al. (2016). "Entity Linking for Mathematical Expressions in Scientific Documents". Digital Libraries: Knowledge, Information, and Data in an Open Access Society. Lecture Notes in Computer Science. Vol. 10075. Springer. pp. 144–149. doi:10.1007/978-3-319-49304-6_18. ISBN 978-3-319-49303-9.
- Philipp Scharpf; Moritz Schubotz; et al. (2018). Representing Mathematical Formulae in Content MathML using Wikidata. ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2018).
- Moritz Schubotz; Philipp Scharpf; et al. (2018). "Introducing MathQA: a Math-Aware question answering system". Information Discovery and Delivery. Emerald Publishing Limited. 46 (4): 214–224. arXiv:1907.01642. doi:10.1108/IDD-06-2018-0022. S2CID 49484035.
- "AnnoMathTeX Formula/Identifier Annotation Recommender System".
- Philipp Scharpf; Ian Mackerracher; et al. (17 September 2019). "AnnoMathTeX - a formula identifier annotation recommender system for STEM documents". Proceedings of the 13th ACM Conference on Recommender Systems (PDF). pp. 532–533. doi:10.1145/3298689.3347042. ISBN 9781450362436. S2CID 202639987.
- Philipp Scharpf; Moritz Schubotz; Bela Gipp (14 April 2021). "Fast Linking of Mathematical Wikidata Entities in Wikipedia Articles Using Annotation Recommendation". Companion Proceedings of the Web Conference 2021 (PDF). pp. 602–609. arXiv:2104.05111. doi:10.1145/3442442.3452348. ISBN 9781450383134. S2CID 233210264.
- "MathMLben formula benchmark".
- Moritz Schubotz; André Greiner-Petter; Philipp Scharpf; Norman Meuschke; Howard Cohl; Bela Gipp (2018). "Improving the Representation and Conversion of Mathematical Formulae by Considering their Textual Context". Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries (PDF). pp. 233–242. arXiv:1804.04956. doi:10.1145/3197026.3197058. ISBN 9781450351782. PMC 8474120. PMID 34584342. S2CID 4872257.
{{cite book}}:|journal=ignored (help) - "arXiv preprint repository".
- "zbMath mathematical document library".
- André Greiner-Petter; Moritz Schubotz; Fabian Mueller; Corinna Breitinger; Howard S. Cohl; Akiko Aizawa; Bela Gipp (2020). "Discovering Mathematical Objects of Interest—A Study of Mathematical Notations". Proceedings of the Web Conference 2020 (PDF). pp. 1445–1456. arXiv:2002.02712. doi:10.1145/3366423.3380218. ISBN 9781450370233. S2CID 211066554.
- Akiko Aizawa; Michael Kohlhase; Iadh Ounis; Moritz Schubotz. "NTCIR-11 Math-2 Task Overview". Proceedings of the 11th NTCIR Conference on Evaluation of Information Access Technologies.