Failure detector
In a distributed computing system, a failure detector is a computer application or a subsystem that is responsible for the detection of node failures or crashes.[1] Failure detectors were first introduced in 1996 by Chandra and Toueg in their book Unreliable Failure Detectors for Reliable Distributed Systems. The book depicts the failure detector as a tool to improve consensus (the achievement of reliability) and atomic broadcast (the same sequence of messages) in the distributed system. In other words, failure detectors seek errors in the process, and the system will maintain a level of reliability. In practice, after failure detectors spot crashes, the system will ban the processes that are making mistakes to prevent any further serious crashes or errors.[2][3]
In the 21st century, failure detectors are widely used in distributed computing systems to detect application errors, such as a software application stops functioning properly. As the distributed computing projects (see List of distributed computing projects) become more and more popular, the usage of the failure detects also becomes important and critical.[4][5]
Origin
Unreliable failure detector
Chandra and Toueg, the co-authors of the book Unreliable Failure Detectors for Reliable Distributed Systems (1996), approached the concept of detecting failure nodes by introducing the unreliable failure detector.[6] They describe the behavior of a unreliable failure detector in a distributed computing system as: after each process in the system entered a local failure detector component, each local component will examine a portion of all processes within the system.[5] In addition, each process must also contain programs that are currently suspected by failure detectors.[5]
Failure detector
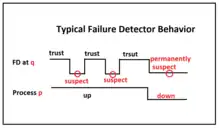
Chandra and Toueg claimed that an unreliable failure detector can still be reliable in detecting the errors made by the system.[6] They generalize unreliable failure detectors to all forms of failure detectors because unreliable failure detectors and failure detectors share the same properties. Furthermore, Chandra and Toueg point out an important fact that the failure detector does not prevent any crashes in the system, even if the crashed program has been suspected previously. The construction of a failure detector is an essential, but a very difficult problem that occurred in the development of the fault-tolerant component in a distributed computer system. As a result, the failure detector was invented because of the need for detecting errors in the massive information transaction in distributed computing systems.[1][3][5]
Properties
The classes of failure detectors are distinguished by two important properties: completeness and accuracy. Completeness means that the failure detectors would find the programs that finally crashed in a process, whereas accuracy means that correct decisions that the failure detectors made in a process.[5]
Degrees of completeness
The degrees of completeness depend on the number of crashed process is suspected by a failure detector in a certain period.[5]
Degrees of accuracy
The degrees of accuracy depend on the number of mistakes that a failure detector made in a certain period.[5]
- Strong accuracy: "no process is suspected (by anybody) before it crashes."[6]
- Weak accuracy: "some non-faulty process is never suspected."[6]
- Eventual strong accuracy: "no non-faulty process is suspected after some time since the end of the initial period of chaos as the time at which the last crash occurs."[6]
- Eventual weak accuracy: "after some initial period of confusion, some non-faulty process is never suspected."[6]
Classification
Failure detectors can be categorized in the following eight types:[1][7]
- Perfect failure detector (P)
- Eventually perfect failure detectors (♦P)
- Strong failure detectors (S)
- Eventually strong failure detectors (♦S)
- Weak failure detectors (W)
- Eventually weak failure detectors (♦W)
- Quasi-perfect failure detectors (Q)
- Eventually quasi-perfect failure detectors (♦Q)
The properties of these failure detectors are described below:[1]
Accuracy Complete- ness |
Strong Perpetual Accuracy |
Weak Perpetual Accuracy |
Strong Eventual Accuracy |
Weak Eventual Accuracy |
|---|---|---|---|---|
| Strong Completeness | P | S | ♦P | ♦S |
| Weak Completeness | Q | W | ♦Q | ♦W |
In a nutshell, the properties of failure detectors depend on how fast the failure detector detects actual failures and how well it avoids false detection. A perfect failure detector will find all errors without any mistakes, whereas a weak failure detector will not find any errors and make numerous mistakes.[3][8]
Applications
Different types of failure detectors can be obtained by changing the properties of failure detectors.[3][6] The first examples show that how to increase completeness of a failure detector, and the second example shows that how to change one type of the failure detector to another.
Boosting completeness
The following is an example abstracted from the Department of Computer Science at Yale University. It functions by boosting the completeness of a failure detector.[6]
initially suspects = ∅
do forever:
for each process p:
if my weak-detector suspects p, then send p to all processes
upon receiving p from some process q:
suspects := suspects + p - q
From the example above, if p crashes, then the weak-detector will eventually suspect it. All failure detectors in the system will eventually suspect the p because of the infinite loop created by failure detectors. This example also shows that a weak completeness failure detector can also suspect all crashes eventually.[6] The inspection of crashed programs does not depend on completeness.[5]
Reducing a failure detector W to a failure detector S
The following are correctness arguments to satisfy the algorithm of changing a failure detector W to a failure detector S.[1] The failure detector W is weak in completeness, and the failure detector S is strong in completeness. They are both weak in accuracy.[6]
- It transforms weak completeness into strong completeness.[1]
- It preserves the perpetual accuracy.[1]
- It preserves the eventual accuracy.[1]
If all arguments above are satisfied, the reduction of a weak failure detector W to a strong failure detector S will agree with the algorithm within the distributed computing system.[1]
See also
References
- D., Kshemkalyani, Ajay (2008). Distributed computing : principles, algorithms, and systems. Singhal, Mukesh. Cambridge: Cambridge University Press. ISBN 9780521189842. OCLC 175284075.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Aguilera, Marcos Kawazoe; Chen, Wei; Toueg, Sam (2000-04-01). "Failure detection and consensus in the crash-recovery model". Distributed Computing. 13 (2): 99–125. doi:10.1007/s004460050070. hdl:1813/7330. ISSN 0178-2770.
- Fischer, Michael J.; Lynch, Nancy A.; Paterson, Michael S. (April 1985). "Impossibility of Distributed Consensus with One Faulty Process". J. ACM. 32 (2): 374–382. CiteSeerX 10.1.1.13.6760. doi:10.1145/3149.214121. ISSN 0004-5411.
- Holohan, Anne; Garg, Anurag (2005-07-01). "Collaboration Online: The Example of Distributed Computing". Journal of Computer-Mediated Communication. 10 (4): 00. doi:10.1111/j.1083-6101.2005.tb00279.x. ISSN 1083-6101.
- Chandra, Tushar Deepak; Toueg, Sam (1996). Unreliable failure detectors for reliable distributed systems. pp. 225–267. doi:10.1145/226643.226647. hdl:1813/7192. ISBN 978-0897914390.
{{cite book}}:|journal=ignored (help) - "FailureDetectors". www.cs.yale.edu. Retrieved 2017-10-23.
- Aguilera, Marcos Kawazoe; Toueg, Sam (1996-10-09). "Randomization and failure detection: A hybrid approach to solve Consensus". Distributed Algorithms. Lecture Notes in Computer Science. Vol. 1151. Springer, Berlin, Heidelberg. pp. 29–39. CiteSeerX 10.1.1.88.1597. doi:10.1007/3-540-61769-8_3. ISBN 978-3540617693.
- Chen, Wei; Toueg, S.; Aguilera, M. K. (January 2002). "On the quality of service of failure detectors". IEEE Transactions on Computers. 51 (1): 13–32. CiteSeerX 10.1.1.461.5630. doi:10.1109/12.980014. ISSN 0018-9340.
External links
- http://www.cs.yale.edu/homes/aspnes/pinewiki/FailureDetectors.html
- http://www.cs.cornell.edu/home/sam/FDpapers.html
