Features from accelerated segment test
Features from accelerated segment test (FAST) is a corner detection method, which could be used to extract feature points and later used to track and map objects in many computer vision tasks. The FAST corner detector was originally developed by Edward Rosten and Tom Drummond, and was published in 2006.[1] The most promising advantage of the FAST corner detector is its computational efficiency. Referring to its name, it is indeed faster than many other well-known feature extraction methods, such as difference of Gaussians (DoG) used by the SIFT, SUSAN and Harris detectors. Moreover, when machine learning techniques are applied, superior performance in terms of computation time and resources can be realised. The FAST corner detector is very suitable for real-time video processing application because of this high-speed performance.
Segment test detector
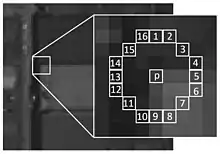
FAST corner detector uses a circle of 16 pixels (a Bresenham circle of radius 3) to classify whether a candidate point p is actually a corner. Each pixel in the circle is labeled from integer number 1 to 16 clockwise. If a set of N contiguous pixels in the circle are all brighter than the intensity of candidate pixel p (denoted by Ip) plus a threshold value t or all darker than the intensity of candidate pixel p minus threshold value t, then p is classified as corner. The conditions can be written as:
- Condition 1: A set of N contiguous pixels S, , the intensity of x > Ip + threshold, or
- Condition 2: A set of N contiguous pixels S, ,



So when either of the two conditions is met, candidate p can be classified as a corner. There is a tradeoff of choosing N, the number of contiguous pixels and the threshold value t. On one hand the number of detected corner points should not be too many, on the other hand, the high performance should not be achieved by sacrificing computational efficiency. Without the improvement of machine learning, N is usually chosen as 12. A high-speed test method could be applied to exclude non-corner points.
High-speed test
The high-speed test for rejecting non-corner points is operated by examining 4 example pixels, namely pixel 1, 9, 5 and 13. Because there should be at least 12 contiguous pixels that are whether all brighter or darker than the candidate corner, so there should be at least 3 pixels out of these 4 example pixels that are all brighter or darker than the candidate corner. Firstly pixels 1 and 9 are examined, if both I1 and I9 are within [Ip - t, Ip + t], then candidate p is not a corner. Otherwise pixels 5 and 13 are further examined to check whether three of them are brighter than Ip + t or darker than Ip - t. If there exists 3 of them that are either brighter or darker, the rest pixels are then examined for final conclusion. And according to the inventor in his first paper,[2] on average 3.8 pixels are needed to check for candidate corner pixel. Compared with 8.5 pixels for each candidate corner, 3.8 is really a great reduction which could highly improve the performance.
However, there are several weaknesses for this test method:
- The high-speed test cannot be generalized well for N < 12. If N < 12, it would be possible that a candidate p is a corner and only 2 out of 4 example test pixels are both brighter Ip + t or darker than Ip - t.
- The efficiency of the detector depends on the choice and ordering of these selected test pixels. However it is unlikely that the chosen pixels are optimal which take concerns about the distribution of corner appearances.
- Multiple features are detected adjacent to one another
Improvement with machine learning
In order to address the first two weakness points of high-speed test, a machine learning approach is introduced to help improve the detecting algorithm. This machine learning approach operates in two stages. Firstly, corner detection with a given N is processed on a set of training images which are preferable from the target application domain. Corners are detected through the simplest implementation which literally extracts a ring of 16 pixels and compares the intensity values with an appropriate threshold.
For candidate p, each location on the circle x ∈ {1, 2, 3, ..., 16} can be denoted by p→x. The state of each pixel, Sp→x must be in one of the following three states:
- d, Ip→x ≤ Ip - t (darker)
- s, Ip - t ≤ Ip→x ≤ Ip + t (similar)
- b, Ip→x≥ Ip + t (brighter)
Then choosing an x (same for all p) partitions P (the set of all pixels of all training images) into 3 different subsets, Pd, Ps, Pb where:
- Pd = {p ∈ P : Sp→x = d }
- Ps = {p ∈ P : Sp→x = s }
- Pb = {p ∈ P : Sp→x = b }
Secondly, a decision tree algorithm, the ID3 algorithm is applied to the 16 locations in order to achieve the maximum information gain. Let Kp be a boolean variable which indicates whether p is a corner, then the entropy of Kp is used to measure the information of p being a corner. For a set of pixels Q, the total entropy of KQ (not normalized) is:
- H(Q) = ( c + n ) log2( c + n ) - clog2c - nlog2n
- where c = |{ i ∈ Q: Ki is true}| (number of corners)
- where n = |{ i ∈ Q: Ki is false}| (number of non-corners)
The information gain can then be represented as:
- Hg= H(P) - H(Pb) - H(Ps) - H(Pd)
A recursive process is applied to each subsets in order to select each x that could maximize the information gain. For example, at first an x is selected to partition P into Pd, Ps, Pb with the most information; then for each subset Pd, Ps, Pb, another y is selected to yield the most information gain (notice that the y could be the same as x ). This recursive process ends when the entropy is zero so that either all pixels in that subset are corners or non-corners.
This generated decision tree can then be converted into programming code, such as C and C++, which is just a bunch of nested if-else statements. For optimization purpose, profile-guided optimization is used to compile the code. The complied code is used as corner detector later for other images.
Notice that the corners detected using this decision tree algorithm should be slightly different from the results using segment test detector. This is because that decision tree model depends on the training data, which could not cover all possible corners.
Non-maximum suppression
"Since the segment test does not compute a corner response function, non-maximum suppression can not be applied directly to the resulting features." However, if N is fixed, for each pixel p the corner strength is defined as the maximum value of t that makes p a corner. Two approaches therefore could be used:
- A binary search algorithm could be applied to find the biggest t for which p is still a corner. So each time a different t is set for the decision tree algorithm. When it manages to find the biggest t, that t could be regarded as the corner strength.
- Another approach is an iteration scheme, where each time t is increased to the smallest value of which pass the test.
FAST-ER: Enhanced repeatability
FAST-ER detector is an improvement of the FAST detector using a metaheuristic algorithm, in this case simulated annealing. So that after the optimization, the structure of the decision tree would be optimized and suitable for points with high repeatability. However, since simulated annealing is a metaheurisic algorithm, each time the algorithm would generate a different optimized decision tree. So it is better to take efficiently large amount of iterations to find a solution that is close to the real optimal. According to Rosten, it takes about 200 hours on a Pentium 4 at 3 GHz which is 100 repeats of 100,000 iterations to optimize the FAST detector.
Comparison with other detectors
In Rosten's research,[3] FAST and FAST-ER detector are evaluated on several different datasets and compared with the DoG, Harris, Harris-Laplace, Shi-Tomasi, and SUSAN corner detectors.
The parameter settings for the detectors (other than FAST) are as follows:
| Detector | Parameter Setting | Value |
|---|---|---|
| DoG | ||
| Scales per octave | 3 | |
| Initial blur σ | 0.8 | |
| Octaves | 4 | |
| SUSAN | Distance threshold | 4.0 |
| Harris, Shi-Tomasi | Blur σ | 2.5 |
| Harris-Laplace | Initial blur σ | 0.8 |
| Harris blur | 3 | |
| Octaves | 4 | |
| Scales per octave | 10 | |
| General parameters | ε | 5 pixels |
- Repeatability test result is presented as the averaged area under repeatability curves for 0-2000 corners per frame over all datasets (except the additive noise):
| Detector | A |
|---|---|
| FAST-ER | 1313.6 |
| FAST-9 | 1304.57 |
| DOG | 1275.59 |
| Shi & Tomasi | 1219.08 |
| Harris | 1195.2 |
| Harris-Laplace | 1153.13 |
| FAST-12 | 1121.53 |
| SUSAN | 1116.79 |
| Random | 271.73 |
- Speed tests were performed on a 3.0 GHz Pentium 4-D computer. The dataset are divided into a training set and a test set. The training set consists of 101 monochrome images with a resolution of 992×668 pixels. The test set consists of 4968 frames of monochrome 352×288 video. And the result is:
| Detector | Training set pixel rate | Test set pixel rate |
|---|---|---|
| FAST n=9 | 188 | 179 |
| FAST n=12 | 158 | 154 |
| Original FAST n=12 | 79 | 82.2 |
| FAST-ER | 75.4 | 67.5 |
| SUSAN | 12.3 | 13.6 |
| Harris | 8.05 | 7.90 |
| Shi-Tomasi | 6.50 | 6.50 |
| DoG | 4.72 | 5.10 |
References
- Rosten, Edward; Drummond, Tom (2006). "Machine Learning for High-speed Corner Detection". Computer Vision – ECCV 2006. Lecture Notes in Computer Science. Vol. 3951. pp. 430–443. doi:10.1007/11744023_34. ISBN 978-3-540-33832-1. S2CID 1388140.
- Edward Rosten, Real-time Video Annotations for Augmented Reality
- Edward Rosten, FASTER and better: A machine learning approach to corner detection
Bibliography
- Rosten, Edward; Tom Drummond (2005). "Fusing points and lines for high performance tracking". Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1 (PDF). Vol. 2. pp. 1508–1511. CiteSeerX 10.1.1.60.4715. doi:10.1109/ICCV.2005.104. ISBN 978-0-7695-2334-7. S2CID 1505168.
- Rosten, Edward; Reid Porter; Tom Drummond (2010). "FASTER and better: A machine learning approach to corner detection". IEEE Transactions on Pattern Analysis and Machine Intelligence. 32 (1): 105–119. arXiv:0810.2434. doi:10.1109/TPAMI.2008.275. PMID 19926902. S2CID 206764370.
- Rosten, Edward; Tom Drummond (2006). "Machine Learning for High-Speed Corner Detection". Computer Vision – ECCV 2006 (PDF). pp. 430–443. CiteSeerX 10.1.1.64.8513. doi:10.1007/11744023_34. ISBN 978-3-540-33832-1. S2CID 1388140.
{{cite book}}:|journal=ignored (help)