Federated search
Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines.[1] A user makes a single query request which is distributed to the search engines, databases or other query engines participating in the federation. The federated search then aggregates the results that are received from the search engines for presentation to the user. Federated search can be used to integrate disparate information resources within a single large organization ("enterprise") or for the entire web.
Federated search, unlike distributed search, requires centralized coordination of the searchable resources. This involves both coordination of the queries transmitted to the individual search engines and fusion of the search results returned by each of them.
Purpose
Federated search came about to meet the need of searching multiple disparate content sources with one query. This allows a user to search multiple databases at once in real time, arrange the results from the various databases into a useful form and then present the results to the user.
As such, it is an information aggregation or integration approach - it provides single point access to many information resources, and typically returns the data in a standard or partially homogenized form. Other approaches include constructing an Enterprise data warehouse, Data lake, or Data hub. Federated Search queries many times in many ways (each source is queried separately) where other approaches import and transform data many times, typically in overnight batch processes. Federated search provides a real-time view of all sources (to the extent they are all online and available).
In industrial search engines, such as LinkedIn, federated search is used to personalize vertical preference for ambiguous queries.[2] For instance, when a user issues a query like "machine learning" on LinkedIn, he or she could mean to search for people with machine learning skill, jobs requiring machine learning skill or content about the topic. In such cases, federated search could exploit user intent (e.g., hiring, job seeking or content consuming) to personalize the vertical order for each individual user.
Process
As described by Peter Jacso (2004[3]), federated searching consists of (1) transforming a query and broadcasting it to a group of disparate databases or other web resources, with the appropriate syntax, (2) merging the results collected from the databases, (3) presenting them in a succinct and unified format with minimal duplication, and (4) providing a means, performed either automatically or by the portal user, to sort the merged result set.
Federated search portals, either commercial or open access, generally search public access bibliographic databases, public access Web-based library catalogues (OPACs), Web-based search engines like Google and/or open-access, government-operated or corporate data collections. These individual information sources send back to the portal's interface a list of results from the search query. The user can review this hit list. Some portals will merely screen scrape the actual database results and not directly allow a user to enter the information source's application. More sophisticated ones will de-dupe the results list by merging and removing duplicates. There are additional features available in many portals, but the basic idea is the same: to improve the accuracy and relevance of individual searches as well as reduce the amount of time required to search for resources.
This process allows federated search some key advantages when compared with existing crawler-based search engines. Federated search need not place any requirements or burdens on owners of the individual information sources, other than handling increased traffic. Federated searches are inherently as current as the individual information sources, as they are searched in real time.
Implementation
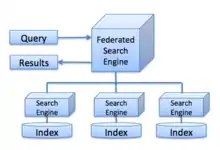
One application of federated searching is the metasearch engine. However, the metasearch approach does not overcome the shortcomings of the component search engines, such as incomplete indexes. Documents that are not indexed by search engines create what is known as the deep Web, or invisible Web. Google Scholar is one example of many projects trying to address this, by indexing electronic documents that search engines ignore. And the metasearch approach, like the underlying search engine technology, only works with information sources stored in electronic form.
One of the main challenges of metasearch, is ensuring that the search query is compatible with the component search engines that are being federated and combined. When the search vocabulary or data model of the search system is different from the data model of one or more of the foreign target systems, the query must be translated into each of the foreign target systems. This can be done using simple data-element translation or may require semantic translation. For example, if one search engine allows for quoting of exact strings or n-grams and another does not, the query must be translated to be compatible with each search engine. To translate a quoted exact string query, it can be broken down into a set of overlapping N-grams that are most likely to give the desired search results in each search engine.
Another challenge faced in the implementation of federated search engines is scalability. It is difficult to maintain the performance, the response speed, of a federated search engine as it combines more and more information sources together. One implementation of federated search that has begun to address this issue is WorldWideScience, hosted by the U.S. Department of Energy's Office of Scientific and Technical Information. WorldWideScience[4] is composed of more than 40 information sources, several of which are federated search portals themselves. One such portal is Science.gov[5] which itself federates more than 30 information sources representing most of the R&D output of the U.S. Federal government. Science.gov returns its highest ranked results to WorldWideScience, which then merges and ranks these results with the search returned by the other information sources that comprise WorldWideScience.[5] This approach of cascaded federated search enables large number of information sources to be searched via a single query.
Another application Sesam running in both Norway and Sweden has been built on top of an open sourced platform specialised for federated search solutions. Sesat,[6] an acronym for Sesam Search Application Toolkit, is a platform that provides much of the framework and functionality required for handling parallel and pipelined searches and displaying them elegantly in a user interface, allowing engineers to focus on the index/database configuration tuning.
To personalize vertical orders in federated search, LinkedIn search engine[2] exploits the searcher's profile and recent activities to infer his or her intent, such as hiring, job seeking and content consuming, then uses the intent, along with many other signals, to rank vertical orders that are personally relevant to the individual searcher.
SWIRL Search[7] is an open source federated search engine, released under the Apache 2.0 license. It includes pre-built connectors to popular open source search engines, and re-ranks results using cosine vector similarity.
Challenges
Federated searches present a number of significant challenges, as compared with conventional, single-source searches:
1. Passing of credentials
When federated search is performed against secure data sources, the users' credentials must be passed on to each underlying search engine, so that appropriate security is maintained. If the user has different login credentials for different systems, there must be a means to map their login ID to each search engine's security domain.[8]
2. Mapping results list navigators into a common form
Suppose three real-estate sites are searched, each provides a list of hyperlinked city names to click on, to see matches only in each city. Ideally these facets would be combined into one set, but that presents additional technical challenges.[9] The system also needs to understand "next page" links if it's going to allow the user to page through the combined results.
Some of this challenge of mapping to a common form can be solved if the federated resources support linked open data via RDF. Ontologies (rules) can be added to map results to common forms using that technology.
3. Sorting and scoring results
Each web resource has its own notion of relevance score, and may support some sorted results orders. Relevance varies greatly among "federates" in the search, so knowing how to interleave results to show the most relevant is difficult or impossible.
4. Robust query
Federated search may have to restrict itself to the minimal set of query capabilities that are common to all federates. E.g. if Google supports negation and quoted phrases, but science.gov does not, it will be impossible for the federated search to support negated, quoted phrases.
5. Availability and timeout
As the number of federates (federated sources) grows, the likelihood of one or more slow or offline federates becomes high. The federated search must decide when to consider a federate offline, or wait for a slow response. Response times will be dictated by the slowest federate of the bunch.
6. Development and testing within an enterprise (vs. on the public internet)
Development groups should typically not hit live, production systems as they do regular work, much less intensive load testing. Also, some resources are secure, and should not be arbitrarily queried and exposed in development due to privacy and security concerns. Therefore, the development, testing and performance test environments must include installation and configuration for many sub-systems to allow safe, secure testing.
7. HA/DR (high-availability and disaster recovery)
For the overall federated system to be HA/DR, every sub-system must be HA/DR.
Similarly, performance modeling and capacity planning for the federated system requires modeling, planning and sometimes expansion of all federates.
For all of the above reasons, within an enterprise, a data hub or data lake may be preferable, or a hybrid approach. Data hubs and lakes simplify development and access, but may incur some time lag before data is available (without special synchronizing logic). On the web, federation is more typical.
See also
References
- "What is Federated Search?". Coveo Blog. Coveo. Retrieved June 29, 2020.
- Arya, Dhruv; Ha-Thuc, Viet; Sinha, Shakti (2015). "Personalized Federated Search at LinkedIn". Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (CIKM). pp. 1699–1702. arXiv:1602.04924. doi:10.1145/2806416.2806615. ISBN 9781450337946.
- Thoughts About Federated Searching. Jacsó, Péter, Information Today, Oct 2004, Vol. 21, Issue 9
- WorldWideScience
- Science.gov
- "Sesat". Archived from the original on 2015-07-20. Retrieved 2019-08-17.
- "SWIRL SEARCH". Retrieved 2022-09-08.
- Mapping Security Requirements to Enterprise Search
- 20+ Differences Between Internet vs. Enterprise Search - part 1
Further reading
- Federated Search 101. Linoski, Alexis, Walczyk, Tine, Library Journal, Summer 2008 Net Connect, Vol. 133. This content has been moved here, but you will need a remote access account through your local library to get the whole article.
- Cox, Christopher N. Federated Search: Solution or Setback for Online Library Services. Binghamton, NY: Haworth Information Press, 2007. Table of Contents
- Federated Search Primer. Lederman, S., AltSearchEngines, January 2009. This material has been reposted here Archived 2019-11-14 at the Wayback Machine, on the blog of a commercial search engine company.
- Si, Luo; Shokouhi, Milad (2011). "Federated Search". Foundations and Trends in Information Retrieval. 5: 1–102. doi:10.1561/1500000010.