Flow-based generative model
A flow-based generative model is a generative model used in machine learning that explicitly models a probability distribution by leveraging normalizing flow,[1][2] which is a statistical method using the change-of-variable law of probabilities to transform a simple distribution into a complex one.
| Part of a series on |
| Machine learning and data mining |
|---|
 |
The direct modeling of likelihood provides many advantages. For example, the negative log-likelihood can be directly computed and minimized as the loss function. Additionally, novel samples can be generated by sampling from the initial distribution, and applying the flow transformation.
In contrast, many alternative generative modeling methods such as variational autoencoder (VAE) and generative adversarial network do not explicitly represent the likelihood function.
Method
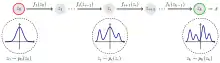
Let be a (possibly multivariate) random variable with distribution .


For , let be a sequence of random variables transformed from . The functions should be invertible, i.e. the inverse function exists. The final output models the target distribution.





The log likelihood of is (see derivation):

To efficiently compute the log likelihood, the functions should be 1. easy to invert, and 2. easy to compute the determinant of its Jacobian. In practice, the functions are modeled using deep neural networks, and are trained to minimize the negative log-likelihood of data samples from the target distribution. These architectures are usually designed such that only the forward pass of the neural network is required in both the inverse and the Jacobian determinant calculations. Examples of such architectures include NICE,[3] RealNVP,[4] and Glow.[5]
Derivation of log likelihood
Consider and . Note that .


By the change of variable formula, the distribution of is:

Where is the determinant of the Jacobian matrix of .


By the inverse function theorem:

By the identity (where is an invertible matrix), we have:



The log likelihood is thus:

In general, the above applies to any and . Since is equal to subtracted by a non-recursive term, we can infer by induction that:




Training method
As is generally done when training a deep learning model, the goal with normalizing flows is to minimize the Kullback–Leibler divergence between the model's likelihood and the target distribution to be estimated. Denoting the model's likelihood and the target distribution to learn, the (forward) KL-divergence is:


![{\displaystyle D_{KL}[p^{*}(x)||p_{\theta }(x)]=-\mathbb {E} _{p^{*}(x)}[\log(p_{\theta }(x))]+\mathbb {E} _{p^{*}(x)}[\log(p^{*}(x))]}](../I/04ee6882a8ed6fc75f6d21a5fba1dd3432444f8d.svg)
The second term on the right-hand side of the equation corresponds to the entropy of the target distribution and is independent of the parameter we want the model to learn, which only leaves the expectation of the negative log-likelihood to minimize under the target distribution. This intractable term can be approximated with a Monte-Carlo method by importance sampling. Indeed, if we have a dataset of samples each independently drawn from the target distribution , then this term can be estimated as:



![{\displaystyle -{\hat {\mathbb {E} }}_{p^{*}(x)}[\log(p_{\theta }(x))]=-{\frac {1}{N}}\sum _{i=0}^{N}\log(p_{\theta }(x_{i}))}](../I/30a12e136dd2aef8e2decc70137af8f7c23c446f.svg)
Therefore, the learning objective
![{\displaystyle {\underset {\theta }{\operatorname {arg\,min} }}\ D_{KL}[p^{*}(x)||p_{\theta }(x)]}](../I/f0a4c309afb71183258b303be7a3cc0a6f0d9387.svg)
is replaced by

In other words, minimizing the Kullback–Leibler divergence between the model's likelihood and the target distribution is equivalent to maximizing the model likelihood under observed samples of the target distribution.[6]
A pseudocode for training normalizing flows is as follows:[7]
- INPUT. dataset , normalizing flow model .
- SOLVE. by gradient descent
- RETURN.




Variants
Planar Flow
The earliest example.[8] Fix some activation function , and let with th appropriate dimensions, then



The inverse has no closed-form solution in general.

The Jacobian is .

For it to be invertible everywhere, it must be nonzero everywhere. For example, and satisfies the requirement.


Nonlinear Independent Components Estimation (NICE)
Let be even-dimensional, and split them in the middle.[3] Then the normalizing flow functions are


where is any neural network with weights .

is just , and the Jacobian is just 1, that is, the flow is volume-preserving.

When , this is seen as a curvy shearing along the direction.


Real Non-Volume Preserving (Real NVP)
The Real Non-Volume Preserving model generalizes NICE model by:[4]

Its inverse is , and its Jacobian is . The NICE model is recovered by setting . Since the Real NVP map keeps the first and second halves of the vector separate, it's usually required to add a permutation after every Real NVP layer.





Generative Flow (Glow)
In generative flow model,[5] each layer has 3 parts:
- channel-wise affine transformwith Jacobian .
- invertible 1x1 convolutionwith Jacobian . Here is any invertible matrix.
- Real NVP, with Jacobian as described in Real NVP.





The idea of using the invertible 1x1 convolution is to permute all layers in general, instead of merely permuting the first and second half, as in Real NVP.
Masked autoregressive flow (MAF)
An autoregressive model of a distribution on is defined as the following stochastic process:[9]


where and are fixed functions that define the autoregressive model. By the reparametrization trick, the autoregressive model is generalized to a normalizing flow:



The autoregressive model is recovered by setting .

The forward mapping is slow (because it's sequential), but the backward mapping is fast (because it's parallel).
The Jacobian matrix is lower-diagonal, so the Jacobian is .

Reversing the two maps and of MAF results in Inverse Autoregressive Flow (IAF), which has fast forward mapping and slow backward mapping.[10]

Continuous Normalizing Flow (CNF)
Instead of constructing flow by function composition, another approach is to formulate the flow as a continuous-time dynamic.[11][12] Let be the latent variable with distribution . Map this latent variable to data space with the following flow function:


where is an arbitrary function and can be modeled with e.g. neural networks.

The inverse function is then naturally:[11]

And the log-likelihood of can be found as:[11]
![{\displaystyle \log(p(x))=\log(p(z_{0}))-\int _{0}^{T}{\text{Tr}}\left[{\frac {\partial f}{\partial z_{t}}}\right]dt}](../I/6f905397962b6ca087144ba0b8ebed38c6ef7255.svg)
Since the trace depends only on the diagonal of the Jacobian , this allows "free-form" Jacobian.[13] Here, "free-form" means that there is no restriction on the Jacobian's form. It is contrasted with previous discrete models of normalizing flow, where the Jacobian is carefully designed to be only upper- or lower-diagonal, so that the Jacobian can be evaluated efficiently.

The trace can be estimated by "Hutchinson's trick":[14][15]
Given any matrix , and any random with , we have . (Proof: expand the expectation directly.)


![{\displaystyle E[uu^{T}]=I}](../I/53a3c98828325626aa932d00cb0d1d312d00904f.svg)
![{\displaystyle E[u^{T}Wu]=tr(W)}](../I/5cc42305c8e1dd65ccb16b79c599e10d8ebdb0d5.svg)
Usually, the random vector is sampled from (normal distribution) or (Radamacher distribution).


When is implemented as a neural network, neural ODE methods[16] would be needed. Indeed, CNF was first proposed in the same paper that proposed neural ODE.
There are two main deficiencies of CNF, one is that a continuous flow must be a homeomorphism, thus preserve orientation and ambient isotopy (for example, it's impossible to flip a left-hand to a right-hand by continuous deforming of space, and it's impossible to turn a sphere inside out, or undo a knot), and the other is that the learned flow might be ill-behaved, due to degeneracy (that is, there are an infinite number of possible that all solve the same problem).
By adding extra dimensions, the CNF gains enough freedom to reverse orientation and go beyond ambient isotopy (just like how one can pick up a polygon from a desk and flip it around in 3-space, or unknot a knot in 4-space), yielding the "augmented neural ODE".[17]
Any homeomorphism of can be approximated by a neural ODE operating on , proved by combining Whitney embedding theorem for manifolds and the universal approximation theorem for neural networks.[18]

To regularize the flow , one can impose regularization losses. The paper [14] proposed the following regularization loss based on optimal transport theory:

where are hyperparameters. The first term punishes the model for oscillating the flow field over time, and the second term punishes it for oscillating the flow field over space. Both terms together guide the model into a flow that is smooth (not "bumpy") over space and time.

Downsides
Despite normalizing flows success in estimating high-dimensional densities, some downsides still exist in their designs. First of all, their latent space where input data is projected onto is not a lower-dimensional space and therefore, flow-based models do not allow for compression of data by default and require a lot of computation. However, it is still possible to perform image compression with them.[19]
Flow-based models are also notorious for failing in estimating the likelihood of out-of-distribution samples (i.e.: samples that were not drawn from the same distribution as the training set).[20] Some hypotheses were formulated to explain this phenomenon, among which the typical set hypothesis,[21] estimation issues when training models,[22] or fundamental issues due to the entropy of the data distributions.[23]
One of the most interesting properties of normalizing flows is the invertibility of their learned bijective map. This property is given by constraints in the design of the models (cf.: RealNVP, Glow) which guarantee theoretical invertibility. The integrity of the inverse is important in order to ensure the applicability of the change-of-variable theorem, the computation of the Jacobian of the map as well as sampling with the model. However, in practice this invertibility is violated and the inverse map explodes because of numerical imprecision.[24]
Applications
Flow-based generative models have been applied on a variety of modeling tasks, including:
References
- Tabak, Esteban G.; Turner, Cristina V. (2012). "A family of nonparametric density estimation algorithms". Communications on Pure and Applied Mathematics. 66 (2): 145–164. doi:10.1002/cpa.21423. hdl:11336/8930. S2CID 17820269.
- Papamakarios, George; Nalisnick, Eric; Jimenez Rezende, Danilo; Mohamed, Shakir; Bakshminarayanan, Balaji (2021). "Normalizing flows for probabilistic modeling and inference". Journal of Machine Learning Research. 22 (1): 2617–2680.
- Dinh, Laurent; Krueger, David; Bengio, Yoshua (2014). "NICE: Non-linear Independent Components Estimation". arXiv:1410.8516 [cs.LG].
- Dinh, Laurent; Sohl-Dickstein, Jascha; Bengio, Samy (2016). "Density estimation using Real NVP". arXiv:1605.08803 [cs.LG].
- Kingma, Diederik P.; Dhariwal, Prafulla (2018). "Glow: Generative Flow with Invertible 1x1 Convolutions". arXiv:1807.03039 [stat.ML].
- Papamakarios, George; Nalisnick, Eric; Rezende, Danilo Jimenez; Shakir, Mohamed; Balaji, Lakshminarayanan (March 2021). "Normalizing Flows for Probabilistic Modeling and Inference". Journal of Machine Learning Research. 22 (57): 1–64. arXiv:1912.02762.
- Kobyzev, Ivan; Prince, Simon J.D.; Brubaker, Marcus A. (November 2021). "Normalizing Flows: An Introduction and Review of Current Methods". IEEE Transactions on Pattern Analysis and Machine Intelligence. 43 (11): 3964–3979. arXiv:1908.09257. doi:10.1109/TPAMI.2020.2992934. ISSN 1939-3539. PMID 32396070. S2CID 208910764.
- Danilo Jimenez Rezende; Mohamed, Shakir (2015). "Variational Inference with Normalizing Flows". arXiv:1505.05770 [stat.ML].
- Papamakarios, George; Pavlakou, Theo; Murray, Iain (2017). "Masked Autoregressive Flow for Density Estimation". Advances in Neural Information Processing Systems. Curran Associates, Inc. 30. arXiv:1705.07057.
- Kingma, Durk P; Salimans, Tim; Jozefowicz, Rafal; Chen, Xi; Sutskever, Ilya; Welling, Max (2016). "Improved Variational Inference with Inverse Autoregressive Flow". Advances in Neural Information Processing Systems. Curran Associates, Inc. 29. arXiv:1606.04934.
- Grathwohl, Will; Chen, Ricky T. Q.; Bettencourt, Jesse; Sutskever, Ilya; Duvenaud, David (2018). "FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models". arXiv:1810.01367 [cs.LG].
- Lipman, Yaron; Chen, Ricky T. Q.; Ben-Hamu, Heli; Nickel, Maximilian; Le, Matt (2022-10-01). "Flow Matching for Generative Modeling".
{{cite journal}}: Cite journal requires|journal=(help) - Grathwohl, Will; Chen, Ricky T. Q.; Bettencourt, Jesse; Sutskever, Ilya; Duvenaud, David (2018-10-22). "FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models". arXiv:1810.01367 [cs.LG].
- Finlay, Chris; Jacobsen, Joern-Henrik; Nurbekyan, Levon; Oberman, Adam (2020-11-21). "How to Train Your Neural ODE: the World of Jacobian and Kinetic Regularization". International Conference on Machine Learning. PMLR: 3154–3164. arXiv:2002.02798.
- Hutchinson, M.F. (January 1989). "A Stochastic Estimator of the Trace of the Influence Matrix for Laplacian Smoothing Splines". Communications in Statistics - Simulation and Computation. 18 (3): 1059–1076. doi:10.1080/03610918908812806. ISSN 0361-0918.
- Chen, Ricky T. Q.; Rubanova, Yulia; Bettencourt, Jesse; Duvenaud, David (2018). "Neural Ordinary Differential Equations". arXiv:1806.07366 [cs.LG].
- Dupont, Emilien; Doucet, Arnaud; Teh, Yee Whye (2019). "Augmented Neural ODEs". Advances in Neural Information Processing Systems. Curran Associates, Inc. 32.
- Zhang, Han; Gao, Xi; Unterman, Jacob; Arodz, Tom (2019-07-30). "Approximation Capabilities of Neural ODEs and Invertible Residual Networks". arXiv:1907.12998 [cs.LG].
- Helminger, Leonhard; Djelouah, Abdelaziz; Gross, Markus; Schroers, Christopher (2020). "Lossy Image Compression with Normalizing Flows". arXiv:2008.10486 [cs.CV].
- Nalisnick, Eric; Matsukawa, Teh; Zhao, Yee Whye; Song, Zhao (2018). "Do Deep Generative Models Know What They Don't Know?". arXiv:1810.09136v3 [stat.ML].
- Nalisnick, Eric; Matsukawa, Teh; Zhao, Yee Whye; Song, Zhao (2019). "Detecting Out-of-Distribution Inputs to Deep Generative Models Using Typicality". arXiv:1906.02994 [stat.ML].
- Zhang, Lily; Goldstein, Mark; Ranganath, Rajesh (2021). "Understanding Failures in Out-of-Distribution Detection with Deep Generative Models". Proceedings of Machine Learning Research. 139: 12427–12436. PMC 9295254. PMID 35860036.
- Caterini, Anthony L.; Loaiza-Ganem, Gabriel (2022). "Entropic Issues in Likelihood-Based OOD Detection". 163: 21–26. arXiv:2109.10794.
{{cite journal}}: Cite journal requires|journal=(help) - Behrmann, Jens; Vicol, Paul; Wang, Kuan-Chieh; Grosse, Roger; Jacobsen, Jörn-Henrik (2020). "Understanding and Mitigating Exploding Inverses in Invertible Neural Networks". arXiv:2006.09347 [cs.LG].
- Ping, Wei; Peng, Kainan; Gorur, Dilan; Lakshminarayanan, Balaji (2019). "WaveFlow: A Compact Flow-based Model for Raw Audio". arXiv:1912.01219 [cs.SD].
- Shi, Chence; Xu, Minkai; Zhu, Zhaocheng; Zhang, Weinan; Zhang, Ming; Tang, Jian (2020). "GraphAF: A Flow-based Autoregressive Model for Molecular Graph Generation". arXiv:2001.09382 [cs.LG].
- Yang, Guandao; Huang, Xun; Hao, Zekun; Liu, Ming-Yu; Belongie, Serge; Hariharan, Bharath (2019). "PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows". arXiv:1906.12320 [cs.CV].
- Kumar, Manoj; Babaeizadeh, Mohammad; Erhan, Dumitru; Finn, Chelsea; Levine, Sergey; Dinh, Laurent; Kingma, Durk (2019). "VideoFlow: A Conditional Flow-Based Model for Stochastic Video Generation". arXiv:1903.01434 [cs.CV].
- Rudolph, Marco; Wandt, Bastian; Rosenhahn, Bodo (2021). "Same Same But DifferNet: Semi-Supervised Defect Detection with Normalizing Flows". arXiv:2008.12577 [cs.CV].