Generalized functional linear model
The generalized functional linear model (GFLM) is an extension of the generalized linear model (GLM) that allows one to regress univariate responses of various types (continuous or discrete) on functional predictors, which are mostly random trajectories generated by a square-integrable stochastic processes. Similarly to GLM, a link function relates the expected value of the response variable to a linear predictor, which in case of GFLM is obtained by forming the scalar product of the random predictor function with a smooth parameter function . Functional Linear Regression, Functional Poisson Regression and Functional Binomial Regression, with the important Functional Logistic Regression included, are special cases of GFLM. Applications of GFLM include classification and discrimination of stochastic processes and functional data.[1]


Overview
A key aspect of GFLM is estimation and inference for the smooth parameter function which is usually obtained by dimension reduction of the infinite dimensional functional predictor. A common method is to expand the predictor function in an orthonormal basis of L2 space, the Hilbert space of square integrable functions with the simultaneous expansion of the parameter function in the same basis. This representation is then combined with a truncation step to reduce the contribution of the parameter function in the linear predictor to a finite number of regression coefficients. Functional principal component analysis (FPCA) that employs the Karhunen–Loève expansion is a common and parsimonious approach to accomplish this. Other orthogonal expansions, like Fourier expansions and B-spline expansions may also be employed for the dimension reduction step. The Akaike information criterion (AIC) can be used for selecting the number of included components. Minimization of cross-validation prediction errors is another criterion often used in classification applications. Once the dimension of the predictor process has been reduced, the simplified linear predictor allows to use GLM and quasi-likelihood estimation techniques to obtain estimates of the finite dimensional regression coefficients which in turn provide an estimate of the parameter function in the GFLM.
Model components
Linear predictor
The predictor functions , typically are square integrable stochastic processes on a real interval and the unknown smooth parameter function , is assumed to be square integrable on . Given a real measure on , the linear predictor is given by where is the centered predictor process and is a scalar that serves as an intercept.







Response variable and variance function
The outcome is typically a real valued random variable which may be either continuous or discrete. Often the conditional distribution of given the predictor process is specified within the exponential family. However it is also sufficient to consider the functional quasi-likelihood set up, where instead of the distribution of the response one specifies the conditional variance function, , as a function of the conditional mean, .



Link function
The link function is a smooth invertible function, that relates the conditional mean of the response with the linear predictor . The relationship is given by .


Formulation
In order to implement the necessary dimension reduction, the centered predictor process and the parameter function are expanded as,



where is an orthonormal basis of the function space such that where if and otherwise.






The random variables are given by and the coefficients as for .





and and denoting , so .




From the orthonormality of the basis functions , it follows immediately that .


The key step is then approximating by for a suitably chosen truncation point .



FPCA gives the most parsimonious approximation of the linear predictor for a given number of basis functions as the eigenfunction basis explains more of the variation than any other set of basis functions.
For a differentiable link function with bounded first derivative, the approximation error of the -truncated model i.e. the linear predictor truncated to the summation of the first components, is a constant multiple of .

A heuristic motivation for the truncation strategy derives from the fact that which is a consequence of the Cauchy–Schwarz inequality and by noting that the right hand side of the last inequality converges to 0 as since both and are finite.




For the special case of the eigenfunction basis, the sequence corresponds to the sequence of the eigenvalues of the covariance kernel .


For data with i.i.d observations, setting , and , the approximated linear predictors can be represented as which are related to the means through .






Estimation
The main aim is to estimate the parameter function .
Once has been fixed, standard GLM and quasi-likelihood methods can be used for the -truncated model to estimate by solving the estimating equation or the score equation


The vector valued score function turns out to be which depends on through and .




Just as in GLM, the equation is solved using iterative methods like Newton–Raphson (NR) or Fisher scoring (FS) or iteratively reweighted least squares (IWLS) to get the estimate of the regression coefficients , leading to the estimate of the parameter function . When using the canonical link function, these methods are equivalent.



Results are available in the literature of -truncated models as which provide asymptotic inference for the deviation of the estimated parametric function from the true parametric function and also asymptotic tests for regression effects and asymptotic confidence regions.
Exponential family response
If the response variable , given follows the one parameter exponential family, then its probability density function or probability mass function (as the case may be) is



for some functions and , where is the canonical parameter, and is a dispersion parameter which is typically assumed to be positive.




In the canonical set up, and from the properties of exponential family,


Hence serves as a link function and is called the canonical link function.

is the corresponding variance function and the dispersion parameter.

Special cases
Functional linear regression (FLR)
Functional linear regression, one of the most useful tools of functional data analysis, is an example of GFLM where the response variable is continuous and is often assumed to have a Normal distribution. The variance function is a constant function and the link function is identity. Under these assumptions the GFLM reduces to the FLR,

Without the normality assumption, the constant variance function motivates the use of quasi-normal techniques.
Functional binary regression
When the response variable has binary outcomes, i.e., 0 or 1, the distribution is usually chosen as Bernoulli, and then . Popular link functions are the expit function, which is the inverse of the logit function (functional logistic regression) and the probit function (functional probit regression). Any cumulative distribution function F has range [0,1] which is the range of binomial mean and so can be chosen as a link function. Another link function in this context is the complementary log–log function, which is an asymmetric link. The variance function for binary data is given by where the dispersion parameter is taken as 1 or alternatively the quasi-likelihood approach is used.


Functional Poisson regression
Another special case of GFLM occurs when the outcomes are counts, so that the distribution of the responses is assumed to be Poisson. The mean is typically linked to the linear predictor via a log-link, which is also the canonical link . The variance function is , where the dispersion parameter is 1, except when the data might be over-dispersed which is when the quasi-Poisson approach is used.



Extensions
Extensions of GFLM have been proposed for the cases where there are multiple predictor functions.[2] Another generalization is called the Semi Parametric Quasi-likelihood Regression (SPQR)[1] which considers the situation where the link and the variance functions are unknown and are estimated non-parametrically from the data. This situation can also be handled by single or multiple index models, using for example Sliced Inverse Regression (SIR).
Another extension in this domain is Functional Generalized Additive Model (FGAM))[3] which is a generalization of generalized additive model(GAM) where

where are the expansion coefficients of the random predictor function and each is an unknown smooth function that has to be estimated and where .


In general, estimation in FGAM requires combining IWLS with backfitting. However, if the expansion coefficients are obtained as functional principal components, then in some cases (e.g. Gaussian predictor function ), they will be independent in which case backfitting is not needed, and one can use popular smoothing methods for estimating the unknown parameter functions .
Application
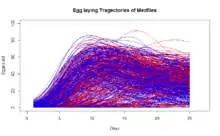
A popular data set that has been used for a number of analysis in the domain of functional data analysis consists of the number of eggs laid daily until death of 1000 Mediterranean fruit flies (or medflies for short). The plot here shows the egg laying trajectories in the first 25 days of life of about 600 female medflies (those that have at least 20 remaining eggs in their lifetime). The red colored curves belong to those flies that will lay less than the median number of remaining eggs, while the blue colored curves belong to the flies that will lay more than the median number of remaining eggs after age 25. An related problem of classifying medflies as long-lived or short-lived based on the initial egg laying trajectories as predictors and the subsequent longevity of the flies as response has been studied with the GFLM[1]
See also
References
- Muller and Stadtmuller (2005). "Generalized Functional Linear Models". The Annals of Statistics. 33 (2): 774–805. arXiv:math/0505638. doi:10.1214/009053604000001156.
- James (2002). "Generalized linear models with functional predictors". Journal of the Royal Statistical Society, Series B. 64 (3): 411–432. CiteSeerX 10.1.1.165.1333. doi:10.1111/1467-9868.00342.
- Muller and Yao (2008). "Functional Additive Models". Journal of the American Statistical Association. 103 (484): 1534–1544. doi:10.1198/016214508000000751.