Hash collision
In computer science, a hash collision or hash clash[1] is when two pieces of data in a hash table share the same hash value. The hash value in this case is derived from a hash function which takes a data input and returns a fixed length of bits.[2]

Although hash algorithms have been created with the intent of being collision resistant, they can still sometimes map different data to the same hash (by virtue of the pigeonhole principle). Malicious users can take advantage of this to mimic, access, or alter data.[3]
Due to the possible negative applications of hash collisions in data management and computer security (in particular, cryptographic hash functions), collision avoidance has become an important topic in computer security.
Background
Hash collisions can be unavoidable depending on the number of objects in a set and whether or not the bit string they are mapped to is long enough in length. When there is a set of n objects, if n is greater than |R|, which in this case R is the range of the hash value, the probability that there will be a hash collision is 1, meaning it is guaranteed to occur.[4]
Another reason hash collisions are likely at some point in time stems from the idea of the birthday paradox in mathematics. This problem looks at the probability of a set of two randomly chosen people having the same birthday out of n number of people.[5] This idea has led to what has been called the birthday attack. The premise of this attack is that it is difficult to find a birthday that specifically matches your birthday or a specific birthday, but the probability of finding a set of any two people with matching birthdays increases the probability greatly. Bad actors can use this approach to make it simpler for them to find hash values that collide with any other hash value – rather than searching for a specific value.[6]
The impact of collisions depends on the application. When hash functions and fingerprints are used to identify similar data, such as homologous DNA sequences or similar audio files, the functions are designed so as to maximize the probability of collision between distinct but similar data, using techniques like locality-sensitive hashing.[7] Checksums, on the other hand, are designed to minimize the probability of collisions between similar inputs, without regard for collisions between very different inputs.[8] Instances where bad actors attempt to create or find hash collisions are known as collision attacks.[9]
In practice, security-related applications use cryptographic hash algorithms, which are designed to be long enough for random matches to be unlikely, fast enough that they can be used anywhere, and safe enough that it would be extremely hard to find collisions.[8]
Probability of occurrence
Hash collisions can occur by chance and can be intentionally created for many hash algorithms. The probability of a hash collision thus depends on the size of the algorithm, the distribution of hash values, and whether or not it is both mathematically known and computationally feasible to create specific collisions.
Take into account the following hash algorithms – CRC-32, MD5, and SHA-1. These are common hash algorithms with varying levels of collision risk.[10]
CRC-32
CRC-32 poses the highest risk for hash collisions. This hash function is generally not recommended for use. If a hub were to contain 77,163 hash values, the chance of a hash collision occurring is 50%, which is extremely high compared to other methods.[11]
MD5
MD5 is the most commonly used and when compared to the other two hash functions, it represents the middle ground in terms of hash collision risk. In order to get a 50% chance of a hash collision occurring, there would have to be over 5.06 billion records in the hub.[11]
SHA-1
SHA-1 offers the lowest risk for hash collisions. For a SHA-1 function to have a 50% chance of a hash collision occurring, there would have to be 1.42 × 1024 records in the hub. Note, the number of records mentioned in these examples would have to be in the same hub.[11]
Having a hub with a smaller number of records could decrease the probability of a hash collision in all of these hash functions, although there will always be a minor risk present, which is inevitable, unless collision resolution techniques are used.
Collision resolution
Since hash collisions are inevitable, hash tables have mechanisms of dealing with them, known as collision resolutions. Two of the most common strategies are open addressing and separate chaining. The cache-conscious collision resolution is another strategy that has been discussed in the past for string hash tables.
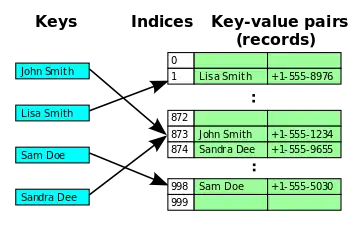
Open addressing
Cells in the hash table are assigned one of three states in this method – occupied, empty, or deleted. If a hash collision occurs, the table will be probed to move the record to an alternate cell that is stated as empty. There are different types of probing that take place when a hash collision happens and this method is implemented. Some types of probing are linear probing, double hashing, and quadratic probing.[12] Open Addressing is also known as closed hashing.[13]
Separate chaining
This strategy allows more than one record to be "chained" to the cells of a hash table. If two records are being directed to the same cell, both would go into that cell as a linked list. This efficiently prevents a hash collision from occurring since records with the same hash values can go into the same cell, but it has its disadvantages. Keeping track of so many lists is difficult and can cause whatever tool that is being used to become very slow.[12] Separate chaining is also known as open hashing.[14]
Cache-conscious collision resolution
Although much less used than the previous two, Askitis & Zobel (2005) has proposed the cache-conscious collision resolution method in 2005.[15] It is a similar idea to the separate chaining methods, although it does not technically involve the chained lists. In this case, instead of chained lists, the hash values are represented in a contiguous list of items. This is better suited for string hash tables and the use for numeric values is still unknown.[12]
See also
- Universal one-way hash function – type of universal hash function in cryptography proposed as an alternative to collision-resistant hash functions
- Cryptography – Practice and study of secure communication techniques
- Universal hashing – Technique for selecting hash functions
- Perfect hash function – Hash function without any collisions
References
- Thomas, Cormen (2009), Introduction to Algorithms, MIT Press, p. 253, ISBN 978-0-262-03384-8
- Stapko, Timothy (2008), "Embedded Security", Practical Embedded Security, Elsevier, pp. 83–114, doi:10.1016/b978-075068215-2.50006-9, ISBN 9780750682152, retrieved 2021-12-08
- Schneier, Bruce. "Cryptanalysis of MD5 and SHA: Time for a New Standard". Computerworld. Archived from the original on 2016-03-16. Retrieved 2016-04-20.
Much more than encryption algorithms, one-way hash functions are the workhorses of modern cryptography.
- Cybersecurity and Applied Mathematics. 2016. doi:10.1016/c2015-0-01807-x. ISBN 9780128044520.
- Soltanian, Mohammad Reza Khalifeh (10 November 2015). Theoretical and Experimental Methods for Defending Against DDoS Attacks. ISBN 978-0-12-805399-7. OCLC 1162249290.
- Conrad, Eric; Misenar, Seth; Feldman, Joshua (2016), "Domain 3: Security Engineering (Engineering and Management of Security)", CISSP Study Guide, Elsevier, pp. 103–217, doi:10.1016/b978-0-12-802437-9.00004-7, ISBN 9780128024379, retrieved 2021-12-08
- Rajaraman, A.; Ullman, J. (2010). "Mining of Massive Datasets, Ch. 3".
- Al-Kuwari, Saif; Davenport, James H.; Bradford, Russell J. (2011). Cryptographic Hash Functions: Recent Design Trends and Security Notions. Inscrypt '10.
- Schema, Mike (2012). Hacking Web Apps.
- Altheide, Cory; Carvey, Harlan (2011). Digital Forensics with Open Source Tools. Elsevier. pp. 1–8. doi:10.1016/b978-1-59749-586-8.00001-7. ISBN 9781597495868. Retrieved 2021-12-08.
- Linstedt, Daniel; Olschimke, Michael (2016). "Scalable Data Warehouse Architecture". Building a Scalable Data Warehouse with Data Vault 2.0. Elsevier. pp. 17–32. doi:10.1016/b978-0-12-802510-9.00002-7. ISBN 9780128025109. Retrieved 2021-12-07.
- Nimbe, Peter; Ofori Frimpong, Samuel; Opoku, Michael (2014-08-20). "An Efficient Strategy for Collision Resolution in Hash Tables". International Journal of Computer Applications. 99 (10): 35–41. Bibcode:2014IJCA...99j..35N. doi:10.5120/17411-7990. ISSN 0975-8887.
- Kline, Robert. "Closed Hashing". CSC241 Data Structures and Algorithms. West Chester University. Retrieved 2022-04-06.
- "Open hashing or separate chaining". Log22.
- Askitis, Nikolas; Zobel, Justin (2005). Consens, M.; Navarro, G. (eds.). Cache-Conscious Collision Resolution in String Hash Tables. International Symposium on String Processing and Information Retrieval. String Processing and Information Retrieval SPIRE 2005. Lecture Notes in Computer Science. Vol. 3772. Berlin, Heidelberg: Springer Berlin Heidelberg. pp. 91–102. doi:10.1007/11575832_11. ISBN 978-3-540-29740-6.
External links
| |||||||||||||||||||||||||||||