ID/LP grammar
ID/LP Grammars are a subset of Phrase Structure Grammars, differentiated from other formal grammars by distinguishing between immediate dominance (ID) and linear precedence (LP) constraints. Whereas traditional phrase structure rules incorporate dominance and precedence into a single rule, ID/LP Grammars maintains separate rule sets which need not be processed simultaneously. ID/LP Grammars are used in Computational Linguistics.
For example, a typical phrase structure rule such as , indicating that an S-node dominates an NP-node and a VP-node, and that the NP precedes the VP in the surface string. In ID/LP Grammars, this rule would only indicate dominance, and a linear precedence statement, such as , would also be given.


The idea first came to prominence as part of Generalized Phrase Structure Grammar;[1][2] the ID/LP Grammar approach is also used in head-driven phrase structure grammar,[3] lexical functional grammar, and other unification grammars.
Current work in the Minimalist Program also attempts to distinguish between dominance and ordering. For instance, recent papers by Noam Chomsky have proposed that, while hierarchical structure is the result of the syntactic structure-building operation Merge, linear order is not determined by this operation, and is simply the result of externalization (oral pronunciation, or, in the case of sign language, manual signing).[4][5][6]
Defining Dominance and Precedence
Immediate Dominance
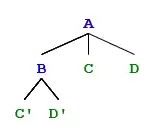
Immediate dominance is the asymmetrical relationship between the mother node of a parse tree and its daughters, where the mother node (to the left of the arrow) is said to immediately dominate the daughter nodes (those to the right of the arrow), but the daughters do not immediately dominate the mother. The daughter nodes are also dominated by any node that immediately dominates the mother node, however this is not an immediate dominance relation.
For example, the context free rule , shows that the node labelled A (mother node) immediately dominates nodes labelled B, C, and D, (daughter nodes) and nodes labelled B, C, and D can be immediately dominated by a node labelled A.

Linear Precedence
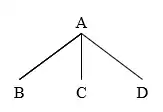
Linear precedence is the order relationship of sister nodes. LP constraints specify in what order sister nodes under the same mother can appear. Nodes that surface earlier in strings precede their sisters.[2] LP can be shown in phrase structure rules in the form to mean B precedes C precedes D, as shown in the tree below.
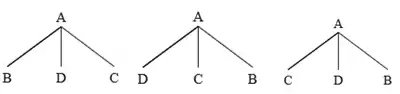
A rule that has ID constraints but not LP is written with commas between the daughter nodes, for example . Since there is no fixed order for the daughter nodes, it is possible that all three of the trees shown here are generated by this rule.

Alternatively, these relationships can be expressed through linear precedence statements, such as , to mean that anytime B and C are sisters, B must precede C.[2][7]

The principle of transitivity can be applied to LP relations which means that if and , then as well. LP relationships are asymmetric: if B precedes C, C can never precede B. An LP relationship where there can be no intervening nodes is called immediate precedence, while an LP where there can be intervening nodes (those derived from the principle of transitivity) are said to have weak precedence.[8]


Grammaticality in ID/LP Grammars
For a string to be grammatical in an ID/LP Grammar, it must belong to a local subtree that follows at least one ID rule and all LP statements of the grammar. If every possible string generated by the grammar fits this criteria, than it is an ID/LP Grammar. Additionally, for a grammar to be able to be written in ID/LP format, it must have the property of Exhaustive Constant Partial Ordering (ECPO): namely that at least part of the ID/LP relations in one rule is observed in all other rules.[2] For example, the set of rules:
(1)
(2)

does not have the ECPO property, because (1) says that C must always precede D, while (2) says that D must always precede C.
Advantages of ID/LP Grammars
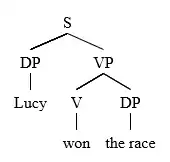
Since LP statements apply regardless of the ID rule context, they allow us to make generalizations across the whole grammar.[2][7] For example, given the LP statement , where V is the head of a VP, this means that in any clause in any sentence, V will always surface before its DP sister[7] in any context, as seen in the following examples.

Lucy won the race.
Ava told Sara to read a book.
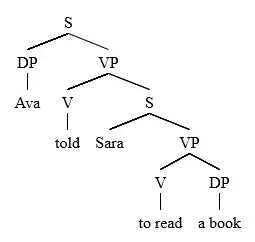
This can be generalized into a rule that holds across English, , where X is the head of any phrase and YP is its complement. Non-ID/LP Grammars are unable to make such generalizations across the whole grammar, and so must repeat ordering restrictions for each individual context.[7]

Separating LP requirements from ID rules also accounts for the phenomena of free word order in natural language. For example, in English it is possible to put adverbs before or after a verb and have both strings be grammatical.[7]
John suddenly screamed. John screamed suddenly.
A traditional PS rule would require two separate rules, but this can be described by the single ID/LP rule .This property of ID/LP Grammars enables easier cross linguistic generalizations by describing the language specific differences in constituent order with LP statements, separately from the ID rules that are similar across languages.[7]

Parsing in ID/LP Grammars
Two parsing algorithms used to parse ID/LP Grammars are the Earley Parser and Shieber's algorithm.[9]
Earley Parser in ID/LP Grammars
ID and LP rules impose constraints on sentence strings;[9] when dealing with large strings,[9] the constraints of these rules can cause the parsed string to become infinite, thus making parsing difficult. The Earley Parser solves this by altering[10] the format of an ID/LP Grammar into a Context Free Grammar (CFG), dividing the ID/LP Grammar into an Ordered Context Free Grammar (CFG) and Unordered Context Free Grammar (UCFG). This allows the two algorithms to parse strings more efficiently;[9] in particular, the Earley Parser uses a point tracking method that follows a linear path established by the LP rules.[9] In a CFG, LP rules do not allow repeated constituents in the parsed string, but an UCFG allows repeated constituents within the parsed strings.[9] If the ID/LP Grammar is converted to a UCFG then the LP rules do not dominate during the parsing process, however, it still follows the point tracking method.
Earley Parsing in CFG
After the ID/LP Grammar has been converted to the equivalent form within a CFG, the algorithm will analyze the string. Let stand for start and stand for the elements of the string and it also represents Syntactic Categories. The algorithm then analyzes the string and identifies the following:


- The original position of the dot; it usually begins with the left-most element of the string.
- The current position of the dot; this predicts the following element.
- The production of the completed string.[9]
(1)

(2) (is being predicted)


(3)

The parsed strings are then used together to form a Parse List[10] for example:

which the list will help determine whether the completed production element () is accepted within the main string. It does this by looking whether the produced individual strings are found in the Parse List. If one or all of the individual strings are not found within the Parse List, then the overall string will fail. If one or all of the individual strings are found in the Parse List, then the overall string will be accepted.[10]

Earley Parsing in UCFG
The UCFG is the appropriate equivalent to convert the ID/LP Grammar into in order to use the Earley Parser.[9] This algorithm read strings similarly to how it parses CFG, however, in this case the order of elements is not enforced; resulting in lack of LP rule enforcement. This allows some elements to be repeated within the parsed strings and the UCFG accepts empty multi-sets along with filled multi-sets within its strings.[9] For example:
- The origin position of the dot; it is between the empty set and the filled set.
- The current position of the dot which predicts the following set; the element that the dot passed will move into the empty set.
- The production of the completed string. In this case, the position of the two sets in the origin position will swap; the filled set is on the left edge and the empty set is on the right edge.[9]
(1)

(2) (are being predicted)


(3)

When parsing a string that contains a number of unordered elements, the Earley Parser treats it as a Permutation, Y!, and generates each string individually instead of using one string to represent the repeated parsed strings.[9] Whenever the dot moves over one element, the algorithm begins to generate parsed strings of the elements on the right edge in random positions until there are no more elements in the right edge set. Let X0 represent the original string and X1 as the first parsed string; for example:
![{\displaystyle \mathrm {X} _{0}:[\mathrm {X} \longrightarrow \{\}\cdot \{t,v,w,z\},0]}](../../I/999c405f60d02257cec0f65e8316183f0eba3a64.svg)
![{\displaystyle \mathrm {X} _{1}:[\mathrm {X} \longrightarrow \{t\}\cdot \{v,w,z\},0]}](../../I/42d65c4a57770fc4b70e9df1289f8db857432d9c.svg)
string X1 will produce, 3! = 6, different parsed strings of the right edge set:
(1) (4)
![{\displaystyle [\mathrm {X} \longrightarrow t.vwz,0]}](../../I/7c66d2b655fad0954b865e30ccb0a3fcc9a9097f.svg)
![{\displaystyle [\mathrm {X} \longrightarrow t.zvw,0]}](../../I/deeeb2a25aa7d7ac6b7788637e339c9fca168763.svg)
(2) (5)
![{\displaystyle [\mathrm {X} \longrightarrow t.vzw,0]}](../../I/ee68b634544148645602bb83487862f772eca48f.svg)
![{\displaystyle [\mathrm {X} \longrightarrow t.wvz,0]}](../../I/1ec9c119269d3840c15f1c4a66151a5e02666ec9.svg)
(3) (6)
![{\displaystyle [\mathrm {X} \longrightarrow t.zwv,0]}](../../I/bbd30b7ffcea4e7e3a54126e9d0184e38dbaa421.svg)
![{\displaystyle [\mathrm {X} \longrightarrow t.wzv,0]}](../../I/747b9b9dbf1d282351acee98511668960aefd21d.svg)
The Earley Parser applies each string to the individual rules of a grammar[9] and this results in very large sets.The large sets is partly resulted in the conversion of ID/LP Grammar into an equivalent grammar, however, parsing the overall ID/LP Grammar is difficult to begin with.[9]
Shieber's Algorithm
The foundation of Shieber's Algorithm[9] is based on the Earley Parser for CFG,[10] however, it does not require the ID/LP Grammar to be converted into a different grammar[10] in order to be parsed. ID rules can be parsed in a separate form, S →ID {V, NP, S}, from the LP rules, V < S.[10] Shieber compared parsing of a CFG to an ordered ID/LP Grammar string and Barton compared the parsing of a UCFG to an unordered ID/LP Grammar string.
Direct Parsing of an Ordered ID/LP Grammar
Parsing an ID/LP Grammar, directly, generates a set list that will determine whether the production of the string will be accepted or fail. The algorithm follows 6 Steps (the symbols used can also represents the Syntactic Categories):
- For all of the ID rules, add to the initial item in the parse list, .[10]
- If all of the elements in , , and the elements, , of does not allow Z to be preceded by ,, and Z is not an element of , ; then the following string, can be added to .
- If all items, , are elements of , then , and and all of then the next item can be added to this list, .
- This step will build the set list, , more. Every item, , that is an element of and where , and then the following item is added, , to .
- If items, , are elements of and items, , are elements of where , and ; the string, , is added to .
- If the items, , is an element of where , and ; the string, , is added to .
![{\displaystyle [S,\mathrm {T} ,\beta ,0]}](../../I/ab8c6117dd1e5a820e874cbca03efd60d1c4085f.svg)

![{\displaystyle [\mathrm {Z} ,\lambda ,\theta ,0]}](../../I/36093b39724c82c18b63c1e6ef6f9f759b16fa58.svg)
![{\displaystyle [\mathrm {A} ,\alpha ,\{Z\}\cup \beta ,0]}](../../I/ba08939ce70f3f831f1b7da30dbdd8a65bc6d0e3.svg)


![{\displaystyle [\mathrm {A} ,\alpha Z,\beta ,0]}](../../I/8a299b56735dceafc726a12a747d647b36349446.svg)

![{\displaystyle [Z,T,\lambda ,0]}](../../I/d032a702b7a4a0e235026340d7277f7869c42e7f.svg)

![{\displaystyle [A,\alpha ,\{q\}\cup \beta ,i]}](../../I/67a6cbd6d3e18e5255f0869502fcf01fa8e0eb2d.svg)




![{\displaystyle [A,\alpha q,\beta ,i]}](../../I/1b28aa563a2883780d08f5e057442b721677b433.svg)
![{\displaystyle [Z,\lambda ,\theta ,i]}](../../I/44c28f66f861565e20a67c3a7fcd32152c0ff51e.svg)
![{\displaystyle [A,\alpha \{Z\}\cup \beta ,k]}](../../I/e87ee9ed6d6d5767f4f339871123d5ad31d94f3f.svg)

![{\displaystyle [A,\alpha Z,\beta ,k]}](../../I/47978e333cf1e7867b7e9a498ddf6a2227007f2e.svg)
![{\displaystyle [A,\alpha ,\{Z\}\cup \beta ,i]}](../../I/8a4bbfd36cdae9ad01f6256aeef753c55c82b9a4.svg)
![{\displaystyle [Z,T,\lambda ,n]}](../../I/42f86f143848ce9486ca8ceb1a03677c9ab1026f.svg)
Steps 2-3 are repeated exhaustively[10] until no more new items can be added and then continue on to Step 4. Steps 5-6 are also exhaustively repeated[10] until no further new items can be added to the set list. The string will be accepted if a string behaves or resembles the production, is an element of .[10] For example:
![{\displaystyle [S,\alpha ,\theta ,0]}](../../I/8e6362ca84a93ea615d455a13210dd701c1c4508.svg)




| Set Lists | Items |
|---|---|
|
| |
|
| |
|
| |
|
|
![{\displaystyle [S,T,\{C,D,F\},0],}](../../I/97e8060f30ab7ca6e55817a59deb38112b72a854.svg)
![{\displaystyle [C,T,\{c\},0],}](../../I/18690765bb4303dbb178a17078cd2e4894c0ea27.svg)
![{\displaystyle [F,T,\{f\},0]}](../../I/589c48e8ceef990e2d6fa1f4c722623cb96727a2.svg)

![{\displaystyle [C,c,\emptyset ,0],}](../../I/f5b028bee6384fb695cb9c812cb755798f3d349a.svg)
![{\displaystyle [S,C,\{D,F\},0],}](../../I/9d6f8690e1cbd443b7e5658eb74e1bae26a17c19.svg)
![{\displaystyle [D,T,\{d\},1],}](../../I/be4e218c85cc1fbeacbb4a9c669df29ab627c6c4.svg)
![{\displaystyle [F,T,\{f\},1]}](../../I/b15858d831d23b409b1b9f7599c0a09f42275912.svg)

![{\displaystyle [F,f,\emptyset ,1],}](../../I/a7530d47d46c576f69f15bb90c799adf664444ac.svg)
![{\displaystyle [S,CF,\{D\},0],}](../../I/5136538387f45326f16b153cf0726478e49d0956.svg)
![{\displaystyle [D,T,\{d\},2]}](../../I/8bb3aba8317a6b29e481197cc3d8dd86ec5d8de1.svg)

![{\displaystyle [D,d,\emptyset ,2],}](../../I/ccc42538f31413f1f6c400c217edee1a1ce36e98.svg)
![{\displaystyle [S,CDF,\emptyset ,0]}](../../I/f4dee533569f2d4d17dd4532a4a469535fe70741.svg)
The complete production of is accepted and produces the following production string: .[10]

![{\displaystyle [S,CDF,\emptyset ,0],}](../../I/dd518da0300fda376d9a601fba5dbbd2ffcd3a0a.svg)
![{\displaystyle [_{S}[_{C}c][_{D}d][_{F}f]]}](../../I/d0a116ae310ba6186dc76369a45611e9b8f53971.svg)
Direct Parsing of an Unordered ID/LP Grammar
The Unordered ID/LP Grammar follow the above, 6 step algorithm, in order to parse the strings. The noticeable difference is in the productions of each set list; there is one string that represents the many individual strings within one list.[9] The table below shows the set list of Table 1.0, in an unordered grammar:
| Set List | Items |
|---|---|
![{\displaystyle [S,T,C\cdot d,f,\emptyset ,0]}](../../I/e3afb806e4f5b0e7baf268edc4befd6415495555.svg)
![{\displaystyle [S,T\cdot c,d,f,\emptyset ,0]}](../../I/2dd9806f1cc34377067ca343ccce95c56c4fa11c.svg)
![{\displaystyle [S,T,C,d\cdot F,\emptyset ,0]}](../../I/261f144061b8362ecc3a3f48714deb369a3b0bcd.svg)
![{\displaystyle [S,T,C,D,F\cdot \emptyset ,0]}](../../I/fb9d9d1a6686eaec190adaed1be0baec40e349a5.svg)
The complete production string, results in a similar string as the ordered ID/LP Grammar; however, the order of the items within the string is not enforced. The final string is accepted as it matches the original string's elements.
![{\displaystyle [S,T,C,D,F\cdot \emptyset ,0],}](../../I/6556c6966673b75a255651ac4ee43c0f9c007d25.svg)
Notice how the Unordered version of ID/LP Grammar contains mush less strings than the UCFG; Shieber's Algorithm use one string to represent the multiple different strings for repeated elements. Both algorithms can parse Ordered Grammars equally, however, Shieber's Algorithm seems to be more efficient[9] when parsing an Unordered Grammar.
References
- Gazdar, Gerald; Pullum, Geoffrey K. (1981). "Subcategorization, constituent order, and the notion 'head'". In M. Moortgat; H.v.d. Hulst; T. Hoekstra (eds.). The scope of lexical rules. pp. 107–124. ISBN 9070176521.
- Gazdar, Gerald; Ewan H. Klein; Geoffrey K. Pullum; Ivan A. Sag (1985). Generalized Phrase Structure Grammar. Oxford: Blackwell, and Cambridge, MA: Harvard University Press. ISBN 0-674-34455-3.
- Daniels, Mike; Meurers, Detmar (2004). "GIDLP: A grammar format for linearization-based HPSG" (PDF). Proceedings of the Eleventh International Conference on Head-Driven Phrase Structure Grammar. doi:10.21248/hpsg.2004.5. S2CID 17009554.
- Chomsky, Noam (2007). "Biolinguistic explorations: Design, development, evolution". International Journal of Philosophical Studies. 15 (1): 1–21. doi:10.1080/09672550601143078. S2CID 144566546.
- Chomsky, Noam (2011). "Language and other cognitive systems. What is special about language?". Language Learning and Development. 7 (4): 263–278. doi:10.1080/15475441.2011.584041. S2CID 122866773.
- Berwick, Robert C.; et al. (2011). "Poverty of the stimulus revisited". Cognitive Science. 35 (7): 1207–1242. doi:10.1111/j.1551-6709.2011.01189.x. PMID 21824178.
- Bennett, Paul (1995). A Course in Generalized Phrase Structure Grammar. London: UCL Press. ISBN 1-85728-217-5.
- Daniels, M. (2005). Generalized ID/LP grammar: a formalism for parsing linearization-based HPSG grammars. (Electronic Thesis or Dissertation). Retrieved from https://etd.ohiolink.edu/
- Barton, Jr., G. Edward (1985). "On the Complexity of ID/LP Parsing". Computational Linguistics. 11 (4): 205–218 – via Association for Computational Linguistics.
- Shieber, Stuart M. (1983). "Direct Parsing of ID/LP Grammars". Linguistics and Philosophy. 7 (2): 1–30 – via SRI International.