Statistical dispersion
In statistics, dispersion (also called variability, scatter, or spread) is the extent to which a distribution is stretched or squeezed.[1] Common examples of measures of statistical dispersion are the variance, standard deviation, and interquartile range. For instance, when the variance of data in a set is large, the data is widely scattered. On the other hand, when the variance is small, the data in the set is clustered.
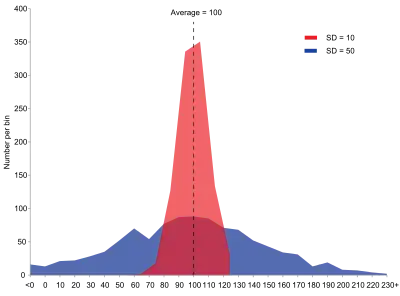
Dispersion is contrasted with location or central tendency, and together they are the most used properties of distributions.
Measures of statistical dispersion
A measure of statistical dispersion is a nonnegative real number that is zero if all the data are the same and increases as the data become more diverse.
Most measures of dispersion have the same units as the quantity being measured. In other words, if the measurements are in metres or seconds, so is the measure of dispersion. Examples of dispersion measures include:
- Standard deviation
- Interquartile range (IQR)
- Range
- Mean absolute difference (also known as Gini mean absolute difference)
- Median absolute deviation (MAD)
- Average absolute deviation (or simply called average deviation)
- Distance standard deviation
These are frequently used (together with scale factors) as estimators of scale parameters, in which capacity they are called estimates of scale. Robust measures of scale are those unaffected by a small number of outliers, and include the IQR and MAD.
All the above measures of statistical dispersion have the useful property that they are location-invariant and linear in scale. This means that if a random variable has a dispersion of then a linear transformation for real and should have dispersion , where is the absolute value of , that is, ignores a preceding negative sign .








Other measures of dispersion are dimensionless. In other words, they have no units even if the variable itself has units. These include:
- Coefficient of variation
- Quartile coefficient of dispersion
- Relative mean difference, equal to twice the Gini coefficient
- Entropy: While the entropy of a discrete variable is location-invariant and scale-independent, and therefore not a measure of dispersion in the above sense, the entropy of a continuous variable is location invariant and additive in scale: If is the entropy of a continuous variable and , then .




There are other measures of dispersion:
- Variance (the square of the standard deviation) – location-invariant but not linear in scale.
- Variance-to-mean ratio – mostly used for count data when the term coefficient of dispersion is used and when this ratio is dimensionless, as count data are themselves dimensionless, not otherwise.
Some measures of dispersion have specialized purposes. The Allan variance can be used for applications where the noise disrupts convergence.[2] The Hadamard variance can be used to counteract linear frequency drift sensitivity.[3]
For categorical variables, it is less common to measure dispersion by a single number; see qualitative variation. One measure that does so is the discrete entropy.
Sources
In the physical sciences, such variability may result from random measurement errors: instrument measurements are often not perfectly precise, i.e., reproducible, and there is additional inter-rater variability in interpreting and reporting the measured results. One may assume that the quantity being measured is stable, and that the variation between measurements is due to observational error. A system of a large number of particles is characterized by the mean values of a relatively few number of macroscopic quantities such as temperature, energy, and density. The standard deviation is an important measure in fluctuation theory, which explains many physical phenomena, including why the sky is blue.[4]
In the biological sciences, the quantity being measured is seldom unchanging and stable, and the variation observed might additionally be intrinsic to the phenomenon: It may be due to inter-individual variability, that is, distinct members of a population differing from each other. Also, it may be due to intra-individual variability, that is, one and the same subject differing in tests taken at different times or in other differing conditions. Such types of variability are also seen in the arena of manufactured products; even there, the meticulous scientist finds variation.
A partial ordering of dispersion
A mean-preserving spread (MPS) is a change from one probability distribution A to another probability distribution B, where B is formed by spreading out one or more portions of A's probability density function while leaving the mean (the expected value) unchanged.[5] The concept of a mean-preserving spread provides a partial ordering of probability distributions according to their dispersions: of two probability distributions, one may be ranked as having more dispersion than the other, or alternatively neither may be ranked as having more dispersion.
See also
References
- NIST/SEMATECH e-Handbook of Statistical Methods. "1.3.6.4. Location and Scale Parameters". www.itl.nist.gov. U.S. Department of Commerce.
- "Allan Variance -- Overview by David W. Allan". www.allanstime.com. Retrieved 2021-09-16.
- "Hadamard Variance". www.wriley.com. Retrieved 2021-09-16.
- McQuarrie, Donald A. (1976). Statistical Mechanics. NY: Harper & Row. ISBN 0-06-044366-9.
- Rothschild, Michael; Stiglitz, Joseph (1970). "Increasing risk I: A definition". Journal of Economic Theory. 2 (3): 225–243. doi:10.1016/0022-0531(70)90038-4.