k-medoids
The k-medoids problem is a clustering problem similar to k-means. The name was coined by Leonard Kaufman and Peter J. Rousseeuw with their PAM (Partitioning Around Medoids) algorithm.[1] Both the k-means and k-medoids algorithms are partitional (breaking the dataset up into groups) and attempt to minimize the distance between points labeled to be in a cluster and a point designated as the center of that cluster. In contrast to the k-means algorithm, k-medoids chooses actual data points as centers (medoids or exemplars), and thereby allows for greater interpretability of the cluster centers than in k-means, where the center of a cluster is not necessarily one of the input data points (it is the average between the points in the cluster). Furthermore, k-medoids can be used with arbitrary dissimilarity measures, whereas k-means generally requires Euclidean distance for efficient solutions. Because k-medoids minimizes a sum of pairwise dissimilarities instead of a sum of squared Euclidean distances, it is more robust to noise and outliers than k-means.
k-medoids is a classical partitioning technique of clustering that splits the data set of n objects into k clusters, where the number k of clusters assumed known a priori (which implies that the programmer must specify k before the execution of a k-medoids algorithm). The "goodness" of the given value of k can be assessed with methods such as the silhouette method.
The medoid of a cluster is defined as the object in the cluster whose average dissimilarity to all the objects in the cluster is minimal, that is, it is a most centrally located point in the cluster.
Algorithms
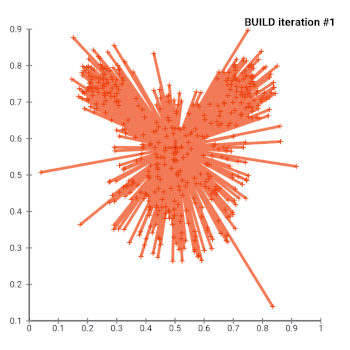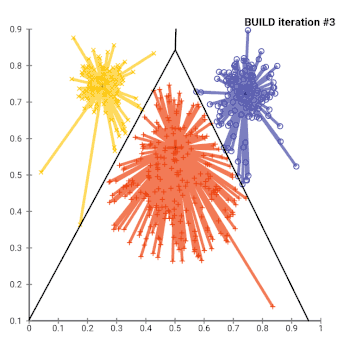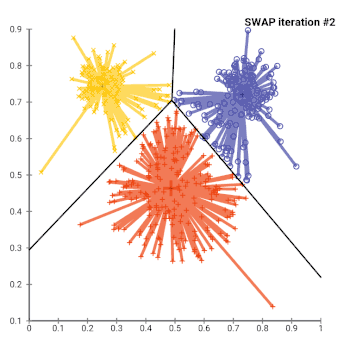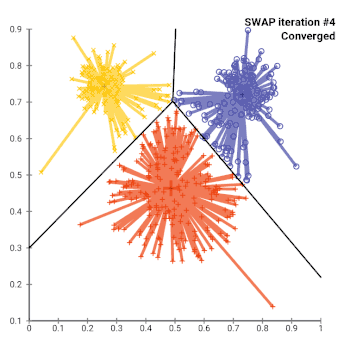
In general, the k-medoids problem is NP-hard to solve exactly. As such, many heuristic solutions exist.
Partitioning Around Medoids (PAM)
PAM[1] uses a greedy search which may not find the optimum solution, but it is faster than exhaustive search. It works as follows:
- (BUILD) Initialize: greedily select k of the n data points as the medoids to minimize the cost
- Associate each data point to the closest medoid.
- (SWAP) While the cost of the configuration decreases:
- For each medoid m, and for each non-medoid data point o:
- Consider the swap of m and o, and compute the cost change
- If the cost change is the current best, remember this m and o combination
- Perform the best swap of and , if it decreases the cost function. Otherwise, the algorithm terminates.
- For each medoid m, and for each non-medoid data point o:


The runtime complexity of the original PAM algorithm per iteration of (3) is , by only computing the change in cost. A naive implementation recomputing the entire cost function every time will be in . This runtime can be further reduced to , by splitting the cost change into three parts such that computations can be shared or avoided (FastPAM). The runtime can further be reduced by eagerly performing swaps (FasterPAM),[2] at which point a random initialization becomes a viable alternative to BUILD.



Alternating Optimization
Algorithms other than PAM have also been suggested in the literature, including the following Voronoi iteration method known as the "Alternating" heuristic in literature, as it alternates between two optimization steps:[3][4][5]
- Select initial medoids randomly
- Iterate while the cost decreases:
- In each cluster, make the point that minimizes the sum of distances within the cluster the medoid
- Reassign each point to the cluster defined by the closest medoid determined in the previous step
k-means-style Voronoi iteration tends to produce worse results, and exhibit "erratic behavior".[6]: 957 Because it does not allow re-assigning points to other clusters while updating means it only explores a smaller search space. It can be shown that even in simple cases this heuristic finds inferior solutions the swap based methods can solve.[2]
Hierarchical Clustering
Multiple variants of hierarchical clustering with a "medoid linkage" have been proposed. The Minimum Sum linkage criterion[7] directly uses the objective of medoids, but the Minimum Sum Increase linkage was shown to produce better results (similar to how Ward linkage uses the increase in squared error). Earlier approaches simply used the distance of the cluster medoids of the previous medoids as linkage measure,[8][9] but which tends to result in worse solutions, as the distance of two medoids does not ensure there exists a good medoid for the combination. These approaches have a run time complexity of , and when the dendrogram is cut at a particular number of clusters k, the results will typically be worse than the results found by PAM.[7] Hence these methods are primarily of interest when a hierarchical tree structure is desired.

Other Algorithms
Other approximate algorithms such as CLARA and CLARANS trade quality for runtime. CLARA applies PAM on multiple subsamples, keeping the best result. CLARANS works on the entire data set, but only explores a subset of the possible swaps of medoids and non-medoids using sampling. BanditPAM uses the concept of multi-armed bandits to choose candidate swaps instead of uniform sampling as in CLARANS.[10]
Software
- ELKI includes several k-medoid variants, including a Voronoi-iteration k-medoids, the original PAM algorithm, Reynolds' improvements, and the O(n²) FastPAM and FasterPAM algorithms, CLARA, CLARANS, FastCLARA and FastCLARANS.
- Julia contains a k-medoid implementation of the k-means style algorithm (fast, but much worse result quality) in the JuliaStats/Clustering.jl package.
- KNIME includes a k-medoid implementation supporting a variety of efficient matrix distance measures, as well as a number of native (and integrated third-party) k-means implementations
- Python contains FasterPAM and other variants in the "kmedoids" package, additional implementations can be found in many other packages
- R contains PAM in the "cluster" package, including the FasterPAM improvements via the options
variant = "faster"andmedoids = "random". There also exists a "fastkmedoids" package. - RapidMiner has an operator named KMedoids, but it does not implement any of above KMedoids algorithms. Instead, it is a k-means variant, that substitutes the mean with the closest data point (which is not the medoid), which combines the drawbacks of k-means (limited to coordinate data) with the additional cost of finding the nearest point to the mean.
- Rust has a "kmedoids" crate that also includes the FasterPAM variant.
- MATLAB implements PAM, CLARA, and two other algorithms to solve the k-medoid clustering problem.
References
- Kaufman, Leonard; Rousseeuw, Peter J. (1990-03-08), "Partitioning Around Medoids (Program PAM)", Wiley Series in Probability and Statistics, Hoboken, NJ, USA: John Wiley & Sons, Inc., pp. 68–125, doi:10.1002/9780470316801.ch2, ISBN 978-0-470-31680-1, retrieved 2021-06-13
- Schubert, Erich; Rousseeuw, Peter J. (2021). "Fast and eager k -medoids clustering: O(k) runtime improvement of the PAM, CLARA, and CLARANS algorithms". Information Systems. 101: 101804. arXiv:2008.05171. doi:10.1016/j.is.2021.101804. S2CID 221103804.
- Maranzana, F. E. (1963). "On the location of supply points to minimize transportation costs". IBM Systems Journal. 2 (2): 129–135. doi:10.1147/sj.22.0129.
- T. Hastie, R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Springer (2001), 468–469.
- Park, Hae-Sang; Jun, Chi-Hyuck (2009). "A simple and fast algorithm for K-medoids clustering". Expert Systems with Applications. 36 (2): 3336–3341. doi:10.1016/j.eswa.2008.01.039.
- Teitz, Michael B.; Bart, Polly (1968-10-01). "Heuristic Methods for Estimating the Generalized Vertex Median of a Weighted Graph". Operations Research. 16 (5): 955–961. doi:10.1287/opre.16.5.955. ISSN 0030-364X.
- Schubert, Erich (2021). HACAM: Hierarchical Agglomerative Clustering Around Medoids – and its Limitations (PDF). LWDA’21: Lernen, Wissen, Daten, Analysen September 01–03, 2021, Munich, Germany. pp. 191–204 – via CEUR-WS.
- Miyamoto, Sadaaki; Kaizu, Yousuke; Endo, Yasunori (2016). Hierarchical and Non-Hierarchical Medoid Clustering Using Asymmetric Similarity Measures. 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems (SCIS) and 17th International Symposium on Advanced Intelligent Systems (ISIS). pp. 400–403. doi:10.1109/SCIS-ISIS.2016.0091.
- Herr, Dominik; Han, Qi; Lohmann, Steffen; Ertl, Thomas (2016). Visual Clutter Reduction through Hierarchy-based Projection of High-dimensional Labeled Data (PDF). Graphics Interface. Graphics Interface. doi:10.20380/gi2016.14. Retrieved 2022-11-04.
- Tiwari, Mo; Zhang, Martin J.; Mayclin, James; Thrun, Sebastian; Piech, Chris; Shomorony, Ilan (2020). "BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits". Advances in Neural Information Processing Systems. 33.