Exploratory factor analysis
In multivariate statistics, exploratory factor analysis (EFA) is a statistical method used to uncover the underlying structure of a relatively large set of variables. EFA is a technique within factor analysis whose overarching goal is to identify the underlying relationships between measured variables.[1] It is commonly used by researchers when developing a scale (a scale is a collection of questions used to measure a particular research topic) and serves to identify a set of latent constructs underlying a battery of measured variables.[2] It should be used when the researcher has no a priori hypothesis about factors or patterns of measured variables.[3] Measured variables are any one of several attributes of people that may be observed and measured. Examples of measured variables could be the physical height, weight, and pulse rate of a human being. Usually, researchers would have a large number of measured variables, which are assumed to be related to a smaller number of "unobserved" factors. Researchers must carefully consider the number of measured variables to include in the analysis.[2] EFA procedures are more accurate when each factor is represented by multiple measured variables in the analysis.
.png.webp)
EFA is based on the common factor model.[1] In this model, manifest variables are expressed as a function of common factors, unique factors, and errors of measurement. Each unique factor influences only one manifest variable, and does not explain correlations between manifest variables. Common factors influence more than one manifest variable and "factor loadings" are measures of the influence of a common factor on a manifest variable.[1] For the EFA procedure, we are more interested in identifying the common factors and the related manifest variables.
EFA assumes that any indicator/measured variable may be associated with any factor. When developing a scale, researchers should use EFA first before moving on to confirmatory factor analysis (CFA).[4] EFA is essential to determine underlying factors/constructs for a set of measured variables; while CFA allows the researcher to test the hypothesis that a relationship between the observed variables and their underlying latent factor(s)/construct(s) exists.[5] EFA requires the researcher to make a number of important decisions about how to conduct the analysis because there is no one set method.
Fitting procedures
Fitting procedures are used to estimate the factor loadings and unique variances of the model (Factor loadings are the regression coefficients between items and factors and measure the influence of a common factor on a measured variable). There are several factor analysis fitting methods to choose from, however there is little information on all of their strengths and weaknesses and many don't even have an exact name that is used consistently. Principal axis factoring (PAF) and maximum likelihood (ML) are two extraction methods that are generally recommended. In general, ML or PAF give the best results, depending on whether data are normally-distributed or if the assumption of normality has been violated.[2]
Maximum likelihood (ML)
The maximum likelihood method has many advantages in that it allows researchers to compute of a wide range of indexes of the goodness of fit of the model, it allows researchers to test the statistical significance of factor loadings, calculate correlations among factors and compute confidence intervals for these parameters.[6] ML is the best choice when data are normally distributed because “it allows for the computation of a wide range of indexes of the goodness of fit of the model [and] permits statistical significance testing of factor loadings and correlations among factors and the computation of confidence intervals”.[2]
Principal axis factoring (PAF)
Called “principal” axis factoring because the first factor accounts for as much common variance as possible, then the second factor next most variance, and so on. PAF is a descriptive procedure so it is best to use when the focus is just on your sample and you do not plan to generalize the results beyond your sample. A downside of PAF is that it provides a limited range of goodness-of-fit indexes compared to ML and does not allow for the computation of confidence intervals and significance tests.
Selecting the appropriate number of factors
When selecting how many factors to include in a model, researchers must try to balance parsimony (a model with relatively few factors) and plausibility (that there are enough factors to adequately account for correlations among measured variables).[7]
Overfactoring occurs when too many factors are included in a model and may lead researchers to put forward constructs with little theoretical value.
Underfactoring occurs when too few factors are included in a model. If not enough factors are included in a model, there is likely to be substantial error. Measured variables that load onto a factor not included in the model can falsely load on factors that are included, altering true factor loadings. This can result in rotated solutions in which two factors are combined into a single factor, obscuring the true factor structure.
There are a number of procedures designed to determine the optimal number of factors to retain in EFA. These include Kaiser's (1960) eigenvalue-greater-than-one rule (or K1 rule),[8] Cattell's (1966) scree plot,[9] Revelle and Rocklin's (1979) very simple structure criterion,[10] model comparison techniques,[11] Raiche, Roipel, and Blais's (2006) acceleration factor and optimal coordinates,[12] Velicer's (1976) minimum average partial,[13] Horn's (1965) parallel analysis, and Ruscio and Roche's (2012) comparison data.[14] Recent simulation studies assessing the robustness of such techniques suggest that the latter five can better assist practitioners to judiciously model data.[14] These five modern techniques are now easily accessible through integrated use of IBM SPSS Statistics software (SPSS) and R (R Development Core Team, 2011). See Courtney (2013)[15] for guidance on how to carry out these procedures for continuous, ordinal, and heterogenous (continuous and ordinal) data.
With the exception of Revelle and Rocklin's (1979) very simple structure criterion, model comparison techniques, and Velicer's (1976) minimum average partial, all other procedures rely on the analysis of eigenvalues. The eigenvalue of a factor represents the amount of variance of the variables accounted for by that factor. The lower the eigenvalue, the less that factor contributes to explaining the variance of the variables.[1]
A short description of each of the nine procedures mentioned above is provided below.
Kaiser's (1960) eigenvalue-greater-than-one rule (K1 or Kaiser criterion)
Compute the eigenvalues for the correlation matrix and determine how many of these eigenvalues are greater than 1. This number is the number of factors to include in the model. A disadvantage of this procedure is that it is quite arbitrary (e.g., an eigenvalue of 1.01 is included whereas an eigenvalue of .99 is not). This procedure often leads to overfactoring and sometimes underfactoring. Therefore, this procedure should not be used.[2] A variation of the K1 criterion has been created to lessen the severity of the criterion's problems where a researcher calculates confidence intervals for each eigenvalue and retains only factors which have the entire confidence interval greater than 1.0.[16][17]
Cattell's (1966) scree plot
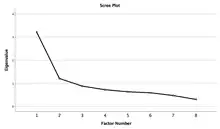
Compute the eigenvalues for the correlation matrix and plot the values from largest to smallest. Examine the graph to determine the last substantial drop in the magnitude of eigenvalues. The number of plotted points before the last drop is the number of factors to include in the model.[9] This method has been criticized because of its subjective nature (i.e., there is no clear objective definition of what constitutes a substantial drop).[18] As this procedure is subjective, Courtney (2013) does not recommend it.[15]
Revelle and Rocklin (1979) very simple structure
Revelle and Rocklin's (1979) VSS criterion operationalizes this tendency by assessing the extent to which the original correlation matrix is reproduced by a simplified pattern matrix, in which only the highest loading for each item is retained, all other loadings being set to zero. The VSS criterion for assessing the extent of replication can take values between 0 and 1, and is a measure of the goodness-of-fit of the factor solution. The VSS criterion is gathered from factor solutions that involve one factor (k = 1) to a user-specified theoretical maximum number of factors. Thereafter, the factor solution that provides the highest VSS criterion determines the optimal number of interpretable factors in the matrix. In an attempt to accommodate datasets where items covary with more than one factor (i.e., more factorially complex data), the criterion can also be carried out with simplified pattern matrices in which the highest two loadings are retained, with the rest set to zero (Max VSS complexity 2). Courtney also does not recommend VSS because of lack of robust simulation research concerning the performance of the VSS criterion.[15]
Model comparison techniques
Choose the best model from a series of models that differ in complexity. Researchers use goodness-of-fit measures to fit models beginning with a model with zero factors and gradually increase the number of factors. The goal is to ultimately choose a model that explains the data significantly better than simpler models (with fewer factors) and explains the data as well as more complex models (with more factors).
There are different methods that can be used to assess model fit:[2]
- Likelihood ratio statistic:[19] Used to test the null hypothesis that a model has perfect model fit. It should be applied to models with an increasing number of factors until the result is nonsignificant, indicating that the model is not rejected as good model fit of the population. This statistic should be used with a large sample size and normally distributed data. There are some drawbacks to the likelihood ratio test. First, when there is a large sample size, even small discrepancies between the model and the data result in model rejection.[20][21][22] When there is a small sample size, even large discrepancies between the model and data may not be significant, which leads to underfactoring.[20] Another disadvantage of the likelihood ratio test is that the null hypothesis of perfect fit is an unrealistic standard.[23][24]
- Root mean square error of approximation (RMSEA) fit index: RMSEA is an estimate of the discrepancy between the model and the data per degree of freedom for the model. Values less that .05 constitute good fit, values between 0.05 and 0.08 constitute acceptable fit, a values between 0.08 and 0.10 constitute marginal fit and values greater than 0.10 indicate poor fit .[24][25] An advantage of the RMSEA fit index is that it provides confidence intervals which allow researchers to compare a series of models with varying numbers of factors.
- Information Criteria: Information criteria such as Akaike Information Criterion (AIC) or the Bayesian Information Criterion (BIC) [26] can be used to trade-off model fit with model complexity and select an optimal number of factors.
- Out-of-sample Prediction Errors: Using the connection between model-implied covariance matrices and standardized regression weights, the number of factors can be selected using out-of-sample prediction errors.[27]
Optimal Coordinate and Acceleration Factor
In an attempt to overcome the subjective weakness of Cattell's (1966) scree test,[9][28] presented two families of non-graphical solutions. The first method, coined the optimal coordinate (OC), attempts to determine the location of the scree by measuring the gradients associated with eigenvalues and their preceding coordinates. The second method, coined the acceleration factor (AF), pertains to a numerical solution for determining the coordinate where the slope of the curve changes most abruptly. Both of these methods have out-performed the K1 method in simulation.[14] In the Ruscio and Roche study (2012),[14] the OC method was correct 74.03% of the time rivaling the PA technique (76.42%). The AF method was correct 45.91% of the time with a tendency toward under-estimation. Both the OC and AF methods, generated with the use of Pearson correlation coefficients, were reviewed in Ruscio and Roche's (2012) simulation study. Results suggested that both techniques performed quite well under ordinal response categories of two to seven (C = 2-7) and quasi-continuous (C = 10 or 20) data situations. Given the accuracy of these procedures under simulation, they are highly recommended for determining the number of factors to retain in EFA. It is one of Courtney's 5 recommended modern procedures.[15]
Velicer's Minimum Average Partial test (MAP)
Velicer's (1976) MAP test[13] “involves a complete principal components analysis followed by the examination of a series of matrices of partial correlations” (p. 397). The squared correlation for Step “0” (see Figure 4) is the average squared off-diagonal correlation for the unpartialed correlation matrix. On Step 1, the first principal component and its associated items are partialed out. Thereafter, the average squared off-diagonal correlation for the subsequent correlation matrix is computed for Step 1. On Step 2, the first two principal components are partialed out and the resultant average squared off-diagonal correlation is again computed. The computations are carried out for k minus one steps (k representing the total number of variables in the matrix). Finally, the average squared correlations for all steps are lined up and the step number that resulted in the lowest average squared partial correlation determines the number of components or factors to retain (Velicer, 1976). By this method, components are maintained as long as the variance in the correlation matrix represents systematic variance, as opposed to residual or error variance. Although methodologically akin to principal components analysis, the MAP technique has been shown to perform quite well in determining the number of factors to retain in multiple simulation studies.[14][29] However, in a very small minority of cases MAP may grossly overestimate the number of factors in a dataset for unknown reasons.[30] This procedure is made available through SPSS's user interface. See Courtney (2013)[15] for guidance. This is one of his five recommended modern procedures.
Parallel analysis
To carry out the PA test, users compute the eigenvalues for the correlation matrix and plot the values from largest to smallest and then plot a set of random eigenvalues. The number of eigenvalues before the intersection points indicates how many factors to include in your model.[20][31][32] This procedure can be somewhat arbitrary (i.e. a factor just meeting the cutoff will be included and one just below will not).[2] Moreover, the method is very sensitive to sample size, with PA suggesting more factors in datasets with larger sample sizes.[33] Despite its shortcomings, this procedure performs very well in simulation studies and is one of Courtney's recommended procedures.[15] PA has been implemented in a number of commonly used statistics programs such as R and SPSS.
Ruscio and Roche's comparison data
In 2012 Ruscio and Roche[14] introduced the comparative data (CD) procedure in an attempt improve upon the PA method. The authors state that "rather than generating random datasets, which only take into account sampling error, multiple datasets with known factorial structures are analyzed to determine which best reproduces the profile of eigenvalues for the actual data" (p. 258). The strength of the procedure is its ability to not only incorporate sampling error, but also the factorial structure and multivariate distribution of the items. Ruscio and Roche's (2012) simulation study[14] determined that the CD procedure outperformed many other methods aimed at determining the correct number of factors to retain. In that study, the CD technique, making use of Pearson correlations accurately predicted the correct number of factors 87.14% of the time. However, the simulated study never involved more than five factors. Therefore, the applicability of the CD procedure to estimate factorial structures beyond five factors is yet to be tested. Courtney includes this procedure in his recommended list and gives guidelines showing how it can be easily carried out from within SPSS's user interface.[15]
Convergence of multiple tests
A review of 60 journal articles by Henson and Roberts (2006) found that none used multiple modern techniques in an attempt to find convergence, such as PA and Velicer's (1976) minimum average partial (MAP) procedures. Ruscio and Roche (2012) simulation study demonstrated the empirical advantage of seeking convergence. When the CD and PA procedures agreed, the accuracy of the estimated number of factors was correct 92.2% of the time. Ruscio and Roche (2012) demonstrated that when further tests were in agreement, the accuracy of the estimation could be increased even further.[15]
Tailoring Courtney's recommended procedures for ordinal and continuous data
Recent simulation studies in the field of psychometrics suggest that the parallel analysis, minimum average partial, and comparative data techniques can be improved for different data situations. For example, in simulation studies, the performance of the minimum average partial test, when ordinal data is concerned, can be improved by utilizing polychoric correlations, as opposed to Pearson correlations. Courtney (2013)[15] details how each of these three procedures can be optimized and carried out simultaneously from within the SPSS interface.
Factor rotation
Factor rotation is a commonly employed step in EFA, used to aide interpretation of factor matrixes.[34][35][36] For any solution with two or more factors there are an infinite number of orientations of the factors that will explain the data equally well. Because there is no unique solution, a researcher must select a single solution from the infinite possibilities. The goal of factor rotation is to rotate factors in multidimensional space to arrive at a solution with best simple structure. There are two main types of factor rotation: orthogonal and oblique rotation.
Orthogonal rotation
Orthogonal rotations constrain factors to be perpendicular to each other and hence uncorrelated. An advantage of orthogonal rotation is its simplicity and conceptual clarity, although there are several disadvantages. In the social sciences, there is often a theoretical basis for expecting constructs to be correlated, therefore orthogonal rotations may not be very realistic because they do not allow this. Also, because orthogonal rotations require factors to be uncorrelated, they are less likely to produce solutions with simple structure.[2]
Varimax rotation is an orthogonal rotation of the factor axes to maximize the variance of the squared loadings of a factor (column) on all the variables (rows) in a factor matrix, which has the effect of differentiating the original variables by extracted factor. Each factor will tend to have either large or small loadings of any particular variable. A varimax solution yields results which make it as easy as possible to identify each variable with a single factor. This is the most common orthogonal rotation option.[2]
Quartimax rotation is an orthogonal rotation that maximizes the squared loadings for each variable rather than each factor. This minimizes the number of factors needed to explain each variable. This type of rotation often generates a general factor on which most variables are loaded to a high or medium degree.[37]
Equimax rotation is a compromise between varimax and quartimax criteria.
Oblique rotation
Oblique rotations permit correlations among factors. An advantage of oblique rotation is that it produces solutions with better simple structure when factors are expected to correlate, and it produces estimates of correlations among factors.[2] These rotations may produce solutions similar to orthogonal rotation if the factors do not correlate with each other.
Several oblique rotation procedures are commonly used. Direct oblimin rotation is the standard oblique rotation method. Promax rotation is often seen in older literature because it is easier to calculate than oblimin. Other oblique methods include direct quartimin rotation and Harris-Kaiser orthoblique rotation.[2]
Unrotated solution
Common factor analysis software is capable of producing an unrotated solution. This refers to the result of a principal axis factoring with no further rotation. The so-called unrotated solution is in fact an orthogonal rotation that maximizes the variance of the first factors. The unrotated solution tends to give a general factor with loadings for most of the variables. This may be useful if many variables are correlated with each other, as revealed by one or a few dominating eigenvalues on a scree plot.
The usefulness of an unrotated solution was emphasized by a meta analysis of studies of cultural differences. This revealed that many published studies of cultural differences have given similar factor analysis results, but rotated differently. Factor rotation has obscured the similarity between the results of different studies and the existence of a strong general factor, while the unrotated solutions were much more similar.[38][39]
Factor interpretation
Factor loadings are numerical values that indicate the strength and direction of a factor on a measured variable. Factor loadings indicate how strongly the factor influences the measured variable. In order to label the factors in the model, researchers should examine the factor pattern to see which items load highly on which factors and then determine what those items have in common.[2] Whatever the items have in common will indicate the meaning of the factor.
See also
References
- Norris, Megan; Lecavalier, Luc (17 July 2009). "Evaluating the Use of Exploratory Factor Analysis in Developmental Disability Psychological Research". Journal of Autism and Developmental Disorders. 40 (1): 8–20. doi:10.1007/s10803-009-0816-2. PMID 19609833. S2CID 45751299.
- Fabrigar, Leandre R.; Wegener, Duane T.; MacCallum, Robert C.; Strahan, Erin J. (1 January 1999). "Evaluating the use of exploratory factor analysis in psychological research" (PDF). Psychological Methods. 4 (3): 272–299. doi:10.1037/1082-989X.4.3.272.
- Finch, J. F.; West, S. G. (1997). "The investigation of personality structure: Statistical models". Journal of Research in Personality. 31 (4): 439–485. doi:10.1006/jrpe.1997.2194.
- Worthington, Roger L.; Whittaker, Tiffany A J. (1 January 2006). "Scale development research: A content analysis and recommendations for best practices". The Counseling Psychologist. 34 (6): 806–838. doi:10.1177/0011000006288127. S2CID 146284440.
- Suhr, D. D. (2006). Exploratory or confirmatory factor analysis? (pp. 1-17). Cary: SAS Institute.
- Cudeck, R.; O'Dell, L. L. (1994). "Applications of standard error estimates in unrestricted factor analysis: Significance tests for factor loadings and correlations". Psychological Bulletin. 115 (3): 475–487. doi:10.1037/0033-2909.115.3.475. PMID 8016288.
- Fabrigar, Leandre R.; Wegener, Duane T. (2012-01-12). Exploratory factor analysis. Oxford: Oxford University Press. ISBN 978-0-19-973417-7.
- Kaiser, H.F. (1960). "The application of electronic computers to factor analysis". Educational and Psychological Measurement. 20: 141–151. doi:10.1177/001316446002000116. S2CID 146138712.
- Cattell, R. B. (1966). The scree test for the number of factors. Multivariate Behavioral Research, I, 245-276.
- Revelle, W.; Rocklin, T. (1979). "Very simple structure-alternative procedure for estimating the optimal number of interpretable factors". Multivariate Behavioral Research. 14 (4): 403–414. doi:10.1207/s15327906mbr1404_2. PMID 26804437.
- Fabrigar, Leandre R.; Wegener, Duane T.; MacCallum, Robert C.; Strahan, Erin J. (1999). "Evaluating the use of exploratory factor analysis in psychological research". Psychological Methods. 4 (3): 272–299. doi:10.1037/1082-989X.4.3.272.
- Raiche, G., Roipel, M., & Blais, J. G.|Non graphical solutions for the Cattell’s scree test. Paper presented at The International Annual Meeting of the Psychometric Society, Montreal|date=2006|Retrieved December 10, 2012 from "Archived copy" (PDF). Archived (PDF) from the original on 2013-10-21. Retrieved 2013-05-03.
{{cite web}}: CS1 maint: archived copy as title (link) - Velicer, W.F. (1976). "Determining the number of components from the matrix of partial correlations". Psychometrika. 41 (3): 321–327. doi:10.1007/bf02293557. S2CID 122907389.
- Ruscio, J.; Roche, B. (2012). "Determining the number of factors to retain in an exploratory factor analysis using comparison data of a known factorial structure". Psychological Assessment. 24 (2): 282–292. doi:10.1037/a0025697. PMID 21966933.
- Courtney, M. G. R. (2013). Determining the number of factors to retain in EFA: Using the SPSS R-Menu v2.0 to make more judicious estimations. Practical Assessment, Research and Evaluation, 18(8). Available online:
"Archived copy". Archived from the original on 2015-03-17. Retrieved 2014-06-08.
{{cite web}}: CS1 maint: archived copy as title (link) - Larsen, R.; Warne, R. T. (2010). "Estimating confidence intervals for eigenvalues in exploratory factor analysis". Behavior Research Methods. 42 (3): 871–876. doi:10.3758/BRM.42.3.871. PMID 20805609.
- Warne, R. T.; Larsen, R. (2014). "Evaluating a proposed modification of the Guttman rule for determining the number of factors in an exploratory factor analysis". Psychological Test and Assessment Modeling. 56: 104–123.
- Kaiser, H. F. (1970). "A second generation little jiffy". Psychometrika. 35 (4): 401–415. doi:10.1007/bf02291817. S2CID 121850294.
- Lawley, D. N. (1940). The estimation of factor loadings by the method of maximumlikelihood. Proceedings of the Royal Society ofedinborough, 60A, 64-82.
- Humphreys, L. G.; Montanelli, R. G. Jr (1975). "An investigation of the parallel analysis criterion for determining the number of common factors". Multivariate Behavioral Research. 10 (2): 193–205. doi:10.1207/s15327906mbr1002_5.
- Hakstian, A. R.; Rogers, W. T.; Cattell, R. B. (1982). "The behavior of number-offactors rules with simulated data". Multivariate Behavioral Research. 17 (2): 193–219. doi:10.1207/s15327906mbr1702_3. PMID 26810948.
- Harris, M. L.; Harris, C. W. (1 October 1971). "A Factor Analytic Interpretation Strategy". Educational and Psychological Measurement. 31 (3): 589–606. doi:10.1177/001316447103100301. S2CID 143515527.
- Maccallum, R. C. (1990). "The need for alternative measures of fit in covariance structure modeling". Multivariate Behavioral Research. 25 (2): 157–162. doi:10.1207/s15327906mbr2502_2. PMID 26794477.
- Browne, M. W.; Cudeck, R. (1992). "Alternative ways of assessing model fit". Sociological Methods and Research. 21 (2): 230–258. doi:10.1177/0049124192021002005. S2CID 120166447.
- Steiger, J. H. (1989). EzPATH: A supplementary module for SYSTAT andsygraph. Evanston, IL: SYSTAT
- Neath, A. A., & Cavanaugh, J. E. (2012). The Bayesian information criterion: background, derivation, and applications. Wiley Interdisciplinary Reviews: Computational Statistics, 4(2), 199-203.
- Haslbeck, J., & van Bork, R. (2022). Estimating the number of factors in exploratory factor analysis via out-of-sample prediction errors. Psychological Methods.
- Raiche, Roipel, and Blais (2006)
- Garrido, L. E., & Abad, F. J., & Ponsoda, V. (2012). A new look at Horn's parallel analysis with ordinal variables. Psychological Methods. Advance online publication. doi:10.1037/a0030005
- Warne, R. T.; Larsen, R. (2014). "Evaluating a proposed modification of the Guttman rule for determinig the number of factors in an exploratory factor analysis". Psychological Test and Assessment Modeling. 56: 104–123.
- Horn, John L. (1 June 1965). "A rationale and test for the number of factors in factor analysis". Psychometrika. 30 (2): 179–185. doi:10.1007/BF02289447. PMID 14306381. S2CID 19663974.
- Humphreys, L. G.; Ilgen, D. R. (1 October 1969). "Note On a Criterion for the Number of Common Factors". Educational and Psychological Measurement. 29 (3): 571–578. doi:10.1177/001316446902900303. S2CID 145258601.
- Warne, R. G.; Larsen, R. (2014). "Evaluating a proposed modification of the Guttman rule for determining the number of factors in an exploratory factor analysis". Psychological Test and Assessment Modeling. 56: 104–123.
- Browne, Michael W. (January 2001). "An Overview of Analytic Rotation in Exploratory Factor Analysis". Multivariate Behavioral Research. 36 (1): 111–150. doi:10.1207/S15327906MBR3601_05. S2CID 9598774.
- Sass, Daniel A.; Schmitt, Thomas A. (29 January 2010). "A Comparative Investigation of Rotation Criteria Within Exploratory Factor Analysis". Multivariate Behavioral Research. 45 (1): 73–103. doi:10.1080/00273170903504810. PMID 26789085. S2CID 6458980.
- Schmitt, Thomas A.; Sass, Daniel A. (February 2011). "Rotation Criteria and Hypothesis Testing for Exploratory Factor Analysis: Implications for Factor Pattern Loadings and Interfactor Correlations". Educational and Psychological Measurement. 71 (1): 95–113. doi:10.1177/0013164410387348. S2CID 120709021.
- Neuhaus, Jack O; Wrigley, C. (1954). "The Quartimax Method". British Journal of Statistical Psychology. 7 (2): 81–91. doi:10.1111/j.2044-8317.1954.tb00147.x.
- Fog, A. (2020). "A Test of the Reproducibility of the Clustering of Cultural Variables". Cross-Cultural Research. 55: 29–57. doi:10.1177/1069397120956948. S2CID 224909443.
- "Examining Factors in 2015 TIMSS Australian Grade 4 Student Questionnaire Regarding Attitudes Towards Science Using Exploratory Factor Analysis (EFA)". North American Academic Research. 3.
External links
- Best Practices in Exploratory Factor Analysis: Four Recommendations for Getting the Most From Your Analysis. http://pareonline.net/pdf/v10n7.pdf
- Wikiversity: Exploratory Factor Analysis. http://en.wikiversity.org/wiki/Exploratory_factor_analysis
- Tucker and MacCallum: Exploratory Factor Analysis. pdf