Savitzky–Golay filter
A Savitzky–Golay filter is a digital filter that can be applied to a set of digital data points for the purpose of smoothing the data, that is, to increase the precision of the data without distorting the signal tendency. This is achieved, in a process known as convolution, by fitting successive sub-sets of adjacent data points with a low-degree polynomial by the method of linear least squares. When the data points are equally spaced, an analytical solution to the least-squares equations can be found, in the form of a single set of "convolution coefficients" that can be applied to all data sub-sets, to give estimates of the smoothed signal, (or derivatives of the smoothed signal) at the central point of each sub-set. The method, based on established mathematical procedures,[1][2] was popularized by Abraham Savitzky and Marcel J. E. Golay, who published tables of convolution coefficients for various polynomials and sub-set sizes in 1964.[3][4] Some errors in the tables have been corrected.[5] The method has been extended for the treatment of 2- and 3-dimensional data.
Savitzky and Golay's paper is one of the most widely cited papers in the journal Analytical Chemistry[6] and is classed by that journal as one of its "10 seminal papers" saying "it can be argued that the dawn of the computer-controlled analytical instrument can be traced to this article".[7]
Applications
The data consists of a set of points {xj, yj}, j = 1, ..., n, where xj is an independent variable and yj is an observed value. They are treated with a set of m convolution coefficients, Ci, according to the expression

Selected convolution coefficients are shown in the tables, below. For example, for smoothing by a 5-point quadratic polynomial, m = 5, i = −2, −1, 0, 1, 2 and the jth smoothed data point, Yj, is given by
- ,

where, C−2 = −3/35, C−1 = 12 / 35, etc. There are numerous applications of smoothing, which is performed primarily to make the data appear to be less noisy than it really is. The following are applications of numerical differentiation of data.[8] Note When calculating the nth derivative, an additional scaling factor of may be applied to all calculated data points to obtain absolute values (see expressions for , below, for details).


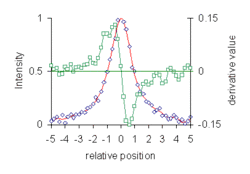
- Location of maxima and minima in experimental data curves. This was the application that first motivated Savitzky.[4] The first derivative of a function is zero at a maximum or minimum. The diagram shows data points belonging to a synthetic Lorentzian curve, with added noise (blue diamonds). Data are plotted on a scale of half width, relative to the peak maximum at zero. The smoothed curve (red line) and 1st derivative (green) were calculated with 7-point cubic Savitzky–Golay filters. Linear interpolation of the first derivative values at positions either side of the zero-crossing gives the position of the peak maximum. 3rd derivatives can also be used for this purpose.
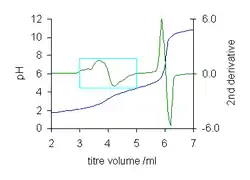
- Location of an end-point in a titration curve. An end-point is an inflection point where the second derivative of the function is zero.[9] The titration curve for malonic acid illustrates the power of the method. The first end-point at 4 ml is barely visible, but the second derivative allows its value to be easily determined by linear interpolation to find the zero crossing.
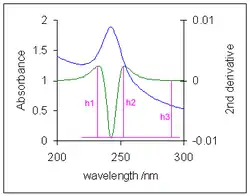
- Baseline flattening. In analytical chemistry it is sometimes necessary to measure the height of an absorption band against a curved baseline.[10] Because the curvature of the baseline is much less than the curvature of the absorption band, the second derivative effectively flattens the baseline. Three measures of the derivative height, which is proportional to the absorption band height, are the "peak-to-valley" distances h1 and h2, and the height from baseline, h3.[11]
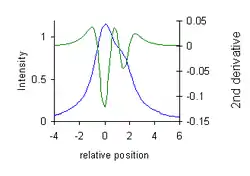
- Resolution enhancement in spectroscopy. Bands in the second derivative of a spectroscopic curve are narrower than the bands in the spectrum: they have reduced half-width. This allows partially overlapping bands to be "resolved" into separate (negative) peaks.[12] The diagram illustrates how this may be used also for chemical analysis, using measurement of "peak-to-valley" distances. In this case the valleys are a property of the 2nd derivative of a Lorentzian. (x-axis position is relative to the position of the peak maximum on a scale of half width at half height).
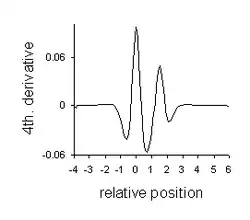
- Resolution enhancement with 4th derivative (positive peaks). The minima are a property of the 4th derivative of a Lorentzian.
Moving average
A moving average filter is commonly used with time series data to smooth out short-term fluctuations and highlight longer-term trends or cycles. It is often used in technical analysis of financial data, like stock prices, returns or trading volumes. It is also used in economics to examine gross domestic product, employment or other macroeconomic time series.
An unweighted moving average filter is the simplest convolution filter. Each subset of the data set is fitted by a straight horizontal line. It was not included in the Savitzsky-Golay tables of convolution coefficients as all the coefficient values are identical, with the value 1/m.
Derivation of convolution coefficients
When the data points are equally spaced, an analytical solution to the least-squares equations can be found.[2] This solution forms the basis of the convolution method of numerical smoothing and differentiation. Suppose that the data consists of a set of n points (xj, yj) (j = 1, ..., n), where xj is an independent variable and yj is a datum value. A polynomial will be fitted by linear least squares to a set of m (an odd number) adjacent data points, each separated by an interval h. Firstly, a change of variable is made

where is the value of the central point. z takes the values (e.g. m = 5 → z = −2, −1, 0, 1, 2).[note 1] The polynomial, of degree k is defined as



The coefficients a0, a1 etc. are obtained by solving the normal equations (bold a represents a vector, bold J represents a matrix).

where is a Vandermonde matrix, that is -th row of has values .



For example, for a cubic polynomial fitted to 5 points, z= −2, −1, 0, 1, 2 the normal equations are solved as follows.


Now, the normal equations can be factored into two separate sets of equations, by rearranging rows and columns, with

Expressions for the inverse of each of these matrices can be obtained using Cramer's rule

The normal equations become

and

Multiplying out and removing common factors,

The coefficients of y in these expressions are known as convolution coefficients. They are elements of the matrix

In general,

In matrix notation this example is written as

Tables of convolution coefficients, calculated in the same way for m up to 25, were published for the Savitzky–Golay smoothing filter in 1964,[3][5] The value of the central point, z = 0, is obtained from a single set of coefficients, a0 for smoothing, a1 for 1st derivative etc. The numerical derivatives are obtained by differentiating Y. This means that the derivatives are calculated for the smoothed data curve. For a cubic polynomial

In general, polynomials of degree (0 and 1),[note 3] (2 and 3), (4 and 5) etc. give the same coefficients for smoothing and even derivatives. Polynomials of degree (1 and 2), (3 and 4) etc. give the same coefficients for odd derivatives.
Algebraic expressions
It is not necessary always to use the Savitzky–Golay tables. The summations in the matrix JTJ can be evaluated in closed form,

so that algebraic formulae can be derived for the convolution coefficients.[13][note 4] Functions that are suitable for use with a curve that has an inflection point are:
- Smoothing, polynomial degree 2,3 : (the range of values for i also applies to the expressions below)

- 1st derivative: polynomial degree 3,4

- 2nd derivative: polynomial degree 2,3

- 3rd derivative: polynomial degree 3,4

Simpler expressions that can be used with curves that don't have an inflection point are:
- Smoothing, polynomial degree 0,1 (moving average):

- 1st derivative, polynomial degree 1,2:

Higher derivatives can be obtained. For example, a fourth derivative can be obtained by performing two passes of a second derivative function.[14]
Use of orthogonal polynomials
An alternative to fitting m data points by a simple polynomial in the subsidiary variable, z, is to use orthogonal polynomials.

where P0, ..., Pk is a set of mutually orthogonal polynomials of degree 0, ..., k. Full details on how to obtain expressions for the orthogonal polynomials and the relationship between the coefficients b and a are given by Guest.[2] Expressions for the convolution coefficients are easily obtained because the normal equations matrix, JTJ, is a diagonal matrix as the product of any two orthogonal polynomials is zero by virtue of their mutual orthogonality. Therefore, each non-zero element of its inverse is simply the reciprocal the corresponding element in the normal equation matrix. The calculation is further simplified by using recursion to build orthogonal Gram polynomials. The whole calculation can be coded in a few lines of PASCAL, a computer language well-adapted for calculations involving recursion.[15]
Treatment of first and last points
Savitzky–Golay filters are most commonly used to obtain the smoothed or derivative value at the central point, z = 0, using a single set of convolution coefficients. (m − 1)/2 points at the start and end of the series cannot be calculated using this process. Various strategies can be employed to avoid this inconvenience.
- The data could be artificially extended by adding, in reverse order, copies of the first (m − 1)/2 points at the beginning and copies of the last (m − 1)/2 points at the end. For instance, with m = 5, two points are added at the start and end of the data y1, ..., yn.
- y3,y2,y1, ... ,yn, yn−1, yn−2.
- Looking again at the fitting polynomial, it is obvious that data can be calculated for all values of z by using all sets of convolution coefficients for a single polynomial, a0 .. ak.
- For a cubic polynomial

- Convolution coefficients for the missing first and last points can also be easily obtained.[15] This is also equivalent to fitting the first (m + 1)/2 points with the same polynomial, and similarly for the last points.
Weighting the data
It is implicit in the above treatment that the data points are all given equal weight. Technically, the objective function

being minimized in the least-squares process has unit weights, wi = 1. When weights are not all the same the normal equations become
- ,

If the same set of diagonal weights is used for all data subsets, , an analytical solution to the normal equations can be written down. For example, with a quadratic polynomial,


An explicit expression for the inverse of this matrix can be obtained using Cramer's rule. A set of convolution coefficients may then be derived as

Alternatively the coefficients, C, could be calculated in a spreadsheet, employing a built-in matrix inversion routine to obtain the inverse of the normal equations matrix. This set of coefficients, once calculated and stored, can be used with all calculations in which the same weighting scheme applies. A different set of coefficients is needed for each different weighting scheme.
It was shown that Savitzky–Golay filter can be improved by introducing weights that decrease at the ends of the fitting interval.[16]
Two-dimensional convolution coefficients
Two-dimensional smoothing and differentiation can also be applied to tables of data values, such as intensity values in a photographic image which is composed of a rectangular grid of pixels.[17] [18] Such a grid is referred as a kernel, and the data points that constitute the kernel are referred as nodes. The trick is to transform the rectangular kernel into a single row by a simple ordering of the indices of the nodes. Whereas the one-dimensional filter coefficients are found by fitting a polynomial in the subsidiary variable z to a set of m data points, the two-dimensional coefficients are found by fitting a polynomial in subsidiary variables v and w to a set of the values at the m × n kernel nodes. The following example, for a bivariate polynomial of total degree 3, m = 7, and n = 5, illustrates the process, which parallels the process for the one dimensional case, above.[19]


The rectangular kernel of 35 data values, d1 − d35
- vw
−3 −2 −1 0 1 2 3 −2 d1 d2 d3 d4 d5 d6 d7 −1 d8 d9 d10 d11 d12 d13 d14 0 d15 d16 d17 d18 d19 d20 d21 1 d22 d23 d24 d25 d26 d27 d28 2 d29 d30 d31 d32 d33 d34 d35
becomes a vector when the rows are placed one after another.
- d = (d1 ... d35)T
The Jacobian has 10 columns, one for each of the parameters a00 − a03, and 35 rows, one for each pair of v and w values. Each row has the form

The convolution coefficients are calculated as

The first row of C contains 35 convolution coefficients, which can be multiplied with the 35 data values, respectively, to obtain the polynomial coefficient , which is the smoothed value at the central node of the kernel (i.e. at the 18th node of the above table). Similarly, other rows of C can be multiplied with the 35 values to obtain other polynomial coefficients, which, in turn, can be used to obtain smoothed values and different smoothed partial derivatives at different nodes.

Nikitas and Pappa-Louisi showed that depending on the format of the used polynomial, the quality of smoothing may vary significantly.[20] They recommend using the polynomial of the form

because such polynomials can achieve good smoothing both in the central and in the near-boundary regions of a kernel, and therefore they can be confidently used in smoothing both at the internal and at the near-boundary data points of a sampled domain. In order to avoid ill-conditioning when solving the least-squares problem, p < m and q < n. For software that calculates the two-dimensional coefficients and for a database of such C's, see the section on multi-dimensional convolution coefficients, below.
Multi-dimensional convolution coefficients
The idea of two-dimensional convolution coefficients can be extended to the higher spatial dimensions as well, in a straightforward manner,[17][21] by arranging multidimensional distribution of the kernel nodes in a single row. Following the aforementioned finding by Nikitas and Pappa-Louisi[20] in two-dimensional cases, usage of the following form of the polynomial is recommended in multidimensional cases:

where D is the dimension of the space, 's are the polynomial coefficients, and u's are the coordinates in the different spatial directions. Algebraic expressions for partial derivatives of any order, be it mixed or otherwise, can be easily derived from the above expression.[21] Note that C depends on the manner in which the kernel nodes are arranged in a row and on the manner in which the different terms of the expanded form of the above polynomial is arranged, when preparing the Jacobian.

Accurate computation of C in multidimensional cases becomes challenging, as precision of standard floating point numbers available in computer programming languages no longer remain sufficient. The insufficient precision causes the floating point truncation errors to become comparable to the magnitudes of some C elements, which, in turn, severely degrades its accuracy and renders it useless. Chandra Shekhar has brought forth two open source softwares, Advanced Convolution Coefficient Calculator (ACCC) and Precise Convolution Coefficient Calculator (PCCC), which handle these accuracy issues adequately. ACCC performs the computation by using floating point numbers, in an iterative manner.[22] The precision of the floating-point numbers is gradually increased in each iteration, by using GNU MPFR. Once the obtained C's in two consecutive iterations start having same significant digits until a pre-specified distance, the convergence is assumed to have reached. If the distance is sufficiently large, the computation yields a highly accurate C. PCCC employs rational number calculations, by using GNU Multiple Precision Arithmetic Library, and yields a fully accurate C, in the rational number format.[23] In the end, these rational numbers are converted into floating point numbers, until a pre-specified number of significant digits.
A database of C's that are calculated by using ACCC, for symmetric kernels and both symmetric and asymmetric polynomials, on unity-spaced kernel nodes, in the 1, 2, 3, and 4 dimensional spaces, is made available.[24] Chandra Shekhar has also laid out a mathematical framework that describes usage of C calculated on unity-spaced kernel nodes to perform filtering and partial differentiations (of various orders) on non-uniformly spaced kernel nodes,[21] allowing usage of C provided in the aforementioned database. Although this method yields approximate results only, they are acceptable in most engineering applications, provided that non-uniformity of the kernel nodes is weak.
Some properties of convolution
- The sum of convolution coefficients for smoothing is equal to one. The sum of coefficients for odd derivatives is zero.[25]
- The sum of squared convolution coefficients for smoothing is equal to the value of the central coefficient.[26]
- Smoothing of a function leaves the area under the function unchanged.[25]
- Convolution of a symmetric function with even-derivative coefficients conserves the centre of symmetry.[25]
- Properties of derivative filters.[27]
Signal distortion and noise reduction
It is inevitable that the signal will be distorted in the convolution process. From property 3 above, when data which has a peak is smoothed the peak height will be reduced and the half-width will be increased. Both the extent of the distortion and S/N (signal-to-noise ratio) improvement:
- decrease as the degree of the polynomial increases
- increase as the width, m of the convolution function increases
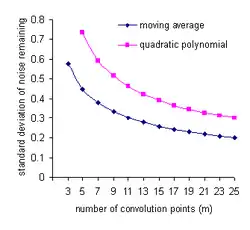
For example, If the noise in all data points is uncorrelated and has a constant standard deviation, σ, the standard deviation on the noise will be decreased by convolution with an m-point smoothing function to[26][note 5]
- polynomial degree 0 or 1: (moving average)
- polynomial degree 2 or 3: .


These functions are shown in the plot at the right. For example, with a 9-point linear function (moving average) two thirds of the noise is removed and with a 9-point quadratic/cubic smoothing function only about half the noise is removed. Most of the noise remaining is low-frequency noise(see Frequency characteristics of convolution filters, below).
Although the moving average function gives better noise reduction it is unsuitable for smoothing data which has curvature over m points. A quadratic filter function is unsuitable for getting a derivative of a data curve with an inflection point because a quadratic polynomial does not have one. The optimal choice of polynomial order and number of convolution coefficients will be a compromise between noise reduction and distortion.[28]
Multipass filters
One way to mitigate distortion and improve noise removal is to use a filter of smaller width and perform more than one convolution with it. For two passes of the same filter this is equivalent to one pass of a filter obtained by convolution of the original filter with itself.[29] For example, 2 passes of the filter with coefficients (1/3, 1/3, 1/3) is equivalent to 1 pass of the filter with coefficients (1/9, 2/9, 3/9, 2/9, 1/9).
The disadvantage of multipassing is that the equivalent filter width for passes of an –point function is so multipassing is subject to greater end-effects. Nevertheless, multipassing has been used to great advantage. For instance, some 40–80 passes on data with a signal-to-noise ratio of only 5 gave useful results.[30] The noise reduction formulae given above do not apply because correlation between calculated data points increases with each pass.



Frequency characteristics of convolution filters
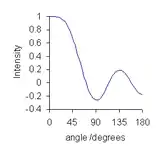
Convolution maps to multiplication in the Fourier co-domain. The discrete Fourier transform of a convolution filter is a real-valued function which can be represented as

θ runs from 0 to 180 degrees, after which the function merely repeats itself. The plot for a 9-point quadratic/cubic smoothing function is typical. At very low angle, the plot is almost flat, meaning that low-frequency components of the data will be virtually unchanged by the smoothing operation. As the angle increases the value decreases so that higher frequency components are more and more attenuated. This shows that the convolution filter can be described as a low-pass filter: the noise that is removed is primarily high-frequency noise and low-frequency noise passes through the filter.[31] Some high-frequency noise components are attenuated more than others, as shown by undulations in the Fourier transform at large angles. This can give rise to small oscillations in the smoothed data[32] and phase reversal, i.e., high-frequency oscillations in the data get inverted by Savitzky–Golay filtering.[33]
Convolution and correlation
Convolution affects the correlation between errors in the data. The effect of convolution can be expressed as a linear transformation.

By the law of error propagation, the variance-covariance matrix of the data, A will be transformed into B according to

To see how this applies in practice, consider the effect of a 3-point moving average on the first three calculated points, Y2 − Y4, assuming that the data points have equal variance and that there is no correlation between them. A will be an identity matrix multiplied by a constant, σ2, the variance at each point.

In this case the correlation coefficients,

between calculated points i and j will be

In general, the calculated values are correlated even when the observed values are not correlated. The correlation extends over m − 1 calculated points at a time.[34]
Multipass filters
To illustrate the effect of multipassing on the noise and correlation of a set of data, consider the effects of a second pass of a 3-point moving average filter. For the second pass[note 6]

After two passes, the standard deviation of the central point has decreased to , compared to 0.58σ for one pass. The noise reduction is a little less than would be obtained with one pass of a 5-point moving average which, under the same conditions, would result in the smoothed points having the smaller standard deviation of 0.45σ.

Correlation now extends over a span of 4 sequential points with correlation coefficients

The advantage obtained by performing two passes with the narrower smoothing function is that it introduces less distortion into the calculated data.
Comparison with other filters and alternatives
Compared with other smoothing filters, e.g. convolution with a Gaussian or multi-pass moving-average filtering, Savitzky–Golay filters have an initially flatter response and sharper cutoff in the frequency domain, especially for high orders of the fit polynomial (see frequency characteristics). For data with limited signal bandwidth, this means that Savitzky–Golay filtering can provide better signal-to-noise ratio than many other filters; e.g., peak heights of spectra are better preserved than for other filters with similar noise suppression. Disadvantages of the Savitzky–Golay filters are comparably poor suppression of some high frequencies (poor stopband suppression) and artifacts when using polynomial fits for the first and last points.[16]
Alternative smoothing methods that share the advantages of Savitzky–Golay filters and mitigate at least some of their disadvantages are Savitzky–Golay filters with properly chosen fitting weights, Whittaker–Henderson smoothing (a method closely related to smoothing splines), and convolution with a windowed sinc function.[16]
See also
- Kernel smoother – Different terminology for many of the same processes, used in statistics
- Local regression — the LOESS and LOWESS methods
- Numerical differentiation – Application to differentiation of functions
- Smoothing spline
- Stencil (numerical analysis) – Application to the solution of differential equations
Appendix
Tables of selected convolution coefficients
Consider a set of data points . The Savitzky–Golay tables refer to the case that the step is constant, h. Examples of the use of the so-called convolution coefficients, with a cubic polynomial and a window size, m, of 5 points are as follows.


- Smoothing
- ;
- 1st derivative
- ;
- 2nd derivative
- .



Selected values of the convolution coefficients for polynomials of degree 1, 2, 3, 4 and 5 are given in the following tables[note 7] The values were calculated using the PASCAL code provided in Gorry.[15]
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Notes
- With even values of m, z will run from 1 − m to m − 1 in steps of 2
- The simple moving average is a special case with k = 0, Y = a0. In this case all convolution coefficients are equal to 1/m.
- Smoothing using the moving average is equivalent, with equally spaced points, to local fitting with a (sloping) straight line
- The expressions given here are different from those of Madden, which are given in terms of the variable m' = (m − 1)/2.
- The expressions under the square root sign are the same as the expression for the convolution coefficient with z=0
- The same result is obtained with one pass of the equivalent filter with coefficients (1/9, 2/9, 3/9, 2/9, 1/9) and an identity variance-covariance matrix
- More extensive tables and the method to calculate additional coefficients were originally provided by Savitzky and Golay.[3]
References
- Whittaker, E.T; Robinson, G (1924). The Calculus Of Observations. Blackie & Son. pp. 291–6. OCLC 1187948.. "Graduation Formulae obtained by fitting a Polynomial."
- Guest, P.G. (2012) [1961]. "Ch. 7: Estimation of Polynomial Coefficients". Numerical Methods of Curve Fitting. Cambridge University Press. pp. 147–. ISBN 978-1-107-64695-7.
- Savitzky, A.; Golay, M.J.E. (1964). "Smoothing and Differentiation of Data by Simplified Least Squares Procedures". Analytical Chemistry. 36 (8): 1627–39. Bibcode:1964AnaCh..36.1627S. doi:10.1021/ac60214a047.
- Savitzky, Abraham (1989). "A Historic Collaboration". Analytical Chemistry. 61 (15): 921A–3A. doi:10.1021/ac00190a744.
- Steinier, Jean; Termonia, Yves; Deltour, Jules (1972). "Smoothing and differentiation of data by simplified least square procedure". Analytical Chemistry. 44 (11): 1906–9. doi:10.1021/ac60319a045. PMID 22324618.
- Larive, Cynthia K.; Sweedler, Jonathan V. (2013). "Celebrating the 75th Anniversary of the ACS Division of Analytical Chemistry: A Special Collection of the Most Highly Cited Analytical Chemistry Papers Published between 1938 and 2012". Analytical Chemistry. 85 (9): 4201–2. doi:10.1021/ac401048d. PMID 23647149.
- Riordon, James; Zubritsky, Elizabeth; Newman, Alan (2000). "Top 10 Articles". Analytical Chemistry. 72 (9): 24 A–329 A. doi:10.1021/ac002801q.
- Talsky, Gerhard (1994-10-04). Derivative Spectrophotometry. Wiley. ISBN 978-3527282944.
- Abbaspour, Abdolkarim; Khajehzadeha, Abdolreza (2012). "End point detection of precipitation titration by scanometry method without using indicator". Anal. Methods. 4 (4): 923–932. doi:10.1039/C2AY05492B.
- Li, N; Li, XY; Zou, XZ; Lin, LR; Li, YQ (2011). "A novel baseline-correction method for standard addition based derivative spectra and its application to quantitative analysis of benzo(a)pyrene in vegetable oil samples". Analyst. 136 (13): 2802–10. Bibcode:2011Ana...136.2802L. doi:10.1039/c0an00751j. PMID 21594244.
- Dixit, L.; Ram, S. (1985). "Quantitative Analysis by Derivative Electronic Spectroscopy". Applied Spectroscopy Reviews. 21 (4): 311–418. Bibcode:1985ApSRv..21..311D. doi:10.1080/05704928508060434.
- Giese, Arthur T.; French, C. Stacey (1955). "The Analysis of Overlapping Spectral Absorption Bands by Derivative Spectrophotometry". Appl. Spectrosc. 9 (2): 78–96. Bibcode:1955ApSpe...9...78G. doi:10.1366/000370255774634089. S2CID 97784067.
- Madden, Hannibal H. (1978). "Comments on the Savitzky–Golay convolution method for least-squares-fit smoothing and differentiation of digital data" (PDF). Anal. Chem. 50 (9): 1383–6. doi:10.1021/ac50031a048.
- Gans 1992, pp. 153–7, "Repeated smoothing and differentiation"
- A., Gorry (1990). "General least-squares smoothing and differentiation by the convolution (Savitzky–Golay) method". Analytical Chemistry. 62 (6): 570–3. doi:10.1021/ac00205a007.
- Schmid, Michael; Rath, David; Diebold, Ulrike (2022). "Why and how Savitzky–Golay filters should be replaced". ACS Measurement Science Au. 2 (2): 185–196. doi:10.1021/acsmeasuresciau.1c00054. PMC 9026279. PMID 35479103.
- Thornley, David J. Anisotropic Multidimensional Savitzky Golay kernels for Smoothing, Differentiation and Reconstruction (PDF) (Technical report). Imperial College Department of Computing. 2066/8.
- Ratzlaff, Kenneth L.; Johnson, Jean T. (1989). "Computation of two-dimensional polynomial least-squares convolution smoothing integers". Anal. Chem. 61 (11): 1303–5. doi:10.1021/ac00186a026.
- Krumm, John. "Savitzky–Golay filters for 2D Images". Microsoft Research, Redmond.
- Nikitas and Pappa-Louisi (2000). "Comments on the two-dimensional smoothing of data". Analytica Chimica Acta. 415 (1–2): 117–125. doi:10.1016/s0003-2670(00)00861-8.
- Shekhar, Chandra (2015). On Simplified Application of Multidimensional Savitzky-Golay Filters and Differentiators. Progress in Applied Mathematics in Science and Engineering. AIP Conference Proceedings. Vol. 1705. p. 020014. Bibcode:2016AIPC.1705b0014S. doi:10.1063/1.4940262.
- Chandra, Shekhar (2017-08-02). "Advanced Convolution Coefficient Calculator". Zenodo. doi:10.5281/zenodo.835283.
- Chandra, Shekhar (2018-06-02). "Precise Convolution Coefficient Calculator". Zenodo. doi:10.5281/zenodo.1257898.
- Shekhar, Chandra. "Convolution Coefficient Database for Multidimensional Least-Squares Filters".
- Gans 1992, Appendix 7
- Ziegler, Horst (1981). "Properties of Digital Smoothing Polynomial (DISPO) Filters". Applied Spectroscopy. 35 (1): 88–92. Bibcode:1981ApSpe..35...88Z. doi:10.1366/0003702814731798. S2CID 97777604.
- Luo, Jianwen; Ying, Kui; He, Ping; Bai, Jing (2005). "Properties of Savitzky–Golay digital differentiators" (PDF). Digital Signal Processing. 15 (2): 122–136. doi:10.1016/j.dsp.2004.09.008.
- Gans, Peter; Gill, J. Bernard (1983). "Examination of the Convolution Method for Numerical Smoothing and Differentiation of Spectroscopic Data in Theory and in Practice". Applied Spectroscopy. 37 (6): 515–520. Bibcode:1983ApSpe..37..515G. doi:10.1366/0003702834634712. S2CID 97649068.
- Gans 1992, p. 153
- Procter, Andrew; Sherwood, Peter M.A. (1980). "Smoothing of digital x-ray photoelectron spectra by an extended sliding least-squares approach". Anal. Chem. 52 (14): 2315–21. doi:10.1021/ac50064a018.
- Gans 1992, p. 207
- Bromba, Manfred U.A; Ziegler, Horst (1981). "Application hints for Savitzky–Golay digital smoothing filters". Anal. Chem. 53 (11): 1583–6. doi:10.1021/ac00234a011.
- Marchand, P.; Marmet, L. (1983). "Binomial smoothing filter: A way to avoid some pitfalls of least‐squares polynomial smoothing". Review of Scientific Instruments. 54 (8): 1034–1041. doi:10.1063/1.1137498.
- Gans 1992, p. 157
- Gans, Peter (1992). Data fitting in the chemical sciences: By the method of least squares. ISBN 9780471934127.