Large language model
A large language model (LLM) is a type of language model notable for its ability to achieve general-purpose language understanding and generation. LLMs acquire these abilities by using massive amounts of data to learn billions of parameters during training and consuming large computational resources during their training and operation.[1] LLMs are artificial neural networks (mainly transformers[2]) and are (pre-)trained using self-supervised learning and semi-supervised learning.
| Part of a series on |
| Machine learning and data mining |
|---|
 |
As autoregressive language models, they work by taking an input text and repeatedly predicting the next token or word.[3] Up to 2020, fine tuning was the only way a model could be adapted to be able to accomplish specific tasks. Larger sized models, such as GPT-3, however, can be prompt-engineered to achieve similar results.[4] They are thought to acquire embodied knowledge about syntax, semantics and "ontology" inherent in human language corpora, but also inaccuracies and biases present in the corpora.[5]
Notable examples include OpenAI's GPT models (e.g., GPT-3.5 and GPT-4, used in ChatGPT), Google's PaLM (used in Bard), and Meta's LLaMa, as well as BLOOM, Ernie 3.0 Titan, and Anthropic's Claude 2.
Dataset preprocessing
Probabilistic tokenization
Using a modification of byte-pair encoding, in the first step, all unique characters (including blanks and punctuation marks) are treated as an initial set of n-grams (i.e. initial set of uni-grams). Successively the most frequent pair of adjacent characters is merged into a bi-gram and all instances of the pair are replaced by it. All occurrences of adjacent pairs of (previously merged) n-grams that most frequently occur together are then again merged into even lengthier n-gram repeatedly until a vocabulary of prescribed size is obtained (in case of GPT-3, the size is 50257).[6] Token vocabulary consists of integers, spanning from zero up to the size of the token vocabulary. New words can always be interpreted as combinations of the tokens and the initial-set uni-grams.[7]
A token vocabulary based on the frequencies extracted from mainly English corpora uses as few tokens as possible for an average English word. An average word in another language encoded by such an English-optimized tokenizer is however split into suboptimal amount of tokens.
tokenizer: texts -> series of numerical "tokens" may be split into:
| n-grams: | token | izer | : | texts | -> | series | of | numerical | " | t | ok | ens | " |
| numbers as "tokens": | 30001 | 7509 | 25 | 13399 | 4613 | 2168 | 286 | 29052 | 366 | 83 | 482 | 641 | 1 |
Probabilistic tokenization also compresses the datasets, which is the reason for using the byte pair encoding algorithm as a tokenizer. Because LLMs generally require input to be an array that is not jagged, the shorter texts must be "padded" until they match the length of the longest one. How many tokens are, on average, needed per word depends on the language of the dataset.[8][9]
Dataset cleaning
Removal of toxic passages from the dataset, discarding low-quality data, and de-duplication are examples of dataset cleaning.[10] Resulting, cleaned (high-quality) datasets contain up to 17 trillion words in 2022, raising from 985 million words, used in 2018 for GPT-1,[11] and 3.3 billion words, used for BERT.[12] The future data is, however, expected to be increasingly "contaminated" by LLM-generated contents themselves.[13]
Training and architecture details
Reinforcement learning from human feedback (RLHF)
Reinforcement learning from human feedback (RLHF) through algorithms, such as proximal policy optimization, is used to further fine-tune a model based on a dataset of human preferences.[14]
Instruction tuning
Using "self-instruct" approaches, LLMs have been able to bootstrap correct responses, replacing any naive responses, starting from human-generated corrections of a few cases. For example, in the instruction "Write an essay about the main themes represented in Hamlet," an initial naive completion might be 'If you submit the essay after March 17, your grade will be reduced by 10% for each day of delay," based on the frequency of this textual sequence in the corpus.[15]
Mixture of experts
The largest LLM may be too expensive to train and use directly. For such models, mixture of experts (MoE) can be applied, a line of research pursued by Google researchers since 2017 to train models reaching up to 1 billion parameters.[16][17][18]
Prompt engineering, attention mechanism, and context window
Most results previously achievable only by (costly) fine-tuning, can be achieved through prompt engineering, although limited to the scope of a single conversation (more precisely, limited to the scope of a context window).[19]
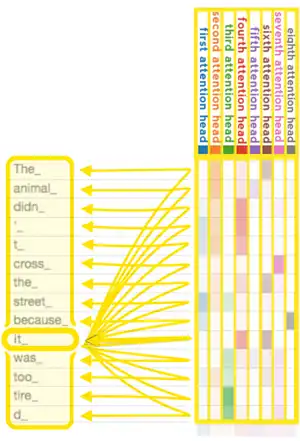
In order to find out which tokens are relevant to each other within the scope of the context window, the attention mechanism calculates "soft" weights for each token, more precisely for its embedding, by using multiple attention heads, each with its own "relevance" for calculating its own soft weights. For example, the small (i.e. 117M parameter sized) GPT-2 model, has had twelve attention heads and a context window of only 1k token.[21] In its medium version it has 345M parameters and contains 24 layers, each with 12 attention heads. For the training with gradient descent a batch size of 512 was utilized.[7]
The largest models can have a context window sized up to 32k (for example, GPT-4; while GPT-3.5 has a context window sized from 4k to 16k, and legacy GPT-3 has had 2k sized context window).[22]
Length of a conversation that the model can take into account when generating its next answer is limited by the size of a context window, as well. If the length of a conversation, for example with Chat-GPT, is longer than its context window, only the parts inside the context window are taken into account when generating the next answer, or the model needs to apply some algorithm to summarize the too distant parts of conversation.
The shortcomings of making a context window larger include higher computational cost and possibly diluting the focus on local context, while making it smaller can cause a model to miss an important long-range dependency. Balancing them are a matter of experimentation and domain-specific considerations.
A model may be pre-trained either to predict how the segment continues, or what is missing in the segment, given a segment from its training dataset.[23] It can be either
- autoregressive (i.e. predicting how the segment continues, the way GPTs do it): for example given a segment "I like to eat", the model predicts "ice cream", or
- "masked" (i.e. filling in the parts missing from the segment, the way "BERT"[12] does it): for example, given a segment "I like to
[__] [__]cream", the model predicts that "eat" and "ice" are missing.
Models may be trained on auxiliary tasks which test their understanding of the data distribution, such as Next Sentence Prediction (NSP), in which pairs of sentences are presented and the model must predict whether they appear consecutively in the training corpus.[12] During training, regularization loss is also used to stabilize training. However regularization loss is usually not used during testing and evaluation.
Training cost
Advances in software and hardware have reduced the cost substantially since 2020, such that in 2023 training of a 12-billion-parameter LLM computational cost is 72,300 A100-GPU-hours, while in 2020 the cost of training a 1.5-billion-parameter LLM (which was two orders of magnitude smaller than the state of the art in 2020) was between $80 thousand and $1.6 million.[24][25][26] Since 2020, large sums were invested in increasingly large models. For example, training of the GPT-2 (i.e. a 1.5-billion-parameters model) in 2019 cost $50,000, while training of the PaLM (i.e. a 540-billion-parameters model) in 2022 cost $8 million.[27]
For Transformer-based LLM, training cost is much higher than inference cost. It costs 6 FLOPs per parameter to train on one token, whereas it costs 1 to 2 FLOPs per parameter to infer on one token.[28]
Tool use
There are certain tasks that, in principle, cannot be solved by any LLM, at least not without the use of external tools or additional software. An example of such a task is responding to the user's input '354 * 139 = ', provided that the LLM has not already encountered a continuation of this calculation in its training corpus. In such cases, the LLM needs to resort to running program code that calculates the result, which can then be included in its response. Another example is 'What is the time now? It is ', where a separate program interpreter would need to execute a code to get system time on the computer, so LLM could include it in its reply.[29][30] This basic strategy can be sophisticated with multiple attempts of generated programs, and other sampling strategies.[31]
Generally, in order to get an LLM to use tools, one must finetune it for tool-use. If the number of tools is finite, then finetuning may be done just once. If the number of tools can grow arbitrarily, as with online API services, then the LLM can be finetuned to be able to read API documentation and call API correctly.[32][33]
A simpler form of tool use is Retrieval Augmented Generation: augment an LLM with document retrieval, sometimes using a vector database. Given a query, a document retriever is called to retrieve the most relevant (usually measured by first encoding the query and the documents into vectors, then finding the documents with vectors closest in Euclidean norm to the query vector). The LLM then generates an output based on both the query and the retrieved documents.[34]
Agency
An LLM is a language model, which is not an agent as it has no goal, but it can be used as a component of an intelligent agent.[35] Researchers have described several methods for such integrations.
The ReAct ("Reason+Act") method constructs an agent out of an LLM, using the LLM as a planner. The LLM is prompted to "think out loud". Specifically, the language model is prompted with a textual description of the environment, a goal, a list of possible actions, and a record of the actions and observations so far. It generates one or more thoughts before generating an action, which is then executed in the environment.[36] The linguistic description of the environment given to the LLM planner can even be the LaTeX code of a paper describing the environment.[37]
In the DEPS ("Describe, Explain, Plan and Select") method, an LLM is first connected to the visual world via image descriptions, then it is prompted to produce plans for complex tasks and behaviors based on its pretrained knowledge and environmental feedback it receives.[38]
The Reflexion method[39] constructs an agent that learns over multiple episodes. At the end of each episode, the LLM is given the record of the episode, and prompted to think up "lessons learned", which would help it perform better at a subsequent episode. These "lessons learned" are given to the agent in the subsequent episodes.
Monte Carlo tree search can use an LLM as rollout heuristic. When a programmatic world model is not available, an LLM can also be prompted with a description of the environment to act as world model.[40]
For open-ended exploration, an LLM can be used to score observations for their "interestingness", which can be used as a reward signal to guide a normal (non-LLM) reinforcement learning agent.[41] Alternatively, it can propose increasingly difficult tasks for curriculum learning.[42] Instead of outputting individual actions, an LLM planner can also construct "skills", or functions for complex action sequences. The skills can be stored and later invoked, allowing increasing levels of abstraction in planning.[42]
LLM-powered agents can keep a long-term memory of its previous contexts, and the memory can be retrieved in the same way as Retrieval Augmented Generation. Multiple such agents can interact socially.[43]
Compression
Typically, LLM are trained with full- or half-precision floating point numbers (float32 and float16). One float16 has 16 bits, or 2 bytes, and so one billion parameters require 2 gigabytes. The largest models typically have 100 billion parameters, requiring 200 gigabytes to load, which places them outside the range of most consumer electronics.
Post-training quantization[44] aims to decrease the space requirement by lowering precision of the parameters of a trained model, while preserving most of its performance.[45][46] The simplest form of quantization simply truncates all numbers to a given number of bits. It can be improved by using a different quantization codebook per layer. Further improvement can be done by applying different precisions to different parameters, with higher precision for particularly important parameters ("outlier weights").[47]
While quantized models are typically frozen, and only pre-quantized models are finetuned, quantized models can still be finetuned.[48]
Multimodality
Multimodality means "having several modalities", and a "modality" means a type of input, such as video, image, audio, text, proprioception, etc.[49] There have been many AI models trained specifically to ingest one modality and output another modality, such as AlexNet for image to label,[50] visual question answering for image-text to text,[51] and speech recognition for speech to text. A review article of multimodal LLM is.[52]
A common method to create multimodal models out of an LLM is to "tokenize" the output of a trained encoder. Concretely, one can construct a LLM that can understand images as follows: take a trained LLM, and take a trained image encoder . Make a small multilayered perceptron , so that for any image , the post-processed vector has the same dimensions as an encoded token. That is an "image token". Then, one can interleave text tokens and image tokens. The compound model is then finetuned on an image-text dataset. This basic construction can be applied with more sophistication to improve the model. The image encoder may be frozen to improve stability.[53]




Flamingo demonstrated the effectiveness of the tokenization method, finetuning a pair of pretrained language model and image encoder to perform better on visual question answering than models trained from scratch.[54] Google PaLM model was finetuned into a multimodal model PaLM-E using the tokenization method, and applied to robotic control.[55] LLaMA models have also been turned multimodal using the tokenization method, to allow image inputs,[56] and video inputs.[57]
GPT-4 can use both text and image as inputs,[58] while Google Gemini is expected to be multimodal.[59]
Properties
Scaling laws and emergent abilities
The following four hyper-parameters characterize a LLM:
- cost of (pre-)training (),
- size of the artificial neural network itself, such as number of parameters (i.e. amount of neurons in its layers, amount of weights between them and biases),
- size of its (pre-)training dataset (i.e. number of tokens in corpus, ),
- performance after (pre-)training.



They are related by simple statistical laws, called "scaling laws". One particular scaling law ("Chinchilla scaling") for LLM autoregressively trained for one epoch, with a log-log learning rate schedule, states that:[60]

where the variables are
- is the cost of training the model, in FLOPs.
- is the number of parameters in the model.
- is the number of tokens in the training set.
- is the average negative log-likelihood loss per token (nats/token), achieved by the trained LLM on the test dataset.

and the statistical hyper-parameters are
- , meaning that it costs 6 FLOPs per parameter to train on one token. Note that training cost is much higher than inference cost, where it costs 1 to 2 FLOPs per parameter to infer on one token.[28]



When one subtracts out from the y-axis the best performance that can be achieved even with infinite scaling of the x-axis quantity, large models' performance, measured on various tasks, seems to be a linear extrapolation of other (smaller-sized and medium-sized) models' performance on a log-log plot. However, sometimes the line's slope transitions from one slope to another at point(s) referred to as break(s)[61] in downstream scaling laws, appearing as a series of linear segments connected by arcs; it seems that larger models acquire "emergent abilities" at this point(s).[19][62] These abilities are discovered rather than programmed-in or designed, in some cases only after the LLM has been publicly deployed.[3]
The most intriguing among emergent abilities is in-context learning from example demonstrations.[63] In-context learning is involved in tasks, such as:
- reported arithmetics, decoding the International Phonetic Alphabet, unscrambling a word's letters, disambiguate word in context,[19][64][65] converting spatial words, cardinal directions (for example, replying "northeast" upon [0, 0, 1; 0, 0, 0; 0, 0, 0]), color terms represented in text.[66]
- chain-of-thought prompting: Model outputs are improved by chain-of-thought prompting only when model size exceeds 62B. Smaller models perform better when prompted to answer immediately, without chain of thought.[67]
- identifying offensive content in paragraphs of Hinglish (a combination of Hindi and English), and generating a similar English equivalent of Kiswahili proverbs.[68]
Schaeffer et. al. argue that the emergent abilities are not unpredictably acquired, but predictably acquired according to a smooth scaling law. The authors considered a toy statistical model of an LLM solving multiple-choice questions, and showed that this statistical model, modified to account for other types of tasks, applies to these tasks as well.[69]
Let be the number of parameter count, and be the performance of the model.

- When , then is an exponential curve (before it hits the plateau at one), which looks like emergence.
- When , then the plot is a straight line (before it hits the plateau at zero), which does not look like emergence.
- When , then is a step-function, which looks like emergence.




Interpretation
Large language models by themselves are "black boxes", and it is not clear how they can perform linguistic tasks. There are several methods for understanding how LLM work.
Mechanistic interpretability aims to reverse-engineer LLM by discovering symbolic algorithms that approximate the inference performed by LLM. One example is Othello-GPT, where a small Transformer is trained to predict legal Othello moves. It is found that there is a linear representation of Othello board, and modifying the representation changes the predicted legal Othello moves in the correct way.[70][71] In another example, a small Transformer is trained on Karel programs. Similar to the Othello-GPT example, there is a linear representation of Karel program semantics, and modifying the representation changes output in the correct way. The model also generates correct programs that are on average shorter than those in the training set.[72]
In another example, the authors trained small transformers on modular arithmetic addition. The resulting models were reverse-engineered, and it turned out they used discrete Fourier transform.[73]
Understanding and intelligence
NLP researchers were evenly split when asked, in a 2022 survey, whether (untuned) LLMs "could (ever) understand natural language in some nontrivial sense".[74] Proponents of "LLM understanding" believe that some LLM abilities, such as mathematical reasoning, imply an ability to "understand" certain concepts. A Microsoft team argued in 2023 that GPT-4 "can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more" and that GPT-4 "could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence system": "Can one reasonably say that a system that passes exams for software engineering candidates is not really intelligent?"[75][76] Some researchers characterize LLMs as "alien intelligence".[77][78] For example, Conjecture CEO Connor Leahy considers untuned LLMs to be like inscrutable alien "Shoggoths", and believes that RLHF tuning creates a "smiling facade" obscuring the inner workings of the LLM: "If you don't push it too far, the smiley face stays on. But then you give it [an unexpected] prompt, and suddenly you see this massive underbelly of insanity, of weird thought processes and clearly non-human understanding."[79][80]
In contrast, some proponents of the "LLMs lack understanding" school believe that existing LLMs are "simply remixing and recombining existing writing",[78] or point to the deficits existing LLMs continue to have in prediction skills, reasoning skills, agency, and explainability.[74] For example, GPT-4 has natural deficits in planning and in real-time learning.[76] Generative LLMs have been observed to confidently assert claims of fact which do not seem to be justified by their training data, a phenomenon which has been termed "hallucination".[81] Specifically, hallucinations in the context of LLMs correspond to the generation of text or responses that seem syntactically sound, fluent, and natural but are factually incorrect, nonsensical, or unfaithful to the provided source input.[82] Neuroscientist Terrence Sejnowski has argued that "The diverging opinions of experts on the intelligence of LLMs suggests that our old ideas based on natural intelligence are inadequate".[74]
The matter of LLM's exhibiting intelligence or understanding [74] has foundations in the study of language as a model of Cognition in the field of Cognitive linguistics. The American Linguist George Lakoff presented Neural Theory of Language (NTL) as a computational basis for using language as a model of learning tasks and understanding.[83] In his 2014 book titled The Language Myth: Why Language Is Not An Instinct, British cognitive linguist and digital communication technologist Vyvyan Evans maps out the role of probabilistic context-free grammar (PCFG) in enabling NLP to model cognitive patterns.
Evaluation
Perplexity
The most commonly used measure of a language model's performance is its perplexity on a given text corpus. Perplexity is a measure of how well a model is able to predict the contents of a dataset; the higher the likelihood the model assigns to the dataset, the lower the perplexity. Mathematically, perplexity is defined as the exponential of the average negative log likelihood per token:

here is the number of tokens in the text corpus, and "context for token " depends on the specific type of LLM used. If the LLM is autoregressive, then "context for token " is the segment of text appearing before token . If the LLM is masked, then "context for token " is the segment of text surrounding token .

Because language models may overfit to their training data, models are usually evaluated by their perplexity on a test set of unseen data.[12] This presents particular challenges for the evaluation of large language models. As they are trained on increasingly large corpora of text largely scraped from the web, it becomes increasingly likely that models' training data inadvertently includes portions of any given test set.[4]
Task-specific datasets and benchmarks
A large number of testing datasets and benchmarks have also been developed to evaluate the capabilities of language models on more specific downstream tasks. Tests may be designed to evaluate a variety of capabilities, including general knowledge, commonsense reasoning, and mathematical problem-solving.
One broad category of evaluation dataset is question answering datasets, consisting of pairs of questions and correct answers, for example, ("Have the San Jose Sharks won the Stanley Cup?", "No").[84] A question answering task is considered "open book" if the model's prompt includes text from which the expected answer can be derived (for example, the previous question could be adjoined with some text which includes the sentence "The Sharks have advanced to the Stanley Cup finals once, losing to the Pittsburgh Penguins in 2016."[84]). Otherwise, the task is considered "closed book", and the model must draw on knowledge retained during training.[85] Some examples of commonly used question answering datasets include TruthfulQA, Web Questions, TriviaQA, and SQuAD.[85]
Evaluation datasets may also take the form of text completion, having the model select the most likely word or sentence to complete a prompt, for example: "Alice was friends with Bob. Alice went to visit her friend, ____".[4]
Some composite benchmarks have also been developed which combine a diversity of different evaluation datasets and tasks. Examples include GLUE, SuperGLUE, MMLU, BIG-bench, and HELM.[86][85]
It was previously standard to report results on a heldout portion of an evaluation dataset after doing supervised fine-tuning on the remainder. It is now more common to evaluate a pre-trained model directly through prompting techniques, though researchers vary in the details of how they formulate prompts for particular tasks, particularly with respect to how many examples of solved tasks are adjoined to the prompt (i.e. the value of n in n-shot prompting).
Adversarially constructed evaluations
Because of the rapid pace of improvement of large language models, evaluation benchmarks have suffered from short lifespans, with state of the art models quickly "saturating" existing benchmarks, exceeding the performance of human annotators, leading to efforts to replace or augment the benchmark with more challenging tasks.[87] In addition, there are cases of "shortcut learning" wherein AIs sometimes "cheat" on multiple-choice tests by using statistical correlations in superficial test question wording in order to guess the correct responses, without necessarily understanding the actual question being asked.[74]
Some datasets have been constructed adversarially, focusing on particular problems on which extant language models seem to have unusually poor performance compared to humans. One example is the TruthfulQA dataset, a question answering dataset consisting of 817 questions which language models are susceptible to answering incorrectly by mimicking falsehoods to which they were repeatedly exposed during training. For example, an LLM may answer "No" to the question "Can you teach an old dog new tricks?" because of its exposure to the English idiom you can't teach an old dog new tricks, even though this is not literally true.[88]
Another example of an adversarial evaluation dataset is Swag and its successor, HellaSwag, collections of problems in which one of multiple options must be selected to complete a text passage. The incorrect completions were generated by sampling from a language model and filtering with a set of classifiers. The resulting problems are trivial for humans but at the time the datasets were created state of the art language models had poor accuracy on them. For example:
We see a fitness center sign. We then see a man talking to the camera and sitting and laying on a exercise ball. The man...
a) demonstrates how to increase efficient exercise work by running up and down balls.
b) moves all his arms and legs and builds up a lot of muscle.
c) then plays the ball and we see a graphics and hedge trimming demonstration.
d) performs sits ups while on the ball and talking.[89]
BERT selects b) as the most likely completion, though the correct answer is d).[89]
Wider impact
In 2023, Nature Biomedical Engineering wrote that "it is no longer possible to accurately distinguish" human-written text from text created by large language models, and that "It is all but certain that general-purpose large language models will rapidly proliferate... It is a rather safe bet that they will change many industries over time."[90] Goldman Sachs suggested in 2023 that generative language AI could increase global GDP by 7% in the next ten years, and could expose to automation 300 million jobs globally.[91][92] Some commenters expressed concern over accidental or deliberate creation of misinformation, or other forms of misuse.[93] For example, the availability of large language models could reduce the skill-level required to commit bioterrorism; biosecurity researcher Kevin Esvelt has suggested that LLM creators should exclude from their training data papers on creating or enhancing pathogens.[94]
List
| Name | Release date[lower-alpha 1] | Developer | Number of parameters[lower-alpha 2] | Corpus size | Training cost (petaFLOP-day) | License[lower-alpha 3] | Notes |
|---|---|---|---|---|---|---|---|
| BERT | 2018 | 340 million[95] | 3.3 billion words[95] | 9[96] | Apache 2.0[97] | An early and influential language model,[5] but encoder-only and thus not built to be prompted or generative[98] | |
| XLNet | 2019 | ~340 million[99] | 33 billion words | An alternative to BERT; designed as encoder-only[100][101] | |||
| GPT-2 | 2019 | OpenAI | 1.5 billion[102] | 40GB[103] (~10 billion tokens)[104] | MIT[105] | general-purpose model based on transformer architecture | |
| GPT-3 | 2020 | OpenAI | 175 billion[24] | 300 billion tokens[104] | 3640[106] | proprietary | A fine-tuned variant of GPT-3, termed GPT-3.5, was made available to the public through a web interface called ChatGPT in 2022.[107] |
| GPT-Neo | March 2021 | EleutherAI | 2.7 billion[108] | 825 GiB[109] | MIT[110] | The first of a series of free GPT-3 alternatives released by EleutherAI. GPT-Neo outperformed an equivalent-size GPT-3 model on some benchmarks, but was significantly worse than the largest GPT-3.[110] | |
| GPT-J | June 2021 | EleutherAI | 6 billion[111] | 825 GiB[109] | 200[112] | Apache 2.0 | GPT-3-style language model |
| Megatron-Turing NLG | October 2021[113] | Microsoft and Nvidia | 530 billion[114] | 338.6 billion tokens[114] | Restricted web access | Standard architecture but trained on a supercomputing cluster. | |
| Ernie 3.0 Titan | December 2021 | Baidu | 260 billion[115] | 4 Tb | Proprietary | Chinese-language LLM. Ernie Bot is based on this model. | |
| Claude[116] | December 2021 | Anthropic | 52 billion[117] | 400 billion tokens[117] | beta | Fine-tuned for desirable behavior in conversations.[118] | |
| GLaM (Generalist Language Model) | December 2021 | 1.2 trillion[18] | 1.6 trillion tokens[18] | 5600[18] | Proprietary | Sparse mixture of experts model, making it more expensive to train but cheaper to run inference compared to GPT-3. | |
| Gopher | December 2021 | DeepMind | 280 billion[119] | 300 billion tokens[120] | 5833[121] | Proprietary | |
| LaMDA (Language Models for Dialog Applications) | January 2022 | 137 billion[122] | 1.56T words,[122] 168 billion tokens[120] | 4110[123] | Proprietary | Specialized for response generation in conversations. | |
| GPT-NeoX | February 2022 | EleutherAI | 20 billion[124] | 825 GiB[109] | 740[112] | Apache 2.0 | based on the Megatron architecture |
| Chinchilla | March 2022 | DeepMind | 70 billion[125] | 1.4 trillion tokens[125][120] | 6805[121] | Proprietary | Reduced-parameter model trained on more data. Used in the Sparrow bot. |
| PaLM (Pathways Language Model) | April 2022 | 540 billion[126] | 768 billion tokens[125] | 29250[121] | Proprietary | aimed to reach the practical limits of model scale | |
| OPT (Open Pretrained Transformer) | May 2022 | Meta | 175 billion[127] | 180 billion tokens[128] | 310[112] | Non-commercial research[lower-alpha 4] | GPT-3 architecture with some adaptations from Megatron |
| YaLM 100B | June 2022 | Yandex | 100 billion[129] | 1.7TB[129] | Apache 2.0 | English-Russian model based on Microsoft's Megatron-LM. | |
| Minerva | June 2022 | 540 billion[130] | 38.5B tokens from webpages filtered for mathematical content and from papers submitted to the arXiv preprint server[130] | Proprietary | LLM trained for solving "mathematical and scientific questions using step-by-step reasoning".[131] Minerva is based on PaLM model, further trained on mathematical and scientific data. | ||
| BLOOM | July 2022 | Large collaboration led by Hugging Face | 175 billion[132] | 350 billion tokens (1.6TB)[133] | Responsible AI | Essentially GPT-3 but trained on a multi-lingual corpus (30% English excluding programming languages) | |
| Galactica | November 2022 | Meta | 120 billion | 106 billion tokens[134] | unknown | CC-BY-NC-4.0 | Trained on scientific text and modalities. |
| AlexaTM (Teacher Models) | November 2022 | Amazon | 20 billion[135] | 1.3 trillion[136] | proprietary[137] | bidirectional sequence-to-sequence architecture | |
| LLaMA (Large Language Model Meta AI) | February 2023 | Meta | 65 billion[138] | 1.4 trillion[138] | 6300[139] | Non-commercial research[lower-alpha 5] | Trained on a large 20-language corpus to aim for better performance with fewer parameters.[138] Researchers from Stanford University trained a fine-tuned model based on LLaMA weights, called Alpaca.[140] |
| GPT-4 | March 2023 | OpenAI | Exact number unknown[lower-alpha 6] | Unknown | Unknown | proprietary | Available for ChatGPT Plus users and used in several products. |
| Cerebras-GPT | March 2023 | Cerebras | 13 billion[142] | 270[112] | Apache 2.0 | Trained with Chinchilla formula. | |
| Falcon | March 2023 | Technology Innovation Institute | 40 billion[143] | 1 trillion tokens, from RefinedWeb (filtered web text corpus)[144] plus some "curated corpora".[145] | 2800[139] | Apache 2.0[146] | |
| BloombergGPT | March 2023 | Bloomberg L.P. | 50 billion | 363 billion token dataset based on Bloomberg's data sources, plus 345 billion tokens from general purpose datasets[147] | Proprietary | LLM trained on financial data from proprietary sources, that "outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks" | |
| PanGu-Σ | March 2023 | Huawei | 1.085 trillion | 329 billion tokens[148] | Proprietary | ||
| OpenAssistant[149] | March 2023 | LAION | 17 billion | 1.5 trillion tokens | Apache 2.0 | Trained on crowdsourced open data | |
| Jurassic-2[150] | March 2023 | AI21 Labs | Exact size unknown | Unknown | Proprietary | Multilingual[151] | |
| PaLM 2 (Pathways Language Model 2) | May 2023 | 340 billion[152] | 3.6 trillion tokens[152] | 85000[139] | Proprietary | Used in Bard chatbot.[153] | |
| Llama 2 | July 2023 | Meta | 70 billion[154] | 2 trillion tokens[154] | Llama 2 license | Successor of LLaMA. | |
| Falcon 180B | September 2023 | Technology Innovation Institute | 180 billion[155] | 3.5 trillion tokens[155] | Falcon 180B TII license | ||
| Mistral 7B | September 2023 | Mistral | 7.3 billion[156] | Unknown | Apache 2.0 |
Further reading
- Jurafsky, Dan, Martin, James. H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd Edition draft, 2023.
- Phuong, Mary; Hutter, Marcus (2022). "Formal Algorithms for Transformers". arXiv:2207.09238 [cs.LG].
- Eloundou, Tyna; Manning, Sam; Mishkin, Pamela; Rock, Daniel (2023). "GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models". arXiv:2303.10130 [econ.GN].
- Eldan, Ronen; Li, Yuanzhi (2023). "TinyStories: How Small Can Language Models Be and Still Speak Coherent English?". arXiv:2305.07759 [cs.CL].
- Frank, Michael C. (27 June 2023). "Baby steps in evaluating the capacities of large language models". Nature Reviews Psychology. 2 (8): 451–452. doi:10.1038/s44159-023-00211-x. ISSN 2731-0574. S2CID 259713140. Retrieved 2 July 2023.
- Zhao, Wayne Xin; et al. (2023). "A Survey of Large Language Models". arXiv:2303.18223 [cs.CL].
- Kaddour, Jean; et al. (2023). "Challenges and Applications of Large Language Models". arXiv:2307.10169 [cs.CL].
See also
Notes
- This is the date that documentation describing the model's architecture was first released.
- In many cases, researchers release or report on multiple versions of a model having different sizes. In these cases, the size of the largest model is listed here.
- This is the license of the pre-trained model weights. In almost all cases the training code itself is open-source or can be easily replicated.
- The smaller models including 66B are publicly available, while the 175B model is available on request.
- Facebook's license and distribution scheme restricted access to approved researchers, but the model weights were leaked and became widely available.
- As stated in Technical report: "Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method ..."[141]
References
- "Better Language Models and Their Implications". OpenAI. 2019-02-14. Archived from the original on 2020-12-19. Retrieved 2019-08-25.
- Merritt, Rick (2022-03-25). "What Is a Transformer Model?". NVIDIA Blog. Retrieved 2023-07-25.
- Bowman, Samuel R. (2023). "Eight Things to Know about Large Language Models". arXiv:2304.00612 [cs.CL].
- Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda; Agarwal, Sandhini; Herbert-Voss, Ariel; Krueger, Gretchen; Henighan, Tom; Child, Rewon; Ramesh, Aditya; Ziegler, Daniel M.; Wu, Jeffrey; Winter, Clemens; Hesse, Christopher; Chen, Mark; Sigler, Eric; Litwin, Mateusz; Gray, Scott; Chess, Benjamin; Clark, Jack; Berner, Christopher; McCandlish, Sam; Radford, Alec; Sutskever, Ilya; Amodei, Dario (Dec 2020). Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.F.; Lin, H. (eds.). "Language Models are Few-Shot Learners" (PDF). Advances in Neural Information Processing Systems. Curran Associates, Inc. 33: 1877–1901.
- Manning, Christopher D. (2022). "Human Language Understanding & Reasoning". Daedalus. 151 (2): 127–138. doi:10.1162/daed_a_01905. S2CID 248377870.
- "OpenAI API". platform.openai.com. Archived from the original on April 23, 2023. Retrieved 2023-04-30.
- Paaß, Gerhard; Giesselbach, Sven (2022). "Pre-trained Language Models". Foundation Models for Natural Language Processing. Artificial Intelligence: Foundations, Theory, and Algorithms. pp. 19–78. doi:10.1007/978-3-031-23190-2_2. ISBN 9783031231902. Retrieved 3 August 2023.
- Yennie Jun (2023-05-03). "All languages are NOT created (tokenized) equal". Language models cost much more in some languages than others. Retrieved 2023-08-17.
In other words, to express the same sentiment, some languages require up to 10 times more tokens.
- Petrov, Aleksandar; Malfa, Emanuele La; Torr, Philip; Bibi, Adel (June 23, 2023). "Language Model Tokenizers Introduce Unfairness Between Languages". arXiv:2305.15425 – via openreview.net.
{{cite journal}}: Cite journal requires|journal=(help) - Dodge, Jesse; Sap, Maarten; Marasović, Ana; Agnew, William; Ilharco, Gabriel; Groeneveld, Dirk; Mitchell, Margaret; Gardner, Matt (2021). "Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus". arXiv:2104.08758 [cs.CL].
- Zhu, Yukun; Kiros, Ryan; Zemel, Rich; Salakhutdinov, Ruslan; Urtasun, Raquel; Torralba, Antonio; Fidler, Sanja (December 2015). "Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books" (PDF). 2015 IEEE International Conference on Computer Vision (ICCV). pp. 19–27. arXiv:1506.06724. doi:10.1109/ICCV.2015.11. ISBN 978-1-4673-8391-2. S2CID 6866988. Retrieved 11 April 2023.
- Jurafsky, Dan; Martin, James H. (7 January 2023). Speech and Language Processing (PDF) (3rd edition draft ed.). Retrieved 24 May 2022.
- Brown, Tom B.; et al. (2020). "Language Models are Few-Shot Learners". arXiv:2005.14165 [cs.CL].
- Ouyang, Long; Wu, Jeff; Jiang, Xu; Almeida, Diogo; Wainwright, Carroll L.; Mishkin, Pamela; Zhang, Chong; Agarwal, Sandhini; Slama, Katarina; Ray, Alex; Schulman, John; Hilton, Jacob; Kelton, Fraser; Miller, Luke; Simens, Maddie; Askell, Amanda; Welinder, Peter; Christiano, Paul; Leike, Jan; Lowe, Ryan (2022). "Training language models to follow instructions with human feedback". arXiv:2203.02155 [cs.CL].
- Wang, Yizhong; Kordi, Yeganeh; Mishra, Swaroop; Liu, Alisa; Smith, Noah A.; Khashabi, Daniel; Hajishirzi, Hannaneh (2022). "Self-Instruct: Aligning Language Model with Self Generated Instructions". arXiv:2212.10560 [cs.CL].
- Shazeer, Noam; Mirhoseini, Azalia; Maziarz, Krzysztof; Davis, Andy; Le, Quoc; Hinton, Geoffrey; Dean, Jeff (2017-01-01). "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer". arXiv:1701.06538 [cs.LG].
- Lepikhin, Dmitry; Lee, HyoukJoong; Xu, Yuanzhong; Chen, Dehao; Firat, Orhan; Huang, Yanping; Krikun, Maxim; Shazeer, Noam; Chen, Zhifeng (2021-01-12). "GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding". arXiv:2006.16668 [cs.CL].
- Dai, Andrew M; Du, Nan (December 9, 2021). "More Efficient In-Context Learning with GLaM". ai.googleblog.com. Retrieved 2023-03-09.
- Wei, Jason; Tay, Yi; Bommasani, Rishi; Raffel, Colin; Zoph, Barret; Borgeaud, Sebastian; Yogatama, Dani; Bosma, Maarten; Zhou, Denny; Metzler, Donald; Chi, Ed H.; Hashimoto, Tatsunori; Vinyals, Oriol; Liang, Percy; Dean, Jeff; Fedus, William (31 August 2022). "Emergent Abilities of Large Language Models". Transactions on Machine Learning Research. ISSN 2835-8856.
- Allamar, Jay. "Illustrated transformer". Retrieved 2023-07-29.
- Allamar, Jay. "The Illustrated GPT-2 (Visualizing Transformer Language Models)". Retrieved 2023-08-01.
- "OpenAI API". platform.openai.com. Archived from the original on 20 June 2023. Retrieved 2023-06-20.
- Zaib, Munazza; Sheng, Quan Z.; Emma Zhang, Wei (4 February 2020). "A Short Survey of Pre-trained Language Models for Conversational AI-A New Age in NLP". Proceedings of the Australasian Computer Science Week Multiconference. pp. 1–4. arXiv:2104.10810. doi:10.1145/3373017.3373028. ISBN 9781450376976. S2CID 211040895.
- Wiggers, Kyle (28 April 2022). "The emerging types of language models and why they matter". TechCrunch.
- Sharir, Or; Peleg, Barak; Shoham, Yoav (2020). "The Cost of Training NLP Models: A Concise Overview". arXiv:2004.08900 [cs.CL].
- Biderman, Stella; Schoelkopf, Hailey; Anthony, Quentin; Bradley, Herbie; Khan, Mohammad Aflah; Purohit, Shivanshu; Prashanth, USVSN Sai (April 2023). "Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling". arXiv:2304.01373 [cs.CL].
- Vincent, James (3 April 2023). "AI is entering an era of corporate control". The Verge. Retrieved 19 June 2023.
- Section 2.1 and Table 1, Kaplan, Jared; McCandlish, Sam; Henighan, Tom; Brown, Tom B.; Chess, Benjamin; Child, Rewon; Gray, Scott; Radford, Alec; Wu, Jeffrey; Amodei, Dario (2020). "Scaling Laws for Neural Language Models". arXiv:2001.08361 [cs.LG].
- Gao, Luyu; Madaan, Aman; Zhou, Shuyan; Alon, Uri; Liu, Pengfei; Yang, Yiming; Callan, Jamie; Neubig, Graham (2022-11-01). "PAL: Program-aided Language Models". arXiv:2211.10435 [cs.CL].
- "PAL: Program-aided Language Models". reasonwithpal.com. Retrieved 2023-06-12.
- Paranjape, Bhargavi; Lundberg, Scott; Singh, Sameer; Hajishirzi, Hannaneh; Zettlemoyer, Luke; Tulio Ribeiro, Marco (2023-03-01). "ART: Automatic multi-step reasoning and tool-use for large language models". arXiv:2303.09014 [cs.CL].
- Liang, Yaobo; Wu, Chenfei; Song, Ting; Wu, Wenshan; Xia, Yan; Liu, Yu; Ou, Yang; Lu, Shuai; Ji, Lei; Mao, Shaoguang; Wang, Yun; Shou, Linjun; Gong, Ming; Duan, Nan (2023-03-01). "TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs". arXiv:2303.16434 [cs.AI].
- Patil, Shishir G.; Zhang, Tianjun; Wang, Xin; Gonzalez, Joseph E. (2023-05-01). "Gorilla: Large Language Model Connected with Massive APIs". arXiv:2305.15334 [cs.CL].
- Lewis, Patrick; Perez, Ethan; Piktus, Aleksandra; Petroni, Fabio; Karpukhin, Vladimir; Goyal, Naman; Küttler, Heinrich; Lewis, Mike; Yih, Wen-tau; Rocktäschel, Tim; Riedel, Sebastian; Kiela, Douwe (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks". Advances in Neural Information Processing Systems. Curran Associates, Inc. 33: 9459–9474. arXiv:2005.11401.
- Huang, Wenlong; Abbeel, Pieter; Pathak, Deepak; Mordatch, Igor (2022-06-28). "Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents". Proceedings of the 39th International Conference on Machine Learning. PMLR: 9118–9147. arXiv:2201.07207.
- Yao, Shunyu; Zhao, Jeffrey; Yu, Dian; Du, Nan; Shafran, Izhak; Narasimhan, Karthik; Cao, Yuan (2022-10-01). "ReAct: Synergizing Reasoning and Acting in Language Models". arXiv:2210.03629 [cs.CL].
- Wu, Yue; Prabhumoye, Shrimai; Min, So Yeon (24 May 2023). "SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning". arXiv:2305.15486 [cs.AI].
- Wang, Zihao; Cai, Shaofei; Liu, Anji; Ma, Xiaojian; Liang, Yitao (2023-02-03). "Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents". arXiv:2302.01560 [cs.AI].
- Shinn, Noah; Cassano, Federico; Labash, Beck; Gopinath, Ashwin; Narasimhan, Karthik; Yao, Shunyu (2023-03-01). "Reflexion: Language Agents with Verbal Reinforcement Learning". arXiv:2303.11366 [cs.AI].
- Hao, Shibo; Gu, Yi; Ma, Haodi; Jiahua Hong, Joshua; Wang, Zhen; Zhe Wang, Daisy; Hu, Zhiting (2023-05-01). "Reasoning with Language Model is Planning with World Model". arXiv:2305.14992 [cs.CL].
- Zhang, Jenny; Lehman, Joel; Stanley, Kenneth; Clune, Jeff (2 June 2023). "OMNI: Open-endedness via Models of human Notions of Interestingness". arXiv:2306.01711 [cs.AI].
- "Voyager | An Open-Ended Embodied Agent with Large Language Models". voyager.minedojo.org. Retrieved 2023-06-09.
- Park, Joon Sung; O'Brien, Joseph C.; Cai, Carrie J.; Ringel Morris, Meredith; Liang, Percy; Bernstein, Michael S. (2023-04-01). "Generative Agents: Interactive Simulacra of Human Behavior". arXiv:2304.03442 [cs.HC].
- Nagel, Markus; Amjad, Rana Ali; Baalen, Mart Van; Louizos, Christos; Blankevoort, Tijmen (2020-11-21). "Up or Down? Adaptive Rounding for Post-Training Quantization". Proceedings of the 37th International Conference on Machine Learning. PMLR: 7197–7206.
- Polino, Antonio; Pascanu, Razvan; Alistarh, Dan (2018-02-01). "Model compression via distillation and quantization". arXiv:1802.05668 [cs.NE].
- Frantar, Elias; Ashkboos, Saleh; Hoefler, Torsten; Alistarh, Dan (2022-10-01). "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers". arXiv:2210.17323 [cs.LG].
- Dettmers, Tim; Svirschevski, Ruslan; Egiazarian, Vage; Kuznedelev, Denis; Frantar, Elias; Ashkboos, Saleh; Borzunov, Alexander; Hoefler, Torsten; Alistarh, Dan (2023-06-01). "SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression". arXiv:2306.03078 [cs.CL].
- Dettmers, Tim; Pagnoni, Artidoro; Holtzman, Ari; Zettlemoyer, Luke (2023-05-01). "QLoRA: Efficient Finetuning of Quantized LLMs". arXiv:2305.14314 [cs.LG].
- Kiros, Ryan; Salakhutdinov, Ruslan; Zemel, Rich (2014-06-18). "Multimodal Neural Language Models". Proceedings of the 31st International Conference on Machine Learning. PMLR: 595–603.
- Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffrey E (2012). "ImageNet Classification with Deep Convolutional Neural Networks". Advances in Neural Information Processing Systems. Curran Associates, Inc. 25.
- Antol, Stanislaw; Agrawal, Aishwarya; Lu, Jiasen; Mitchell, Margaret; Batra, Dhruv; Zitnick, C. Lawrence; Parikh, Devi (2015). "VQA: Visual Question Answering": 2425–2433.
{{cite journal}}: Cite journal requires|journal=(help) - Yin, Shukang; Fu, Chaoyou; Zhao, Sirui; Li, Ke; Sun, Xing; Xu, Tong; Chen, Enhong (2023-06-01). "A Survey on Multimodal Large Language Models". arXiv:2306.13549 [cs.CV].
- Li, Junnan; Li, Dongxu; Savarese, Silvio; Hoi, Steven (2023-01-01). "BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models". arXiv:2301.12597 [cs.CV].
- Alayrac, Jean-Baptiste; Donahue, Jeff; Luc, Pauline; Miech, Antoine; Barr, Iain; Hasson, Yana; Lenc, Karel; Mensch, Arthur; Millican, Katherine; Reynolds, Malcolm; Ring, Roman; Rutherford, Eliza; Cabi, Serkan; Han, Tengda; Gong, Zhitao (2022-12-06). "Flamingo: a Visual Language Model for Few-Shot Learning". Advances in Neural Information Processing Systems. 35: 23716–23736. arXiv:2204.14198.
- Driess, Danny; Xia, Fei; Sajjadi, Mehdi S. M.; Lynch, Corey; Chowdhery, Aakanksha; Ichter, Brian; Wahid, Ayzaan; Tompson, Jonathan; Vuong, Quan; Yu, Tianhe; Huang, Wenlong; Chebotar, Yevgen; Sermanet, Pierre; Duckworth, Daniel; Levine, Sergey (2023-03-01). "PaLM-E: An Embodied Multimodal Language Model". arXiv:2303.03378 [cs.LG].
- Liu, Haotian; Li, Chunyuan; Wu, Qingyang; Lee, Yong Jae (2023-04-01). "Visual Instruction Tuning". arXiv:2304.08485 [cs.CV].
- Zhang, Hang; Li, Xin; Bing, Lidong (2023-06-01). "Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding". arXiv:2306.02858 [cs.CL].
- OpenAI (2023-03-27). "GPT-4 Technical Report". arXiv:2303.08774 [cs.CL].
- Pichai, Sundar, Google Keynote (Google I/O '23), timestamp 15:31, retrieved 2023-07-02
- Hoffmann, Jordan; Borgeaud, Sebastian; Mensch, Arthur; Buchatskaya, Elena; Cai, Trevor; Rutherford, Eliza; Casas, Diego de Las; Hendricks, Lisa Anne; Welbl, Johannes; Clark, Aidan; Hennigan, Tom; Noland, Eric; Millican, Katie; Driessche, George van den; Damoc, Bogdan (2022-03-29). "Training Compute-Optimal Large Language Models". arXiv:2203.15556 [cs.CL].
- Caballero, Ethan; Gupta, Kshitij; Rish, Irina; Krueger, David (2022). "Broken Neural Scaling Laws". arXiv:2210.14891 [cs.LG].
- "137 emergent abilities of large language models". Jason Wei. Retrieved 2023-06-24.
- Hahn, Michael; Goyal, Navin (2023-03-14). "A Theory of Emergent In-Context Learning as Implicit Structure Induction". arXiv:2303.07971 [cs.LG].
- Pilehvar, Mohammad Taher; Camacho-Collados, Jose (June 2019). "Proceedings of the 2019 Conference of the North". Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics: 1267–1273. doi:10.18653/v1/N19-1128. S2CID 102353817.
- "WiC: The Word-in-Context Dataset". pilehvar.github.io. Retrieved 2023-06-27.
- Patel, Roma; Pavlick, Ellie (2021-10-06). "Mapping Language Models to Grounded Conceptual Spaces".
{{cite journal}}: Cite journal requires|journal=(help) - A Closer Look at Large Language Models Emergent Abilities (Yao Fu, Nov 20, 2022)
- Ornes, Stephen (March 16, 2023). "The Unpredictable Abilities Emerging From Large AI Models". Quanta Magazine.
- Schaeffer, Rylan; Miranda, Brando; Koyejo, Sanmi (2023-04-01). "Are Emergent Abilities of Large Language Models a Mirage?". arXiv:2304.15004 [cs.AI].
- Li, Kenneth; Hopkins, Aspen K.; Bau, David; Viégas, Fernanda; Pfister, Hanspeter; Wattenberg, Martin (2022-10-01). "Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task". arXiv:2210.13382 [cs.LG].
- "Large Language Model: world models or surface statistics?". The Gradient. 2023-01-21. Retrieved 2023-06-12.
- Jin, Charles; Rinard, Martin (2023-05-01). "Evidence of Meaning in Language Models Trained on Programs". arXiv:2305.11169 [cs.LG].
- Nanda, Neel; Chan, Lawrence; Lieberum, Tom; Smith, Jess; Steinhardt, Jacob (2023-01-01). "Progress measures for grokking via mechanistic interpretability". arXiv:2301.05217 [cs.LG].
- Mitchell, Melanie; Krakauer, David C. (28 March 2023). "The debate over understanding in AI's large language models". Proceedings of the National Academy of Sciences. 120 (13): e2215907120. arXiv:2210.13966. Bibcode:2023PNAS..12015907M. doi:10.1073/pnas.2215907120. PMC 10068812. PMID 36943882.
- Metz, Cade (16 May 2023). "Microsoft Says New A.I. Shows Signs of Human Reasoning". The New York Times.
- Bubeck, Sébastien; Chandrasekaran, Varun; Eldan, Ronen; Gehrke, Johannes; Horvitz, Eric; Kamar, Ece; Lee, Peter; Lee, Yin Tat; Li, Yuanzhi; Lundberg, Scott; Nori, Harsha; Palangi, Hamid; Ribeiro, Marco Tulio; Zhang, Yi (2023). "Sparks of Artificial General Intelligence: Early experiments with GPT-4". arXiv:2303.12712 [cs.CL].
- "ChatGPT is more like an 'alien intelligence' than a human brain, says futurist". ZDNET. 2023. Retrieved 12 June 2023.
- Newport, Cal (13 April 2023). "What Kind of Mind Does ChatGPT Have?". The New Yorker. Retrieved 12 June 2023.
- Roose, Kevin (30 May 2023). "Why an Octopus-like Creature Has Come to Symbolize the State of A.I." The New York Times. Retrieved 12 June 2023.
- "The A to Z of Artificial Intelligence". Time Magazine. 13 April 2023. Retrieved 12 June 2023.
- Ji, Ziwei; Lee, Nayeon; Frieske, Rita; Yu, Tiezheng; Su, Dan; Xu, Yan; Ishii, Etsuko; Bang, Yejin; Dai, Wenliang; Madotto, Andrea; Fung, Pascale (November 2022). "Survey of Hallucination in Natural Language Generation" (pdf). ACM Computing Surveys. Association for Computing Machinery. 55 (12): 1–38. arXiv:2202.03629. doi:10.1145/3571730. S2CID 246652372. Retrieved 15 January 2023.
- Varshney, Neeraj (2023). "A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation". arXiv:2307.03987.
{{cite journal}}: Cite journal requires|journal=(help) - Lakoff, G., and M. Johnson, 1999, Philosophy in the Flesh: The Embodied Mind and its Challenge to Western Thought, New York: Basic Books
- Clark, Christopher; Lee, Kenton; Chang, Ming-Wei; Kwiatkowski, Tom; Collins, Michael; Toutanova, Kristina (2019). "BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions". arXiv:1905.10044 [cs.CL].
- Wayne Xin Zhao; Zhou, Kun; Li, Junyi; Tang, Tianyi; Wang, Xiaolei; Hou, Yupeng; Min, Yingqian; Zhang, Beichen; Zhang, Junjie; Dong, Zican; Du, Yifan; Yang, Chen; Chen, Yushuo; Chen, Zhipeng; Jiang, Jinhao; Ren, Ruiyang; Li, Yifan; Tang, Xinyu; Liu, Zikang; Liu, Peiyu; Nie, Jian-Yun; Wen, Ji-Rong (2023). "A Survey of Large Language Models". arXiv:2303.18223 [cs.CL].
- Huyen, Chip (18 October 2019). "Evaluation Metrics for Language Modeling". The Gradient.
- Srivastava, Aarohi; et al. (2022). "Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models". arXiv:2206.04615 [cs.CL].
- Lin, Stephanie; Hilton, Jacob; Evans, Owain (2021). "TruthfulQA: Measuring How Models Mimic Human Falsehoods". arXiv:2109.07958 [cs.CL].
- Zellers, Rowan; Holtzman, Ari; Bisk, Yonatan; Farhadi, Ali; Choi, Yejin (2019). "HellaSwag: Can a Machine Really Finish Your Sentence?". arXiv:1905.07830 [cs.CL].
- "Prepare for truly useful large language models". Nature Biomedical Engineering. 7 (2): 85–86. 7 March 2023. doi:10.1038/s41551-023-01012-6. PMID 36882584. S2CID 257403466.
- "Your job is (probably) safe from artificial intelligence". The Economist. 7 May 2023. Retrieved 18 June 2023.
- "Generative AI Could Raise Global GDP by 7%". Goldman Sachs. Retrieved 18 June 2023.
- Alba, Davey (1 May 2023). "AI chatbots have been used to create dozens of news content farms". The Japan Times. Retrieved 18 June 2023.
- "Could chatbots help devise the next pandemic virus?". Science. 14 June 2023. doi:10.1126/science.adj2463.
- Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (11 October 2018). "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding". arXiv:1810.04805v2 [cs.CL].
- Prickett, Nicole Hemsoth (2021-08-24). "Cerebras Shifts Architecture To Meet Massive AI/ML Models". The Next Platform. Retrieved 2023-06-20.
- "BERT". March 13, 2023 – via GitHub.
- Patel, Ajay; Li, Bryan; Rasooli, Mohammad Sadegh; Constant, Noah; Raffel, Colin; Callison-Burch, Chris (2022). "Bidirectional Language Models Are Also Few-shot Learners". arXiv:2209.14500 [cs.LG].
- "BERT, RoBERTa, DistilBERT, XLNet: Which one to use?". KDnuggets.
- Naik, Amit Raja (September 23, 2021). "Google Introduces New Architecture To Reduce Cost Of Transformers". Analytics India Magazine.
- Yang, Zhilin; Dai, Zihang; Yang, Yiming; Carbonell, Jaime; Salakhutdinov, Ruslan; Le, Quoc V. (2 January 2020). "XLNet: Generalized Autoregressive Pretraining for Language Understanding". arXiv:1906.08237 [cs.CL].
- "GPT-2: 1.5B Release". OpenAI. 2019-11-05. Archived from the original on 2019-11-14. Retrieved 2019-11-14.
- "Better language models and their implications". openai.com.
- "OpenAI's GPT-3 Language Model: A Technical Overview". lambdalabs.com. 3 June 2020.
- "gpt-2". GitHub. Retrieved 13 March 2023.
- Table D.1 in Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda; Agarwal, Sandhini; Herbert-Voss, Ariel; Krueger, Gretchen; Henighan, Tom; Child, Rewon; Ramesh, Aditya; Ziegler, Daniel M.; Wu, Jeffrey; Winter, Clemens; Hesse, Christopher; Chen, Mark; Sigler, Eric; Litwin, Mateusz; Gray, Scott; Chess, Benjamin; Clark, Jack; Berner, Christopher; McCandlish, Sam; Radford, Alec; Sutskever, Ilya; Amodei, Dario (May 28, 2020). "Language Models are Few-Shot Learners". arXiv:2005.14165v4 [cs.CL].
- "ChatGPT: Optimizing Language Models for Dialogue". OpenAI. 2022-11-30. Retrieved 2023-01-13.
- "GPT Neo". March 15, 2023 – via GitHub.
- Gao, Leo; Biderman, Stella; Black, Sid; Golding, Laurence; Hoppe, Travis; Foster, Charles; Phang, Jason; He, Horace; Thite, Anish; Nabeshima, Noa; Presser, Shawn; Leahy, Connor (31 December 2020). "The Pile: An 800GB Dataset of Diverse Text for Language Modeling". arXiv:2101.00027 [cs.CL].
- Iyer, Abhishek (15 May 2021). "GPT-3's free alternative GPT-Neo is something to be excited about". VentureBeat.
- "GPT-J-6B: An Introduction to the Largest Open Source GPT Model | Forefront". www.forefront.ai. Retrieved 2023-02-28.
- Dey, Nolan; Gosal, Gurpreet; Zhiming; Chen; Khachane, Hemant; Marshall, William; Pathria, Ribhu; Tom, Marvin; Hestness, Joel (2023-04-01). "Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster". arXiv:2304.03208 [cs.LG].
- Alvi, Ali; Kharya, Paresh (11 October 2021). "Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World's Largest and Most Powerful Generative Language Model". Microsoft Research.
- Smith, Shaden; Patwary, Mostofa; Norick, Brandon; LeGresley, Patrick; Rajbhandari, Samyam; Casper, Jared; Liu, Zhun; Prabhumoye, Shrimai; Zerveas, George; Korthikanti, Vijay; Zhang, Elton; Child, Rewon; Aminabadi, Reza Yazdani; Bernauer, Julie; Song, Xia (2022-02-04). "Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model". arXiv:2201.11990 [cs.CL].
- Wang, Shuohuan; Sun, Yu; Xiang, Yang; Wu, Zhihua; Ding, Siyu; Gong, Weibao; Feng, Shikun; Shang, Junyuan; Zhao, Yanbin; Pang, Chao; Liu, Jiaxiang; Chen, Xuyi; Lu, Yuxiang; Liu, Weixin; Wang, Xi; Bai, Yangfan; Chen, Qiuliang; Zhao, Li; Li, Shiyong; Sun, Peng; Yu, Dianhai; Ma, Yanjun; Tian, Hao; Wu, Hua; Wu, Tian; Zeng, Wei; Li, Ge; Gao, Wen; Wang, Haifeng (December 23, 2021). "ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation". arXiv:2112.12731 [cs.CL].
- "Product". Anthropic. Retrieved 14 March 2023.
- Askell, Amanda; Bai, Yuntao; Chen, Anna; et al. (9 December 2021). "A General Language Assistant as a Laboratory for Alignment". arXiv:2112.00861 [cs.CL].
- Bai, Yuntao; Kadavath, Saurav; Kundu, Sandipan; et al. (15 December 2022). "Constitutional AI: Harmlessness from AI Feedback". arXiv:2212.08073 [cs.CL].
- "Language modelling at scale: Gopher, ethical considerations, and retrieval". www.deepmind.com. Retrieved 20 March 2023.
- Hoffmann, Jordan; Borgeaud, Sebastian; Mensch, Arthur; et al. (29 March 2022). "Training Compute-Optimal Large Language Models". arXiv:2203.15556 [cs.CL].
- Table 20 of PaLM: Scaling Language Modeling with Pathways
- Cheng, Heng-Tze; Thoppilan, Romal (January 21, 2022). "LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything". ai.googleblog.com. Retrieved 2023-03-09.
- Thoppilan, Romal; De Freitas, Daniel; Hall, Jamie; Shazeer, Noam; Kulshreshtha, Apoorv; Cheng, Heng-Tze; Jin, Alicia; Bos, Taylor; Baker, Leslie; Du, Yu; Li, YaGuang; Lee, Hongrae; Zheng, Huaixiu Steven; Ghafouri, Amin; Menegali, Marcelo (2022-01-01). "LaMDA: Language Models for Dialog Applications". arXiv:2201.08239 [cs.CL].
- Black, Sidney; Biderman, Stella; Hallahan, Eric; et al. (2022-05-01). GPT-NeoX-20B: An Open-Source Autoregressive Language Model. Proceedings of BigScience Episode #5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. Vol. Proceedings of BigScience Episode #5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. pp. 95–136. Retrieved 2022-12-19.
- Hoffmann, Jordan; Borgeaud, Sebastian; Mensch, Arthur; Sifre, Laurent (12 April 2022). "An empirical analysis of compute-optimal large language model training". Deepmind Blog.
- Narang, Sharan; Chowdhery, Aakanksha (April 4, 2022). "Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance". ai.googleblog.com. Retrieved 2023-03-09.
- "Democratizing access to large-scale language models with OPT-175B". ai.facebook.com.
- Zhang, Susan; Roller, Stephen; Goyal, Naman; Artetxe, Mikel; Chen, Moya; Chen, Shuohui; Dewan, Christopher; Diab, Mona; Li, Xian; Lin, Xi Victoria; Mihaylov, Todor; Ott, Myle; Shleifer, Sam; Shuster, Kurt; Simig, Daniel; Koura, Punit Singh; Sridhar, Anjali; Wang, Tianlu; Zettlemoyer, Luke (21 June 2022). "OPT: Open Pre-trained Transformer Language Models". arXiv:2205.01068 [cs.CL].
- Khrushchev, Mikhail; Vasilev, Ruslan; Petrov, Alexey; Zinov, Nikolay (2022-06-22), YaLM 100B, retrieved 2023-03-18
- Lewkowycz, Aitor; Andreassen, Anders; Dohan, David; Dyer, Ethan; Michalewski, Henryk; Ramasesh, Vinay; Slone, Ambrose; Anil, Cem; Schlag, Imanol; Gutman-Solo, Theo; Wu, Yuhuai; Neyshabur, Behnam; Gur-Ari, Guy; Misra, Vedant (30 June 2022). "Solving Quantitative Reasoning Problems with Language Models". arXiv:2206.14858 [cs.CL].
- "Minerva: Solving Quantitative Reasoning Problems with Language Models". ai.googleblog.com. 30 June 2022. Retrieved 20 March 2023.
- Ananthaswamy, Anil (8 March 2023). "In AI, is bigger always better?". Nature. 615 (7951): 202–205. Bibcode:2023Natur.615..202A. doi:10.1038/d41586-023-00641-w. PMID 36890378. S2CID 257380916.
- "bigscience/bloom · Hugging Face". huggingface.co.
- Taylor, Ross; Kardas, Marcin; Cucurull, Guillem; Scialom, Thomas; Hartshorn, Anthony; Saravia, Elvis; Poulton, Andrew; Kerkez, Viktor; Stojnic, Robert (16 November 2022). "Galactica: A Large Language Model for Science". arXiv:2211.09085 [cs.CL].
- "20B-parameter Alexa model sets new marks in few-shot learning". Amazon Science. 2 August 2022.
- Soltan, Saleh; Ananthakrishnan, Shankar; FitzGerald, Jack; et al. (3 August 2022). "AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model". arXiv:2208.01448 [cs.CL].
- "AlexaTM 20B is now available in Amazon SageMaker JumpStart | AWS Machine Learning Blog". aws.amazon.com. 17 November 2022. Retrieved 13 March 2023.
- "Introducing LLaMA: A foundational, 65-billion-parameter large language model". Meta AI. 24 February 2023.
- "The Falcon has landed in the Hugging Face ecosystem". huggingface.co. Retrieved 2023-06-20.
- "Stanford CRFM". crfm.stanford.edu.
- "GPT-4 Technical Report" (PDF). OpenAI. 2023. Archived (PDF) from the original on March 14, 2023. Retrieved March 14, 2023.
- Dey, Nolan (March 28, 2023). "Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models". Cerebras.
- "Abu Dhabi-based TII launches its own version of ChatGPT". tii.ae.
- Penedo, Guilherme; Malartic, Quentin; Hesslow, Daniel; Cojocaru, Ruxandra; Cappelli, Alessandro; Alobeidli, Hamza; Pannier, Baptiste; Almazrouei, Ebtesam; Launay, Julien (2023-06-01). "The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only". arXiv:2306.01116 [cs.CL].
- "tiiuae/falcon-40b · Hugging Face". huggingface.co. 2023-06-09. Retrieved 2023-06-20.
- UAE’s Falcon 40B, World’s Top-Ranked AI Model from Technology Innovation Institute, is Now Royalty-Free, 31 May 2023
- Wu, Shijie; Irsoy, Ozan; Lu, Steven; Dabravolski, Vadim; Dredze, Mark; Gehrmann, Sebastian; Kambadur, Prabhanjan; Rosenberg, David; Mann, Gideon (March 30, 2023). "BloombergGPT: A Large Language Model for Finance". arXiv:2303.17564 [cs.LG].
- Ren, Xiaozhe; Zhou, Pingyi; Meng, Xinfan; Huang, Xinjing; Wang, Yadao; Wang, Weichao; Li, Pengfei; Zhang, Xiaoda; Podolskiy, Alexander; Arshinov, Grigory; Bout, Andrey; Piontkovskaya, Irina; Wei, Jiansheng; Jiang, Xin; Su, Teng; Liu, Qun; Yao, Jun (March 19, 2023). "PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing". arXiv:2303.10845 [cs.CL].
- Köpf, Andreas; Kilcher, Yannic; von Rütte, Dimitri; Anagnostidis, Sotiris; Tam, Zhi-Rui; Stevens, Keith; Barhoum, Abdullah; Duc, Nguyen Minh; Stanley, Oliver; Nagyfi, Richárd; ES, Shahul; Suri, Sameer; Glushkov, David; Dantuluri, Arnav; Maguire, Andrew (2023-04-14). "OpenAssistant Conversations -- Democratizing Large Language Model Alignment". arXiv:2304.07327 [cs.CL].
- Wrobel, Sharon. "Tel Aviv startup rolls out new advanced AI language model to rival OpenAI". www.timesofisrael.com. Retrieved 2023-07-24.
- Wiggers, Kyle (2023-04-13). "With Bedrock, Amazon enters the generative AI race". TechCrunch. Retrieved 2023-07-24.
- Elias, Jennifer (16 May 2023). "Google's newest A.I. model uses nearly five times more text data for training than its predecessor". CNBC. Retrieved 18 May 2023.
- "Introducing PaLM 2". Google. May 10, 2023.
- "Introducing Llama 2: The Next Generation of Our Open Source Large Language Model". Meta AI. 2023. Retrieved 2023-07-19.
- "Falcon 180B". Technology Innovation Institute. 2023. Retrieved 2023-09-21.
- "Announcing Mistral 7B". Mistral. 2023. Retrieved 2023-10-06.