Levenberg–Marquardt algorithm
In mathematics and computing, the Levenberg–Marquardt algorithm (LMA or just LM), also known as the damped least-squares (DLS) method, is used to solve non-linear least squares problems. These minimization problems arise especially in least squares curve fitting. The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.
The algorithm was first published in 1944 by Kenneth Levenberg,[1] while working at the Frankford Army Arsenal. It was rediscovered in 1963 by Donald Marquardt,[2] who worked as a statistician at DuPont, and independently by Girard,[3] Wynne[4] and Morrison.[5]
The LMA is used in many software applications for solving generic curve-fitting problems. By using the Gauss–Newton algorithm it often converges faster than first-order methods.[6] However, like other iterative optimization algorithms, the LMA finds only a local minimum, which is not necessarily the global minimum.
The problem
The primary application of the Levenberg–Marquardt algorithm is in the least-squares curve fitting problem: given a set of empirical pairs of independent and dependent variables, find the parameters of the model curve so that the sum of the squares of the deviations is minimized:





- which is assumed to be non-empty.
![{\displaystyle {\hat {\boldsymbol {\beta }}}\in \operatorname {argmin} \limits _{\boldsymbol {\beta }}S\left({\boldsymbol {\beta }}\right)\equiv \operatorname {argmin} \limits _{\boldsymbol {\beta }}\sum _{i=1}^{m}\left[y_{i}-f\left(x_{i},{\boldsymbol {\beta }}\right)\right]^{2},}](../I/1c7912b49e447a4d589f324e7dfa794d4f57e494.svg)
The solution
Like other numeric minimization algorithms, the Levenberg–Marquardt algorithm is an iterative procedure. To start a minimization, the user has to provide an initial guess for the parameter vector . In cases with only one minimum, an uninformed standard guess like will work fine; in cases with multiple minima, the algorithm converges to the global minimum only if the initial guess is already somewhat close to the final solution.

In each iteration step, the parameter vector is replaced by a new estimate . To determine , the function is approximated by its linearization:




where

is the gradient (row-vector in this case) of with respect to .

The sum of square deviations has its minimum at a zero gradient with respect to . The above first-order approximation of gives
![{\displaystyle S\left({\boldsymbol {\beta }}+{\boldsymbol {\delta }}\right)\approx \sum _{i=1}^{m}\left[y_{i}-f\left(x_{i},{\boldsymbol {\beta }}\right)-\mathbf {J} _{i}{\boldsymbol {\delta }}\right]^{2},}](../I/6e25768636e7ae5b26d0937c3dfbd68e93f296d7.svg)
or in vector notation,
![{\displaystyle {\begin{aligned}S\left({\boldsymbol {\beta }}+{\boldsymbol {\delta }}\right)&\approx \left\|\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)-\mathbf {J} {\boldsymbol {\delta }}\right\|^{2}\\&=\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)-\mathbf {J} {\boldsymbol {\delta }}\right]^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)-\mathbf {J} {\boldsymbol {\delta }}\right]\\&=\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]-\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]^{\mathrm {T} }\mathbf {J} {\boldsymbol {\delta }}-\left(\mathbf {J} {\boldsymbol {\delta }}\right)^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]+{\boldsymbol {\delta }}^{\mathrm {T} }\mathbf {J} ^{\mathrm {T} }\mathbf {J} {\boldsymbol {\delta }}\\&=\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]-2\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]^{\mathrm {T} }\mathbf {J} {\boldsymbol {\delta }}+{\boldsymbol {\delta }}^{\mathrm {T} }\mathbf {J} ^{\mathrm {T} }\mathbf {J} {\boldsymbol {\delta }}.\end{aligned}}}](../I/7bdfaf3c5eb5647e7be6004e8f5e751b74b770ff.svg)
Taking the derivative of with respect to and setting the result to zero gives

![{\displaystyle \left(\mathbf {J} ^{\mathrm {T} }\mathbf {J} \right){\boldsymbol {\delta }}=\mathbf {J} ^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right],}](../I/d10c1953686875476646a1d58403b1a14bf3ab37.svg)
where is the Jacobian matrix, whose -th row equals , and where and are vectors with -th component and respectively. The above expression obtained for comes under the Gauss–Newton method. The Jacobian matrix as defined above is not (in general) a square matrix, but a rectangular matrix of size , where is the number of parameters (size of the vector ). The matrix multiplication yields the required square matrix and the matrix-vector product on the right hand side yields a vector of size . The result is a set of linear equations, which can be solved for .











Levenberg's contribution is to replace this equation by a "damped version":
![{\displaystyle \left(\mathbf {J} ^{\mathrm {T} }\mathbf {J} +\lambda \mathbf {I} \right){\boldsymbol {\delta }}=\mathbf {J} ^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right],}](../I/de95bef27493cc5fddb18a6667d3bfbb1d37f02d.svg)
where is the identity matrix, giving as the increment to the estimated parameter vector .

The (non-negative) damping factor is adjusted at each iteration. If reduction of is rapid, a smaller value can be used, bringing the algorithm closer to the Gauss–Newton algorithm, whereas if an iteration gives insufficient reduction in the residual, can be increased, giving a step closer to the gradient-descent direction. Note that the gradient of with respect to equals . Therefore, for large values of , the step will be taken approximately in the direction opposite to the gradient. If either the length of the calculated step or the reduction of sum of squares from the latest parameter vector fall below predefined limits, iteration stops, and the last parameter vector is considered to be the solution.


![{\displaystyle -2\left(\mathbf {J} ^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]\right)^{\mathrm {T} }}](../I/0cd695e6d32730c8c98f8fbc53c5fbb60df71621.svg)
When the damping factor is large relative to , inverting is not necessary, as the update is well-approximated by the small gradient step .


![{\displaystyle \lambda ^{-1}\mathbf {J} ^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right]}](../I/8c712a75de97774308bbdb84544b34ced713ad9d.svg)
To make the solution scale invariant Marquardt's algorithm solved a modified problem with each component of the gradient scaled according to the curvature. This provides larger movement along the directions where the gradient is smaller, which avoids slow convergence in the direction of small gradient. Fletcher in his 1971 paper A modified Marquardt subroutine for non-linear least squares simplified the form, replacing the identity matrix with the diagonal matrix consisting of the diagonal elements of :

![{\displaystyle \left[\mathbf {J} ^{\mathrm {T} }\mathbf {J} +\lambda \operatorname {diag} \left(\mathbf {J} ^{\mathrm {T} }\mathbf {J} \right)\right]{\boldsymbol {\delta }}=\mathbf {J} ^{\mathrm {T} }\left[\mathbf {y} -\mathbf {f} \left({\boldsymbol {\beta }}\right)\right].}](../I/04f27e5c01204646993d90be632921e6c48ca6b8.svg)
A similar damping factor appears in Tikhonov regularization, which is used to solve linear ill-posed problems, as well as in ridge regression, an estimation technique in statistics.
Choice of damping parameter
Various more or less heuristic arguments have been put forward for the best choice for the damping parameter . Theoretical arguments exist showing why some of these choices guarantee local convergence of the algorithm; however, these choices can make the global convergence of the algorithm suffer from the undesirable properties of steepest descent, in particular, very slow convergence close to the optimum.
The absolute values of any choice depend on how well-scaled the initial problem is. Marquardt recommended starting with a value and a factor . Initially setting and computing the residual sum of squares after one step from the starting point with the damping factor of and secondly with . If both of these are worse than the initial point, then the damping is increased by successive multiplication by until a better point is found with a new damping factor of for some .







If use of the damping factor results in a reduction in squared residual, then this is taken as the new value of (and the new optimum location is taken as that obtained with this damping factor) and the process continues; if using resulted in a worse residual, but using resulted in a better residual, then is left unchanged and the new optimum is taken as the value obtained with as damping factor.

An effective strategy for the control of the damping parameter, called delayed gratification, consists of increasing the parameter by a small amount for each uphill step, and decreasing by a large amount for each downhill step. The idea behind this strategy is to avoid moving downhill too fast in the beginning of optimization, therefore restricting the steps available in future iterations and therefore slowing down convergence.[7] An increase by a factor of 2 and a decrease by a factor of 3 has been shown to be effective in most cases, while for large problems more extreme values can work better, with an increase by a factor of 1.5 and a decrease by a factor of 5.[8]
Geodesic acceleration
When interpreting the Levenberg–Marquardt step as the velocity along a geodesic path in the parameter space, it is possible to improve the method by adding a second order term that accounts for the acceleration along the geodesic



where is the solution of

Since this geodesic acceleration term depends only on the directional derivative along the direction of the velocity , it does not require computing the full second order derivative matrix, requiring only a small overhead in terms of computing cost.[9] Since the second order derivative can be a fairly complex expression, it can be convenient to replace it with a finite difference approximation



where and have already been computed by the algorithm, therefore requiring only one additional function evaluation to compute . The choice of the finite difference step can affect the stability of the algorithm, and a value of around 0.1 is usually reasonable in general.[8]




Since the acceleration may point in opposite direction to the velocity, to prevent it to stall the method in case the damping is too small, an additional criterion on the acceleration is added in order to accept a step, requiring that

where is usually fixed to a value lesser than 1, with smaller values for harder problems.[8]

The addition of a geodesic acceleration term can allow significant increase in convergence speed and it is especially useful when the algorithm is moving through narrow canyons in the landscape of the objective function, where the allowed steps are smaller and the higher accuracy due to the second order term gives significant improvements.[8]
Example
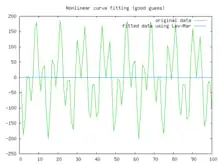
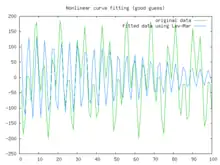
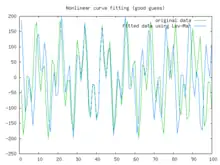
In this example we try to fit the function using the Levenberg–Marquardt algorithm implemented in GNU Octave as the leasqr function. The graphs show progressively better fitting for the parameters , used in the initial curve. Only when the parameters in the last graph are chosen closest to the original, are the curves fitting exactly. This equation is an example of very sensitive initial conditions for the Levenberg–Marquardt algorithm. One reason for this sensitivity is the existence of multiple minima — the function has minima at parameter value and .






See also
- Trust region
- Nelder–Mead method
- Variants of the Levenberg–Marquardt algorithm have also been used for solving nonlinear systems of equations.[10]
References
- Levenberg, Kenneth (1944). "A Method for the Solution of Certain Non-Linear Problems in Least Squares". Quarterly of Applied Mathematics. 2 (2): 164–168. doi:10.1090/qam/10666.
- Marquardt, Donald (1963). "An Algorithm for Least-Squares Estimation of Nonlinear Parameters". SIAM Journal on Applied Mathematics. 11 (2): 431–441. doi:10.1137/0111030. hdl:10338.dmlcz/104299.
- Girard, André (1958). "Excerpt from Revue d'optique théorique et instrumentale". Rev. Opt. 37: 225–241, 397–424.
- Wynne, C. G. (1959). "Lens Designing by Electronic Digital Computer: I". Proc. Phys. Soc. Lond. 73 (5): 777–787. Bibcode:1959PPS....73..777W. doi:10.1088/0370-1328/73/5/310.
- Morrison, David D. (1960). "Methods for nonlinear least squares problems and convergence proofs". Proceedings of the Jet Propulsion Laboratory Seminar on Tracking Programs and Orbit Determination: 1–9.
- Wiliamowski, Bogdan; Yu, Hao (June 2010). "Improved Computation for Levenberg–Marquardt Training" (PDF). IEEE Transactions on Neural Networks and Learning Systems. 21 (6).
- Transtrum, Mark K; Machta, Benjamin B; Sethna, James P (2011). "Geometry of nonlinear least squares with applications to sloppy models and optimization". Physical Review E. APS. 83 (3): 036701. arXiv:1010.1449. Bibcode:2011PhRvE..83c6701T. doi:10.1103/PhysRevE.83.036701. PMID 21517619. S2CID 15361707.
- Transtrum, Mark K; Sethna, James P (2012). "Improvements to the Levenberg-Marquardt algorithm for nonlinear least-squares minimization". arXiv:1201.5885 [physics.data-an].
- "Nonlinear Least-Squares Fitting". GNU Scientific Library. Archived from the original on 2020-04-14.
- Kanzow, Christian; Yamashita, Nobuo; Fukushima, Masao (2004). "Levenberg–Marquardt methods with strong local convergence properties for solving nonlinear equations with convex constraints". Journal of Computational and Applied Mathematics. 172 (2): 375–397. Bibcode:2004JCoAM.172..375K. doi:10.1016/j.cam.2004.02.013.
Further reading
- Moré, Jorge J.; Sorensen, Daniel C. (1983). "Computing a Trust-Region Step" (PDF). SIAM J. Sci. Stat. Comput. 4 (3): 553–572. doi:10.1137/0904038.
- Gill, Philip E.; Murray, Walter (1978). "Algorithms for the solution of the nonlinear least-squares problem". SIAM Journal on Numerical Analysis. 15 (5): 977–992. Bibcode:1978SJNA...15..977G. doi:10.1137/0715063.
- Pujol, Jose (2007). "The solution of nonlinear inverse problems and the Levenberg-Marquardt method". Geophysics. SEG. 72 (4): W1–W16. Bibcode:2007Geop...72W...1P. doi:10.1190/1.2732552.
- Nocedal, Jorge; Wright, Stephen J. (2006). Numerical Optimization (2nd ed.). Springer. ISBN 978-0-387-30303-1.
External links
- Detailed description of the algorithm can be found in Numerical Recipes in C, Chapter 15.5: Nonlinear models
- C. T. Kelley, Iterative Methods for Optimization, SIAM Frontiers in Applied Mathematics, no 18, 1999, ISBN 0-89871-433-8. Online copy
- History of the algorithm in SIAM news
- A tutorial by Ananth Ranganathan
- K. Madsen, H. B. Nielsen, O. Tingleff, Methods for Non-Linear Least Squares Problems (nonlinear least-squares tutorial; L-M code: analytic Jacobian secant)
- T. Strutz: Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). 2nd edition, Springer Vieweg, 2016, ISBN 978-3-658-11455-8.
- H. P. Gavin, The Levenberg-Marquardt method for nonlinear least-squares curve-fitting problems (MATLAB implementation included)
|  Optimization computes maxima and minima. | |||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||