Linguistic performance
The term linguistic performance was used by Noam Chomsky in 1960 to describe "the actual use of language in concrete situations".[1] It is used to describe both the production, sometimes called parole, as well as the comprehension of language.[2] Performance is defined in opposition to "competence"; the latter describes the mental knowledge that a speaker or listener has of language.[3]
| Part of a series on |
| Linguistics |
|---|
|
|
Part of the motivation for the distinction between performance and competence comes from speech errors: despite having a perfect understanding of the correct forms, a speaker of a language may unintentionally produce incorrect forms. This is because performance occurs in real situations, and so is subject to many non-linguistic influences. For example, distractions or memory limitations can affect lexical retrieval (Chomsky 1965:3), and give rise to errors in both production and perception.[4] Such non-linguistic factors are completely independent of the actual knowledge of language,[5] and establish that speakers' knowledge of language (their competence) is distinct from their actual use of language (their performance).[6]
Background
|
Descriptor |
Proponent |
Explication |
|---|---|---|
| Langue/Parole | Ferdinand de Saussure (1916)[7] | Language is a system of signs. Langue describes the social consensus of how signs are applied. Parole describes the physical manifestation of langue. Emphasizes revealing the structure of langue through the study of parole. |
| Competence/Performance | Noam Chomsky (1965)[8] | Introduced in generative grammar theory, competence describes the unconscious and innate knowledge of linguistic rules. Performance describes the observable use of language. Emphasizes the study of competence over performance. |
| I-Language/E-Language | Noam Chomsky (1986)[9] | Similar to the performance/competence distinction, I-Language is the internalized innate knowledge of language; E-Language is the externalized observable output. Emphasizes the study of I-Language over E-Language. |
Langue versus parole
Published in 1916, Ferdinand de Saussure's Course in General Linguistics describes language as "a system of signs that express ideas".[7] de Saussure describes two components of language: langue and parole. Langue consists of the structural relations that define a language, which includes grammar, syntax and phonology. Parole is the physical manifestation of signs; in particular the concrete manifestation of langue as speech or writing. While langue can be viewed strictly as a system of rules, it is not an absolute system such that parole must utterly conform to langue.[10] Drawing an analogy to chess, de Saussure compares langue to the rules of chess that define how the game should be played, and parole to the individual choices of a player given the possible moves allowed within the system of rules.[7]
Competence versus performance
Proposed in the 1950s by Noam Chomsky, generative grammar is an analysis approach to language as a structural framework of the human mind.[11] Through formal analysis of components such as syntax, morphology, semantics and phonology, a generative grammar seeks to model the implicit linguistic knowledge with which speakers determine grammaticality.
In transformational generative grammar theory, Chomsky distinguishes between two components of language production: competence and performance.[5] Competence describes the mental knowledge of a language, the speaker's intrinsic understanding of sound-meaning relations as established by linguistic rules. Performance – that is the actual observed use of language – involves more factors than phonetic-semantic understanding. Performance requires extra-linguistic knowledge such as an awareness of the speaker, audience and the context, which crucially determines how speech is constructed and analyzed. It is also governed by principles of cognitive structures not considered aspects of language, such as memory, distractions, attention, and speech errors.
I-Language versus E-Language
In 1986, Chomsky proposed a distinction similar to the competence/performance distinction, entertaining the notion of an I-Language (internal language) which is the intrinsic linguistic knowledge within a native speaker and E-Language (external language) which is the observable linguistic output of a speaker. It was I-Language that Chomsky argued should be the focus of inquiry, and not E-Language.[9]
E-language has been used to describe the application of artificial systems, such as in calculus, set theory and with natural language viewed as sets, while performance has been used purely to describe applications of natural language.[12] Between I-Language and competence, I-Language refers to our intrinsic faculty for language, competence is used by Chomsky as an informal, general term, or as term with reference to a specific competency such as "grammatical competence" or "pragmatic competence".[12]
Performance-grammar correspondence hypothesis
John A. Hawkins's Performance-Grammar Correspondence Hypothesis (PGCH) states that the syntactic structures of grammars are conventionalized based on whether and how much the structures are preferred in performance.[13] Performance preference is related to structure complexity and processing, or comprehension, efficiency. Specifically, a complex structure refers to a structure containing more linguistic elements or words at the end of the structure than at the beginning. It is this structural complexity that results in decreased processing efficiency since more structure requires additional processing.[13] This model seeks to explain word order across languages based on avoidance of unnecessary complexity in favour of increased processing efficiency. Speakers make an automatic calculation of the Immediate Constituent(IC)-to-word order ratio and produce the structure with the highest ratio.[13] Structures with a high IC-to-word order are structures that contain the fewest words required for the listener to parse the structure into constituents which results in more efficient processing.[13]
Head-initial structures
In head-initial structures, which includes example SVO and VSO word order, the speaker's goal is to order the sentence constituents from least to most complex.
SVO word order
SVO word order can be exemplified with English; consider the example sentences in (1). In (1a) three immediate constituents (ICs) are present in the verb phrase, namely VP, PP1 and PP2, and there are four words (went, to, London, in) required to parse the VP into its constituents. Therefore, the IC-to-word ratio is 3/4=75%. In contrast, in (1b) the VP is still composed of three ICs but there are now six words that are required to determine the constituent structure of the VP (went, in, the, late, afternoon, to). Thus, the ratio for (1b) is 3/6 = 50%. Hawkins proposes that speakers prefer to produce (1a) since it has a higher IC-to-word ratio and this leads to faster and more efficient processing.[13]
1a. John [VP went [PP1 to London] [[PP2 in the late afternoon]] 1b. John [VP went [PP2 in the late afternoon]] [[PP1 to London]]
Hawkins supports the above analysis by providing performance data to demonstrate the preference speakers have for ordering short phrases before long phrases when producing head-initial structures. The table based on English data, below, illustrates that the short prepositional phrase (PP1) is preferentially ordered before the long PP (PP2) and that this preference increases as the size differential between the two PPs increases. For example, 60% of the sentences are ordered short (PP1) to long (PP2) when PP2 was longer than PP1 by 1 word. In contrast, 99% of the sentences are ordered short to long when PP2 is longer than PP1 by 7+ words.
English prepositional phrase orderings by relative weight[13]
| n = 323 | PP2 > PP1 by 1 word | by 2-4 | by 5-6 | by 7+ |
|---|---|---|---|---|
| [V PP1 PP2] | 60% (58) | 86% (108) | 94% (31) | 99% (68) |
| [V PP2 PP1] | 40% (38) | 14% (17) | 6% (2) | 1% (1) |
PP2 = longer PP; PP1=shorter PP. Proportion of short-long to long-short as a percentage; actual numbers of sequences in parentheses. An additional 71 sequences had PPs of equal length (total n=394)
VSO word order
Hawkins argues that the preference for short followed by long phrases applies to all languages that have head-initial structuring. This includes languages with VSO word order such as from Hungarian. By calculating the IC-to-word ratio for the Hungarian sentences in the same way as was done for the English sentences, 2a. emerges as having a higher ratio than 2b.[13]
2a. VP[Döngetik NP[facipöink NP[az utcakat] ]
batter wooden shoes-1PL the streets-ACC
Our wooden shoes batter the streets
2b. VP[Döngetik NP[az utcakat] NP[[ facipöink ] ]
The Hungarian performance data (below) show the same preference pattern as the English data. This study looked at the ordering of two successive noun phrases (NPs) and found that the shorter NP followed by the longer NP is preferred in performance, and that this preference increases as the size differential between NP1 and NP2 increases.
Hungarian noun phrase orderings by relative weight[13]
| n = 85 | mNP2 > mNP1 by 1 word | by 2 | by 3+ |
|---|---|---|---|
| [V mNP1 mNP2] | 85% (50) | 96% (27) | 100% (8) |
| [V mNP2 mNP1] | 15% (9) | 4% (1) | 0% (0) |
mNP = any NP constructed on its left periphery. NP2 = longer NP; NP1 = shorter NP. Proportion of short-long to long-short given as a percentage; actual numbers of sequences given in parentheses. An additional 21 sequences had NPs of equal length (total n = 16).
Head-final structures
Hawkins' explanation of performance and word order extends to head-final structures. For example, since Japanese is a SOV language the head (V) is at the end of the sentence. This theory predicts that speakers will prefer to order the phrases in head-final sentences from long phrases to short, as opposed to short to long as seen in head-initial languages.[13] This reversal of ordering preference is due to the fact that in head-final sentences it is the long followed by short phrasal ordering that has the higher IC-to-word ratio.
3a. Tanaka ga vp[pp[Hanako kara]np[sono hon o] katta]
Tanaka NOM Hanako from that book ACC bought
Tanako bought that book from Hanako
3b. Tanaka ga vp[np[sono hon o] pp[Hanako kara] [katta]
The VP and its constituents in 4. are constructed from their heads on the right. This means that the number of words used to calculate the ratio is counted from the head of the first phrase (PP in 3a. and NP in 3b.) to the verb (as indicated in bold above). The IC-to-word ratio for the VP in 3a. is 3/5=60% while the ratio for the VP in 3b. is 3/4=75%. Therefore, 3b. should be preferred by Japanese speakers since it has a higher IC-to-word ratio which leads to faster parsing of sentences by the listener.[13]
The performance preference for long to short phrase ordering in SVO languages is supported by performance data. The table below shows that production of long to short phrases is preferred and that this preference increases as the size of the differential between the two phrases increases. For example, ordering of the longer 2ICm (where ICm is either a direct object NP with an accusative case particle or a PP constructed from the right periphery) before the shorter 1ICm is more frequent, and the frequency increases to 91% if the 2ICm is longer than the 1ICm by 9+ words.
Japanese NPo and PPm orderings by relative weight[13]
| n = 153 | 2ICm > 1ICm by 1-2 words | by 3-4 | by 5-8 | by 9+ |
|---|---|---|---|---|
| [2ICm 1ICm V] | 66% (59) | 72% (21) | 83% (20) | 91% (10) |
| [1ICm 2ICm V] | 34% (30) | 28% (8) | 17% (4) | 9% (1) |
Npo = direct object NP with accusative case particle. PPm = PP constructed on its right periphery by a P(ostposition). ICm= either NPo or PPm. 2IC=longer IC; 1IC = shorter IC. Proportion of long-to short to short-long orders given as a percentage; actual numbers of sequences in parentheses. an additional 91 sequences had ICs of equal length (total n=244)
Utterance planning hypothesis
Tom Wasow proposes that word order arises as a result of utterance planning benefiting the speaker.[14] He introduces the concepts of early versus late commitment, where commitment is the point in the utterance where it becomes possible to predict subsequent structure.[14] Specifically, early commitment refers to the commitment point present earlier in the utterance and late commitment refers to the commitment point present later in the utterance.[14] He explains that early commitment will favour the listener since early prediction of subsequent structure enables faster processing. Comparatively, late commitment will favour the speaker by postponing decision making, giving the speaker more time to plan the utterance.[14] Wasow illustrates how utterance planning influences syntactic word order by testing early versus late commitment in heavy-NP shifted (HNPS) sentences. The idea is to examine the patterns of HNPS to determine if the performance data show sentences that are structured to favour the speaker or the listener.[14]
Examples of early/late commitment and heavy-NP shift
The following examples illustrate what is meant by early versus late commitment and how heavy-NP shift applies to these sentences. Wasow looked at two types of verbs:[14]
Vt (transitive verbs): require NP objects.
4a. Pat VP[brought NP[a box with a ribbon around it] PP[ [to the party] ]
4b. Pat VP[brought PP[to the party] NP[ [a box with a ribbon around it] ]
In 4a. no heavy-NP shift has been applied. The NP is available early but does not provide any additional information about the sentence structure – the "to" appearing late in the sentence is an example of late commitment. In contrast, in 4b., where heavy-NP shift has shifted the NP to the right, as soon as "to" is uttered the listener knows that the VP must contain the NP and a PP. In other words, when "to" is uttered it allows the listener to predict the remaining structure of the sentence early on. Thus for transitive verbs HNPS results in early commitment and favors the listener.
Vp (prepositional verbs): can take an NP object or an immediately following PP with no NP object
5a. Pat VP[wrote NP[something about Chris] PP[ [on the blackboard]].
5b. Pat VP[wrote PP[on the blackboard] NP[ [something about Chris.]]
No HNPS has been applied to 5a. In 5b. the listener needs to hear the word "something" in order to know that the utterance contains a PP and an NP since the object NP is optional but "something" has been shifted to later in the sentence. Thus for prepositional verbs HNPS results in late commitment and favours the speaker.
Predictions and findings
Based on the above information Wasow predicted that if sentences are constructed from the speaker's perspective then heavy-NP shift would rarely apply to sentences containing a transitive verb but would apply frequently to sentences containing a prepositional verb. The opposite prediction was made if sentences are constructed from the listener's perspective.[14]
| Speaker's Perspective | Listener's Perspective | |
|---|---|---|
| Vt | Heavy-NP shift= rare | Heavy-NP shift= relatively common |
| Vp | Heavy-NP shift= relatively common | Heavy-NP shift =very rare |
To test his predictions Wasow analyzed performance data (from corpora data) for the rates of occurrence of HNPS for Vt and Vp and found HNPS occurred twice as frequently in Vp than in Vt, therefore supporting the predictions made from the speaker's perspective.[14] In contrast, he did not find evidence in support of the predictions made based on the listener's perspective. In other words, given the data above, when HNPS is applied to sentences containing a transitive verb the result favors the listener. Wasow found that HNPS applied to transitive verb sentences is rare in performance data thus supporting the speaker's perspective. Additionally, when HNPS is applied to prepositional verb structures the result favors the speaker. In his study of the performance data, Wasow found evidence of HNPS frequently applied to prepositional verb structures further supporting the speaker's perspective.[14] Based on these findings Wasow concludes that HNPS is correlated with the speaker's preference for late commitment thereby demonstrating how speaker performance preference can influence word order.
Alternative grammar models
While the dominant views of grammar are largely oriented towards competence, many, including Chomsky himself, have argued that a complete model of grammar should be able to account for performance data. But while Chomsky argues that competence should be studied first, thereby allowing further study of performance,[6] some systems, such as constraint grammars are built with performance as a starting point (comprehension, in the case of constraint grammars[15] While traditional models of generative grammar have had a great deal of success in describing the structure of languages, they have been less successful in describing how language is interpreted in real situations. For example, traditional grammar describes a sentence as having an "underlying structure" which is different from the "surface structure" which speakers actually produce. In a real conversation, however, a listener interprets the meaning of a sentence in real time, as the surface structure goes by.[16] This kind of on-line processing, which accounts for phenomena such as finishing another person's sentence, and starting a sentence without knowing how it is going to finish, is not directly accounted for in traditional generative models of grammar.[16] Several alternative grammar models exist which may be better able to capture this surface-based aspect of linguistic performance, including Constraint Grammar, Lexical Functional Grammar, and Head-driven phrase structure grammar.
Errors in linguistic performance
Errors in linguistic performance not only occur in children newly acquiring their native language, second language learners, those with a disability or an acquired brain injury but among competent speakers as well. Types of performance errors that will be of focus here are those that involve errors in syntax, other types of errors can occur in the phonological, semantic features of words, for further information see speech errors. Phonological and semantic errors can be due to the repetition of words, mispronunciations, limitations in verbal working memory, and length of the utterance.[17] Slips of the tongue are most common in spoken languages and occur when the speaker either: says something they did not mean to; produces the incorrect order of sounds or words; or uses the incorrect word.[18] Other instances of errors in linguistic performance are slips of the hand in signed languages, slips of the ear which are errors in comprehension of utterances and slips of the pen which occur while writing. Errors of linguistic performance are perceived by both the speaker and the listener and can therefore have many interpretations depending on the persons judgement and the context in which the sentence was spoken.[19]
It is proposed that there is a close relation between the linguistic units of grammar and the psychological units of speech which implies that there is a relation between linguistic rules and the psychological processes that create utterances.[20] Errors in performance can occur at any level of these psychological processes. Lise Menn proposes that there are five levels of processing in speech production, each with its own possible error that could occur.[18] According to the proposed speech processing structure by Menn an error in the syntactic properties of an utterance occurs at the positional level.
- Message Level
- Functional Level
- Positional Level
- Phonological Encoding
- Speech Gesture
Another proposal for the levels of speech processing is made by Willem J. M. Levelt to be structured as so:[21]
- Conceptualization
- Formulation
- Articulation
- Self-Monitoring
Levelt (1993) states that we as speakers are unaware of most of these levels of performance such as articulation, which includes the movement and placement of the articulators, the formulation of the utterance which includes the words selected and their pronunciation and the rules which must be followed for the utterance to be grammatical. The levels speakers are consciously aware is the intent of the message which occurs at the level of conceptualization and then again at self-monitoring which is when the speaker would become aware of any errors that may have occurred and correct themselves.[21]
Slips of the tongue
One type of slip of the tongue which cause an error in the syntax of the utterance are called transformational errors. Transformational errors are a mental operation proposed by Chomsky in his Transformational Hypothesis and it has three parts which errors in performance can occur. These transformations are applied at the level of the underlying structures and predict the ways in which an error can occur.[20]
- Structural analysis
- Structural Change
- Conditions
Structural Analysis errors can occur due to the application of (a) the rule misanalyzing the tense marker causing the rule to apply incorrectly, (b) the rule not being applied when it should or (c) a rule being applied when it should not.
This example from Fromkin (1980) demonstrates a rule misanalyzing the tense marker and for subject-auxiliary inversion to be incorrectly applied. The subject-auxiliary inversion is misanalyzed as to which structure it applies, applying without the verb be in the tense as it moves to the C position. This causes "do-support" to occur and the verb to lack tense causing the syntactic error.
6a. Error: Why do you be an oaf sometimes?
6b. Target: Why are you an oaf sometimes?

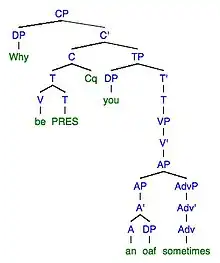
| Transformation in Error | Error | Transformation in Target | Target |
|---|---|---|---|
| Underlying Structure | [CP[C+q][TP[T'[T PRES][VP[DP you][V'[Vbe][[DP an oaf]][AdvP sometimes][DP why] | Underlying Structure | [CP[C'[C+q][TP[T'[T PRES][VP[DP you][V'[V be][DP[D an][[NPoaf]] [AdvPsometimes][DP why] |
| Wh-Movement | [CP[DP Why][C'[C+q][TP[T'[T pres][VP[DP you][V'[V be][AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] | Wh-Movement | [CP[DP Why][C'[C+q][TP[T'[T pres][VP[DP you][V'[V be][AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] |
| Subject-Auxiliary Inversion | [CP[DP Why][C'[C[T Pres][ [Cq e]][TP[T'[T e][VP[DP you][V'[V be][AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] | DP Movement | [CP[DP Why][C'[C+q][TP[DP you][T'[T PRES][VP[V'[V be][AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] |
| Do-Support | [CP[DP Why][C'[C[T[V do][ [T PRES]][ [Cq e]][TP[T'[T e][VP[DP you][V'[V be][AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] | Subject-Auxiliary Inversion | [CP[DP Why][C'[C[T[V be][ [T PRES]]Cq][TP[DP you][T'[T[VP[V'[AP[AP[A'[A an][DP[oaf]]]][AdvP[Adv'[Adv sometimes][DP e] |
| Morphophonemic | Why do you be an oaf sometimes? | Morphophonemic | Why are you an oaf sometimes? |
The following example from Fromkin (1980) demonstrates how a rule is being applied when it should not. The subject-auxiliary inversion rule is omitted in the error utterance, causing affix-hopping to occur and putting the tense onto the verb "say" creating the syntactic error. In the target the subject-auxiliary rule and then do-support applies creating the grammatically correct structure.
7a. Error: And what he said?
7b. Target: And what did he say?


| Transformation in Error | Error | Transformation in Target | Target |
|---|---|---|---|
| Underlying Structure | [CP[CONJ And][CP[C'[C +q][TP[T'[T PAST][VP[DP he][V'[V say][DP what] | Underlying Structure | [CP[CONJ And][CP[C'[C +q][TP[T'[T PAST][VP[DP he][V'[V say][DP what] |
| Wh-Movement | [CP[CONJ And][CP[DP what][C'[C +q][TP[T'[T PAST][VP[DP he][V'[V say][DP e] | DP & Wh-Movement | [CP[CONJ And][CP[DP what][C'[C +q][TP[DP he][T'[T PAST][VP[V'[V say] |
| Affix Hopping | [CP[CONJ And][CP[DP what][C'[C +q][TP[T'[T e][VP[DP he][V'[V say+PAST][DP e] | Subject-Auxiliary Inversion + Do Support | [CP[CONJ And][CP[DP what][C'[C[T[V do][ [T PAST]][ [Cq]][TP[DP he][T'[T e][VP[DP e][V'[V say][DPe] |
| Morphophonemic | And what he said? | Morphophonemic | And what did he say? |
This example from Fromkin (1980) shows how a rule is being applied when it should not. The subject-auxiliary inversion and do-support has applied to an idiomatic expression causing the insertion of "do" when it should not be applied in the ungrammatical utterance.
8a. Error: How do we go!!
8b. Target: How we go!!

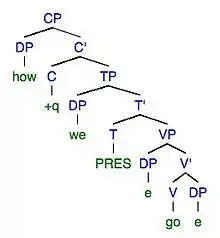
| Transformation in Error | Error | Transformation in Target | Target |
|---|---|---|---|
| Underlying Structure | [CP[C'[C +q][TP[T'[T PRES][VP[DP we][V'[V go][DP how] | Underlying Structure | [CP[C'[C +q][TP[T'[T PRES][VP[DP we][V'[V go][DP how] |
| Wh-Movement | [CP[DP how][C'[C +q][TP[T'[T PRES][VP[DP we][V'[V go][DP e] | Wh-Movement | [CP[DP how][C'[C +q][TP[T'[T PRES][VP[DP we][V'[V go][DP e] |
| DP Movement | [CP[DP how][C'[C +q][TP[DP we][T'[T PRES][VP[DP e][V'[V go][DP e] | DP Movement | [CP[DP how][C'[C +q][TP[DP we][T'[T PRES][VP[DP e][V'[V go][DP e] |
| Subject-Auxiliary Inversion + Do-Support | [CP[DP How][C'[C[T[V do][ [T PRES]][ [Cq]][TP[DP we][T'[T e][VP[DP e][V'[V go][DP e] | [CP[DP how][C'[C +q][TP[DP we][T'[T PRES][VP[DP e][V'[V go][DP e] | |
| Morphophonemic | How do we go! | Morphophonemic | How we go! |
Structural Change Errors can occur in the carrying out of rules, even though the analysis of the phrase marker is done correctly. This can occur when the analysis requires multiple rules to occur.
The following example from Fromkin (1980) shows the relative clause rule copies the determiner phrase "a boy" within the clause and this causes front attaching to the Wh-marker. Deletion is then skipped, leaving the determiner phrase in the clause in the error utterance causing it to be ungrammatical.
9a. Error: A boy who I know a boy has hair down to here.
9b. Target: A boy who I know has hair down to here.

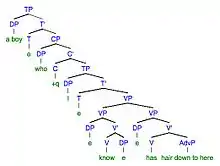
| Transformation in Error | Error | Transformation in Target | Target |
|---|---|---|---|
| Underlying Structure | [TP[T'[Te][CP[C'[C +q][TP[T'[T e][VP[VP[DP I][V'[V know][DP a boy]]][VP[DP who][V'[V has][AdvP hair down to here] | Underlying Structure | [TP[T'[Te][CP[C'[C +q][TP[T'[T e][VP[VP[DP I][V'[V know][DP a boy]]][VP[DP who][V'[V has][AdvP hair down to here] |
| Wh-Movement | [TP[T'[Te][CP[DP who][C'[C +q][TP[T'[T e][VP[VP[DP I][V'[V know][DP a boy]]][VP[DP who][V'[V has][AdvP hair down to here] | Wh-Movement | [TP[T'[Te][CP[DP who][C'[C +q][TP[T'[T e][VP[VP[DP I][V'[V know][DP a boy]]][VP[DP e][V'[V has][AdvP hair down to here] |
| DP-Movement | [TP[DP a boy]][T'[Te][CP[DP who][C'[C +q][TP[DP I][T'[T e][VP[VP[DP e][V'[V know][DP a boy]]][VP[DP e][V'[V has][AdvP hair down to here] | DP-Movement | [TP[DP a boy]][T'[Te][CP[DP who][C'[C +q][TP[DP I][T'[T e][VP[VP[DP e][V'[V know][DP e]]][VP[DP e][V'[V has][AdvP hair down to here] |
| Morphophonemic | A boy who I know a boy has hair down to here | Morphophonemic | A boy who I know has hair down to here |
Conditions errors restrict when the rule can and cannot be applied.
This last example from Fromkin (1980) shows that a rule was applied under a certain condition in which it is restricted. The subject-auxiliary inversion rule cannot apply to embedded clauses. In the case of this example it has causing for the syntactic error.
10a. Error: I know where is a top for it.
10b. Target: I know where a top for it is.

| Transformations in Error | Error | Transformation in Target | Target |
|---|---|---|---|
| Underlying Structure | [TP[T'[T e][VP[DP I][V'[V know][DP where][CP[C'[C e][TP[T'[T PRES][VP[DP a top][V'[PP for it][V be] | Underlying Structure | [TP[T'[T e][VP[DP I][V'[V know][DP where][CP[C'[C e][TP[T'[T PRES][VP[DP a top][V'[PP for it][V be] |
| DP Movement | [TP[DP I][T'[T e][VP[DP e][V'[V know][DP where][CP[C'[C e][TP[DP a top][T'[T PRES][VP[DP e][V'[PP for it][V be] | DP Movement | [TP[DP I][T'[T e][VP[DP e][V'[V know][DP where][CP[C'[C e][TP[DP a top][T'[T PRES][VP[DP e][V'[PP for it][V be] |
| Subject-Auxiliary Inversion | [TP[DP I][T'[T e][VP[DP e][V'[V know][DP where][CP[C'[C[T[V be][ [T PRES]][ [C e]][TP[DP a top][T'[T e][VP[DP e][V'[PP for it][V e] | Affix Hopping | TP[DP I][T'[T e][VP[DP e][V'[V know][DP where][CP[C'[C e][TP[DP a top][T'[T e][VP[DP e][V'[PP for it][V be+PRES] |
| Morphophonemic | I know where is a top for it | Morphophonemic | I know where a top for it is |
A study of deaf Italians found that the second person singular of indicatives would extend to corresponding forms in imperatives and negative imperatives.[22]
| Error | Target |
|---|---|
| "pensi" | "pensa" |
| think-2nd PERS-SG-PRES-IND | think-2nd PERS-SG-IMP |
| "(you) think" | "do think" |
| Error | Target |
|---|---|
| "non fa" | "non fare" |
| not do-2nd PERS-SG-IMP | do-inf |
| "not do" | "do not do" |
The following is an example taken from Dutch data in which there is verb omission in the embedded clause of the utterance (which is not allowed in Dutch), resulting in a performance error.[22]
| Error | Target |
|---|---|
| "dit is de jongen die de tomaat snijdt en dit is de jongen die het brood" | "deze jongen snijdt de tomaat en deze jongen het brood" |
| "this is the boy that cuts the tomato and this is the boy that the bread" | "this boy cuts the tomato and this boy the bread" |
A study done with Zulu speaking children with a language delay displayed errors in linguistic performance of lacking proper passive verb morphology.[22]
| Error | Target |
|---|---|
| "Ulumile ihnashi" | "Ulunywe yihnashi" |
| "U-lum-ile i-hnashi | U-luny-w-e y-i-hnashi |
| sm1-bite-PAST NC5-horse | sm1-bite-PASS-PAST COP-NC5-horse |
| "He bit, the horse did." | "He was bitten by the horse." |
| Error | Target |
|---|---|
| "Ulumile ifish" | "Ulunywe yifish" |
| sm1-bite-PAST NC5-fish | sm1-bite-PASS-PAST COP-NC5-fish |
| "He bit, the fish did." | "He was bitten by the fish." |
Slips of the hand
The linguistic components of American Sign Language (ASL) can be broken down into four parts; the hand configuration, place of articulation, movement and other minor parameters. Hand configuration is determined by the shape of the hand, fingers and thumbs and is specific to the sign that is being used. It allows the signer to articulate what they are wanting to communicate by extending, flexing, bending or spreading the digits; the position of the thumb to the fingers; or the curvature of the hand. However, there are not an infinite amount of possible hand configurations, there are 19 classes of hand configuration primes as listed by the Dictionary of American Sign Language. Place of articulation is the particular location that the sign is being performed known as the "signing place". The "signing place" can be the whole face or a particular part of it, the eyes, nose, cheek, ear, neck, trunk, any part of the arm, or the neutral area in front of the signers head and body. Movement is the most complex as it can be difficult to analyze. Movement is restricted to directional, rotations of the wrist, local movements of the hand and interactions of the hands. These movements can occur singularly, in sequence, or simultaneously. Minor parameters in ASL include contacting region, orientation and hand arrangement. They are subclasses of hand configuration.
Performance errors resulting in ungrammatical signs can result due to processes that change the hand configuration, place, movement or other parameter of the sign. These processes can be anticipation, preservation, or metathesis. Anticipation is caused when some characteristic of the next sign is incorporated into the sign that is presently being performed. Preservation is the opposite of anticipation where some characteristic of the preceding sign is carried over into the performance of the next sign. Metathesis occurs when two characteristics of adjacent signs are combined into one in the performance of both signs.[20] Each of these errors will result in an incorrect sign being performed. This could result in either a different sign being performed instead of the intended one, or nonexistent signs which forms are possible and those which forms are not possible due to the structural rules.[20] These are the main types of performance errors in sign language however on the rare occasion there is also the possibility of errors in the order of the signs performed resulting in a different meaning than what the signer intended.[20]
Other types of errors
Unacceptable Sentences are ones which, although are grammatical, are not considered proper utterances. They are considered unacceptable due to the lack of our cognitive systems to process them. Speakers and listeners can be aided in the performance and processing of these sentences by eliminating time and memory constraints, increasing motivation to process these utterances and using pen and paper.[17] In English there are three types of sentences that are grammatical but are considered unacceptable by speakers and listeners.[17]
- Repeated self-embedded clauses: The cheese that the rat that the cat chased ate is on the table.
- Multi Right Branching: This is the cat that caught the rat that ate the cheese that is on the table.
- Ambiguity or Garden Path Sentences: The horse raced past the barn fell
When a speaker makes an utterance they must translate their ideas into words, then syntactically proper phrases with proper pronunciation.[23] The speaker must have prior world knowledge and an understanding of the grammatical rules that their language enforces. When learning a second language or with children acquiring their first language, speakers usually have this knowledge before they are able to produce them.[23] Their speech is usually slow and deliberate, using phrases they have already mastered, and with practice their skills increase. Errors of linguistic performance are judged by the listener giving many interpretations if an utterance is well-formed or ungrammatical depending on the individual. As well the context in which an utterance is used can determine if the error would be considered or not.[24] When comparing "Who must telephone her?" and "Who need telephone her?" the former would be considered the ungrammatical phrase. However, when comparing it to "Who want telephone her?" it would be considered the grammatical phrase.[24] The listener may also be the speaker. When repeating sentences with errors if the error is not comprehended then it is performed. As well if the speaker does notice the error in the sentence they are supposed to repeat they are unaware of the difference between their well-formed sentence and the ungrammatical sentence.[20] An unacceptable utterance can also be performed due to a brain injury. Three types of brain injuries that could cause errors in performance were studied by Fromkin are dysarthria, apraxia and literal paraphasia. Dysarthria is a defect in the neuromuscular connection that involves speech movement. The speech organs involved can be paralyzed or weakened, making it difficult or impossible for the speaker to produce a target utterance. Apraxia is when there is damage to the ability to initiate speech sounds with no paralysis or weakening of the articulators. Literal paraphasia causes disorganization of linguistic properties, resulting in errors of word order of phonemes.[20] Having a brain injury and being unable to perform proper linguistic utterances, some individuals are still able to process complex sentences and formulate syntactically well formed sentences in their mind.[17] Child productions when they are acquiring language are full of errors of linguistic performance. Children must go from imitating adult speech to create new phrases of their own. They will need to use their cognitive operations of the knowledge of their language they are learning to determine the rules and properties of that language.[23] The following are examples of errors in English speaking children's productions.
- "I goed"
- "He runned"
In an elicited production experiment a child, Adam, was prompted to ask questions to an Old Lady[17]
| Experimenter | Adam, ask the Old Lady what she'll do next. |
| Adam | Old Lady, what will you do now? |
| Old Lady | I'll fly to the moon. |
| Experimenter | Adam, ask the Old Lady why she can't sit down. |
| Adam | Old Lady, why you can't sit down? |
| Old Lady | You haven't given me a chair. |
Performance measures
Mean length of utterance
The most commonly used measure of syntax complexity is the mean length of utterance, also known as MLU.[25] This measure is independent from how often children talk and focuses on the complexity and development of their grammatical systems, including morphological and syntactic development.[26] The number representing a person's MLU corresponds to the complexity of the syntax being used. In general, as the MLU increases, the syntactic complexity also increases. Typically, the average MLU corresponds to a child's age due to their increase in working memory, which allows for sentences to be of greater syntactic complexity.[27] For example, the average MLU of a 7-year-old child is 7 words. However, children show more individual variability of syntactic performance with more complex syntax.[26] Complex syntax have a higher number of phrases and clause levels, therefore adding more words to the overall syntactic structure. Seeing as there are more individual differences in MLU and syntactic development as children get older, MLU is particularly used to measure grammatical complexity among school-aged children.[26] Other types of segmentation strategies for discourse are the T-unit and C-unit (communicative unit). If these two measurements are used to account for discourse, the average length of the sentence will be lower than if MLU is used alone. Both the T-units and C-units count each clause as a new unit, hence a lower number of units.
Typical MLU per age group can be found in the following table, according to Roger Brown's five stages of syntactic and morphological development:[28]
| Stage | MLU | Approximate Age (in months) |
|---|---|---|
| 1 | 1.0-2.0 | 12-26 |
| 2 | 2.0-2.5 | 27-30 |
| 3 | 2.5-3.0 | 31-34 |
| 4 | 3.0-3.75 | 35-40 |
| 5 | 3.75-4.5 | 41-46 |
| 6 | 4.5+ | 47+ |
Here are the steps for calculating MLU:[27]
- Acquire a language sample of about 50-100 utterances
- Count the number of morphemes said by the child, then divide by the number of utterances
- The investigator can assess what stage of syntactic development the child is at, based on their MLU
Here's an example of how to calculate MLU:
| Example utterance | Morpheme and MLU Analysis | Total MLU |
|---|---|---|
| go home now | go (=1) home (=1) now (=1) | 3 |
| I live in Billingham | I (=1) live (=1) in (=1) Billingham (=1) | 4 |
| Mommy kissed my Daddy | Mommy (=1) kiss (=1) -ed (=1) my (=1) daddy (=1) | 5 |
| I like your dogs | I (=1) like (=1) your (=1) dog (=1) -s (=1) | 5 |
In total there are 17 morphemes in this data set. In order to find the MLU, we divide the total number of morphemes (17) by the total number of utterances (4). In this particular data set, the mean length of utterance is 17/4 = 4.25.[29]
Clause density
Clause density refers to the degree to which utterances contain dependent clauses. This density is calculated as a ratio of the total number of clauses across sentences, divide by the number of sentences in a discourse sample.[25] For example, if the clause density is 2.0, the ratio would indicate that the sentence being analyzed has 2 clauses on average: one main clause and one subordinate clause.
Here is an example of how clause density is measured, using T-units, adapted from Silliman & Wilkinson 2007:[30]
| T-unit | Number of words | Number of clauses | Example sentences from a story |
|---|---|---|---|
| 1 | 12 | 2 | When the night was dark I was watching TV in my room |
| 2 | 5 | 1 | I heard a howling noise |
| 3 | 3 | 1 | I looked outside |
Indices of syntactic performance
Indices track structures to show a more comprehensive picture of a person's syntactic complexity. Some examples of indices are Development Sentence Scoring, the Index of Productive Syntax and the Syntactic Complexity Measure.
Developmental sentence scoring
Developmental Sentence Scoring is another method to measure syntactic performance as a clinical tool.[31] In this indice, each consecutive utterance, or sentence, elicited from a child is scored.[32] This is a commonly applied measurement of syntax for first and second language learners, with samples gathered from both elicited and spontaneous oral discourse. Methods for eliciting speech for these samples come in many forms, such having the participant answering questions or re-telling a story. These elicited conversations are commonly tape-recorded for playback during analysis to see how well the person can incorporate syntax among other linguistic cues.[31] For every utterance elicited, the utterance will receive one point if it is a correct form used in adult speech. A score of 1 indicates the least complex syntactic form in the category, whereas a higher score reflects higher level grammaticality.[31] Points are specifically awarded to an utterance based on whether or not it contains any of the eight categories outlined below.[31]
Syntactic categories measured by developmental sentence scoring with examples:
Indefinite pronouns 11a. Score of 1: it, this, that 11b. Score of 6: both, many, several, most, least
Personal pronouns 12a. Score of 1: I, me, my, mine, you, your(s) 12b. Score of 6: Wh-pronouns (i.e. who, which, what, how) and wh-word + infinitive (i.e. I know what to do)
Main verb 13a. Score of 1: Uninflected verb (i.e. I "see" you) and copula, is or 's (i.e. It's red) 13b. Score of 6: Must, shall + verb (i.e. He "must come" or We "shall see"), have + verb + '-en' (i.e. I have eaten)
Secondary verb 14a. Score of 1: Infinitival complements (i.e. I wan"na see" = I want to see) 14b. Score of 6: Gerund (i.e. Swinging is fun)
Negatives 15a. Score of 1: it, this or that + copula or auxiliary 'is' or 's + not (i.e. It's "not" mine) 15b. Score of 5: Uncontracted negative with 'have' (i.e. I have "not" eaten it), auxiliary'have'-negative contraction (i.e. I had"n't" eaten it), pronoun auxiliary 'have' contraction (i.e. I've "not" eaten it)
Conjunctions 16a. Score of 1: and 16b. Score of 6: where, than, how
Interrogative reversals 17a. Score of 1: Reversal of copula (i.e. "Is it" red?) 17b. Score of 5: Reversal with three auxiliaries (i.e. "Could he" have been going?)
Wh-questions 18a. Score of 1: who or what (i.e. "What" do you mean?), what + noun (i.e. "What book" are you reading?) 18b. Score of 5: whose or which (i.e. "Which" do you want?), which + noun (i.e. "Which book" do you want?)
In particular, those categories that appear the earliest in speech receive a lower score, whereas later-appearing categories receive a higher score. If an entire sentence is correct according to adult-like forms, then the utterance would receive an extra point.[31] The eight categories above are the most commonly used structures in syntactic formation, thus structures such as possessives, articles, plurals, prepositional phrases, adverbs and descriptive adjectives were omitted and not scored.[31] Additionally, the scoring system is arbitrary when applied to certain structures. For example, there is no indication as to why "if" would receive four points rather than five. The scores of all the utterances are totalled in the end of the analysis and then averaged to get a final score. This means that the individual's final score reflects their entire syntactic complexity level, rather than syntactic level in a specific category.[31] The main advantage of development sentence scoring is that the final score represents the individual's general syntactic development and allows for easier tracking of changes in language development, making this tool effective for longitudinal studies.[31]
Index of productive syntax
Similar to Development Sentence Scoring, the Index of Productive Syntax evaluates the grammatical complexity of spontaneous language samples. After age 3, Index of Productive Syntax becomes more widely used than MLU to measure syntactic complexity in children.[33] This is because at around age 3, MLU does not distinguish between children of similar language competency as well as Index of Productive Syntax does. For this reason, MLU is initially used in early childhood development to track syntactic ability, then Index of Productive Syntax is used to maintain validity. Individual utterances in a discourse sample are scored based on the presence of 60 different syntactic forms, placed more generally under four subscales: noun phrase, verb phrase, question/negation and sentence structure forms. After a sample is recorded, a corpus is then formed based on 100 utterance transcriptions with 60 different language structures being measured in each utterance. Not included in the corpus are imitations, self-repetitions and routines, which constitute language that does not represent productive language usage.[34] In each of the four sub-scales previously mentioned, the first two unique occurrences of a form are scored. After this, occurrences of a sub-scale are not scored. However, if a child has mastered a complex syntax structure earlier than expected, they will receive extra points.[34]
Standardized tests
The six main tasks in standardized testing for syntax:[25]
- What is the level of syntactic complexity?
- What specific syntactic structures are found? (a syntactic content analysis)
- Are specific structures representative of what is known about syntactic development within the age range of standardization sample?
- What are the processing requirements of the test format? (a task analysis)
- Are processing requirements similar to or different from language processing in more naturalistic contexts?
- Is syntactic ability in naturalistic language predicted by performance on the test?
Some of the common standardized tests for measuring syntactic performance are the TOLD-2 Intermediate (Test of Language Development), the TOAL-2 (Test of Adolescent Language) and the CELF-R (Clinical Evaluation of Language Fundamentals, Revised Screening Test).
| Task being tested | TOLD-2 Intermediate | TOAL-2 | CELF-R |
|---|---|---|---|
| Listening | Grammaticality Judgement (hears 1 sentence: judges correct/incorrect) | Syntactic Paraphrase (hears 3 sentences; marks 2 with similar meaning) | |
| Speaking | Sentence Combining (hears 2-4 sentences, says 1 sentence that combines input sentences) | Sentence Imitation (hears 1 sentence, repeats verbatim) | Formulating Sentences (hears 1-2 words and sees a picture; makes up a sentence using words), Imitating Sentences (hears 1 sentence, repeats verbatim), Scrambled Sentences (hears/sees/reads sentence components out of order; says 2 different recorded/correct versions) |
| Reading | Syntactic paraphrase (read 5 sentences; marks 2 with similar meaning) | ||
| Writing | Sentence combining (reads 2-6 sentences; writes 1 sentence that combines input sentences) |
See also
References
- Matthews, P. H. "performance." Oxford Reference. 30 Oct. 2014. http://www.oxfordreference.com/view/10.1093/acref/9780199202720.001.0001/acref-9780199202720-e-2494.
- Reishaan, Abdul-Hussein Kadhim (2008). "The Relationship between Competence and Performance: Towards a Comprehensive TG Grammar". اداب الكـوفة. 1 (2). Archived from the original on 2014-11-29. Retrieved 2014-11-14.
- Carlson, Marvin (2013), Performance: A Critical Introduction (revised ed.), Routledge, ISBN 9781136498657
- Myers, David G. (December 2011), "8", Psychology (10 ed.), worth publishers, p. 301, ISBN 9781429261784
- Noam Chomsky.(2006).Language and Mind Third Edition. Cambridge University Press. ISBN 0-521-85819-4
- Chomsky, Noam (1965), Aspects of the Theory of Syntax, M.I.T. Press, p. 4, ISBN 0-262-53007-4
- de Saussure, F. (1986). Course in general linguistics (3rd ed.). (R. Harris, Trans.). Chicago: Open Court Publishing Company. (Original work published 1972). p. 9-10, 15, 102.
- Chomsky, Noam (1965). Aspects of the Theory of Syntax. Cambridge: MA: MIT Press.
- Chomsky, Noam (1986).Knowledge of Language. New York:Praeger. ISBN 0-275-90025-8.
- Lacey, Nick (1998). Image and Representation: Key Concepts in Media Studies. Palgrave.
- A Chomsky, Noam (1956). "Three Models for the Description of Language". IRE Transactions on Information Theory 2 (2): 113 123.doi:10.1109/TIT.1956.1056813.
- Smith, Neilson Voyne (1999). Chomsky: Ideas and Ideals. Cambridge University Press. pp. 37–39. ISBN 9780521837880.
- Hawkins, John A. (2004). Efficiency and Complexity in Grammars. Oxford University Press. ISBN 978-0-199-25268-8.
- Wasow, Thomas (2002). Postverbal behavior. Vol. lecture notes, No. 145. Centre for the Study of Language and Information. ISBN 978-1-57586-401-3.
- Karlsson, Fred; Voutilainen, Atro; Heikkilae, Juha; Anttila, Arto (January 1995), Constraint Grammar: A Language-Independent System for Parsing Unrestricted Text, Walter de Gruyter, ISBN 9783110882629
- Sag, I. A. & Wasow, T., 2011. Performance-Compatible Competence Grammar. In: R. Borsley & K. Börjars, eds. Non-Transformational Syntax: Formal and Explicit Models of Grammar. s.l.:John Wiley & Sons, pp. 359-377.
- Stephen Crain; Rosalind Thornton (2000). Investigations in Universal Grammar: A Guide to Experiments on the Acquisition of Syntax and Semantics. MIT Press. ISBN 978-0-262-53180-1.
- Lise Menn (2011). Psycholinguistics: Introduction and Applications. Plural Pub. ISBN 978-1-59756-283-6.
- Montserrat Sanz; Itziar Laka; Michael K. Tanenhaus (29 August 2013). Language Down the Garden Path: The Cognitive and Biological Basis for Linguistic Structures. Oxford University Press. pp. 2–. ISBN 978-0-19-967713-9.
- Victoria Fromkin (1980). Errors in linguistic performance: slips of the tongue, ear, pen, and hand. Academic Press. ISBN 978-0-12-268980-2.
- Willem J. M. Levelt (1993). Speaking: From Intention to Articulation. MIT Press. ISBN 978-0-262-62089-5.
- Elisabetta Fava (2002). Clinical Linguistics: Theory and Applications in Speech Pathology and Therapy. John Benjamins Publishing. pp. 5–. ISBN 1-58811-223-3.
- Michael W. Eysenck; Mark T. Keane (2000). Cognitive Psychology: A Student's Handbook. Taylor & Francis. ISBN 978-0-86377-550-5.
- Montserrat Sanz; Itziar Laka; Michael K. Tanenhaus (29 August 2013). Language Down the Garden Path: The Cognitive and Biological Basis for Linguistic Structures. Oxford University Press. pp. 258–. ISBN 978-0-19-967713-9.
- Scott, CM & Stokes, SL 1995 'Measures of Syntax in School Age Children and Adolescents', Language, Speech & Hearing Services in Schools, vol.56, pp. 309-320
- Huttenlocher, J, Vasilyeva, M, Cymerman, E & Levine, S 2002, 'Language input and child syntax', Cognitive Psychology, vol. 45, pp. 337–374.
- Everyday Language Discovering the Hidden Powers of Speech and Language 2014, Morphology and MLU. Available from: <http://everydaylanguage.qwriting.qc.cuny.edu/2014/03/08/morphology-and-mlu/>. [12 November 2014].
- Brown, R 1973, A first language: The early stages, George Allen & Unwin, London.
- Speech Language Therapy Info 2014, Mean Length of Utterance. Available from: <http://www.sltinfo.com/mean-length-of-utterance/>. [12 November 2014].
- Silliman, ER & Wilkinson, LC 2007, Language and Literacy Learning in Schools. The Guilford Press, New York.
- Rheinhardt, KM 1972, 'The Developmental Sentence Scoring Procedure', Independent Studies and Capstones, vol. 314.
- Politzer, RL, 1974, 'Developmental Sentence Scoring as a Method of Measuring Second Language Acquisition', Modern Language Journal, vol. 58, no. 5/6, pp. 245.
- Lavie, A, Sagae, K, MacWhinney, B, 'Automatic Measurement of Syntactic Development in Child Language', Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pp.197-204.
- Moyle, M & Long, S 2013, 'Index of Productive Syntax (IPSyn)', Encyclopedia of Autism Spectrum Disorders, pp. 1566-1568