Local regression
Local regression or local polynomial regression,[1] also known as moving regression,[2] is a generalization of the moving average and polynomial regression.[3] Its most common methods, initially developed for scatterplot smoothing, are LOESS (locally estimated scatterplot smoothing) and LOWESS (locally weighted scatterplot smoothing), both pronounced /ˈloʊɛs/. They are two strongly related non-parametric regression methods that combine multiple regression models in a k-nearest-neighbor-based meta-model. In some fields, LOESS is known and commonly referred to as Savitzky–Golay filter[4][5] (proposed 15 years before LOESS).
| Part of a series on |
| Regression analysis |
|---|
| Models |
| Estimation |
| Background |
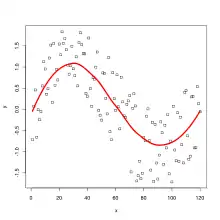
LOESS and LOWESS thus build on "classical" methods, such as linear and nonlinear least squares regression. They address situations in which the classical procedures do not perform well or cannot be effectively applied without undue labor. LOESS combines much of the simplicity of linear least squares regression with the flexibility of nonlinear regression. It does this by fitting simple models to localized subsets of the data to build up a function that describes the deterministic part of the variation in the data, point by point. In fact, one of the chief attractions of this method is that the data analyst is not required to specify a global function of any form to fit a model to the data, only to fit segments of the data.
The trade-off for these features is increased computation. Because it is so computationally intensive, LOESS would have been practically impossible to use in the era when least squares regression was being developed. Most other modern methods for process modeling are similar to LOESS in this respect. These methods have been consciously designed to use our current computational ability to the fullest possible advantage to achieve goals not easily achieved by traditional approaches.
A smooth curve through a set of data points obtained with this statistical technique is called a loess curve, particularly when each smoothed value is given by a weighted quadratic least squares regression over the span of values of the y-axis scattergram criterion variable. When each smoothed value is given by a weighted linear least squares regression over the span, this is known as a lowess curve; however, some authorities treat lowess and loess as synonyms.[6][7]
Model definition
In 1964, Savitsky and Golay proposed a method equivalent to LOESS, which is commonly referred to as Savitzky–Golay filter. William S. Cleveland rediscovered the method in 1979 and gave it a distinct name. The method was further developed by Cleveland and Susan J. Devlin (1988). LOWESS is also known as locally weighted polynomial regression.
At each point in the range of the data set a low-degree polynomial is fitted to a subset of the data, with explanatory variable values near the point whose response is being estimated. The polynomial is fitted using weighted least squares, giving more weight to points near the point whose response is being estimated and less weight to points further away. The value of the regression function for the point is then obtained by evaluating the local polynomial using the explanatory variable values for that data point. The LOESS fit is complete after regression function values have been computed for each of the data points. Many of the details of this method, such as the degree of the polynomial model and the weights, are flexible. The range of choices for each part of the method and typical defaults are briefly discussed next.

Localized subsets of data
The subsets of data used for each weighted least squares fit in LOESS are determined by a nearest neighbors algorithm. A user-specified input to the procedure called the "bandwidth" or "smoothing parameter" determines how much of the data is used to fit each local polynomial. The smoothing parameter, , is the fraction of the total number n of data points that are used in each local fit. The subset of data used in each weighted least squares fit thus comprises the points (rounded to the next largest integer) whose explanatory variables' values are closest to the point at which the response is being estimated.[7]


Since a polynomial of degree k requires at least k + 1 points for a fit, the smoothing parameter must be between and 1, with denoting the degree of the local polynomial.


is called the smoothing parameter because it controls the flexibility of the LOESS regression function. Large values of produce the smoothest functions that wiggle the least in response to fluctuations in the data. The smaller is, the closer the regression function will conform to the data. Using too small a value of the smoothing parameter is not desirable, however, since the regression function will eventually start to capture the random error in the data.
Degree of local polynomials
The local polynomials fit to each subset of the data are almost always of first or second degree; that is, either locally linear (in the straight line sense) or locally quadratic. Using a zero degree polynomial turns LOESS into a weighted moving average. Higher-degree polynomials would work in theory, but yield models that are not really in the spirit of LOESS. LOESS is based on the ideas that any function can be well approximated in a small neighborhood by a low-order polynomial and that simple models can be fit to data easily. High-degree polynomials would tend to overfit the data in each subset and are numerically unstable, making accurate computations difficult.
Weight function
As mentioned above, the weight function gives the most weight to the data points nearest the point of estimation and the least weight to the data points that are furthest away. The use of the weights is based on the idea that points near each other in the explanatory variable space are more likely to be related to each other in a simple way than points that are further apart. Following this logic, points that are likely to follow the local model best influence the local model parameter estimates the most. Points that are less likely to actually conform to the local model have less influence on the local model parameter estimates.
The traditional weight function used for LOESS is the tri-cube weight function,

where d is the distance of a given data point from the point on the curve being fitted, scaled to lie in the range from 0 to 1.[7]
However, any other weight function that satisfies the properties listed in Cleveland (1979) could also be used. The weight for a specific point in any localized subset of data is obtained by evaluating the weight function at the distance between that point and the point of estimation, after scaling the distance so that the maximum absolute distance over all of the points in the subset of data is exactly one.
Consider the following generalisation of the linear regression model with a metric on the target space that depends on two parameters, . Assume that the linear hypothesis is based on input parameters and that, as customary in these cases, we embed the input space into as , and consider the following loss function








Here, is an real matrix of coefficients, and the subscript i enumerates input and output vectors from a training set. Since is a metric, it is a symmetric, positive-definite matrix and, as such, there is another symmetric matrix such that . The above loss function can be rearranged into a trace by observing that . By arranging the vectors and into the columns of a matrix and an matrix respectively, the above loss function can then be written as














where is the square diagonal matrix whose entries are the s. Differentiating with respect to and setting the result equal to 0 one finds the extremal matrix equation




Assuming further that the square matrix is non-singular, the loss function attains its minimum at



A typical choice for is the Gaussian weight

Advantages
As discussed above, the biggest advantage LOESS has over many other methods is the process of fitting a model to the sample data does not begin with the specification of a function. Instead the analyst only has to provide a smoothing parameter value and the degree of the local polynomial. In addition, LOESS is very flexible, making it ideal for modeling complex processes for which no theoretical models exist. These two advantages, combined with the simplicity of the method, make LOESS one of the most attractive of the modern regression methods for applications that fit the general framework of least squares regression but which have a complex deterministic structure.
Although it is less obvious than for some of the other methods related to linear least squares regression, LOESS also accrues most of the benefits typically shared by those procedures. The most important of those is the theory for computing uncertainties for prediction and calibration. Many other tests and procedures used for validation of least squares models can also be extended to LOESS models .
Disadvantages
LOESS makes less efficient use of data than other least squares methods. It requires fairly large, densely sampled data sets in order to produce good models. This is because LOESS relies on the local data structure when performing the local fitting. Thus, LOESS provides less complex data analysis in exchange for greater experimental costs.[7]
Another disadvantage of LOESS is the fact that it does not produce a regression function that is easily represented by a mathematical formula. This can make it difficult to transfer the results of an analysis to other people. In order to transfer the regression function to another person, they would need the data set and software for LOESS calculations. In nonlinear regression, on the other hand, it is only necessary to write down a functional form in order to provide estimates of the unknown parameters and the estimated uncertainty. Depending on the application, this could be either a major or a minor drawback to using LOESS. In particular, the simple form of LOESS can not be used for mechanistic modelling where fitted parameters specify particular physical properties of a system.
Finally, as discussed above, LOESS is a computationally intensive method (with the exception of evenly spaced data, where the regression can then be phrased as a non-causal finite impulse response filter). LOESS is also prone to the effects of outliers in the data set, like other least squares methods. There is an iterative, robust version of LOESS [Cleveland (1979)] that can be used to reduce LOESS' sensitivity to outliers, but too many extreme outliers can still overcome even the robust method.
See also
References
Citations
- Fox & Weisberg 2018, Appendix.
- Harrell 2015, p. 29.
- Garimella 2017.
- "Savitzky–Golay filtering – MATLAB sgolayfilt". Mathworks.com.
- "scipy.signal.savgol_filter — SciPy v0.16.1 Reference Guide". Docs.scipy.org.
- Kristen Pavlik, US Environmental Protection Agency, Loess (or Lowess), Nutrient Steps, July 2016.
- NIST, "LOESS (aka LOWESS)", section 4.1.4.4, NIST/SEMATECH e-Handbook of Statistical Methods, (accessed 14 April 2017)
Sources
- Cleveland, William S. (1979). "Robust Locally Weighted Regression and Smoothing Scatterplots". Journal of the American Statistical Association. 74 (368): 829–836. doi:10.2307/2286407. JSTOR 2286407. MR 0556476.
- Cleveland, William S. (1981). "LOWESS: A program for smoothing scatterplots by robust locally weighted regression". The American Statistician. 35 (1): 54. doi:10.2307/2683591. JSTOR 2683591.
- Cleveland, William S.; Devlin, Susan J. (1988). "Locally-Weighted Regression: An Approach to Regression Analysis by Local Fitting". Journal of the American Statistical Association. 83 (403): 596–610. doi:10.2307/2289282. JSTOR 2289282.
- Fox, John; Weisberg, Sanford (2018). "Appendix: Nonparametric Regression in R" (PDF). An R Companion to Applied Regression (3rd ed.). SAGE. ISBN 978-1-5443-3645-9.
- Friedman, Jerome H. (1984). "A Variable Span Smoother" (PDF). Laboratory for Computational Statistics. LCS Technical Report 5, SLAC PUB-3466. Stanford University.
{{cite journal}}: Cite journal requires|journal=(help) - Garimella, Rao Veerabhadra (22 June 2017). "A Simple Introduction to Moving Least Squares and Local Regression Estimation". doi:10.2172/1367799. OSTI 1367799.
{{cite journal}}: Cite journal requires|journal=(help) - Harrell, Frank E. Jr. (2015). Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. Springer. ISBN 978-3-319-19425-7.
External links
- Local Regression and Election Modeling
- Smoothing by Local Regression: Principles and Methods (PostScript Document)
- NIST Engineering Statistics Handbook Section on LOESS
- Local Fitting Software
- Scatter Plot Smoothing
- R: Local Polynomial Regression Fitting The Loess function in R
- R: Scatter Plot Smoothing The Lowess function in R
- The supsmu function (Friedman's SuperSmoother) in R
- Quantile LOESS – A method to perform Local regression on a Quantile moving window (with R code)
- Nate Silver, How Opinion on Same-Sex Marriage Is Changing, and What It Means – sample of LOESS versus linear regression
Implementations
- Fortran implementation
- C implementation (from the R project)
- Lowess implementation in Cython by Carl Vogel
- Python implementation (in Statsmodels)
- LOESS Smoothing in Excel
- LOESS implementation in pure Julia
- JavaScript implementation
- Java implementation
![]() This article incorporates public domain material from the National Institute of Standards and Technology.
This article incorporates public domain material from the National Institute of Standards and Technology.