Sanger sequencing
Sanger sequencing is a method of DNA sequencing that involves electrophoresis and is based on the random incorporation of chain-terminating dideoxynucleotides by DNA polymerase during in vitro DNA replication. After first being developed by Frederick Sanger and colleagues in 1977, it became the most widely used sequencing method for approximately 40 years. It was first commercialized by Applied Biosystems in 1986. More recently, higher volume Sanger sequencing has been replaced by next generation sequencing methods, especially for large-scale, automated genome analyses. However, the Sanger method remains in wide use for smaller-scale projects and for validation of deep sequencing results. It still has the advantage over short-read sequencing technologies (like Illumina) in that it can produce DNA sequence reads of > 500 nucleotides and maintains a very low error rate with accuracies around 99.99%.[1] Sanger sequencing is still actively being used in efforts for public health initiatives such as sequencing the spike protein from SARS-CoV-2[2] as well as for the surveillance of norovirus outbreaks through the Center for Disease Control and Prevention's (CDC) CaliciNet surveillance network.[3]
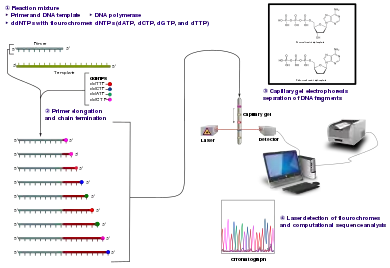
Method
The classical chain-termination method requires a single-stranded DNA template, a DNA primer, a DNA polymerase, normal deoxynucleotide triphosphates (dNTPs), and modified di-deoxynucleotide triphosphates (ddNTPs), the latter of which terminate DNA strand elongation. These chain-terminating nucleotides lack a 3'-OH group required for the formation of a phosphodiester bond between two nucleotides, causing DNA polymerase to cease extension of DNA when a modified ddNTP is incorporated. The ddNTPs may be radioactively or fluorescently labelled for detection in automated sequencing machines.
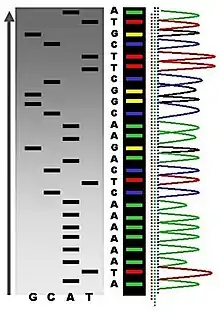
The DNA sample is divided into four separate sequencing reactions, containing all four of the standard deoxynucleotides (dATP, dGTP, dCTP and dTTP) and the DNA polymerase. To each reaction is added only one of the four dideoxynucleotides (ddATP, ddGTP, ddCTP, or ddTTP), while the other added nucleotides are ordinary ones. The deoxynucleotide concentration should be approximately 100-fold higher than that of the corresponding dideoxynucleotide (e.g. 0.5mM dTTP : 0.005mM ddTTP) to allow enough fragments to be produced while still transcribing the complete sequence (but the concentration of ddNTP also depends on the desired length of sequence).[4] Putting it in a more sensible order, four separate reactions are needed in this process to test all four ddNTPs. Following rounds of template DNA extension from the bound primer, the resulting DNA fragments are heat denatured and separated by size using gel electrophoresis. In the original publication of 1977,[4] the formation of base-paired loops of ssDNA was a cause of serious difficulty in resolving bands at some locations. This is frequently performed using a denaturing polyacrylamide-urea gel with each of the four reactions run in one of four individual lanes (lanes A, T, G, C). The DNA bands may then be visualized by autoradiography or UV light, and the DNA sequence can be directly read off the X-ray film or gel image.

In the image on the right, X-ray film was exposed to the gel, and the dark bands correspond to DNA fragments of different lengths. A dark band in a lane indicates a DNA fragment that is the result of chain termination after incorporation of a dideoxynucleotide (ddATP, ddGTP, ddCTP, or ddTTP). The relative positions of the different bands among the four lanes, from bottom to top, are then used to read the DNA sequence.
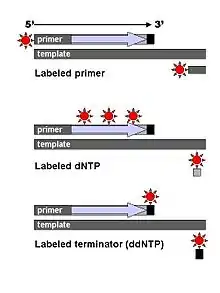
Technical variations of chain-termination sequencing include tagging with nucleotides containing radioactive phosphorus for radiolabelling, or using a primer labeled at the 5' end with a fluorescent dye. Dye-primer sequencing facilitates reading in an optical system for faster and more economical analysis and automation. The later development by Leroy Hood and coworkers[5][6] of fluorescently labeled ddNTPs and primers set the stage for automated, high-throughput DNA sequencing.
Chain-termination methods have greatly simplified DNA sequencing. For example, chain-termination-based kits are commercially available that contain the reagents needed for sequencing, pre-aliquoted and ready to use. Limitations include non-specific binding of the primer to the DNA, affecting accurate read-out of the DNA sequence, and DNA secondary structures affecting the fidelity of the sequence.
Dye-terminator sequencing
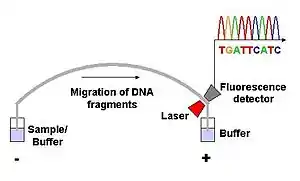
Dye-terminator sequencing utilizes labelling of the chain terminator ddNTPs, which permits sequencing in a single reaction rather than four reactions as in the labelled-primer method. In dye-terminator sequencing, each of the four dideoxynucleotide chain terminators is labelled with fluorescent dyes, each of which emits light at different wavelengths.
Owing to its greater expediency and speed, dye-terminator sequencing is now the mainstay in automated sequencing. Its limitations include dye effects due to differences in the incorporation of the dye-labelled chain terminators into the DNA fragment, resulting in unequal peak heights and shapes in the electronic DNA sequence trace chromatogram after capillary electrophoresis (see figure to the left).
This problem has been addressed with the use of modified DNA polymerase enzyme systems and dyes that minimize incorporation variability, as well as methods for eliminating "dye blobs". The dye-terminator sequencing method, along with automated high-throughput DNA sequence analyzers, was used for the vast majority of sequencing projects until the introduction of next generation sequencing.
Automation and sample preparation

Automated DNA-sequencing instruments (DNA sequencers) can sequence up to 384 DNA samples in a single batch. Batch runs may occur up to 24 times a day. DNA sequencers separate strands by size (or length) using capillary electrophoresis, they detect and record dye fluorescence, and output data as fluorescent peak trace chromatograms. Sequencing reactions (thermocycling and labelling), cleanup and re-suspension of samples in a buffer solution are performed separately, before loading samples onto the sequencer. A number of commercial and non-commercial software packages can trim low-quality DNA traces automatically. These programs score the quality of each peak and remove low-quality base peaks (which are generally located at the ends of the sequence).[7] The accuracy of such algorithms is inferior to visual examination by a human operator, but is adequate for automated processing of large sequence data sets.
Applications of dye-terminating sequencing
The field of public health plays many roles to support patient diagnostics as well as environmental surveillance of potential toxic substances and circulating biological pathogens. Public health laboratories (PHL) and other laboratories around the world have played a pivotal role in providing rapid sequencing data for the surveillance of the virus SARS-CoV-2, causative agent for COVID-19, during the pandemic that was declared a public health emergency on January 30, 2020.[8] Laboratories were tasked with the rapid implementation of sequencing methods and asked to provide accurate data to assist in the decision-making models for the development of policies to mitigate spread of the virus. Many laboratories resorted to next generation sequencing methodologies while others supported efforts with Sanger sequencing. The sequencing efforts of SARS-CoV-2 are many, while most laboratories implemented whole genome sequencing of the virus, others have opted to sequence very specific genes of the virus such as the S-gene, encoding the information needed to produce the spike protein. The high mutation rate of SARS-CoV-2 leads to genetic differences within the S-gene and these differences have played a role in the infectivity of the virus.[9] Sanger sequencing of the S-gene provides a quick, accurate, and more affordable method to retrieving the genetic code. Laboratories in lower income countries may not have the capabilities to implement expensive applications such as next generation sequencing, so Sanger methods may prevail in supporting the generation of sequencing data for surveillance of variants.
Sanger sequencing is also the "gold standard" for norovirus surveillance methods for the Center for Disease Control and Prevention's (CDC) CaliciNet network. CalciNet is an outbreak surveillance network that was established in March 2009. The goal of the network is to collect sequencing data of circulating noroviruses in the United States and activate downstream action to determine the source of infection to mitigate the spread of the virus. The CalciNet network has identified many infections as foodborne illnesses.[3] This data can then be published and used to develop recommendations for future action to prevent tainting food. The methods employed for detection of norovirus involve targeted amplification of specific areas of the genome. The amplicons are then sequenced using dye-terminating Sanger sequencing and the chromatograms and sequences generated are analyzed with a software package developed in BioNumerics. Sequences are tracked and strain relatedness is studied to infer epidemiological relevance.
Challenges
Common challenges of DNA sequencing with the Sanger method include poor quality in the first 15-40 bases of the sequence due to primer binding and deteriorating quality of sequencing traces after 700-900 bases. Base calling software such as Phred typically provides an estimate of quality to aid in trimming of low-quality regions of sequences.[10][11]
In cases where DNA fragments are cloned before sequencing, the resulting sequence may contain parts of the cloning vector. In contrast, PCR-based cloning and next-generation sequencing technologies based on pyrosequencing often avoid using cloning vectors. Recently, one-step Sanger sequencing (combined amplification and sequencing) methods such as Ampliseq and SeqSharp have been developed that allow rapid sequencing of target genes without cloning or prior amplification.[12][13]
Current methods can directly sequence only relatively short (300-1000 nucleotides long) DNA fragments in a single reaction. The main obstacle to sequencing DNA fragments above this size limit is insufficient power of separation for resolving large DNA fragments that differ in length by only one nucleotide.
Microfluidic Sanger sequencing
Microfluidic Sanger sequencing is a lab-on-a-chip application for DNA sequencing, in which the Sanger sequencing steps (thermal cycling, sample purification, and capillary electrophoresis) are integrated on a wafer-scale chip using nanoliter-scale sample volumes. This technology generates long and accurate sequence reads, while obviating many of the significant shortcomings of the conventional Sanger method (e.g. high consumption of expensive reagents, reliance on expensive equipment, personnel-intensive manipulations, etc.) by integrating and automating the Sanger sequencing steps.
In its modern inception, high-throughput genome sequencing involves fragmenting the genome into small single-stranded pieces, followed by amplification of the fragments by polymerase chain reaction (PCR). Adopting the Sanger method, each DNA fragment is irreversibly terminated with the incorporation of a fluorescently labeled dideoxy chain-terminating nucleotide, thereby producing a DNA “ladder” of fragments that each differ in length by one base and bear a base-specific fluorescent label at the terminal base. Amplified base ladders are then separated by capillary array electrophoresis (CAE) with automated, in situ “finish-line” detection of the fluorescently labeled ssDNA fragments, which provides an ordered sequence of the fragments. These sequence reads are then computer assembled into overlapping or contiguous sequences (termed "contigs") which resemble the full genomic sequence once fully assembled.[14]
Sanger methods achieve maximum read lengths of approximately 800 bp (typically 500–600 bp with non-enriched DNA). The longer read lengths in Sanger methods display significant advantages over other sequencing methods especially in terms of sequencing repetitive regions of the genome. A challenge of short-read sequence data is particularly an issue in sequencing new genomes (de novo) and in sequencing highly rearranged genome segments, typically those seen of cancer genomes or in regions of chromosomes that exhibit structural variation.[15]
Applications of microfluidic sequencing technologies
Other useful applications of DNA sequencing include single nucleotide polymorphism (SNP) detection, single-strand conformation polymorphism (SSCP) heteroduplex analysis, and short tandem repeat (STR) analysis. Resolving DNA fragments according to differences in size and/or conformation is the most critical step in studying these features of the genome.[14]
Device design
The sequencing chip has a four-layer construction, consisting of three 100-mm-diameter glass wafers (on which device elements are microfabricated) and a polydimethylsiloxane (PDMS) membrane. Reaction chambers and capillary electrophoresis channels are etched between the top two glass wafers, which are thermally bonded. Three-dimensional channel interconnections and microvalves are formed by the PDMS and bottom manifold glass wafer.
The device consists of three functional units, each corresponding to the Sanger sequencing steps. The thermal cycling (TC) unit is a 250-nanoliter reaction chamber with integrated resistive temperature detector, microvalves, and a surface heater. Movement of reagent between the top all-glass layer and the lower glass-PDMS layer occurs through 500-μm-diameter via-holes. After thermal-cycling, the reaction mixture undergoes purification in the capture/purification chamber, and then is injected into the capillary electrophoresis (CE) chamber. The CE unit consists of a 30-cm capillary which is folded into a compact switchback pattern via 65-μm-wide turns.
Sequencing chemistry
- Thermal cycling
- In the TC reaction chamber, dye-terminator sequencing reagent, template DNA, and primers are loaded into the TC chamber and thermal-cycled for 35 cycles ( at 95 °C for 12 seconds and at 60 °C for 55 seconds).
- Purification
- The charged reaction mixture (containing extension fragments, template DNA, and excess sequencing reagent) is conducted through a capture/purification chamber at 30 °C via a 33-Volts/cm electric field applied between capture outlet and inlet ports. The capture gel through which the sample is driven, consists of 40 μM of oligonucleotide (complementary to the primers) covalently bound to a polyacrylamide matrix. Extension fragments are immobilized by the gel matrix, and excess primer, template, free nucleotides, and salts are eluted through the capture waste port. The capture gel is heated to 67-75 °C to release extension fragments.
- Capillary electrophoresis
- Extension fragments are injected into the CE chamber where they are electrophoresed through a 125-167-V/cm field.
Platforms
The Apollo 100 platform (Microchip Biotechnologies Inc., Dublin, CA)[16] integrates the first two Sanger sequencing steps (thermal cycling and purification) in a fully automated system. The manufacturer claims that samples are ready for capillary electrophoresis within three hours of the sample and reagents being loaded into the system. The Apollo 100 platform requires sub-microliter volumes of reagents.
Comparisons to other sequencing techniques
| Technology | Number of lanes | Injection volume (nL) | Analysis time | Average read length | Throughput (including analysis; Mb/h) | Gel pouring | Lane tracking |
|---|---|---|---|---|---|---|---|
| Slab gel | 96 | 500–1000 | 6–8 hours | 700 bp | 0.0672 | Yes | Yes |
| Capillary array electrophoresis | 96 | 1–5 | 1–3 hours | 700 bp | 0.166 | No | No |
| Microchip | 96 | 0.1–0.5 | 6–30 minutes | 430 bp | 0.660 | No | No |
| 454/Roche FLX (2008) | < 0.001 | 4 hours | 200–300 bp | 20–30 | |||
| Illumina/Solexa (2008) | 2–3 days | 30–100 bp | 20 | ||||
| ABI/SOLiD (2008) | 8 days | 35 bp | 5–15 | ||||
| Illumina MiSeq (2019) | 1–3 days | 2x75–2x300 bp | 170–250 | ||||
| Illumina NovaSeq (2019) | 1–2 days | 2x50–2x150 bp | 22,000–67,000 | ||||
| Ion Torrent Ion 530 (2019) | 2.5–4 hours | 200–600 bp | 110–920 | ||||
| BGI MGISEQ-T7 (2019) | 1 day | 2x150 bp | 250,000 | ||||
| Pacific Biosciences SMRT (2019) | 10–20 hours | 10–30 kb | 1,300 | ||||
| Oxford Nanopore MinIon (2019) | 3 days | 13–20 kb[19] | 700 |
The ultimate goal of high-throughput sequencing is to develop systems that are low-cost, and extremely efficient at obtaining extended (longer) read lengths. Longer read lengths of each single electrophoretic separation, substantially reduces the cost associated with de novo DNA sequencing and the number of templates needed to sequence DNA contigs at a given redundancy. Microfluidics may allow for faster, cheaper and easier sequence assembly.[14]
References
- Shendure J, Ji H (October 2008). "Next-generation DNA sequencing". Nature Biotechnology. 26 (10): 1135–1145. doi:10.1038/nbt1486. PMID 18846087. S2CID 6384349.
- Daniels RS, Harvey R, Ermetal B, Xiang Z, Galiano M, Adams L, McCauley JW (November 2021). "A Sanger sequencing protocol for SARS-CoV-2 S-gene". Influenza and Other Respiratory Viruses. 15 (6): 707–710. doi:10.1111/irv.12892. PMC 8447197. PMID 34346163.
- Vega E, Barclay L, Gregoricus N, Williams K, Lee D, Vinjé J (August 2011). "Novel surveillance network for norovirus gastroenteritis outbreaks, United States". Emerging Infectious Diseases. 17 (8): 1389–1395. doi:10.3201/eid1708.101837. PMC 3381557. PMID 21801614.
- Sanger F, Nicklen S, Coulson AR (December 1977). "DNA sequencing with chain-terminating inhibitors". Proceedings of the National Academy of Sciences of the United States of America. 74 (12): 5463–5467. Bibcode:1977PNAS...74.5463S. doi:10.1073/pnas.74.12.5463. PMC 431765. PMID 271968.
- Smith LM, Sanders JZ, Kaiser RJ, Hughes P, Dodd C, Connell CR, et al. (1986). "Fluorescence detection in automated DNA sequence analysis". Nature. 321 (6071): 674–679. Bibcode:1986Natur.321..674S. doi:10.1038/321674a0. PMID 3713851. S2CID 27800972.
We have developed a method for the partial automation of DNA sequence analysis. Fluorescence detection of the DNA fragments is accomplished by means of a fluorophore covalently attached to the oligonucleotide primer used in enzymatic DNA sequence analysis. A different coloured fluorophore is used for each of the reactions specific for the bases A, C, G and T. The reaction mixtures are combined and co-electrophoresed down a single polyacrylamide gel tube, the separated fluorescent bands of DNA are detected near the bottom of the tube, and the sequence information is acquired directly by computer.
- Smith LM, Fung S, Hunkapiller MW, Hunkapiller TJ, Hood LE (April 1985). "The synthesis of oligonucleotides containing an aliphatic amino group at the 5' terminus: synthesis of fluorescent DNA primers for use in DNA sequence analysis". Nucleic Acids Research. 13 (7): 2399–2412. doi:10.1093/nar/13.7.2399. PMC 341163. PMID 4000959.
- Crossley, Beate M.; Bai, Jianfa; Glaser, Amy; Maes, Roger; Porter, Elizabeth; Killian, Mary Lea; Clement, Travis; Toohey-Kurth, Kathy (November 2020). "Guidelines for Sanger sequencing and molecular assay monitoring". Journal of Veterinary Diagnostic Investigation. 32 (6): 767–775. doi:10.1177/1040638720905833. ISSN 1040-6387. PMC 7649556. PMID 32070230.
- Taylor DB (2021-03-17). "A Timeline of the Coronavirus Pandemic". The New York Times. ISSN 0362-4331. Retrieved 2021-12-05.
- Sanches PR, Charlie-Silva I, Braz HL, Bittar C, Freitas Calmon M, Rahal P, Cilli EM (September 2021). "Recent advances in SARS-CoV-2 Spike protein and RBD mutations comparison between new variants Alpha (B.1.1.7, United Kingdom), Beta (B.1.351, South Africa), Gamma (P.1, Brazil) and Delta (B.1.617.2, India)". Journal of Virus Eradication. 7 (3): 100054. doi:10.1016/j.jve.2021.100054. PMC 8443533. PMID 34548928.
- "Phred - Quality Base Calling". Retrieved 2011-02-24.
- Ledergerber C, Dessimoz C (September 2011). "Base-calling for next-generation sequencing platforms". Briefings in Bioinformatics. 12 (5): 489–497. doi:10.1093/bib/bbq077. PMC 3178052. PMID 21245079.
- Murphy KM, Berg KD, Eshleman JR (January 2005). "Sequencing of genomic DNA by combined amplification and cycle sequencing reaction". Clinical Chemistry. 51 (1): 35–39. doi:10.1373/clinchem.2004.039164. PMID 15514094.
- SenGupta DJ, Cookson BT (May 2010). "SeqSharp: A general approach for improving cycle-sequencing that facilitates a robust one-step combined amplification and sequencing method". The Journal of Molecular Diagnostics. 12 (3): 272–277. doi:10.2353/jmoldx.2010.090134. PMC 2860461. PMID 20203000.
- Kan CW, Fredlake CP, Doherty EA, Barron AE (November 2004). "DNA sequencing and genotyping in miniaturized electrophoresis systems". Electrophoresis. 25 (21–22): 3564–3588. doi:10.1002/elps.200406161. PMID 15565709. S2CID 4851728.
- Morozova O, Marra MA (November 2008). "Applications of next-generation sequencing technologies in functional genomics". Genomics. 92 (5): 255–264. doi:10.1016/j.ygeno.2008.07.001. PMID 18703132.
- Microchip Biologies Inc. Apollo 100
- Sinville R, Soper SA (July 2007). "High resolution DNA separations using microchip electrophoresis". Journal of Separation Science. 30 (11): 1714–1728. doi:10.1002/jssc.200700150. PMID 17623451.
- Kumar KR, Cowley MJ, Davis RL (October 2019). "Next-Generation Sequencing and Emerging Technologies". Seminars in Thrombosis and Hemostasis. 45 (7): 661–673. doi:10.1055/s-0039-1688446. PMID 31096307.
- Tyson JR, O'Neil NJ, Jain M, Olsen HE, Hieter P, Snutch TP (February 2018). "MinION-based long-read sequencing and assembly extends the Caenorhabditis elegans reference genome". Genome Research. 28 (2): 266–274. doi:10.1101/gr.221184.117. PMC 5793790. PMID 29273626.
Further reading
- Dewey FE, Pan S, Wheeler MT, Quake SR, Ashley EA (February 2012). "DNA sequencing: clinical applications of new DNA sequencing technologies". Circulation. 125 (7): 931–944. doi:10.1161/CIRCULATIONAHA.110.972828. PMC 3364518. PMID 22354974.
- Sanger F, Coulson AR, Barrell BG, Smith AJ, Roe BA (October 1980). "Cloning in single-stranded bacteriophage as an aid to rapid DNA sequencing". Journal of Molecular Biology. 143 (2): 161–178. doi:10.1016/0022-2836(80)90196-5. PMID 6260957.