Monte Carlo integration
In mathematics, Monte Carlo integration is a technique for numerical integration using random numbers. It is a particular Monte Carlo method that numerically computes a definite integral. While other algorithms usually evaluate the integrand at a regular grid,[1] Monte Carlo randomly chooses points at which the integrand is evaluated.[2] This method is particularly useful for higher-dimensional integrals.[3]
There are different methods to perform a Monte Carlo integration, such as uniform sampling, stratified sampling, importance sampling, sequential Monte Carlo (also known as a particle filter), and mean-field particle methods.
Overview
In numerical integration, methods such as the trapezoidal rule use a deterministic approach. Monte Carlo integration, on the other hand, employs a non-deterministic approach: each realization provides a different outcome. In Monte Carlo, the final outcome is an approximation of the correct value with respective error bars, and the correct value is likely to be within those error bars.
The problem Monte Carlo integration addresses is the computation of a multidimensional definite integral

where Ω, a subset of Rm, has volume

The naive Monte Carlo approach is to sample points uniformly on Ω:[4] given N uniform samples,

I can be approximated by
- .

This is because the law of large numbers ensures that
- .

Given the estimation of I from QN, the error bars of QN can be estimated by the sample variance using the unbiased estimate of the variance.

which leads to
- .

As long as the sequence

is bounded, this variance decreases asymptotically to zero as 1/N. The estimation of the error of QN is thus

which decreases as . This is standard error of the mean multiplied with . This result does not depend on the number of dimensions of the integral, which is the promised advantage of Monte Carlo integration against most deterministic methods that depend exponentially on the dimension.[5] It is important to notice that, unlike in deterministic methods, the estimate of the error is not a strict error bound; random sampling may not uncover all the important features of the integrand that can result in an underestimate of the error.


While the naive Monte Carlo works for simple examples, an improvement over deterministic algorithms can only be accomplished with algorithms that use problem-specific sampling distributions. With an appropriate sample distribution it is possible to exploit the fact that almost all higher-dimensional integrands are very localized and only small subspace notably contributes to the integral.[6] A large part of the Monte Carlo literature is dedicated in developing strategies to improve the error estimates. In particular, stratified sampling—dividing the region in sub-domains—and importance sampling—sampling from non-uniform distributions—are two examples of such techniques.
Example
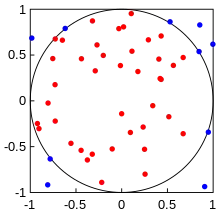
A paradigmatic example of a Monte Carlo integration is the estimation of π. Consider the function

and the set Ω = [−1,1] × [−1,1] with V = 4. Notice that

Thus, a crude way of calculating the value of π with Monte Carlo integration is to pick N random numbers on Ω and compute

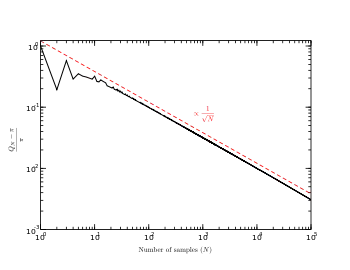
In the figure on the right, the relative error is measured as a function of N, confirming the .

C example
Keep in mind that a true random number generator should be used.
int i, throws = 99999, insideCircle = 0;
double randX, randY, pi;
srand(time(NULL));
for (i = 0; i < throws; ++i) {
randX = rand() / (double) RAND_MAX;
randY = rand() / (double) RAND_MAX;
if (randX * randX + randY * randY < 1) ++insideCircle;
}
pi = 4.0 * insideCircle / throws;
Python example
Made in Python.
from numpy import random
import numpy as np
throws = 2000
inside_circle = 0
i = 0
radius = 1
while i < throws:
# Choose random X and Y centered around 0,0
x = random.uniform(-radius, radius)
y = random.uniform(-radius, radius)
# If the point is inside circle, increase variable
if x**2 + y**2 <= radius**2:
inside_circle += 1
i += 1
# Calculate area and print; should be closer to Pi with increasing number of throws
area = (((2 * radius) ** 2) * inside_circle) / throws
print(area)
Wolfram Mathematica example
The code below describes a process of integrating the function

from using the Monte-Carlo method in Mathematica:

func[x_] := 1/(1 + Sinh[2*x]*(Log[x])^2);
(*Sample from truncated normal distribution to speed up convergence*)
Distrib[x_, average_, var_] := PDF[NormalDistribution[average, var], 1.1*x - 0.1];
n = 10;
RV = RandomVariate[TruncatedDistribution[{0.8, 3}, NormalDistribution[1, 0.399]], n];
Int = 1/n Total[func[RV]/Distrib[RV, 1, 0.399]]*Integrate[Distrib[x, 1, 0.399], {x, 0.8, 3}]
NIntegrate[func[x], {x, 0.8, 3}] (*Compare with real answer*)
Recursive stratified sampling
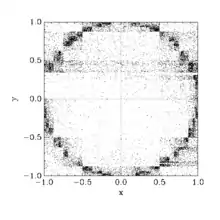

from the above illustration was integrated within a unit square using the suggested algorithm. The sampled points were recorded and plotted. Clearly stratified sampling algorithm concentrates the points in the regions where the variation of the function is largest.
Recursive stratified sampling is a generalization of one-dimensional adaptive quadratures to multi-dimensional integrals. On each recursion step the integral and the error are estimated using a plain Monte Carlo algorithm. If the error estimate is larger than the required accuracy the integration volume is divided into sub-volumes and the procedure is recursively applied to sub-volumes.
The ordinary 'dividing by two' strategy does not work for multi-dimensions as the number of sub-volumes grows far too quickly to keep track. Instead one estimates along which dimension a subdivision should bring the most dividends and only subdivides the volume along this dimension.
The stratified sampling algorithm concentrates the sampling points in the regions where the variance of the function is largest thus reducing the grand variance and making the sampling more effective, as shown on the illustration.
The popular MISER routine implements a similar algorithm.
MISER Monte Carlo
The MISER algorithm is based on recursive stratified sampling. This technique aims to reduce the overall integration error by concentrating integration points in the regions of highest variance.[7]
The idea of stratified sampling begins with the observation that for two disjoint regions a and b with Monte Carlo estimates of the integral and and variances and , the variance Var(f) of the combined estimate





is given by,

It can be shown that this variance is minimized by distributing the points such that,

Hence the smallest error estimate is obtained by allocating sample points in proportion to the standard deviation of the function in each sub-region.
The MISER algorithm proceeds by bisecting the integration region along one coordinate axis to give two sub-regions at each step. The direction is chosen by examining all d possible bisections and selecting the one which will minimize the combined variance of the two sub-regions. The variance in the sub-regions is estimated by sampling with a fraction of the total number of points available to the current step. The same procedure is then repeated recursively for each of the two half-spaces from the best bisection. The remaining sample points are allocated to the sub-regions using the formula for Na and Nb. This recursive allocation of integration points continues down to a user-specified depth where each sub-region is integrated using a plain Monte Carlo estimate. These individual values and their error estimates are then combined upwards to give an overall result and an estimate of its error.
Importance sampling
There are a variety of importance sampling algorithms, such as
Importance sampling algorithm
Importance sampling provides a very important tool to perform Monte-Carlo integration.[3][8] The main result of importance sampling to this method is that the uniform sampling of is a particular case of a more generic choice, on which the samples are drawn from any distribution . The idea is that can be chosen to decrease the variance of the measurement QN.


Consider the following example where one would like to numerically integrate a gaussian function, centered at 0, with σ = 1, from −1000 to 1000. Naturally, if the samples are drawn uniformly on the interval [−1000, 1000], only a very small part of them would be significant to the integral. This can be improved by choosing a different distribution from where the samples are chosen, for instance by sampling according to a gaussian distribution centered at 0, with σ = 1. Of course the "right" choice strongly depends on the integrand.
Formally, given a set of samples chosen from a distribution

the estimator for I is given by[3]

Intuitively, this says that if we pick a particular sample twice as much as other samples, we weight it half as much as the other samples. This estimator is naturally valid for uniform sampling, the case where is constant.
The Metropolis–Hastings algorithm is one of the most used algorithms to generate from ,[3] thus providing an efficient way of computing integrals.
VEGAS Monte Carlo
The VEGAS algorithm approximates the exact distribution by making a number of passes over the integration region which creates the histogram of the function f. Each histogram is used to define a sampling distribution for the next pass. Asymptotically this procedure converges to the desired distribution.[9] In order to avoid the number of histogram bins growing like Kd, the probability distribution is approximated by a separable function:

so that the number of bins required is only Kd. This is equivalent to locating the peaks of the function from the projections of the integrand onto the coordinate axes. The efficiency of VEGAS depends on the validity of this assumption. It is most efficient when the peaks of the integrand are well-localized. If an integrand can be rewritten in a form which is approximately separable this will increase the efficiency of integration with VEGAS. VEGAS incorporates a number of additional features, and combines both stratified sampling and importance sampling.[9]
See also
Notes
- Press et al, 2007, Chap. 4.
- Press et al, 2007, Chap. 7.
- Newman, 1999, Chap. 2.
- Newman, 1999, Chap. 1.
- Press et al, 2007
- MacKay, David (2003). "chapter 4.4 Typicality & chapter 29.1" (PDF). Information Theory, Inference and Learning Algorithms. Cambridge University Press. pp. 284–292. ISBN 978-0-521-64298-9. MR 2012999.
- Press, 1990, pp 190-195.
- Kroese, D. P.; Taimre, T.; Botev, Z. I. (2011). Handbook of Monte Carlo Methods. John Wiley & Sons.
- Lepage, 1978
References
- Caflisch, R. E. (1998). "Monte Carlo and quasi-Monte Carlo methods". Acta Numerica. 7: 1–49. Bibcode:1998AcNum...7....1C. doi:10.1017/S0962492900002804. S2CID 5708790.
- Weinzierl, S. (2000). "Introduction to Monte Carlo methods". arXiv:hep-ph/0006269.
- Press, W. H.; Farrar, G. R. (1990). "Recursive Stratified Sampling for Multidimensional Monte Carlo Integration". Computers in Physics. 4 (2): 190. Bibcode:1990ComPh...4..190P. doi:10.1063/1.4822899.
- Lepage, G. P. (1978). "A New Algorithm for Adaptive Multidimensional Integration". Journal of Computational Physics. 27 (2): 192–203. Bibcode:1978JCoPh..27..192L. doi:10.1016/0021-9991(78)90004-9.
- Lepage, G. P. (1980). "VEGAS: An Adaptive Multi-dimensional Integration Program". Cornell Preprint CLNS 80-447.
- Hammersley, J. M.; Handscomb, D. C. (1964). Monte Carlo Methods. Methuen. ISBN 978-0-416-52340-9.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8.
- Newman, MEJ; Barkema, GT (1999). Monte Carlo Methods in Statistical Physics. Clarendon Press.
- Robert, CP; Casella, G (2004). Monte Carlo Statistical Methods (2nd ed.). Springer. ISBN 978-1-4419-1939-7.
External links
- Café math : Monte Carlo Integration : A blog article describing Monte Carlo integration (principle, hypothesis, confidence interval)
- Boost.Math : Naive Monte Carlo integration: Documentation for the C++ naive Monte-Carlo routines
- Monte Carlo applet applied in statistical physics problems