Moses for Mere Mortals
Moses for Mere Mortals (MMM)[1] is a free open source software composed of a set of scripts designed to allow the automation of processes for the installation and operation of the Moses Open Source Translation System, a statistical machine translation system.
MMM builds a translation chain prototype with Moses + IRSTLM + RandLM + MGIZA.[2][3]
The first version of Moses for Mere Mortals was published in November 2009, and it has been updated and tested on Linux - Ubuntu distributions. MMM is available in the GitHub Project Hosting website.[1]
Overview
Its main aims are to:
- help build a prototype of a translation chain for the real world;
- guide the first steps of users that are just beginning to use Moses;
- enable a simple and quick evaluation of Moses;
- enable the user to do his/her own translations without having to trust third (translating) parties;
- integrate machine translation and translation memories.
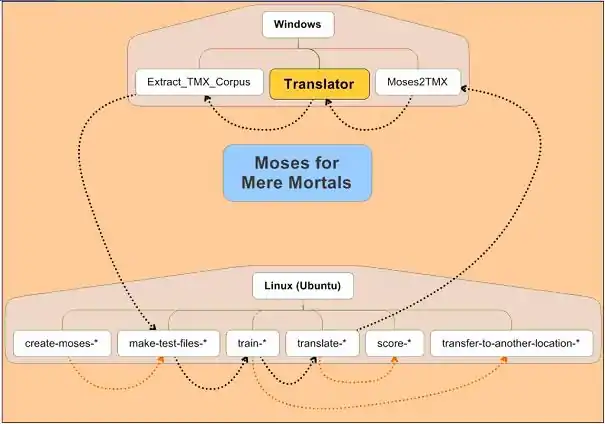
Even though the main thrust is centred on Linux, two Windows add-ins help to make the bridge from Windows to Linux and then back from Linux.
General features
Moses allows the training of corpora where every word is presented together with, for instance, its respective lemma and/or part of speech tag (“factored training”). The scripts do not cover this type of training.
MMM consists of seven scripts for Linux, thoroughly tested with Ubuntu (12.04 and 14.04, 64-bit):
- Install: To install in Ubuntu the packages on which both Moses and Moses for Mere Mortals depend.
- Create: To compile Moses and the other required packages with a single command.
- Make-test-files: To extract from the original corpus a corpus for training, files for tuning and files for testing the training results.
- Train: To train the language pairs needed, as Moses is language-independent and can work with any language/alphabet.
- Translate: To produce machine translations of new documents.
- Score: To automatically evaluate Moses translations against a human translation taken as a gold standard, using BLEU and NIST metrics algorithms, in order to have an idea of the level of performance.
- Transfer training-to-another-location: To transfer engines/trainings to other folders in the same computer or to a different computer.
MMM comes with a 200,000-segment demonstration corpus — which is too small to do justice to the qualitative results achievable with Moses, but capable of giving a realistic view of the relative duration of the steps involved and useful to test whether the installation was correctly done. In order to get good results, one generally needs a corpus with several million segments. Each orthogonal corpus consists of two strictly aligned UTF-8 files, one in the source language and the other in the target language. No grammar knowledge is required, though some language pairs give better results than others. In a general way, morphologically rich languages give worse results.
Add-ins
MMM also contains (for Windows and Linux):
- Extract_TMX_Corpus: An application for the conversion of one or more files in TMX format into two parallel and perfectly aligned files (in the source and target languages) needed for the training of a language pair.
- Moses2TMX: An application to align originals and Moses translations and to package each file in a TMX file with specific attributes so that Moses translations are identified as MT and as having been translated by Moses and can be used with a translation memory tool, with a penalty relative to human memories.
MMM also contains the file Nonbreaking_prefix.pt, a list of abbreviations specific to the Portuguese language, based on English and German versions already available with the Moses package.
Software features
Moses for Mere Mortals also has some original features:
- It removes control characters from the input files (these can crash a training);
- From the corpus, it extracts 2 training files, 2 tuning files and 2 test files (one in the source language and one in the target language) with randomly selected, non-consecutive segments that are erased from the corpus files;
- A new training does not interfere with the files of a previous training;
- A new training reuses, as much as possible, the files created in previous trainings (thus saving time);
- It stops with an informative message if any of the phases of training (language model building, recaser training, corpus training, memory mapping, tuning or training test) doesn’t produce the expected results;
- It can limit the duration of tuning to a specified number of iterations;
- It can generate, in a single step, the BLEU and NIST scores for one translation or a set of translations present in a directory (either for each whole document or for each segment of each document);
- It allows the transfer of corpus trainings to another computer or to another installation in the same computer;
- It allows the mkcls, GIZA and MGIZA parameters to be controlled through parameters in the train script;
- It allows selected parameters in the Moses scripts and the Moses decoder to be controlled through the train and translate scripts.
References
- "moses-for-mere-mortals". GitHub. Retrieved 2014-11-28.
- "Welcome to Moses!". Retrieved 2012-01-29.
- "mosesdecoder". Retrieved 2012-01-29.