NOR flash replacement
While flash memory remains one of the most popular storages in embedded systems because of its non-volatility, shock-resistance, small size, and low energy consumption, its application has grown much beyond its original design. Based on its original design, NOR flash memory is designed to store binary code of programs because it supports XIP (eXecute-In-Place) and high performance in read operations, while NAND flash memory is used as a data storage because of its lower price and higher performance in write/erase operations, compared to NOR flash. In recent years, the price of NAND flash has gone down much faster than that of NOR flash. Thus, to reduce the hardware cost ultimately, using NAND flash to replace NOR flash (motivated by a strong market demand) becomes a new trend in embedded-system designs, especially on mobile phones and arcade games.
Overview
The replacement depends on well-designed management of flash memory, which is carried out by either software on a host system (as a raw medium) or hardware circuits/firmware inside its devices. Here, an efficient prediction mechanism with limited memory-space requirements and an efficient implementation is proposed. The prediction mechanism collects the access patterns of program execution to construct a prediction graph by adopting the working set concept. According to the prediction graph, the prediction mechanism prefetches data (/code) to the SRAM cache, so as to reduce the cache miss rate. Therefore, the performance of the program execution is improved and the read performance gap between NAND and NOR is filled up effectively. Using NAND Flash for boot code requires the use of DRAM to shadow the code.[1]
An effective prefetching strategy
Different from the popular caching ideas in the memory hierarchy, this approach aims at an application-oriented caching mechanism, which adopts prediction-assisted prefetching based on given execution traces of applications. The designs of embedded systems are considered with a limited set of applications, such as a set of selected system programs in mobile phones or arcade games of amusement-park machines. Besides, SRAM capacity and computing power are constrained in the implementation.
Hardware architecture
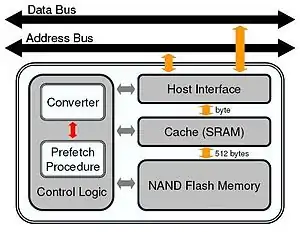
Four essential components are included in the hardware design: host interface, SRAM (cache), NAND flash memory, and control logic. In order to fill up the performance gap between NAND and NOR, SRAM serves as a cache layer for data access over NAND. The host interface is responsible to the communication with the host system via address and data buses. Most importantly, the control logic manages the caching activity and provides the service emulation of NOR flash with NAND flash and SRAM; it must have an intelligent prediction mechanism implemented to improve the system performance. There are two major components in the control logic: The converter emulates NOR flash access over NAND flash with an SRAM cache, where address translation must be done from byte addressing (for NOR) to Logical Block Address (LBA) addressing (for NAND). Note that each 512B/2KB NAND page corresponds to one and four LBA's, respectively. The prefetch procedure tries to prefetch data from NAND to SRAM so that the hit rate of the NOR access is high over SRAM. The procedure should parse and extract the behavior of the target application via a set of collected traces. According to the extracted access patterns from the collected traces, the procedure generates prediction information, referred to as a prediction graph.
Prediction graph
The access pattern of an application execution over NOR (or NAND) consists of a sequence of LBA's. As an application runs for multiple times, the “virtually” complete picture of the possible access pattern of an application execution might appear. Since most application executions are input-dependent or data-driven, there can be more than one subsequent LBA's following a given LBA, where each LBA corresponds to one node in the graph. Nodes with more than one subsequent LBA's are called branch nodes, and the others are called regular nodes. The graph that corresponds to the access patterns is referred to as the prediction graph of the specific application. If pages in NAND flash could be prefetched in an on-time fashion, and there is enough SRAM space for caching, then all data accesses could be done over SRAM.
To save the prediction graph over flash memory with overheads (SRAM capacity) minimized, the subsequent LBA information of each regular node is saved at the spare area of the corresponding page. It is because that the spare area of a page in current implementations has unused space, and the reading of a page usually comes with the reading of its data and spare areas simultaneously. In such a way, the accessing of the subsequent LBA information of a regular node comes with no extra cost. Since a branch node has more than one subsequent LBA's, the spare area of the corresponding page might not have enough free space to store the information. Thus, a branch table is maintained to save the subsequent LBA information of all branch nodes. The starting entry address of the branch table that corresponds to a branch node can be saved at the spare area of the corresponding page. The starting entry records the number of subsequent LBA's of the branch node, and the subsequent LBA's are stored in the entries following the starting entry. The branch table can be saved on flash memory. During the run time, the entire table can be loaded into SRAM for better performance. If there is not enough SRAM space, parts of the table can be loaded in an on-demand fashion.
Prefetch procedure
The objective of the prefetch procedure is to prefetch data from NAND based on a given prediction graph such that most data accesses occur over SRAM. The basic idea is to prefetch data by following the LBA order in the graph. In order to efficiently look up a selected page in the cache, a cyclic queue is adopted in the cache management. Data prefetched from NAND flash is enqueued, while those transferred to the host is dequeued, on the other hand. The prefetch procedure is done in a greedy way: Let P1 be the last prefetched page. If P1 corresponds to a regular node, then the page that corresponds to the subsequent LBA is prefetched. If P1 corresponds to a branch node, then the procedure should prefetch pages by following all possible next LBA links in an equal base and a round-robin way.
2D NAND replacement by 3D NAND
As of 2021, 2D NAND replacement by 3D NAND has commenced.[2] 3D NAND has the advantages of lower cost per bit and the latest controller technology for better reliability. Consequently, even at the low GB level, 3D NAND is the preferred option for code storage.[3][4]