Neural tangent kernel
In the study of artificial neural networks (ANNs), the neural tangent kernel (NTK) is a kernel that describes the evolution of deep artificial neural networks during their training by gradient descent. It allows ANNs to be studied using theoretical tools from kernel methods.
In general, a kernel is a positive-semidefinite symmetric function of two inputs which represents some notion of similarity between the two inputs. The NTK is a specific kernel derived from a given neural network; in general, when the neural network parameters change during training, the NTK evolves as well. However, in the limit of large layer width the NTK becomes constant, revealing a duality between training the wide neural network and kernel methods: gradient descent in the infinite-width limit is fully equivalent to kernel gradient descent with the NTK. As a result, using gradient descent to minimize least-square loss for neural networks yields the same mean estimator as ridgeless kernel regression with the NTK. This duality enables simple closed form equations describing the training dynamics, generalization, and predictions of wide neural networks.
The NTK was introduced in 2018 by Arthur Jacot, Franck Gabriel and Clément Hongler,[1] who used it to study the convergence and generalization properties of fully connected neural networks. Later works[2][3] extended the NTK results to other neural network architectures. In fact, the phenomenon behind NTK is not specific to neural networks and can be observed in generic nonlinear models, usually by a suitable scaling[4].
Main results (informal)
Let denote the scalar function computed by a given neural network with parameters on input . Then the neural tangent kernel is defined[1] as




Since it is written as a dot product between mapped inputs (with the gradient of the neural network function serving as the feature map), we are guaranteed that the NTK is symmetric and positive semi-definite. The NTK is thus a valid kernel function.
Consider a fully connected neural network whose parameters are chosen i.i.d. according to any mean-zero distribution. This random initialization of induces a distribution over whose statistics we will analyze, both at initialization and throughout training (gradient descent on a specified dataset). We can visualize this distribution via a neural network ensemble which is constructed by drawing many times from the initial distribution over and training each draw according to the same training procedure.
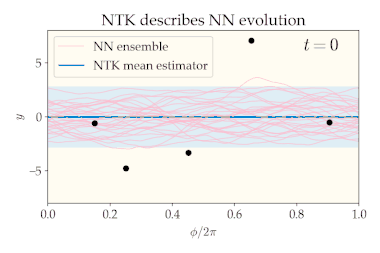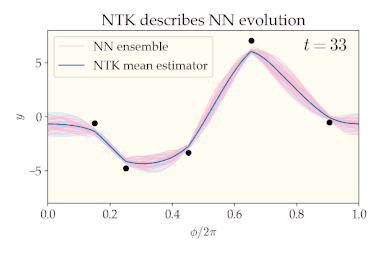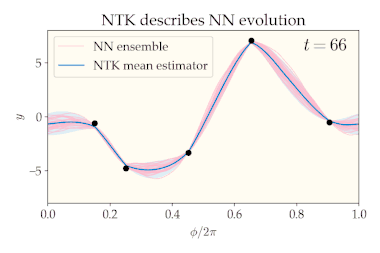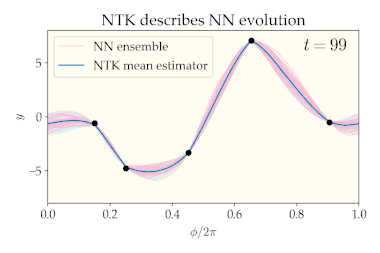
The number of neurons in each layer is called the layer’s width. Consider taking the width of every hidden layer to infinity and training the neural network with gradient descent (with a suitably small learning rate). In this infinite-width limit, several nice properties emerge:
- At initialization (before training), the neural network ensemble is a zero-mean Gaussian process (GP).[5] This means that distribution of functions is the maximum-entropy distribution with mean and covariance , where the GP covariance can be computed from the network architecture. In other words, the distribution of neural network functions at initialization has no structure other than its first and second moments (mean and covariance). This follows from the central limit theorem.
- The NTK is deterministic.[1][6] In other words, the NTK is independent of the random parameter initialization.
- The NTK does not change during training.[1][6]
- Each parameter changes negligibly throughout training. As Lee et al.[6] note, "although individual parameters move by a vanishingly small amount, they collectively conspire to provide a finite change in the final output of the network, as is necessary for training."
- During training, the neural network is linearized, i.e., its parameter dependence can be captured by its first-order Taylor expansion: , where are the initial parameters.[6] This follows from the fact that each parameter changes negligibly during training. (The neural network remains nonlinear with respect to the inputs.)
- The training dynamics are equivalent to kernel gradient descent using the NTK as the kernel.[1] If the loss function is mean-squared error, the final distribution over is still a Gaussian process, but with a new mean and covariance.[1][6] In particular, the mean converges to the same estimator yielded by kernel regression with the NTK as kernel and zero ridge regularization, and the covariance is expressible in terms of the NTK and the initial GP covariance. It can be shown that the ensemble variance vanishes at the training points (in other words, the neural network always interpolates the training data, regardless of initialization).
![{\displaystyle \mathbb {E} _{\theta }[f(x;\theta )]=0}](../I/46ae58ed7aa1d23e3c81c32aa5baf4165309390c.svg)
![{\displaystyle \mathbb {E} _{\theta }[f(x;\theta )f(x';\theta )]=\Sigma (x,x')}](../I/b7dc02a504d58cb034946cfae6929d3efa6a5e44.svg)



Applications
Ridgeless kernel regression and kernel gradient descent
Kernel methods are machine learning algorithms which use only pairwise relations between input points. Kernel methods do not depend on the concrete values of the inputs; they only depend on the relations between the inputs and other inputs (such as the training set). These pairwise relations are fully captured by the kernel function: a symmetric, positive-semidefinite function of two inputs which represents some notion of similarity between the two inputs. A fully equivalent condition is that there exists some feature map such that the kernel function can be written as a dot product of the mapped inputs


The properties of a kernel method depend on the choice of kernel function. (Note that may have higher dimension than .) As a relevant example, consider linear regression. This is the task of estimating given samples generated from , where each is drawn according to some input data distribution. In this setup, is the weight vector which defines the true function ; we wish to use the training samples to develop a model which approximates . We do this by minimizing the mean-square error between our model and the training samples:










There exists an explicit solution for which minimizes the squared error: , where is the matrix whose columns are the training inputs, and is the vector of training outputs. Then, the model can make predictions on new inputs: . However, this result can be rewritten as: .[7] Note that this dual solution is expressed solely in terms of the inner products between inputs. This motivates extending linear regression to settings in which, instead of directly taking inner products between inputs, we first transform the inputs according to a chosen feature map and then evaluate the inner products between the transformed inputs. As discussed above, this can be captured by a kernel function , since all kernel functions are inner products of feature-mapped inputs. This yields the ridgeless kernel regression estimator:







If the kernel matrix is singular, one uses the Moore-Penrose pseudoinverse. The regression equations are called "ridgeless" because they lack a ridge regularization term.

In this view, linear regression is a special case of kernel regression with the identity feature map: . Equivalently, kernel regression is simply linear regression in the feature space (i.e. the range of the feature map defined by the chosen kernel). Note that kernel regression is typically a nonlinear regression in the input space, which is a major strength of the algorithm.

Just as it’s possible to perform linear regression using iterative optimization algorithms such as gradient descent, one can perform kernel regression using kernel gradient descent. This is equivalent to performing gradient descent in the feature space. It’s known that if the weight vector is initialized close to zero, least-squares gradient descent converges to the minimum-norm solution, i.e., the final weight vector has the minimum Euclidean norm of all the interpolating solutions. In the same way, kernel gradient descent yields the minimum-norm solution with respect to the RKHS norm. This is an example of the implicit regularization of gradient descent.
The NTK gives a rigorous connection between the inference performed by infinite-width ANNs and that performed by kernel methods: when the loss function is the least-squares loss, the inference performed by an ANN is in expectation equal to ridgeless kernel regression with respect to the NTK. This suggests that the performance of large ANNs in the NTK parametrization can be replicated by kernel methods for suitably chosen kernels.[1][2]
Overparametrization, interpolation, and generalization
In overparametrized models, the number of tunable parameters exceeds the number of training samples. In this case, the model is able to memorize (perfectly fit) the training data. Therefore, overparametrized models interpolate the training data, achieving essentially zero training error.[8]
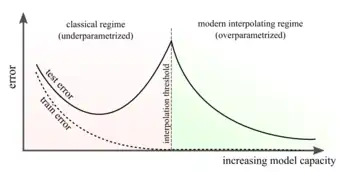
Kernel regression is typically viewed as a non-parametric learning algorithm, since there are no explicit parameters to tune once a kernel function has been chosen. An alternate view is to recall that kernel regression is simply linear regression in feature space, so the “effective” number of parameters is the dimension of the feature space. Therefore, studying kernels with high-dimensional feature maps can provide insights about strongly overparametrized models.
As an example, consider the problem of generalization. According to classical statistics, memorization should cause models to fit noisy signals in the training data, harming their performance on unseen data. To mitigate this, machine learning algorithms often introduce regularization to mitigate noise-fitting tendencies. Surprisingly, modern neural networks (which tend to be strongly overparametrized) seem to generalize well, even in the absence of explicit regularization.[8][9] To study the generalization properties of overparametrized neural networks, one can exploit the infinite-width duality with ridgeless kernel regression. Recent works[10][11][12] have derived equations describing the expected generalization error of high-dimensional kernel regression; these results immediately explain the generalization of sufficiently wide neural networks trained to convergence on least-squares.
Convergence to a global minimum
For a convex loss functional with a global minimum, if the NTK remains positive-definite during training, the loss of the ANN converges to that minimum as . This positive-definiteness property has been shown in a number of cases, yielding the first proofs that large-width ANNs converge to global minima during training.[1][13][14][15][16][17]



Extensions and limitations
The NTK can be studied for various ANN architectures,[2] in particular convolutional neural networks (CNNs),[18] recurrent neural networks (RNNs) and transformers.[19] In such settings, the large-width limit corresponds to letting the number of parameters grow, while keeping the number of layers fixed: for CNNs, this involves letting the number of channels grow.
Individual parameters of a wide neural network in the kernel regime change negligibly during training. However, this implies that infinite-width neural networks cannot exhibit feature learning, which is widely considered to be an important property of realistic deep neural networks. This is not a generic feature of infinite-width neural networks and is largely due to a specific choice of the scaling by which the width is taken to the infinite limit; indeed several works[20][21][22][23] have found alternate infinite-width scaling limits of neural networks in which there is no duality with kernel regression and feature learning occurs during training. Others[24] introduce a "neural tangent hierarchy" to describe finite-width effects, which may drive feature learning.
Neural Tangents is a free and open-source Python library used for computing and doing inference with the infinite width NTK and neural network Gaussian process (NNGP) corresponding to various common ANN architectures.[25] In addition, there exists a scikit-learn compatible implementation of the infinite width NTK for Gaussian processes called scikit-ntk.[26]
Details
When optimizing the parameters of an ANN to minimize an empirical loss through gradient descent, the NTK governs the dynamics of the ANN output function throughout the training.


Case 1: Scalar output
An ANN with scalar output consists of a family of functions parametrized by a vector of parameters .

The NTK is a kernel defined by


In the language of kernel methods, the NTK is the kernel associated with the feature map . To see how this kernel drives the training dynamics of the ANN, consider a dataset with scalar labels and a loss function . Then the associated empirical loss, defined on functions , is given by







When the ANN is trained to fit the dataset (i.e. minimize ) via continuous-time gradient descent, the parameters evolve through the ordinary differential equation:



During training the ANN output function follows an evolution differential equation given in terms of the NTK:

This equation shows how the NTK drives the dynamics of in the space of functions during training.


Case 2: Vector output
An ANN with vector output of size consists in a family of functions parametrized by a vector of parameters .


In this case, the NTK is a matrix-valued kernel, with values in the space of matrices, defined by



Empirical risk minimization proceeds as in the scalar case, with the difference being that the loss function takes vector inputs . The training of through continuous-time gradient descent yields the following evolution in function space driven by the NTK:



This generalizes the equation shown in case 1 for scalar outputs.
Interpretation
The NTK represents the influence of the loss gradient with respect to example on the evolution of ANN output through a gradient descent step: in the scalar case, this reads





In particular, each data point influences the evolution of the output for each throughout the training, in a way that is captured by the NTK .

Wide fully-connected ANNs have a deterministic NTK, which remains constant throughout training
Consider an ANN with fully-connected layers of widths , so that , where is the composition of an affine transformation with the pointwise application of a nonlinearity , where parametrizes the maps . The parameters are initialized randomly, in an independent, identically distributed way.







As the widths grow, the NTK's scale is affected by the exact parametrization of the 's and by the parameter initialization. This motivates the so-called NTK parametrization . This parametrization ensures that if the parameters are initialized as standard normal variables, the NTK has a finite nontrivial limit. In the large-width limit, the NTK converges to a deterministic (non-random) limit , which stays constant in time.


The NTK is explicitly given by , where is determined by the set of recursive equations:



where denotes the kernel defined in terms of the Gaussian expectation:

![{\displaystyle L_{K}^{f}\left(x,y\right)=\mathbb {E} _{\left(X,Y\right)\sim {\mathcal {N}}\left(0,{\begin{pmatrix}K\left(x,x\right)&K\left(x,y\right)\\K\left(y,x\right)&K\left(y,y\right)\end{pmatrix}}\right)}\left[f\left(X\right)f\left(Y\right)\right].}](../I/5369807a8bd0710580946867a70de133c1acde07.svg)
In this formula the kernels are the ANN's so-called activation kernels.[27][28][5]

Wide fully connected networks are linear in their parameters throughout training
The NTK describes the evolution of neural networks under gradient descent in function space. Dual to this perspective is an understanding of how neural networks evolve in parameter space, since the NTK is defined in terms of the gradient of the ANN's outputs with respect to its parameters. In the infinite width limit, the connection between these two perspectives becomes especially interesting. The NTK remaining constant throughout training at large widths co-occurs with the ANN being well described throughout training by its first order Taylor expansion around its parameters at initialization:[6]

References
- Jacot, Arthur; Gabriel, Franck; Hongler, Clement (2018), Bengio, S.; Wallach, H.; Larochelle, H.; Grauman, K. (eds.), "Neural Tangent Kernel: Convergence and Generalization in Neural Networks" (PDF), Advances in Neural Information Processing Systems 31, Curran Associates, Inc., pp. 8571–8580, arXiv:1806.07572, retrieved 2019-11-27
- Arora, Sanjeev; Du, Simon S.; Hu, Wei; Li, Zhiyuan; Salakhutdinov, Ruslan; Wang, Ruosong (2019-11-04). "On Exact Computation with an Infinitely Wide Neural Net". arXiv:1904.11955 [cs.LG].
- Yang, Greg (2020-11-29). "Tensor Programs II: Neural Tangent Kernel for Any Architecture". arXiv:2006.14548 [stat.ML].
- Chizat, Lénaïc; Oyallon, Edouard; Bach, Francis (2019-12-08), "On lazy training in differentiable programming", Proceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA: Curran Associates Inc., pp. 2937–2947, arXiv:1812.07956, retrieved 2023-05-11
- Lee, Jaehoon; Bahri, Yasaman; Novak, Roman; Schoenholz, Samuel S.; Pennington, Jeffrey; Sohl-Dickstein, Jascha (2018-02-15). "Deep Neural Networks as Gaussian Processes".
{{cite journal}}: Cite journal requires|journal=(help) - Lee, Jaehoon; Xiao, Lechao; Schoenholz, Samuel S.; Bahri, Yasaman; Novak, Roman; Sohl-Dickstein, Jascha; Pennington, Jeffrey (2020). "Wide neural networks of any depth evolve as linear models under gradient descent". Journal of Statistical Mechanics: Theory and Experiment. 2020 (12): 124002. arXiv:1902.06720. Bibcode:2020JSMTE2020l4002L. doi:10.1088/1742-5468/abc62b. S2CID 62841516.
- Shawe-Taylor, John; Cristianini, Nello (2004-06-28). Kernel Methods for Pattern Analysis. Cambridge University Press. doi:10.1017/cbo9780511809682. ISBN 978-0-521-81397-6.
- Belkin, Mikhail (2021-05-29). "Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation". arXiv:2105.14368 [stat.ML].
- Novak, Roman; Bahri, Yasaman; Abolafia, Daniel A.; Pennington, Jeffrey; Sohl-Dickstein, Jascha (2018-02-15). "Sensitivity and Generalization in Neural Networks: an Empirical Study". arXiv:1802.08760 [stat.ML].
- Jacot, Arthur; Şimşek, Berfin; Spadaro, Francesco; Hongler, Clément; Gabriel, Franck (2020-06-17). "Kernel Alignment Risk Estimator: Risk Prediction from Training Data". arXiv:2006.09796 [stat.ML].
- Canatar, Abdulkadir; Bordelon, Blake; Pehlevan, Cengiz (2021-05-18). "Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks". Nature Communications. 12 (1): 2914. arXiv:2006.13198. Bibcode:2021NatCo..12.2914C. doi:10.1038/s41467-021-23103-1. ISSN 2041-1723. PMC 8131612. PMID 34006842.
- Simon, James B.; Dickens, Madeline; Karkada, Dhruva; DeWeese, Michael R. (2022-10-12). "The Eigenlearning Framework: A Conservation Law Perspective on Kernel Regression and Wide Neural Networks". arXiv:2110.03922 [cs.LG].
- Allen-Zhu, Zeyuan; Li, Yuanzhi; Song, Zhao (2018). "A convergence theory for deep learning via overparameterization". arXiv:1811.03962 [cs.LG].
- Du, Simon S; Zhai, Xiyu; Poczos, Barnabas; Aarti, Singh (2019). "Gradient descent provably optimizes over-parameterized neural networks". arXiv:1810.02054 [cs.LG].
- Zou, Difan; Cao, Yuan; Zhou, Dongruo; Gu, Quanquan (2020). "Gradient descent optimizes over-parameterized deep ReLU networks". Machine Learning. 109 (3): 467–492. doi:10.1007/s10994-019-05839-6. S2CID 53752874.
- Allen-Zhu, Zeyuan; Li, Yuanzhi; Song, Zhao (2019-05-27). "On the Convergence Rate of Training Recurrent Neural Networks". arXiv:1810.12065 [cs.LG].
- Du, Simon; Lee, Jason; Li, Haochuan; Wang, Liwei; Zhai, Xiyu (2019-05-24). "Gradient Descent Finds Global Minima of Deep Neural Networks". pp. 1675–1685. arXiv:1811.03804 [cs.LG].
- Yang, Greg (2019-02-13). "Scaling Limits of Wide Neural Networks with Weight Sharing: Gaussian Process Behavior, Gradient Independence, and Neural Tangent Kernel Derivation". arXiv:1902.04760 [cs.NE].
- Hron, Jiri; Bahri, Yasaman; Sohl-Dickstein, Jascha; Novak, Roman (2020-06-18). "Infinite attention: NNGP and NTK for deep attention networks". arXiv:2006.10540 [stat.ML].
- Mei, Song; Montanari, Andrea; Nguyen, Phan-Minh (2018-08-14). "A mean field view of the landscape of two-layer neural networks". Proceedings of the National Academy of Sciences. 115 (33): E7665–E7671. arXiv:1804.06561. Bibcode:2018PNAS..115E7665M. doi:10.1073/pnas.1806579115. ISSN 0027-8424. PMC 6099898. PMID 30054315.
- Chizat, Lénaïc; Bach, Francis (2018-12-03). "On the global convergence of gradient descent for over-parameterized models using optimal transport". Proceedings of the 32nd International Conference on Neural Information Processing Systems. NIPS'18. Red Hook, NY, USA: Curran Associates Inc.: 3040–3050. arXiv:1805.09545.
- Nguyen, Phan-Minh; Pham, Huy Tuan (2020-01-30). "A Rigorous Framework for the Mean Field Limit of Multilayer Neural Networks". arXiv:2001.11443 [cs.LG].
- Yang, Greg; Hu, Edward J. (2022-07-15). "Feature Learning in Infinite-Width Neural Networks". arXiv:2011.14522 [cs.LG].
- Huang, Jiaoyang; Yau, Horng-Tzer (2019-09-17). "Dynamics of Deep Neural Networks and Neural Tangent Hierarchy". arXiv:1909.08156 [cs.LG].
- Novak, Roman; Xiao, Lechao; Hron, Jiri; Lee, Jaehoon; Alemi, Alexander A.; Sohl-Dickstein, Jascha; Schoenholz, Samuel S. (2019-12-05), "Neural Tangents: Fast and Easy Infinite Neural Networks in Python", International Conference on Learning Representations (ICLR), vol. 2020, arXiv:1912.02803, Bibcode:2019arXiv191202803N
- Lencevicius, Ronaldas Paulius (2022). "An Empirical Analysis of the Laplace and Neural Tangent Kernels". arXiv:2208.03761 [stat.ML].
- Cho, Youngmin; Saul, Lawrence K. (2009), Bengio, Y.; Schuurmans, D.; Lafferty, J. D.; Williams, C. K. I. (eds.), "Kernel Methods for Deep Learning" (PDF), Advances in Neural Information Processing Systems 22, Curran Associates, Inc., pp. 342–350, retrieved 2019-11-27
- Daniely, Amit; Frostig, Roy; Singer, Yoram (2016), Lee, D. D.; Sugiyama, M.; Luxburg, U. V.; Guyon, I. (eds.), "Toward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual View on Expressivity" (PDF), Advances in Neural Information Processing Systems 29, Curran Associates, Inc., pp. 2253–2261, arXiv:1602.05897, Bibcode:2016arXiv160205897D, retrieved 2019-11-27