ObjectDatabase++
ObjectDatabase++ (ODBPP) is an embeddable object-oriented database designed for server applications that require minimal external maintenance. It is written in C++ as a real-time ISAM level database with the ability to auto recover from system crashes while maintaining database integrity. Its unique transaction process allows for maintenance of both the indexes and tables, preventing double allocation of index entries that could prohibit rollback of transactions.
| Developer(s) | Ekky Software |
|---|---|
| Stable release | |
| Written in | C++, C#, VB.NET & TScript |
| Operating system | Windows & Linux |
| Type | Object database |
| License | Proprietary[2] |
| Website | www |
Features of ODBPP include: full multi-process and multi-thread transaction control, auto real-time database recovery, hierarchical object data design, native code and script access, static hash index on object IDs, numerous supported index methods including full-text and biometric pattern matching.
History
- The initial development was implemented by Ekky Software from 2001 to 2003.
- It took 4 complete rewrites of the database before testing confirmed it matched specifications and functioned as designed.
- Over the last decade numerous product enhancements have enabled far greater index and data support.
Hierarchical data objects
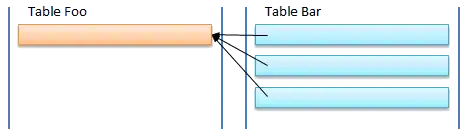
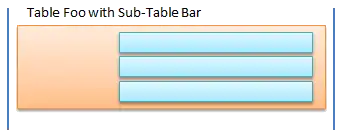
ODBPP supports objects that are hierarchical in design,[3][4] similar to XML, JSON or serialized PHP. It is this hierarchical object that separates object databases from their relational cousins and it is the process of keeping the entire object in one record rather than spreading it out over multiple tables that give object databases the distinction from the relational model.
Traditional relational design
Traditionally databases have been designed with the relational model. This would separate data over several tables and use a common identifier to relate all the child records back to their parent. These model was based on each row within the table containing individual pieces of data. SQL databases based on this design would create joins that would reconnect the entire relation back together, suffering performance limitations.[5]
Object-database design
In the object database design, instead of using multiple tables to store a data object, it is stored in one a single record. This keeps the entire object intact and reducing the need to join the data back together. This process of storing the entire object in one table reduces the total amount to lock, reads and write operations required. It is also this ability to store an object in one record that reduce the amount of file reads and writes, which enables the object design to maintain efficiency with very large and very complex database designs.
Looking at the images to the right, the on above depicts the relational model and has the data spread over two tables, with the parent in amber and the children in blue. In the object model, both the parent and children are stored in the one data record, the information that was previously stored within the related table is now stored within the sub or nested table of Foo.
Multi-process transaction control
ODBPP implements a transaction control that allows for process to continue while another is terminated. This unique transaction control allows the continuing process to identify the terminated transaction, recover database integrity and continue mid transaction. It is this ability to terminate transaction at any point that enables real-time transactions implementation by server using the method.
The transaction control utilizes four separate file to implement the entire process and flushed each change of state to the drive before continuing to the next state. This creates a time consuming process where each individual write to a file has three separate states and the entire transaction is required to pass through three separate files. Initially all adds, edit and deletes are written a shared memory file, this enables all transaction to know if a resource, such as an index value has been allocated. This memory file can be destroy when the OS starts without interfering with the database integrity, and is only used for IPC purposes.
Once a transaction call the commit transaction method, the database then does the bulk of the work and writes the entire transaction from the memory file to the log file. This is done through a three stages process, first is to identify what changes are needed, then it flushed those plans to the rear of the file, once written to the drive, the header is updated to indicate the presences of the update. Secondly the file is then updated, before finally the header is modified to finalized the update. This state process ensure the consistency of the file is always valid because if the process ceases during the first stage, the file is simply truncated and the file is returned to the original state and if the transaction ceases during the second stage, the next transaction the opens the file, identifies the saved plans and re-executes those saved instructions.
Each of the four files in updated in this manner. The transaction starts in the memory file, before been written in one update to the log file, once the transaction has the protection with the transaction secured in the log file, the ODBMS then able to update the index and table files. The entire commit process can be executed concurrently with multiple transactions committing simultaneously and is greatly benefited by using a solid-state drive, although the process of caching the entire transaction in the memory file and only committing to the drive at the end does help reduce the entire transaction time and is comparable to non-flushing DBMS.
Supported indexes
Contrary to some of the earlier object database models,[6][7] as an ISAM level database ODBPP supports a large variety of indexes. During the initial development of the object model, the basic design was to use a schema that contained only a serialized binary object that was referred to by its ID and provided no other index access. This prevented basic search on labels and so on, and was done due to the fact that the underlining architecture was still based on the related model. Since ODBPP was always designed with the object model, it understands the hierarchical nature of the objects and is capable of indexing on data contained within.
Static hash index
All objects within the database are referenced by their object identifier which is itself managed via a static hash index. A static hash index is simply an array index where the location containing the address of the object is deduced by taking the ID value, multiplying it by 12 and adding an offset value. This reveals the location of the physical address of the object. This method translating the ID into its physical address enables true order one (O(1)) retrieval of data, regardless of how many objects are stored within the database.
Imposing the static has index on all table schemata allows for real-time compaction of the file, as object locks are on the index and not the object itself. This than allows for even locked objects to be moved within the file by other transactions that require more space or are deleting objects from the file. This ability to move objects within the file at any time also imposes the need to access the via the index,[8] while SQL databases may scan through all records by scanning the file from beginning to the end, the real-time compaction prohibits this style of access.
B+ tree indexes
The B+ tree index is the primary workhorse of all databases and ODBPP is no exception. The majority of searches are carried out via seeking an index position than repetitively call for the next largest value. ODBPP supports a large number of filters on the B+ Tree to make the results more usable. For example, it can be set to convert all lower case characters to upper case, or set for the removal white spaces or non-alphanumerical characters, and also provide a natural sort order where '9' is before '10'.
One of the features of ODBPP over the standard DBMS is that data stored within hierarchical object can also be indexed. This will then create a situation where there are 0…n index values created for any one object.
Spatial & temporal indexes
Spatial indexes are used to allow searching on both two- and three-dimensional coordinates spaces. Temporal indexes are a similar idea along a one dimensional of time.
Biometric pattern matching
ODBPP also supports sets of spatial data that represent key points of both two and three dimension objects such as finger print or human faces. These sets are indexed via a Spatial index which allow for group searching. The search itself will create a temporary index that has as many objects that have at least the search pattern or more points within a given error.
Full-text searching
ODBPP provides full text indexing via the token list indexes. These indexes are a combination of the B+ Tree and an bucket overflow, where a text string is broken up into its individual tokens and indexed into a B+ Tree and since multiple object will have the same token value, the ID is stored in a bucket overflow (similar to dynamic hashing. With this design, full text searches are done by scanning through all tokens in the B+ Tree leaves and identifying which tokens fit the search criteria and retrieving the matching IDs.
The full text search query also provide set logic functions to reduce the search results to a number that is usable. It allow the user to search of objects that contain token A and not token B for example.
Example implementation
Interface basics
ODBPP has been designed to function in both a procedural style and encapsulated object C++ style. Although the object style still uses the procedural method to interface with the database at the low level, in the example the procedural method is demonstrated.
Native example
class Foo {
public:
enum { TableID = 1};
unsigned int ParentID; // id to link to this objects parent
unsigned int Flags[4]; // 0x01 – has parent
enum {
Name,//the label given to the Foo object
Description//a description of Foo
};
} *fooObject;
CODBPP database;
CODBPP::Object object;
unsigned int error;
char16_t *fooName = TEXT("FooName"), *message, buffer[128];
if ((error = database.OpenDatabase(TEXT("C:\\Path\\To\\Database.odc"))) == NO_ERROR
&& (error = database.BeginTransaction()) == NO_ERROR
&& (error = database.OpenTable(Foo::TableID)) == NO_ERROR
&& (error = database.ReadObject(Foo::TableID, CODBPP::EQUALTO, &object, 1, fooName)) == NO_ERROR){
fooObject = (Foo*)object.fixed;
swprintf_s(buffer, __countof(buffer), TEXT("Parent = %d, Flags = %d"), fixedObject->ParentID, fooObject->Flags[0]);
MessageBox(buffer);
}
if (error && database.GetErrorMessage(&message) == NO_ERROR)
MessageBox(message);
database.EndTransaction();
TScript example
The equivalent TScript example of reading an object from the database that has the name "FooName" is as follows.
#include "ODBPP.ts"
public main(variable parameters = null : Structure results) {
ODBPP database;
ODBPP.Object objectHandle;
database.OpenDatabase(L"c:\\Path\\To\\Database.odc");
database.BeginTransaction();
database.OpenTable(1);
database.ReadIndex(1,CODBPP.EQUALTO,1,L"FooName": objectHandle);
database.FragmentObject(1,objectHandle:results);
System::MessageBox(L"Parent = "+results.ParentID+L", Flags = "+results.Flags);
}
C# example
ObjectDatabase++ is also exposed via COM wrapper class 'ODBPPLib.ODBPP'. The equivalent C# example of reading an object from the database that has the name "FooName" is as follows.
private void button1_Click(object sender, EventArgs e) {
try {
ODBPPLib.ODBPP odbpp = new ODBPPLib.ODBPP();
odbpp.OpenDatabase(@"C:\Path\To\Database.odc");
odbpp.BeginTransaction(odbpp.SHARED, 6000);
odbpp.OpenTable(1);
ODBPPLib.DatabaseObject results = odbpp.ReadObject(1, odbpp.EQUALTO, 1, "FooName");
if (results != null)
MessageBox.Show("Parent = " + results.readField("ParentID") + ", Flags = " + results.readField("Flags"));
}
catch (Exception e1) {
MessageBox.Show(e1.Message);
}
}
References
- Ekky Software Archived 2012-09-29 at the Wayback Machine
- "Ekky Software Sales". Archived from the original on 2013-08-21. Retrieved 2013-08-02.
- Khoualdi, K, & Alghamdi, T 2011, 'Developing Systems by Using Object Oriented Database Practical Study on ISO 9001:2000 System', Journal of Software Engineering & Applications, 4, 12, pp. 666–671, Computers & Applied Sciences Complete
- Naser, T, Alhajj, R, & Ridley, M 2009, 'Two-Way Mapping between Object-Oriented Databases and XML', Informatica (03505596), 33, 3, pp. 297–308, Computers & Applied Sciences Complete
- Suri, P, & Sharma, M 2011, 'A COMPARATIVE STUDY BETWEEN THE PERFORMANCE OF RELATIONAL & OBJECT ORIENTED DATABASE IN DATA WAREHOUSING', International Journal of Database Management Systems, 3, 2, pp. 116–127, Computers & Applied Sciences Complete
- Hardwick, M, Samaras, G, 1989, 'Using a relational database as an index to a distributed object database in engineering design systems ', Data and Knowledge Systems for Manufacturing and Engineering, 1989., Second International Conference on Date of Conference: 16-18 Oct 1989
- Zhang, F, Ma, Z, & Yan, L 2011, 'Construction of ontologies from object-oriented database models', Integrated Computer-Aided Engineering, 18, 4, pp. 327–347, Computers & Applied Sciences Complete
- Lee, K.C.K; Hong Va Leong; Si, A. 2003, 'Approximating object location for moving object database', Distributed Computing Systems Workshops, 2003. Proceedings. 23rd International Conference on Date of Conference: 19–22 May 2003.