Ordinal data
Ordinal data is a categorical, statistical data type where the variables have natural, ordered categories and the distances between the categories are not known.[1]: 2 These data exist on an ordinal scale, one of four levels of measurement described by S. S. Stevens in 1946. The ordinal scale is distinguished from the nominal scale by having a ranking.[2] It also differs from the interval scale and ratio scale by not having category widths that represent equal increments of the underlying attribute.[3]
Examples of ordinal data
A well-known example of ordinal data is the Likert scale. An example of a Likert scale is:[4]: 685
| Like | Like Somewhat | Neutral | Dislike Somewhat | Dislike |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
Examples of ordinal data are often found in questionnaires: for example, the survey question "Is your general health poor, reasonable, good, or excellent?" may have those answers coded respectively as 1, 2, 3, and 4. Sometimes data on an interval scale or ratio scale are grouped onto an ordinal scale: for example, individuals whose income is known might be grouped into the income categories $0–$19,999, $20,000–$39,999, $40,000–$59,999, ..., which then might be coded as 1, 2, 3, 4, .... Other examples of ordinal data include socioeconomic status, military ranks, and letter grades for coursework.[5]
Ways to analyse ordinal data
Ordinal data analysis requires a different set of analyses than other qualitative variables. These methods incorporate the natural ordering of the variables in order to avoid loss of power.[1]: 88 Computing the mean of a sample of ordinal data is discouraged; other measures of central tendency, including the median or mode, are generally more appropriate.[6]
General
Stevens (1946) argued that, because the assumption of equal distance between categories does not hold for ordinal data, the use of means and standard deviations for description of ordinal distributions and of inferential statistics based on means and standard deviations was not appropriate. Instead, positional measures like the median and percentiles, in addition to descriptive statistics appropriate for nominal data (number of cases, mode, contingency correlation), should be used.[3]: 678 Nonparametric methods have been proposed as the most appropriate procedures for inferential statistics involving ordinal data (e.g, Kendall's W, Spearman's rank correlation coefficient, etc.), especially those developed for the analysis of ranked measurements.[5]: 25–28 However, the use of parametric statistics for ordinal data may be permissible with certain caveats to take advantage of the greater range of available statistical procedures.[7][8][4]: 90
Univariate statistics
In place of means and standard deviations, univariate statistics appropriate for ordinal data include the median,[9]: 59–61 other percentiles (such as quartiles and deciles),[9]: 71 and the quartile deviation.[9]: 77 One-sample tests for ordinal data include the Kolmogorov-Smirnov one-sample test,[5]: 51–55 the one-sample runs test,[5]: 58–64 and the change-point test.[5]: 64–71
Bivariate statistics
In lieu of testing differences in means with t-tests, differences in distributions of ordinal data from two independent samples can be tested with Mann-Whitney,[9]: 259–264 runs,[9]: 253–259 Smirnov,[9]: 266–269 and signed-ranks[9]: 269–273 tests. Test for two related or matched samples include the sign test[5]: 80–87 and the Wilcoxon signed ranks test.[5]: 87–95 Analysis of variance with ranks[9]: 367–369 and the Jonckheere test for ordered alternatives[5]: 216–222 can be conducted with ordinal data in place of independent samples ANOVA. Tests for more than two related samples includes the Friedman two-way analysis of variance by ranks[5]: 174–183 and the Page test for ordered alternatives.[5]: 184–188 Correlation measures appropriate for two ordinal-scaled variables include Kendall's tau,[9]: 436–439 gamma,[9]: 442–443 rs,[9]: 434–436 and dyx/dxy.[9]: 443
Regression applications
Ordinal data can be considered as a quantitative variable. In logistic regression, the equation
![{\displaystyle \operatorname {logit} [P(Y=1)]=\alpha +\beta _{1}c+\beta _{2}x}](../I/15e1051682796c9cafeafacdab93b80ec9f8d189.svg)
is the model and c takes on the assigned levels of the categorical scale.[1]: 189 In regression analysis, outcomes (dependent variables) that are ordinal variables can be predicted using a variant of ordinal regression, such as ordered logit or ordered probit.
In multiple regression/correlation analysis, ordinal data can be accommodated using power polynomials and through normalization of scores and ranks.[10]
Linear trends
Linear trends are also used to find associations between ordinal data and other categorical variables, normally in a contingency tables. A correlation r is found between the variables where r lies between -1 and 1. To test the trend, a test statistic:

is used where n is the sample size.[1]: 87
R can be found by letting be the row scores and be the column scores. Let be the mean of the row scores while . Then is the marginal row probability and is the marginal column probability. R is calculated by:







Classification methods
Classification methods have also been developed for ordinal data. The data are divided into different categories such that each observation is similar to others. Dispersion is measured and minimized in each group to maximize classification results. The dispersion function is used in information theory.[11]
Statistical models for ordinal data
There are several different models that can be used to describe the structure of ordinal data.[12] Four major classes of model are described below, each defined for a random variable , with levels indexed by .


Note that in the model definitions below, the values of and will not be the same for all the models for the same set of data, but the notation is used to compare the structure of the different models.


Proportional odds model
The most commonly-used model for ordinal data is the proportional odds model, defined by where the parameters describe the base distribution of the ordinal data, are the covariates and are the coefficients describing the effects of the covariates.
![{\displaystyle \log \left[{\frac {\Pr(Y\leq k)}{Pr(Y>k)}}\right]=\log \left[{\frac {\Pr(Y\leq k)}{1-\Pr(Y\leq k)}}\right]=\mu _{k}+\mathbf {\beta } ^{T}\mathbf {x} }](../I/14e7c49dcb389c4232e1e48a11492ff360a3199c.svg)

This model can be generalized by defining the model using instead of , and this would make the model suitable for nominal data (in which the categories have no natural ordering) as well as ordinal data. However, this generalization can make it much more difficult to fit the model to the data.


Baseline category logit model
The baseline category model is defined by
![{\displaystyle \log \left[{\frac {\Pr(Y=k)}{\Pr(Y=1)}}\right]=\mu _{k}+\mathbf {\beta } _{k}^{T}\mathbf {x} }](../I/553b20d7f329b07553d6d749b2bc912a7c5e0130.svg)
This model does not impose an ordering on the categories and so can be applied to nominal data as well as ordinal data.
Ordered stereotype model
The ordered stereotype model is defined by where the score parameters are constrained such that .
![{\displaystyle \log \left[{\frac {\Pr(Y=k)}{\Pr(Y=1)}}\right]=\mu _{k}+\phi _{k}\mathbf {\beta } ^{T}\mathbf {x} }](../I/68c2a9a4e022ca873d39ec9f34c9398158d7e085.svg)

This is a more parsimonious, and more specialised, model than the baseline category logit model: can be thought of as similar to .


The non-ordered stereotype model has the same form as the ordered stereotype model, but without the ordering imposed on . This model can be applied to nominal data.

Note that the fitted scores, , indicate how easy it is to distinguish between the different levels of . If then that indicates that the current set of data for the covariates do not provide much information to distinguish between levels and , but that does not necessarily imply that the actual values and are far apart. And if the values of the covariates change, then for that new data the fitted scores and might then be far apart.





Adjacent categories logit model
The adjacent categories model is defined by although the most common form, referred to in Agresti (2010)[12] as the "proportional odds form" is defined by
![{\displaystyle \log \left[{\frac {\Pr(Y=k)}{\Pr(Y=k+1)}}\right]=\mu _{k}+\mathbf {\beta } _{k}^{T}\mathbf {x} }](../I/8612e5d7aafe4bb7b9efd3d142406127cae40303.svg)
![{\displaystyle \log \left[{\frac {\Pr(Y=k)}{\Pr(Y=k+1)}}\right]=\mu _{k}+\mathbf {\beta } ^{T}\mathbf {x} }](../I/d713e4d22bcee41130e326b21cc841b39b03490a.svg)
This model can only be applied to ordinal data, since modelling the probabilities of shifts from one category to the next category implies that an ordering of those categories exists.
The adjacent categories logit model can be thought of as a special case of the baseline category logit model, where . The adjacent categories logit model can also be thought of as a special case of the ordered stereotype model, where , i.e. the distances between the are defined in advance, rather than being estimated based on the data.


Comparisons between the models
The proportional odds model has a very different structure to the other three models, and also a different underlying meaning. Note that the size of the reference category in the proportional odds model varies with , since is compared to , whereas in the other models the size of the reference category remains fixed, as is compared to or .





Different link functions
There are variants of all the models that use different link functions, such as the probit link or the complementary log-log link.
Visualization and display
Ordinal data can be visualized in several different ways. Common visualizations are the bar chart or a pie chart. Tables can also be useful for displaying ordinal data and frequencies. Mosaic plots can be used to show the relationship between an ordinal variable and a nominal or ordinal variable.[13] A bump chart—a line chart that shows the relative ranking of items from one time point to the next—is also appropriate for ordinal data.[14]
Color or grayscale gradation can be used to represent the ordered nature of the data. A single-direction scale, such as income ranges, can be represented with a bar chart where increasing (or decreasing) saturation or lightness of a single color indicates higher (or lower) income. The ordinal distribution of a variable measured on a dual-direction scale, such as a Likert scale, could also be illustrated with color in a stacked bar chart. A neutral color (white or gray) might be used for the middle (zero or neutral) point, with contrasting colors used in the opposing directions from the midpoint, where increasing saturation or darkness of the colors could indicate categories at increasing distance from the midpoint.[15] Choropleth maps also use color or grayscale shading to display ordinal data.[16]
.jpg.webp) Example bar plot of opinion on defense spending. |
 Example bump plot of opinion on defense spending by political party. |
 Example mosaic plot of opinion on defense spending by political party. |
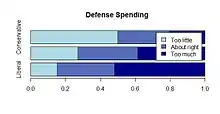 Example stacked bar plot of opinion on defense spending by political party. |
Applications
The use of ordinal data can be found in most areas of research where categorical data are generated. Settings where ordinal data are often collected include the social and behavioral sciences and governmental and business settings where measurements are collected from persons by observation, testing, or questionnaires. Some common contexts for the collection of ordinal data include survey research;[17][18] and intelligence, aptitude, personality testing and decision-making.[2][4]: 89–90
Calculation of 'Effect Size' (Cliff's Delta d) using ordinal data has been recommended as a measure of statistical dominance.[19]
See also
References
- Agresti, Alan (2013). Categorical Data Analysis (3 ed.). Hoboken, New Jersey: John Wiley & Sons. ISBN 978-0-470-46363-5.
- Ataei, Younes; Mahmoudi, Amin; Feylizadeh, Mohammad Reza; Li, Deng-Feng (January 2020). "Ordinal Priority Approach (OPA) in Multiple Attribute Decision-Making". Applied Soft Computing. 86: 105893. doi:10.1016/j.asoc.2019.105893. ISSN 1568-4946. S2CID 209928171.
- Stevens, S. S. (1946). "On the Theory of Scales of Measurement". Science. New Series. 103 (2684): 677–680. Bibcode:1946Sci...103..677S. doi:10.1126/science.103.2684.677. PMID 17750512.
- Cohen, Ronald Jay; Swerdik, Mark E.; Phillips, Suzanne M. (1996). Psychological Testing and Assessment: An Introduction to Tests and Measurement (3rd ed.). Mountain View, CA: Mayfield. pp. 685. ISBN 1-55934-427-X.
- Siegel, Sidney; Castellan, N. John Jr. (1988). Nonparametric Statistics for the Behavioral Sciences (2nd ed.). Boston: McGraw-Hill. pp. 25–26. ISBN 0-07-057357-3.
- Jamieson, Susan (December 2004). "Likert scales: how to (ab)use them" (PDF). Medical Education. 38 (12): 1212–1218. doi:10.1111/j.1365-2929.2004.02012.x. PMID 15566531. S2CID 42509064.
- Sarle, Warren S. (Sep 14, 1997). "Measurement theory: Frequently asked questions".
- van Belle, Gerald (2002). Statistical Rules of Thumb. New York: John Wiley & Sons. pp. 23–24. ISBN 0-471-40227-3.
- Blalock, Hubert M. Jr. (1979). Social Statistics (Rev. 2nd ed.). New York: McGraw-Hill. ISBN 0-07-005752-4.
- Cohen, Jacob; Cohen, Patricia (1983). Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences (2nd ed.). Hillsdale, New Jersey: Lawrence Erlbaum Associates. p. 273. ISBN 0-89859-268-2.
- Laird, Nan M. (1979). "A Note on Classifying Ordinal-Scale Data". Sociological Methodology. 10: 303–310. doi:10.2307/270775. JSTOR 270775.
- Agresti, Alan (2010). Analysis of Ordinal Categorical Data (2nd ed.). Hoboken, New Jersey: Wiley. ISBN 978-0470082898.
- "Plotting Techniques".
- Berinato, Scott (2016). Good Charts: The HBR Guide to Making Smarter, More Persuasive Data Visualizations. Boston: Harvard Business Review Press. p. 228. ISBN 978-1633690707.
- Kirk, Andy (2016). Data Visualisation: A Handbook for Data Driven Design (1st ed.). London: SAGE. p. 269. ISBN 978-1473912144.
- Cairo, Alberto (2016). The Truthful Art: Data, Charts, and Maps for Communication (1st ed.). San Francisco: New Riders. p. 280. ISBN 978-0321934079.
- Alwin, Duane F. (2010). Marsden, Peter V.; Wright, James D. (eds.). Assessing the Reliability and Validity of Survey Measures. p. 420. ISBN 978-1-84855-224-1.
{{cite book}}:|work=ignored (help)CS1 maint: location (link) - Fowler, Floyd J. Jr. (1995). Improving Survey Questions: Design and Evaluation. Thousand Oaks, CA: Sage. pp. 156–165. ISBN 0-8039-4583-3.
- Cliff, Norman (November 1993). "Dominance statistics: Ordinal analyses to answer ordinal questions". Psychological Bulletin. 114 (3): 494–509. doi:10.1037/0033-2909.114.3.494. ISSN 1939-1455.
Further reading
- Agresti, Alan (2010). Analysis of Ordinal Categorical Data (2nd ed.). Hoboken, New Jersey: Wiley. ISBN 978-0470082898.