Overlap–save method
In signal processing, overlap–save is the traditional name for an efficient way to evaluate the discrete convolution between a very long signal and a finite impulse response (FIR) filter :
![x[n]](../I/864cbbefbdcb55af4d9390911de1bf70167c4a3d.svg)
![h[n]](../I/89981bbbb05ffd469eeadb828c18359965985e46.svg)
-
(Eq.1)
![{\displaystyle y[n]=x[n]*h[n]\ \triangleq \ \sum _{m=-\infty }^{\infty }h[m]\cdot x[n-m]=\sum _{m=1}^{M}h[m]\cdot x[n-m],}](../I/6c695304cee4b4c978397073ba487fb5b5f97686.svg)
where h[m] = 0 for m outside the region [1, M]. This article uses common abstract notations, such as or in which it is understood that the functions should be thought of in their totality, rather than at specific instants (see Convolution#Notation).



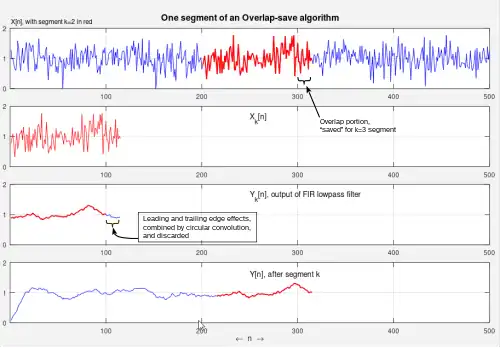
The concept is to compute short segments of y[n] of an arbitrary length L, and concatenate the segments together. Consider a segment that begins at n = kL + M, for any integer k, and define:
![{\displaystyle x_{k}[n]\ \triangleq {\begin{cases}x[n+kL],&1\leq n\leq L+M-1\\0,&{\textrm {otherwise}}.\end{cases}}}](../I/86d96799af4ad7297c6e47260666c2a4e4ef20a3.svg)
![{\displaystyle y_{k}[n]\ \triangleq \ x_{k}[n]*h[n]=\sum _{m=1}^{M}h[m]\cdot x_{k}[n-m].}](../I/8fd9d2fd0bbbfdd29588f4269fa83eb6a5c6bb78.svg)
Then, for , and equivalently , we can write:


![{\displaystyle y[n]=\sum _{m=1}^{M}h[m]\cdot x_{k}[n-kL-m]\ \ \triangleq \ \ y_{k}[n-kL].}](../I/a7c079ad24edca1c7175376f25063e1a0b6e3c26.svg)
With the substitution , the task is reduced to computing for . These steps are illustrated in the first 3 traces of Figure 1, except that the desired portion of the output (third trace) corresponds to 1 ≤ j ≤ L.[upper-alpha 2]

![{\displaystyle y_{k}[j]}](../I/594a6b04e674505684013555e4e89ff0bcfe02ae.svg)

If we periodically extend xk[n] with period N ≥ L + M − 1, according to:
![{\displaystyle x_{k,N}[n]\ \triangleq \ \sum _{\ell =-\infty }^{\infty }x_{k}[n-\ell N],}](../I/5d47dd2d227e66f4bfcefd7e64a245876fb0f04e.svg)
the convolutions and are equivalent in the region . It is therefore sufficient to compute the N-point circular (or cyclic) convolution of with in the region [1, N]. The subregion [M + 1, L + M] is appended to the output stream, and the other values are discarded. The advantage is that the circular convolution can be computed more efficiently than linear convolution, according to the circular convolution theorem:



![x_{k}[n]\,](../I/dc9d9200977fc896075d42002a94bfb133d0dd0a.svg)
![h[n]\,](../I/657f337326ef0221b43c4ae709e54fe608a6a527.svg)
-
(Eq.2)
![{\displaystyle y_{k}[n]\ =\ \scriptstyle {\text{IDFT}}_{N}\displaystyle (\ \scriptstyle {\text{DFT}}_{N}\displaystyle (x_{k}[n])\cdot \ \scriptstyle {\text{DFT}}_{N}\displaystyle (h[n])\ ),}](../I/ee068be99a264a0051a5a36497df695897bebf42.svg)
where:
- DFTN and IDFTN refer to the Discrete Fourier transform and its inverse, evaluated over N discrete points, and
- L is customarily chosen such that N = L+M-1 is an integer power-of-2, and the transforms are implemented with the FFT algorithm, for efficiency.
- The leading and trailing edge-effects of circular convolution are overlapped and added,[upper-alpha 3] and subsequently discarded.[upper-alpha 4]
Pseudocode
(Overlap-save algorithm for linear convolution) h = FIR_impulse_response M = length(h) overlap = M − 1 N = 8 × overlap (see next section for a better choice) step_size = N − overlap H = DFT(h, N) position = 0 while position + N ≤ length(x) yt = IDFT(DFT(x(position+(1:N))) × H) y(position+(1:step_size)) = yt(M : N) (discard M−1 y-values) position = position + step_size end
Efficiency considerations

When the DFT and IDFT are implemented by the FFT algorithm, the pseudocode above requires about N (log2(N) + 1) complex multiplications for the FFT, product of arrays, and IFFT.[upper-alpha 5] Each iteration produces N-M+1 output samples, so the number of complex multiplications per output sample is about:
-
(Eq.3)

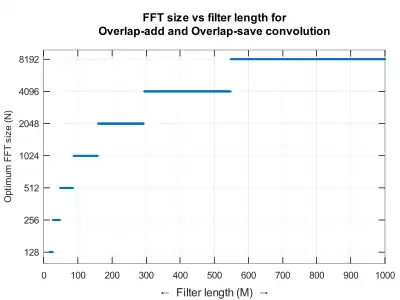
For example, when M=201 and N=1024, Eq.3 equals 13.67, whereas direct evaluation of Eq.1 would require up to 201 complex multiplications per output sample, the worst case being when both x and h are complex-valued. Also note that for any given M, Eq.3 has a minimum with respect to N. Figure 2 is a graph of the values of N that minimize Eq.3 for a range of filter lengths (M).
Instead of Eq.1, we can also consider applying Eq.2 to a long sequence of length samples. The total number of complex multiplications would be:


Comparatively, the number of complex multiplications required by the pseudocode algorithm is:

Hence the cost of the overlap–save method scales almost as while the cost of a single, large circular convolution is almost .


Overlap–discard
Overlap–discard[1] and Overlap–scrap[2] are less commonly used labels for the same method described here. However, these labels are actually better (than overlap–save) to distinguish from overlap–add, because both methods "save", but only one discards. "Save" merely refers to the fact that M − 1 input (or output) samples from segment k are needed to process segment k + 1.
Extending overlap–save
The overlap–save algorithm can be extended to include other common operations of a system:[upper-alpha 6][3]
- additional IFFT channels can be processed more cheaply than the first by reusing the forward FFT
- sampling rates can be changed by using different sized forward and inverse FFTs
- frequency translation (mixing) can be accomplished by rearranging frequency bins
See also
Notes
- Rabiner and Gold, Fig 2.35, fourth trace.
- Shifting the undesirable edge effects to the last M-1 outputs is a potential run-time convenience, because the IDFT can be computed in the buffer, instead of being computed and copied. Then the edge effects can be overwritten by the next IDFT. A subsequent footnote explains how the shift is done, by a time-shift of the impulse response.
- Not to be confused with the Overlap-add method, which preserves separate leading and trailing edge-effects.
- The edge effects can be moved from the front to the back of the IDFT output by replacing with meaning that the N-length buffer is circularly-shifted (rotated) by M-1 samples. Thus the h(M) element is at n=1. The h(M-1) element is at n=N. h(M-2) is at n=N-1. Etc.
- Cooley–Tukey FFT algorithm for N=2k needs (N/2) log2(N) – see FFT – Definition and speed
- Carlin et al. 1999, p 31, col 20.
![y[n]](../I/305428e6d1fb59cd0163a7a96ace52292a262afa.svg)
![{\displaystyle \scriptstyle {\text{DFT}}_{N}\displaystyle (h[n])}](../I/c8b62f1e3076cbb889d1f75935625152f54260c7.svg)
![{\displaystyle \scriptstyle {\text{DFT}}_{N}\displaystyle (h[n+M-1])=\ \scriptstyle {\text{DFT}}_{N}\displaystyle (h[n+M-1-N]),}](../I/4d183616f0965f41fa1094f723772164c57bc814.svg)
References
- Harris, F.J. (1987). D.F.Elliot (ed.). Handbook of Digital Signal Processing. San Diego: Academic Press. pp. 633–699. ISBN 0122370759.
- Frerking, Marvin (1994). Digital Signal Processing in Communication Systems. New York: Van Nostrand Reinhold. ISBN 0442016166.
- Borgerding, Mark (2006). "Turning Overlap–Save into a Multiband Mixing, Downsampling Filter Bank". IEEE Signal Processing Magazine. 23 (March 2006): 158–161. doi:10.1109/MSP.2006.1598092.
- Rabiner, Lawrence R.; Gold, Bernard (1975). "2.25". Theory and application of digital signal processing. Englewood Cliffs, N.J.: Prentice-Hall. pp. 63–67. ISBN 0-13-914101-4.
- US patent 6898235, Carlin,Joe; Collins,Terry & Hays,Peter et al., "Wideband communication intercept and direction finding device using hyperchannelization", published 1999-12-10, issued 2005-05-24, also available at https://patentimages.storage.googleapis.com/4d/39/2a/cec2ae6f33c1e7/US6898235.pdf