Group testing
In statistics and combinatorial mathematics, group testing is any procedure that breaks up the task of identifying certain objects into tests on groups of items, rather than on individual ones. First studied by Robert Dorfman in 1943, group testing is a relatively new field of applied mathematics that can be applied to a wide range of practical applications and is an active area of research today.
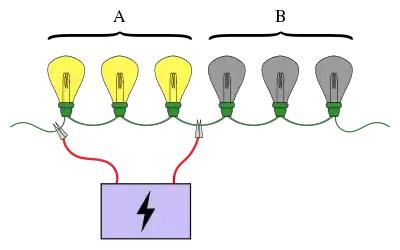
A familiar example of group testing involves a string of light bulbs connected in series, where exactly one of the bulbs is known to be broken. The objective is to find the broken bulb using the smallest number of tests (where a test is when some of the bulbs are connected to a power supply). A simple approach is to test each bulb individually. However, when there are a large number of bulbs it would be much more efficient to pool the bulbs into groups. For example, by connecting the first half of the bulbs at once, it can be determined which half the broken bulb is in, ruling out half of the bulbs in just one test.
Schemes for carrying out group testing can be simple or complex and the tests involved at each stage may be different. Schemes in which the tests for the next stage depend on the results of the previous stages are called adaptive procedures, while schemes designed so that all the tests are known beforehand are called non-adaptive procedures. The structure of the scheme of the tests involved in a non-adaptive procedure is known as a pooling design.
Group testing has many applications, including statistics, biology, computer science, medicine, engineering and cyber security. Modern interest in these testing schemes has been rekindled by the Human Genome Project.[1]
Basic description and terms
Unlike many areas of mathematics, the origins of group testing can be traced back to a single report[2] written by a single person: Robert Dorfman.[3] The motivation arose during the Second World War when the United States Public Health Service and the Selective service embarked upon a large-scale project to weed out all syphilitic men called up for induction. Testing an individual for syphilis involves drawing a blood sample from them and then analysing the sample to determine the presence or absence of syphilis. At the time, performing this test was expensive, and testing every soldier individually would have been very expensive and inefficient.[3]
Supposing there are soldiers, this method of testing leads to separate tests. If a large proportion of the people are infected then this method would be reasonable. However, in the more likely case that only a very small proportion of the men are infected, a much more efficient testing scheme can be achieved. The feasibility of a more effective testing scheme hinges on the following property: the soldiers can be pooled into groups, and in each group the blood samples can be combined together. The combined sample can then be tested to check if at least one soldier in the group has syphilis. This is the central idea behind group testing. If one or more of the soldiers in this group has syphilis, then a test is wasted (more tests need to be performed to find which soldier(s) it was). On the other hand, if no one in the pool has syphilis then many tests are saved, since every soldier in that group can be eliminated with just one test.[3]

The items that cause a group to test positive are generally called defective items (these are the broken lightbulbs, syphilitic men, etc.). Often, the total number of items is denoted as and represents the number of defectives if it is assumed to be known.[3]

Classification of group-testing problems
There are two independent classifications for group-testing problems; every group-testing problem is either adaptive or non-adaptive, and either probabilistic or combinatorial.[3]
In probabilistic models, the defective items are assumed to follow some probability distribution and the aim is to minimise the expected number of tests needed to identify the defectiveness of every item. On the other hand, with combinatorial group testing, the goal is to minimise the number of tests needed in a 'worst-case scenario' – that is, create a minmax algorithm – and no knowledge of the distribution of defectives is assumed.[3]
The other classification, adaptivity, concerns what information can be used when choosing which items to group into a test. In general, the choice of which items to test can depend on the results of previous tests, as in the above lightbulb problem. An algorithm that proceeds by performing a test, and then using the result (and all past results) to decide which next test to perform, is called adaptive. Conversely, in non-adaptive algorithms, all tests are decided in advance. This idea can be generalised to multistage algorithms, where tests are divided into stages, and every test in the next stage must be decided in advance, with only the knowledge of the results of tests in previous stages. Although adaptive algorithms offer much more freedom in design, it is known that adaptive group-testing algorithms do not improve upon non-adaptive ones by more than a constant factor in the number of tests required to identify the set of defective items.[4][3] In addition to this, non-adaptive methods are often useful in practice because one can proceed with successive tests without first analysing the results of all previous tests, allowing for the effective distribution of the testing process.
Variations and extensions
There are many ways to extend the problem of group testing. One of the most important is called noisy group testing, and deals with a big assumption of the original problem: that testing is error-free. A group-testing problem is called noisy when there is some chance that the result of a group test is erroneous (e.g. comes out positive when the test contained no defectives). The Bernoulli noise model assumes this probability is some constant, , but in general it can depend on the true number of defectives in the test and the number of items tested.[5] For example, the effect of dilution can be modelled by saying a positive result is more likely when there are more defectives (or more defectives as a fraction of the number tested), present in the test.[6] A noisy algorithm will always have a non-zero probability of making an error (that is, mislabeling an item).

Group testing can be extended by considering scenarios in which there are more than two possible outcomes of a test. For example, a test may have the outcomes and , corresponding to there being no defectives, a single defective, or an unknown number of defectives larger than one. More generally, it is possible to consider the outcome-set of a test to be for some .[3]




Another extension is to consider geometric restrictions on which sets can be tested. The above lightbulb problem is an example of this kind of restriction: only bulbs that appear consecutively can be tested. Similarly, the items may be arranged in a circle, or in general, a net, where the tests are available paths on the graph. Another kind of geometric restriction would be on the maximum number of items that can be tested in a group,[lower-alpha 1] or the group sizes might have to be even and so on. In a similar way, it may be useful to consider the restriction that any given item can only appear in a certain number of tests.[3]
There are endless ways to continue remixing the basic formula of group testing. The following elaborations will give an idea of some of the more exotic variants. In the 'good–mediocre–bad' model, each item is one of 'good', 'mediocre' or 'bad', and the result of a test is the type of the 'worst' item in the group. In threshold group testing, the result of a test is positive if the number of defective items in the group is greater than some threshold value or proportion.[7] Group testing with inhibitors is a variant with applications in molecular biology. Here, there is a third class of items called inhibitors, and the result of a test is positive if it contains at least one defective and no inhibitors.[8]
History and development
Invention and initial progress
The concept of group testing was first introduced by Robert Dorfman in 1943 in a short report[2] published in the Notes section of Annals of Mathematical Statistics.[3][lower-alpha 2] Dorfman's report – as with all the early work on group testing – focused on the probabilistic problem, and aimed to use the novel idea of group testing to reduce the expected number of tests needed to weed out all syphilitic men in a given pool of soldiers. The method was simple: put the soldiers into groups of a given size, and use individual testing (testing items in groups of size one) on the positive groups to find which were infected. Dorfman tabulated the optimum group sizes for this strategy against the prevalence rate of defectiveness in the population.[2] Stephen Samuels [10] found a closed-form solution for the optimal group size as a function of the prevalence rate.
After 1943, group testing remained largely untouched for a number of years. Then in 1957, Sterrett produced an improvement on Dorfman's procedure.[11] This newer process starts by again performing individual testing on the positive groups, but stopping as soon as a defective is identified. Then, the remaining items in the group are tested together, since it is very likely that none of them are defective.
The first thorough treatment of group testing was given by Sobel and Groll in their formative 1959 paper on the subject.[12] They described five new procedures – in addition to generalisations for when the prevalence rate is unknown – and for the optimal one, they provided an explicit formula for the expected number of tests it would use. The paper also made the connection between group testing and information theory for the first time, as well as discussing several generalisations of the group-testing problem and providing some new applications of the theory.
The fundamental result by Peter Ungar in 1960 shows that if the prevalence rate , then individual testing is the optimal group testing procedure with respect to the expected number of tests, and if , then it is not optimal. However, it is important to note that despite 80 years' worth of research effort, the optimal procedure is yet unknown for and a general population size .[13]



Combinatorial group testing
Group testing was first studied in the combinatorial context by Li in 1962,[14] with the introduction of Li’s -stage algorithm.[3] Li proposed an extension of Dorfman's '2-stage algorithm' to an arbitrary number of stages that required no more than tests to be guaranteed to find or fewer defectives among items. The idea was to remove all the items in negative tests, and divide the remaining items into groups as was done with the initial pool. This was to be done times before performing individual testing.



Combinatorial group testing in general was later studied more fully by Katona in 1973.[15] Katona introduced the matrix representation of non-adaptive group-testing and produced a procedure for finding the defective in the non-adaptive 1-defective case in no more than tests, which he also proved to be optimal.

In general, finding optimal algorithms for adaptive combinatorial group testing is difficult, and although the computational complexity of group testing has not been determined, it is suspected to be hard in some complexity class.[3] However, an important breakthrough occurred in 1972, with the introduction of the generalised binary-splitting algorithm.[16] The generalised binary-splitting algorithm works by performing a binary search on groups that test positive, and is a simple algorithm that finds a single defective in no more than the information-lower-bound number of tests.
In scenarios where there are two or more defectives, the generalised binary-splitting algorithm still produces near-optimal results, requiring at most tests above the information lower bound where is the number of defectives.[16] Considerable improvements to this were made in 2013 by Allemann, getting the required number of tests to less than above the information lower bound when and .[17] This was achieved by changing the binary search in the binary-splitting algorithm to a complex set of sub-algorithms with overlapping test groups. As such, the problem of adaptive combinatorial group testing – with a known number or upper bound on the number of defectives – has essentially been solved, with little room for further improvement.




There is an open question as to when individual testing is minmax. Hu, Hwang and Wang showed in 1981 that individual testing is minmax when , and that it is not minmax when .[18] It is currently conjectured that this bound is sharp: that is, individual testing is minmax if and only if .[19][lower-alpha 3] Some progress was made in 2000 by Riccio and Colbourn, who showed that for large , individual testing is minmax when .[20]




Non-adaptive and probabilistic testing
One of the key insights in non-adaptive group testing is that significant gains can be made by eliminating the requirement that the group-testing procedure be certain to succeed (the "combinatorial" problem), but rather permit it to have some low but non-zero probability of mis-labelling each item (the "probabilistic" problem). It is known that as the number of defective items approaches the total number of items, exact combinatorial solutions require significantly more tests than probabilistic solutions — even probabilistic solutions permitting only an asymptotically small probability of error.[4][lower-alpha 4]
In this vein, Chan et al. (2011) introduced COMP, a probabilistic algorithm that requires no more than tests to find up to defectives in items with a probability of error no more than .[5] This is within a constant factor of the lower bound.[4]



Chan et al. (2011) also provided a generalisation of COMP to a simple noisy model, and similarly produced an explicit performance bound, which was again only a constant (dependent on the likelihood of a failed test) above the corresponding lower bound.[4][5] In general, the number of tests required in the Bernoulli noise case is a constant factor larger than in the noiseless case.[5]
Aldridge, Baldassini and Johnson (2014) produced an extension of the COMP algorithm that added additional post-processing steps.[21] They showed that the performance of this new algorithm, called DD, strictly exceeds that of COMP, and that DD is 'essentially optimal' in scenarios where , by comparing it to a hypothetical algorithm that defines a reasonable optimum. The performance of this hypothetical algorithm suggests that there is room for improvement when , as well as suggesting how much improvement this might be.[21]


Formalisation of combinatorial group testing
This section formally defines the notions and terms relating to group testing.
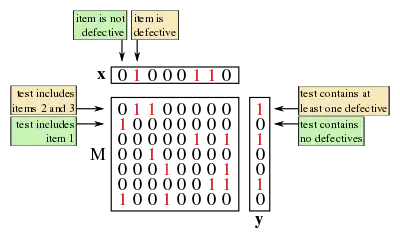
- The input vector, , is defined to be a binary vector of length (that is, ), with the j-th item being called defective if and only if . Further, any non-defective item is called a 'good' item.



is intended to describe the (unknown) set of defective items. The key property of is that it is an implicit input. That is to say, there is no direct knowledge of what the entries of are, other than that which can be inferred via some series of 'tests'. This leads on to the next definition.

- Let be an input vector. A set, is called a test. When testing is noiseless, the result of a test is positive when there exists such that , and the result is negative otherwise.


Therefore, the goal of group testing is to come up with a method for choosing a 'short' series of tests that allow to be determined, either exactly or with a high degree of certainty.
- A group-testing algorithm is said to make an error if it incorrectly labels an item (that is, labels any defective item as non-defective or vice versa). This is not the same thing as the result of a group test being incorrect. An algorithm is called zero-error if the probability that it makes an error is zero.[lower-alpha 5]
- denotes the minimum number of tests required to always find defectives among items with zero probability of error by any group-testing algorithm. For the same quantity but with the restriction that the algorithm is non-adaptive, the notation is used.


General bounds
Since it is always possible to resort to individual testing by setting for each , it must be that that . Also, since any non-adaptive testing procedure can be written as an adaptive algorithm by simply performing all the tests without regard to their outcome, . Finally, when , there is at least one item whose defectiveness must be determined (by at least one test), and so .






In summary (when assuming ), .[lower-alpha 6]

Information lower bound
A lower bound on the number of tests needed can be described using the notion of sample space, denoted , which is simply the set of possible placements of defectives. For any group testing problem with sample space and any group-testing algorithm, it can be shown that , where is the minimum number of tests required to identify all defectives with a zero probability of error. This is called the information lower bound.[3] This bound is derived from the fact that after each test, is split into two disjoint subsets, each corresponding to one of the two possible outcomes of the test.



However, the information lower bound itself is usually unachievable, even for small problems.[3] This is because the splitting of is not arbitrary, since it must be realisable by some test.
In fact, the information lower bound can be generalised to the case where there is a non-zero probability that the algorithm makes an error. In this form, the theorem gives us an upper bound on the probability of success based on the number of tests. For any group-testing algorithm that performs tests, the probability of success, , satisfies . This can be strengthened to: .[5][22]



Representation of non-adaptive algorithms

Algorithms for non-adaptive group testing consist of two distinct phases. First, it is decided how many tests to perform and which items to include in each test. In the second phase, often called the decoding step, the results of each group test are analysed to determine which items are likely to be defective. The first phase is usually encoded in a matrix as follows.[5]
- Suppose a non-adaptive group testing procedure for items consists of the tests for some . The testing matrix for this scheme is the binary matrix, , where if and only if (and is zero otherwise).





Thus each column of represents an item and each row represents a test, with a in the entry indicating that the test included the item and a indicating otherwise.





As well as the vector (of length ) that describes the unknown defective set, it is common to introduce the result vector, which describes the results of each test.
- Let be the number of tests performed by a non-adaptive algorithm. The result vector, , is a binary vector of length (that is, ) such that if and only if the result of the test was positive (i.e. contained at least one defective).[lower-alpha 7]



With these definitions, the non-adaptive problem can be reframed as follows: first a testing matrix is chosen, , after which the vector is returned. Then the problem is to analyse to find some estimate for .

In the simplest noisy case, where there is a constant probability, , that a group test will have an erroneous result, one considers a random binary vector, , where each entry has a probability of being , and is otherwise. The vector that is returned is then , with the usual addition on (equivalently this is the element-wise XOR operation). A noisy algorithm must estimate using (that is, without direct knowledge of ).[5]




Bounds for non-adaptive algorithms
The matrix representation makes it possible to prove some bounds on non-adaptive group testing. The approach mirrors that of many deterministic designs, where -separable matrices are considered, as defined below.[3]
- A binary matrix, , is called -separable if every Boolean sum (logical OR) of any of its columns is distinct. Additionally, the notation -separable indicates that every sum of any of up to of 's columns is distinct. (This is not the same as being -separable for every .)



When is a testing matrix, the property of being -separable (-separable) is equivalent to being able to distinguish between (up to) defectives. However, it does not guarantee that this will be straightforward. A stronger property, called -disjunctness does.
- A binary matrix, is called -disjunct if the Boolean sum of any columns does not contain any other column. (In this context, a column A is said to contain a column B if for every index where B has a 1, A also has a 1.)
A useful property of -disjunct testing matrices is that, with up to defectives, every non-defective item will appear in at least one test whose outcome is negative. This means there is a simple procedure for finding the defectives: just remove every item that appears in a negative test.
Using the properties of -separable and -disjunct matrices the following can be shown for the problem of identifying defectives among total items.[4]
- The number of tests needed for an asymptotically small average probability of error scales as .
- The number of tests needed for an asymptotically small maximum probability of error scales as .
- The number of tests needed for a zero probability of error scales as .



Generalised binary-splitting algorithm
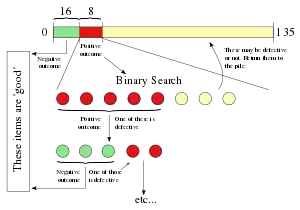



The generalised binary-splitting algorithm is an essentially-optimal adaptive group-testing algorithm that finds or fewer defectives among items as follows:[3][16]
- If , test the items individually. Otherwise, set and .
- Test a group of size . If the outcome is negative, every item in the group is declared to be non-defective; set and go to step 1. Otherwise, use a binary search to identify one defective and an unspecified number, called , of non-defective items; set and . Go to step 1.








The generalised binary-splitting algorithm requires no more than tests where .[3]


For large, it can be shown that ,[3] which compares favorably to the tests required for Li's -stage algorithm. In fact, the generalised binary-splitting algorithm is close to optimal in the following sense. When it can be shown that , where is the information lower bound.[3][16]






Non-adaptive algorithms
Non-adaptive group-testing algorithms tend to assume that the number of defectives, or at least a good upper bound on them, is known.[5] This quantity is denoted in this section. If no bounds are known, there are non-adaptive algorithms with low query complexity that can help estimate .[23]
Combinatorial orthogonal matching pursuit (COMP)
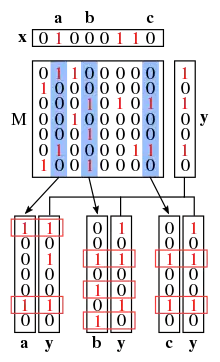
Combinatorial Orthogonal Matching Pursuit, or COMP, is a simple non-adaptive group-testing algorithm that forms the basis for the more complicated algorithms that follow in this section.
First, each entry of the testing matrix is chosen i.i.d. to be with probability and otherwise.

The decoding step proceeds column-wise (i.e. by item). If every test in which an item appears is positive, then the item is declared defective; otherwise the item is assumed to be non-defective. Or equivalently, if an item appears in any test whose outcome is negative, the item is declared non-defective; otherwise the item is assumed to be defective. An important property of this algorithm is that it never creates false negatives, though a false positive occurs when all locations with ones in the j-th column of (corresponding to a non-defective item j) are "hidden" by the ones of other columns corresponding to defective items.
The COMP algorithm requires no more than tests to have an error probability less than or equal to .[5] This is within a constant factor of the lower bound for the average probability of error above.

In the noisy case, one relaxes the requirement in the original COMP algorithm that the set of locations of ones in any column of corresponding to a positive item be entirely contained in the set of locations of ones in the result vector. Instead, one allows for a certain number of “mismatches” – this number of mismatches depends on both the number of ones in each column, and also the noise parameter, . This noisy COMP algorithm requires no more than tests to achieve an error probability at most .[5]

Definite defectives (DD)
The definite defectives method (DD) is an extension of the COMP algorithm that attempts to remove any false positives. Performance guarantees for DD have been shown to strictly exceed those of COMP.[21]
The decoding step uses a useful property of the COMP algorithm: that every item that COMP declares non-defective is certainly non-defective (that is, there are no false negatives). It proceeds as follows.
- First the COMP algorithm is run, and any non-defectives that it detects are removed. All remaining items are now "possibly defective".
- Next the algorithm looks at all the positive tests. If an item appears as the only "possible defective" in a test, then it must be defective, so the algorithm declares it to be defective.
- All other items are assumed to be non-defective. The justification for this last step comes from the assumption that the number of defectives is much smaller than the total number of items.
Note that steps 1 and 2 never make a mistake, so the algorithm can only make a mistake if it declares a defective item to be non-defective. Thus the DD algorithm can only create false negatives.
Sequential COMP (SCOMP)
SCOMP (Sequential COMP) is an algorithm that makes use of the fact that DD makes no mistakes until the last step, where it is assumed that the remaining items are non-defective. Let the set of declared defectives be . A positive test is called explained by if it contains at least one item in . The key observation with SCOMP is that the set of defectives found by DD may not explain every positive test, and that every unexplained test must contain a hidden defective.

The algorithm proceeds as follows.
- Carry out steps 1 and 2 of the DD algorithm to obtain , an initial estimate for the set of defectives.
- If explains every positive test, terminate the algorithm: is the final estimate for the set of defectives.
- If there are any unexplained tests, find the "possible defective" that appears in the largest number of unexplained tests, and declare it to be defective (that is, add it to the set ). Go to step 2.
In simulations, SCOMP has been shown to perform close to optimally.[21]
Polynomial Pools (PP)
A deterministic algorithm that is guaranteed to exactly identify up to positives is Polynomial Pools (PP). [24]. The algorithm is for the construction of the pooling matrix , which can be straightforwardly used to decode the observations in . Similar to COMP, a sample is decoded according to the relation: , where represents element wise multiplication and is the th column of . Since the decoding step is not difficult, PP is specialized for generating .





Forming groups



A group/pool is generated using a polynomial relation that specifies the indices of the samples contained in each pool. A set of input parameters determines the algorithm. For a prime number and an integer any prime power is defined by . For a dimension paramter the total number of samples is and the number of samples per pool is . Further, the Finite field of order is denoted by (i.e, the integers defined by special arithmetic operations that ensure that addition and multiplication in remains in ). The method arranges each sample in a grid and represents it by coordinates . The coordinates are computed according to a polynomial relation using the integers ,













The combination of looping through the values is represented by a set with elements of a sequence of integers, i.e., , where . Without loss of generality, the combination is such that cycles every times, cycles every times until cycles only once. Formulas that compute the sample indices, and thus the corresponding pools, for fixed and , are given by










The computations in can be implemented with publicly available software libraries for finite fields, when is a prime power. When is a prime number then the computations in simplify to modulus arithmetics, i.e, . An example of how to generate one pool when is displayed in the table below, while the corresponding selection of samples is shown in the figure above.
































This method uses tests to exactly identify up to positives among samples. Because of this PP is particularly effective for large sample sizes, since the number of tests grows only linearly with respect to while the samples grow exponentially with this parameter. However PP can also be effective for small sample sizes.[24]


Example applications
The generality of the theory of group testing lends it to many diverse applications, including clone screening, locating electrical shorts;[3] high speed computer networks;[25] medical examination, quantity searching, statistics;[18] machine learning, DNA sequencing;[26] cryptography;[27][28] and data forensics.[29] This section provides a brief overview of a small selection of these applications.
Multiaccess channels

A multiaccess channel is a communication channel that connects many users at once. Every user can listen and transmit on the channel, but if more than one user transmits at the same time, the signals collide, and are reduced to unintelligible noise. Multiaccess channels are important for various real-world applications, notably wireless computer networks and phone networks.[30]
A prominent problem with multiaccess channels is how to assign transmission times to the users so that their messages do not collide. A simple method is to give each user their own time slot in which to transmit, requiring slots. (This is called time division multiplexing, or TDM.) However, this is very inefficient, since it will assign transmission slots to users that may not have a message, and it is usually assumed that only a few users will want to transmit at any given time – otherwise a multiaccess channel is not practical in the first place.
In the context of group testing, this problem is usually tackled by dividing time into 'epochs' in the following way.[3] A user is called 'active' if they have a message at the start of an epoch. (If a message is generated during an epoch, the user only becomes active at the start of the next one.) An epoch ends when every active user has successfully transmitted their message. The problem is then to find all the active users in a given epoch, and schedule a time for them to transmit (if they have not already done so successfully). Here, a test on a set of users corresponds to those users attempting a transmission. The results of the test are the number of users that attempted to transmit, and , corresponding respectively to no active users, exactly one active user (message successful) or more than one active user (message collision). Therefore, using an adaptive group testing algorithm with outcomes , it can be determined which users wish to transmit in the epoch. Then, any user that has not yet made a successful transmission can now be assigned a slot to transmit, without wastefully assigning times to inactive users.


Machine learning and compressed sensing
Machine learning is a field of computer science that has many software applications such as DNA classification, fraud detection and targeted advertising. One of the main subfields of machine learning is the 'learning by examples' problem, where the task is to approximate some unknown function when given its value at a number of specific points.[3] As outlined in this section, this function learning problem can be tackled with a group-testing approach.
In a simple version of the problem, there is some unknown function, where , and (using logical arithmetic: addition is logical OR and multiplication is logical AND). Here is ' sparse', which means that at most of its entries are . The aim is to construct an approximation to using point evaluations, where is as small as possible.[4] (Exactly recovering corresponds to zero-error algorithms, whereas is approximated by algorithms that have a non-zero probability of error.)






In this problem, recovering is equivalent to finding . Moreover, if and only if there is some index, , where . Thus this problem is analogous to a group-testing problem with defectives and total items. The entries of are the items, which are defective if they are , specifies a test, and a test is positive if and only if .[4]



In reality, one will often be interested in functions that are more complicated, such as , again where . Compressed sensing, which is closely related to group testing, can be used to solve this problem.[4]

In compressed sensing, the goal is to reconstruct a signal, , by taking a number of measurements. These measurements are modelled as taking the dot product of with a chosen vector.[lower-alpha 8] The aim is to use a small number of measurements, though this is typically not possible unless something is assumed about the signal. One such assumption (which is common[33][34]) is that only a small number of entries of are significant, meaning that they have a large magnitude. Since the measurements are dot products of , the equation holds, where is a matrix that describes the set of measurements that have been chosen and is the set of measurement results. This construction shows that compressed sensing is a kind of 'continuous' group testing.





The primary difficulty in compressed sensing is identifying which entries are significant.[33] Once that is done, there are a variety of methods to estimate the actual values of the entries.[35] This task of identification can be approached with a simple application of group testing. Here a group test produces a complex number: the sum of the entries that are tested. The outcome of a test is called positive if it produces a complex number with a large magnitude, which, given the assumption that the significant entries are sparse, indicates that at least one significant entry is contained in the test.
There are explicit deterministic constructions for this type of combinatorial search algorithm, requiring measurements.[36] However, as with group-testing, these are sub-optimal, and random constructions (such as COMP) can often recover sub-linearly in .[35]


Multiplex assay design for COVID19 testing
During a pandemic such as the COVID-19 outbreak in 2020, virus detection assays are sometimes run using nonadaptive group testing designs.[37][38] [39] One example was provided by the Origami Assays project which released open source group testing designs to run on a laboratory standard 96 well plate.[40]

In a laboratory setting, one challenge of group testing is the construction of the mixtures can be time-consuming and difficult to do accurately by hand. Origami assays provided a workaround for this construction problem by providing paper templates to guide the technician on how to allocate patient samples across the test wells.[41]
Using the largest group testing designs (XL3) it was possible to test 1120 patient samples in 94 assay wells. If the true positive rate was low enough, then no additional testing was required.
Data forensics
Data forensics is a field dedicated to finding methods for compiling digital evidence of a crime. Such crimes typically involve an adversary modifying the data, documents or databases of a victim, with examples including the altering of tax records, a virus hiding its presence, or an identity thief modifying personal data.[29]
A common tool in data forensics is the one-way cryptographic hash. This is a function that takes the data, and through a difficult-to-reverse procedure, produces a unique number called a hash.[lower-alpha 9] Hashes, which are often much shorter than the data, allow us to check if the data has been changed without having to wastefully store complete copies of the information: the hash for the current data can be compared with a past hash to determine if any changes have occurred. An unfortunate property of this method is that, although it is easy to tell if the data has been modified, there is no way of determining how: that is, it is impossible to recover which part of the data has changed.[29]
One way to get around this limitation is to store more hashes – now of subsets of the data structure – to narrow down where the attack has occurred. However, to find the exact location of the attack with a naive approach, a hash would need to be stored for every datum in the structure, which would defeat the point of the hashes in the first place. (One may as well store a regular copy of the data.) Group testing can be used to dramatically reduce the number of hashes that need to be stored. A test becomes a comparison between the stored and current hashes, which is positive when there is a mismatch. This indicates that at least one edited datum (which is taken as defectiveness in this model) is contained in the group that generated the current hash.[29]
In fact, the amount of hashes needed is so low that they, along with the testing matrix they refer to, can even be stored within the organisational structure of the data itself. This means that as far as memory is concerned the test can be performed 'for free'. (This is true with the exception of a master-key/password that is used to secretly determine the hashing function.)[29]
Notes
- The original problem that Dorfman studied was of this nature (although he did not account for this), since in practice, only a certain number of blood sera could be pooled before the testing procedure became unreliable. This was the main reason that Dorfman’s procedure was not applied at the time.[3]
- However, as is often the case in mathematics, group testing has been subsequently re-invented multiple times since then, often in the context of applications. For example, Hayes independently came up with the idea to query groups of users in the context of multiaccess communication protocols in 1978.[9]
- This is sometimes referred to as the Hu-Hwang-Wang conjecture.
- The number of tests, , must scale as for deterministic designs, compared to for designs that allow arbitrarily small probabilities of error (as and ).[4]
- One must be careful to distinguish between when a test reports a false result and when the group-testing procedure fails as a whole. It is both possible to make an error with no incorrect tests and to not make an error with some incorrect tests. Most modern combinatorial algorithms have some non-zero probability of error (even with no erroneous tests), since this significantly decreases the number of tests needed.
- In fact it is possible to do much better. For example, Li's -stage algorithm gives an explicit construction were .
- Alternatively can be defined by the equation , where multiplication is logical AND () and addition is logical OR (). Here, will have a in position if and only if and are both for any . That is, if and only if at least one defective item was included in the test.
- This kind of measurement comes up in many applications. For example, certain kinds of digital camera[31] or MRI machines,[32] where time constraints require that only a small number of measurements are taken.
- More formally hashes have a property called collision resistance, which is that the likelihood of the same hash resulting from different inputs is very low for data of an appropriate size. In practice, the chance that two different inputs might produce the same hash is often ignored.










References
Citations
- Colbourn, Charles J.; Dinitz, Jeffrey H. (2007), Handbook of Combinatorial Designs (2nd ed.), Boca Raton: Chapman & Hall/ CRC, p. 574, Section 46: Pooling Designs, ISBN 978-1-58488-506-1
- Dorfman, Robert (December 1943), "The Detection of Defective Members of Large Populations", The Annals of Mathematical Statistics, 14 (4): 436–440, doi:10.1214/aoms/1177731363, JSTOR 2235930
- Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapore: World Scientific. ISBN 978-9810212933.
- Atia, George Kamal; Saligrama, Venkatesh (March 2012). "Boolean compressed sensing and noisy group testing". IEEE Transactions on Information Theory. 58 (3): 1880–1901. arXiv:0907.1061. doi:10.1109/TIT.2011.2178156. S2CID 8946216.
- Chun Lam Chan; Pak Hou Che; Jaggi, Sidharth; Saligrama, Venkatesh (1 September 2011). "Non-adaptive probabilistic group testing with noisy measurements: Near-optimal bounds with efficient algorithms". 49th Annual Allerton Conference on Communication, Control, and Computing. pp. 1832–9. arXiv:1107.4540. doi:10.1109/Allerton.2011.6120391. ISBN 978-1-4577-1817-5. S2CID 8408114.
- Hung, M.; Swallow, William H. (March 1999). "Robustness of Group Testing in the Estimation of Proportions". Biometrics. 55 (1): 231–7. doi:10.1111/j.0006-341X.1999.00231.x. PMID 11318160. S2CID 23389365.
- Chen, Hong-Bin; Fu, Hung-Lin (April 2009). "Nonadaptive algorithms for threshold group testing". Discrete Applied Mathematics. 157 (7): 1581–1585. doi:10.1016/j.dam.2008.06.003.
- De Bonis, Annalisa (20 July 2007). "New combinatorial structures with applications to efficient group testing with inhibitors". Journal of Combinatorial Optimization. 15 (1): 77–94. doi:10.1007/s10878-007-9085-1. S2CID 207188798.
- Hayes, J. (August 1978). "An adaptive technique for local distribution". IEEE Transactions on Communications. 26 (8): 1178–86. doi:10.1109/TCOM.1978.1094204.
- Samuels, Stephen (1978). "The Exact Solution to the Two-Stage Group-Testing Problem". Technometrics. 20 (4): 497–500. doi:10.1080/00401706.1978.10489706.
- Sterrett, Andrew (December 1957). "On the detection of defective members of large populations". The Annals of Mathematical Statistics. 28 (4): 1033–6. doi:10.1214/aoms/1177706807.
- Sobel, Milton; Groll, Phyllis A. (September 1959). "Group testing to eliminate efficiently all defectives in a binomial sample". Bell System Technical Journal. 38 (5): 1179–1252. doi:10.1002/j.1538-7305.1959.tb03914.x.
- Ungar, Peter (February 1960). "Cutoff points in group testing". Communications on Pure and Applied Mathematics. 13 (1): 49–54. doi:10.1002/cpa.3160130105.
- Li, Chou Hsiung (June 1962). "A sequential method for screening experimental variables". Journal of the American Statistical Association. 57 (298): 455–477. doi:10.1080/01621459.1962.10480672.
- Katona, Gyula O.H. (1973). "A survey of combinatorial theory". Combinatorial Search Problems. North-Holland. pp. 285–308. ISBN 978-0-7204-2262-7.
- Hwang, Frank K. (September 1972). "A method for detecting all defective members in a population by group testing". Journal of the American Statistical Association. 67 (339): 605–608. doi:10.2307/2284447. JSTOR 2284447.
- Allemann, Andreas (2013). "An Efficient Algorithm for Combinatorial Group Testing". Information Theory, Combinatorics, and Search Theory. Lecture Notes in Computer Science. Vol. 7777. pp. 569–596. doi:10.1007/978-3-642-36899-8_29. ISBN 978-3-642-36898-1.
- Hu, M. C.; Hwang, F. K.; Wang, Ju Kwei (June 1981). "A Boundary Problem for Group Testing". SIAM Journal on Algebraic and Discrete Methods. 2 (2): 81–87. doi:10.1137/0602011.
- Leu, Ming-Guang (28 October 2008). "A note on the Hu–Hwang–Wang conjecture for group testing". The ANZIAM Journal. 49 (4): 561. doi:10.1017/S1446181108000175.
- Riccio, Laura; Colbourn, Charles J. (1 January 2000). "Sharper bounds in adaptive group testing". Taiwanese Journal of Mathematics. 4 (4): 669–673. doi:10.11650/twjm/1500407300.
- Aldridge, Matthew; Baldassini, Leonardo; Johnson, Oliver (June 2014). "Group Testing Algorithms: Bounds and Simulations". IEEE Transactions on Information Theory. 60 (6): 3671–3687. arXiv:1306.6438. doi:10.1109/TIT.2014.2314472. S2CID 8885619.
- Baldassini, L.; Johnson, O.; Aldridge, M. (1 July 2013), "2013 IEEE International Symposium on Information Theory", IEEE International Symposium on Information Theory, pp. 2676–2680, arXiv:1301.7023, CiteSeerX 10.1.1.768.8924, doi:10.1109/ISIT.2013.6620712, ISBN 978-1-4799-0446-4, S2CID 9987210
- Sobel, Milton; Elashoff, R. M. (1975). "Group testing with a new goal, estimation". Biometrika. 62 (1): 181–193. doi:10.1093/biomet/62.1.181. hdl:11299/199154.
- Brust, D.; Brust, J. J. (January 2023). "Effective matrix designs for COVID-19 group testing". BMC Bioinformatics. 24 (26): 26. doi:10.1186/s12859-023-05145-y. PMC 9872308. PMID 36694117.
- Bar-Noy, A.; Hwang, F. K.; Kessler, I.; Kutten, S. (1 May 1992). "A new competitive algorithm for group testing". [Proceedings] IEEE INFOCOM '92: The Conference on Computer Communications. Vol. 2. pp. 786–793. doi:10.1109/INFCOM.1992.263516. ISBN 978-0-7803-0602-8. S2CID 16131063.
- Damaschke, Peter (2000). "Adaptive versus nonadaptive attribute-efficient learning". Machine Learning. 41 (2): 197–215. doi:10.1023/A:1007616604496.
- Stinson, D. R.; van Trung, Tran; Wei, R (May 2000). "Secure frameproof codes, key distribution patterns, group testing algorithms and related structures". Journal of Statistical Planning and Inference. 86 (2): 595–617. CiteSeerX 10.1.1.54.6212. doi:10.1016/S0378-3758(99)00131-7.
- Colbourn, C. J.; Dinitz, J. H.; Stinson, D. R. (1999). "Communications, Cryptography, and Networking". Surveys in Combinatorics. 3 (267): 37–41. doi:10.1007/BF01609873. S2CID 10128581.
- Goodrich, Michael T.; Atallah, Mikhail J.; Tamassia, Roberto (2005). "Indexing Information for Data Forensics". Applied Cryptography and Network Security. Lecture Notes in Computer Science. Vol. 3531. pp. 206–221. CiteSeerX 10.1.1.158.6036. doi:10.1007/11496137_15. ISBN 978-3-540-26223-7.
- Chlebus, B.S. (2001). "Randomized communication in radio networks". In Pardalos, P.M.; Rajasekaran, S.; Reif, J.; Rolim, J.D.P. (eds.). Handbook of Randomized Computing. Kluwer Academic. pp. 401–456. ISBN 978-0-7923-6957-8.
- Takhar, D.; Laska, J. N.; Wakin, M. B.; Duarte, M. F.; Baron, D.; Sarvotham, S.; Kelly, K. F.; Baraniuk, R. G. (February 2006). Bouman, Charles A.; Miller, Eric L.; Pollak, Ilya (eds.). "A new compressive imaging camera architecture using optical-domain compression". Electronic Imaging. Computational Imaging IV. 6065: 606509–606509–10. Bibcode:2006SPIE.6065...43T. CiteSeerX 10.1.1.114.7872. doi:10.1117/12.659602. S2CID 7513433.
- Candès, E.J. (2014). "Mathematics of sparsity (and a few other things)". Proceedings of the International Congress of Mathematicians. Seoul, South Korea.
- Gilbert, A.C.; Iwen, M.A.; Strauss, M.J. (October 2008). "Group testing and sparse signal recovery". 42nd Asilomar Conference on Signals, Systems and Computers. Institute of Electrical and Electronics Engineers. pp. 1059–63. doi:10.1109/ACSSC.2008.5074574. ISBN 978-1-4244-2940-0.
- Wright, S. J.; Nowak, R. D.; Figueiredo, M. A. T. (July 2009). "Sparse Reconstruction by Separable Approximation". IEEE Transactions on Signal Processing. 57 (7): 2479–2493. Bibcode:2009ITSP...57.2479W. CiteSeerX 10.1.1.142.749. doi:10.1109/TSP.2009.2016892. S2CID 7399917.
- Berinde, R.; Gilbert, A. C.; Indyk, P.; Karloff, H.; Strauss, M. J. (September 2008). "Combining geometry and combinatorics: A unified approach to sparse signal recovery". 2008 46th Annual Allerton Conference on Communication, Control, and Computing. pp. 798–805. arXiv:0804.4666. doi:10.1109/ALLERTON.2008.4797639. ISBN 978-1-4244-2925-7. S2CID 8301134.
- Indyk, Piotr (1 January 2008). "Explicit Constructions for Compressed Sensing of Sparse Signals". Proceedings of the Nineteenth Annual ACM-SIAM Symposium on Discrete Algorithms: 30–33.
- Austin, David. "AMS Feature Column — Pooling strategies for COVID-19 testing". American Mathematical Society. Retrieved 2020-10-03.
- Prasanna, Dheeraj. "Tapestry pooling". tapestry-pooling.herokuapp.com. Retrieved 2020-10-03.
- Chiani, M.; Liva, G.; Paolini, E. (February 2022), "Identification-detection group testing protocols for COVID-19 at high prevalence", Scientific Reports, Springer Nature, 12 (1): 3250, arXiv:2104.11305, Bibcode:2022NatSR..12.3250C, doi:10.1038/s41598-022-07205-4, PMC 8885674, PMID 35228579, S2CID 233387831
- "Origami Assays". Origami Assays. April 2, 2020. Retrieved April 7, 2020.
- "Origami Assays". Origami Assays. April 2, 2020. Retrieved April 7, 2020.
General references
- Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapore: World Scientific. ISBN 978-9810212933.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2007), Lectures 7.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2010), Lectures 10, 11, 28, 29
- Du, D.; Hwang, F. (2006). Pooling Designs and Nonadaptive Group Testing. World Scientific. ISBN 9789814477864.
- Aldridge, M.; Johnson, O.; Scarlett, J. (2019). "Group Testing: An Information Theory Perspective" (PDF). Foundations and Trends in Communications and Information Theory. 15 (3–4): 196–392. doi:10.1561/0100000099. S2CID 62841593.
- Porat, E.; Rothschild, A. (2011). "Explicit nonadaptive combinatorial group testing schemes". IEEE Transactions on Information Theory. 57 (12): 7982–89. arXiv:0712.3876. doi:10.1109/TIT.2011.2163296. S2CID 8815474.
- Kagan, Eugene; Ben-gal, Irad (2014), "A group testing algorithm with online informational learning", IIE Transactions, 46 (2): 164–184, doi:10.1080/0740817X.2013.803639, ISSN 0740-817X, S2CID 18588494