Popularity of text encodings
A number of text encoding standards are used on the World Wide Web. Exact measurements for the prevalence of each are not possible. Attempts at measuring encoding popularity may utilize counts of numbers of documents, or counts weighed by actual use or visibility of those documents.
The decision to use any one encoding may depend on the language used for the documents, or the locale that is the source of the document, or the purpose of the document. Text may be ambiguous as to what encoding it is in, for instance pure ASCII text is valid ASCII or ISO-8859-1 or CP1252 or UTF-8. "Tags" may indicate a document encoding, but when this is incorrect this may be silently corrected by display software (for instance the HTML spec says that the tag for ISO-8859-1 should be treated as CP1252), so counts of tags may not be accurate.
Popularity on the World Wide Web
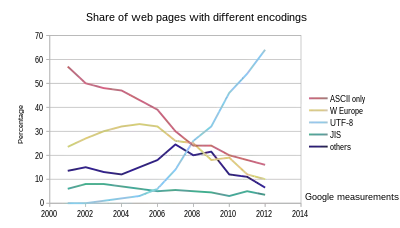
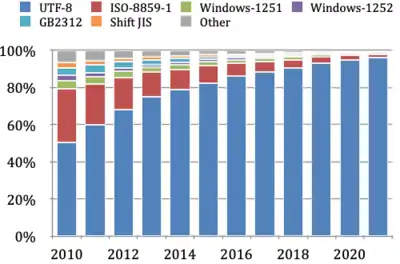
UTF-8 has been the most common encoding for the World Wide Web since 2008.[2] As of October 2023, UTF-8 accounts for 98.0% of all web pages (and 99.0% of top 10,000 pages and 98.5% of the top 1,000 highest ranked web pages, the next most popular encoding, ISO-8859-1, is used by 13 of those sites).[3] Although many pages only use ASCII characters to display content, few websites now declare their encoding to only be ASCII instead of UTF-8.[4]
Virtually all countries and over 97% all of the tracked languages have 95% or more use of UTF-8 encodings on the web. See below for the major alternative encodings:
The second-most popular encoding varies depending on locale, and is typically more efficient for the associated language. One such encoding is the Chinese GB 18030 standard, which is a full Unicode Transformation Format, still 95.2% of websites in China and territories use UTF-8[5][6][7] with it (effectively[8]) the next popular encoding. Big5 is another popular Chinese (for traditional characters) encoding and is next-most popular in Taiwan after UTF-8 at 96.2%, and it's also second-most used in Hong Kong, while there as elsewhere, UTF-8 is even more dominant.[9] The single-byte Windows-1251 is twice as efficient for the Cyrillic script and still 94.3% of Russian websites use UTF-8[10] (however e.g. Greek and Hebrew encodings are also twice as efficient, and UTF-8 has over 99% use for those languages).[11][12] Japanese and Korean language websites also have relatively high non-UTF-8 use compared to most other countries, with Japanese UTF-8 use at 94.5% followed by the legacy Shift JIS and then EUC-JP encoding.[13][14][1] South Korea has 95.0% UTF-8 use, with the rest of websites mainly using EUC-KR which is more efficient for Korean text.
With the exception of GB 18030 (and UTF-16 and UTF-8), other (legacy) encodings do not do not support all Unicode characters, since they were designed for specific languages.
As of October 2023, Breton has the lowest UTF-8 use on the web of any tracked language, with 89.6% use.[15] Well over a third of the languages tracked have 100.0% use of UTF-8 on the web, such as Vietnamese, Marathi, Telugu, Tamil, Javanese, Pañjābī/Punjabi, Gujarati, Farsi/Persian, Hausa, Pashto, Kannada, Lao, Kurdish languages, Tagalog, Somali, Khmer/Cambodian, isiZulu/Zulu, Turkmen, Tajik (has 4 different scripts), and a lot of the languages with the fewest speakers (often with their own scripts) such as, Armenian, Mongolian (which has a top-to-bottom script[16]), Maldivian (Thaana), Greenlandic (Kalaallisut) and also sign languages.[17]
Popularity for local text files
Local storage on computers has considerably more use of "legacy" single-byte encodings than on the web. Attempts to update to UTF-8 have been blocked by editors that do not display or write UTF-8 unless the first character in a file is a byte order mark, making it impossible for other software to use UTF-8 without being rewritten to ignore the byte order mark on input and add it on output. UTF-16 files are also fairly common on Windows, but not in other systems.[18][19]
Popularity internally in software
In the memory of a computer program, usage of UTF-16 is very common, particularly in Windows but and also in JavaScript, Qt, and many other cross-platform software libraries. Compatibility with the Windows API is a major reason for this.
At one time it was believed by many (and is still believed today by some) that having fixed-size code units offers computational advantages, which led many systems, in particular Windows, to use the fixed-size UCS-2 with two bytes per character. This is false: strings are almost never randomly accessed, and sequential access is the same speed. In addition, even UCS-2 was not "fixed size" if combining characters are considered, and when Unicode exceeded 65536 code points it had to be replaced with the non-fixed-sized UTF-16 anyway.
Recently it has become clear that the overhead of translating from/to UTF-8 on input and output, and dealing with potential encoding errors in the input UTF-8, vastly overwhelms any savings UTF-16 could offer. So newer software systems are starting to use UTF-8. International Components for Unicode (ICU) has historically only used UTF-16, and still does only for Java, while it now supports UTF-8 (for C/C++ and other languages indirectly), e.g. used that way by Microsoft; supported as the "Default Charset"[20] including the correct handling of "illegal UTF-8".[21] The default string primitive used in newer programing languages, such as Go,[22] Julia, Rust and Swift 5,[23] assume UTF-8 encoding. PyPy is also using UTF-8 for its strings,[24] and Python is looking into storing all strings with UTF-8.[25] Microsoft now recommends the use of UTF-8 for applications using the Windows API, while continuing to maintain a legacy "Unicode" (meaning UTF-16) interface.[26]
References
- Davis, Mark (2012-02-03). "Unicode over 60 percent of the web". Official Google Blog. Archived from the original on 2018-08-09. Retrieved 2020-07-24.
- Davis, Mark (2008-05-05). "Moving to Unicode 5.1". Official Google Blog. Retrieved 2023-03-13.
- "Usage Survey of Character Encodings broken down by Ranking". w3techs.com. Retrieved 2023-10-01.
- "Usage statistics and market share of ASCII for websites, October 2021". w3techs.com. Retrieved 2020-11-01.
- "Distribution of Character Encodings among websites that use China and territories". w3techs.com. Retrieved 2023-10-01.
- "Distribution of Character Encodings among websites that use .cn". w3techs.com. Retrieved 2021-11-01.
- "Distribution of Character Encodings among websites that use Chinese". w3techs.com. Retrieved 2021-11-01.
- The Chinese standard GB 2312 and with its extension GBK (which are both interpreted by web browsers as GB 18030, having support for the same letters as UTF-8)
- "Distribution of Character Encodings among websites that use Taiwan". w3techs.com. Retrieved 2023-07-07.
- "Distribution of Character Encodings among websites that use .ru". w3techs.com. Retrieved 2023-09-01.
- "Distribution of Character Encodings among websites that use Greek". w3techs.com. Retrieved 2022-11-01.
- "Distribution of Character Encodings among websites that use Hebrew". w3techs.com. Retrieved 2022-10-25.
- "Historical trends in the usage of character encodings". Retrieved 2023-09-01.
- "UTF-8 Usage Statistics". BuiltWith. Retrieved 2011-03-28.
- "Usage Report of UTF-8 broken down by Content Languages". w3techs.com. Retrieved 2023-10-01.
- "ХҮМҮҮН БИЧИГ" [Human papers]. khumuunbichig.montsame.mn (in Mongolian). Montsame News Agency. Retrieved 2022-10-26.
- "Distribution of Character Encodings among websites that use Sign Languages". w3techs.com. Retrieved 2018-12-03.
- "Charset". Android Developers. Retrieved 2021-01-02.
Android note: The Android platform default is always UTF-8.
- Galloway, Matt (9 October 2012). "Character encoding for iOS developers. Or UTF-8 what now?". www.galloway.me.uk. Retrieved 2021-01-02.
in reality, you usually just assume UTF-8 since that is by far the most common encoding.
- "UTF-8 - ICU User Guide". userguide.icu-project.org. Retrieved 2018-04-03.
- "#13311 (change illegal-UTF-8 handling to Unicode "best practice")". bugs.icu-project.org. Retrieved 2018-04-03.
- "The Go Programming Language Specification". Retrieved 2021-02-10.
- Tsai, Michael J. "Michael Tsai - Blog - UTF-8 String in Swift 5". Retrieved 2021-03-15.
- Mattip (2019-03-24). "PyPy Status Blog: PyPy v7.1 released; now uses utf-8 internally for unicode strings". PyPy Status Blog. Retrieved 2020-11-21.
- "PEP 623 -- Remove wstr from Unicode". Python.org. Retrieved 2020-11-21.
Until we drop legacy Unicode object, it is very hard to try other Unicode implementation like UTF-8 based implementation in PyPy.
- "Use the Windows UTF-8 code page". UWP applications. docs.microsoft.com. Retrieved 2020-06-06.