Population proportion
In statistics, a population proportion, generally denoted by or the Greek letter ,[1] is a parameter that describes a percentage value associated with a population. For example, the 2010 United States Census showed that 83.7% of the American population was identified as not being Hispanic or Latino; the value of .837 is a population proportion. In general, the population proportion and other population parameters are unknown. A census can be conducted in order to determine the actual value of a population parameter, but often a census is not practical due to its costs and time consumption.


A population proportion is usually estimated through an unbiased sample statistic obtained from an observational study or experiment. For example, the National Technological Literacy Conference conducted a national survey of 2,000 adults to determine the percentage of adults who are economically illiterate. The study showed that 72% of the 2,000 adults sampled did not understand what a gross domestic product is.[2] The value of 72% is a sample proportion. The sample proportion is generally denoted by and in some textbooks by .[3][4]


Mathematical definition
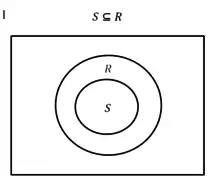


A proportion is mathematically defined as being the ratio of the quantity of elements (a countable quantity) in a subset to the size of a set :

where is the count of successes in the population, and is the size of the population.


This mathematical definition can be generalized to provide the definition for the sample proportion:

where is the count of successes in the sample, and is the size of the sample obtained from the population.[5][3]


Estimation
One of the main focuses of study in inferential statistics is determining the "true" value of a parameter. Generally, the actual value for a parameter will never be found, unless a census is conducted on the population of study. However, there are statistical methods that can be used to get a reasonable estimation for a parameter. These methods include confidence intervals and hypothesis testing.
Estimating the value of a population proportion can be of great implication in the areas of agriculture, business, economics, education, engineering, environmental studies, medicine, law, political science, psychology, and sociology.
A population proportion can be estimated through the usage of a confidence interval known as a one-sample proportion in the Z-interval whose formula is given below:

where is the sample proportion, is the sample size, and is the upper critical value of the standard normal distribution for a level of confidence .[6]



Proof
In order to derive the formula for the one-sample proportion in the Z-interval, a sampling distribution of sample proportions needs to be taken into consideration. The mean of the sampling distribution of sample proportions is usually denoted as and its standard deviation is denoted as:[3]


Since the value of is unknown, an unbiased statistic will be used for . The mean and standard deviation are rewritten respectively as:
- and


Invoking the central limit theorem, the sampling distribution of sample proportions is approximately normal—provided that the sample is reasonably large and unskewed.
Suppose the following probability is calculated:
- ,

where and are the standard critical values.



The inequality

can be algebraically re-written as follows:

From the algebraic work done above, it is evident from a level of certainty that could fall in between the values of:
- .
Conditions for inference
In general, the formula used for estimating a population proportion requires substitutions of known numerical values. However, these numerical values cannot be "blindly" substituted into the formula because statistical inference requires that the estimation of an unknown parameter be justifiable. In order for a parameter's estimation to be justifiable, there are three conditions that need to be verified:
- The data's individual observation have to be obtained from a simple random sample of the population of interest.
- The data's individual observations have to display normality. This can be verified mathematically with the following definition:
- Let be the sample size of a given random sample and let be its sample proportion. If and , then the data's individual observations display normality.
- The data's individual observations have to be independent of each other. This can be verified mathematically with the following definition:
- Let be the size of the population of interest and let be the sample size of a simple random sample of the population. If , then the data's individual observations are independent of each other.



The conditions for SRS, normality, and independence are sometimes referred to as the conditions for the inference tool box in most statistical textbooks.
Example
Suppose a presidential election is taking place in a democracy. A random sample of 400 eligible voters in the democracy's voter population shows that 272 voters support candidate B. A political scientist wants to determine what percentage of the voter population support candidate B.
To answer the political scientist's question, a one-sample proportion in the Z-interval with a confidence level of 95% can be constructed in order to determine the population proportion of eligible voters in this democracy that support candidate B.
Solution
It is known from the random sample that with sample size . Before a confidence interval is constructed, the conditions for inference will be verified.


- Since a random sample of 400 voters was obtained from the voting population, the condition for a simple random sample has been met.
- Let and , it will be checked whether and

- and


- The condition for normality has been met.
- Let be the size of the voter population in this democracy, and let . If , then there is independence.

- The population size for this democracy's voters can be assumed to be at least 4,000. Hence, the condition for independence has been met.
With the conditions for inference verified, it is permissible to construct a confidence interval.
Let and


To solve for , the expression is used.

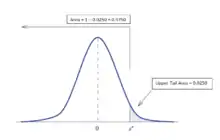

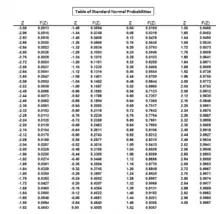

By examining a standard normal bell curve, the value for can be determined by identifying which standard score gives the standard normal curve an upper tail area of 0.0250 or an area of 1 - 0.0250 = 0.9750. The value for can also be found through a table of standard normal probabilities.
From a table of standard normal probabilities, the value of that gives an area of 0.9750 is 1.96. Hence, the value for is 1.96.

The values for , , can now be substituted into the formula for one-sample proportion in the Z-interval:



Based on the conditions of inference and the formula for the one-sample proportion in the Z-interval, it can be concluded with a 95% confidence level that the percentage of the voter population in this democracy supporting candidate B is between 63.429% and 72.571%.
Value of the parameter in the confidence interval range
A commonly asked question in inferential statistics is whether the parameter is included within a confidence interval. The only way to answer this question is for a census to be conducted. Referring to the example given above, the probability that the population proportion is in the range of the confidence interval is either 1 or 0. That is, the parameter is included in the interval range or it is not. The main purpose of a confidence interval is to better illustrate what the ideal value for a parameter could possibly be.
Common errors and misinterpretations from estimation
A very common error that arises from the construction of a confidence interval is the belief that the level of confidence, such as , means 95% chance. This is incorrect. The level of confidence is based on a measure of certainty, not probability. Hence, the values of fall between 0 and 1, exclusively.

See also
References
- Introduction to Statistical Investigations. Wiley. 18 August 2014. ISBN 978-1-118-95667-0.
- Ott, R. Lyman (1993). An Introduction to Statistical Methods and Data Analysis. ISBN 0-534-93150-2.
- Weisstein, Eric W. "Sample Proportion". mathworld.wolfram.com. Retrieved 2020-08-22.
- "6.3: The Sample Proportion". Statistics LibreTexts. 2014-04-16. Retrieved 2020-08-22.
- Weisstein, Eric (1998). CRC Concise Encyclopedia of Mathematics. Chapman & Hall/CRC. Bibcode:1998ccem.book.....W.
- Hinders, Duane (2008). Annotated Teacher's Edition The Practice of Statistics. ISBN 978-0-7167-7703-8.
- Abbasi, Azhar Mehmood; Yousaf Shad, Muhammad (2021-05-15). "Estimation of population proportion using concomitant based ranked set sampling". Communications in Statistics - Theory and Methods. 51 (9): 2689–2709. doi:10.1080/03610926.2021.1916529. ISSN 0361-0926. S2CID 236554602.
- Abbasi, Azhar Mehmood; Shad, Muhammad Yousaf (2021-05-15). "Estimation of population proportion using concomitant based ranked set sampling". Communications in Statistics - Theory and Methods. 51 (9): 2689–2709. doi:10.1080/03610926.2021.1916529. ISSN 0361-0926. S2CID 236554602.