rCUDA
rCUDA, which stands for Remote CUDA, is a type of middleware software framework for remote GPU virtualization. Fully compatible with the CUDA application programming interface (API), it allows the allocation of one or more CUDA-enabled GPUs to a single application. Each GPU can be part of a cluster or running inside of a virtual machine. The approach is aimed at improving performance in GPU clusters that are lacking full utilization. GPU virtualization reduces the number of GPUs needed in a cluster, and in turn, leads to a lower cost configuration – less energy, acquisition, and maintenance.
 | |
| Developer(s) | Universitat Politecnica de Valencia |
|---|---|
| Stable release | 20.07
/ July 26, 2020 |
| Operating system | Linux |
| Type | GPGPU |
| Website | rcuda |
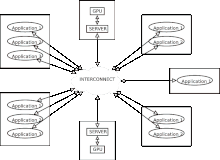
The recommended distributed acceleration architecture is a high performance computing cluster with GPUs attached to only a few of the cluster nodes. When a node without a local GPU executes an application needing GPU resources, remote execution of the kernel is supported by data and code transfers between local system memory and remote GPU memory. rCUDA is designed to accommodate this client-server architecture. On one end, clients employ a library of wrappers to the high-level CUDA Runtime API, and on the other end, there is a network listening service that receives requests on a TCP port. Several nodes running different GPU-accelerated applications can concurrently make use of the whole set of accelerators installed in the cluster. The client forwards the request to one of the servers, which accesses the GPU installed in that computer and executes the request in it. Time-multiplexing the GPU, or in other words sharing it, is accomplished by spawning different server processes for each remote GPU execution request.[1][2][3][4][5][6]
rCUDA v20.07
The rCUDA middleware enables the concurrent usage of CUDA-compatible devices remotely.
rCUDA employs either the InfiniBand network or the socket API for the communication between clients and servers. rCUDA can be useful in three different environments:
- Clusters. To reduce the number of GPUs installed in High Performance Clusters. This leads to energy savings, as well as other related savings like acquisition costs, maintenance, space, cooling, etc.
- Academia. In commodity networks, to offer access to a few high performance GPUs concurrently to many students.
- Virtual Machines. To enable the access to the CUDA facilities on the physical machine.
The current version of rCUDA (v20.07) supports CUDA version 9.0, excluding graphics interoperability. rCUDA v20.07 targets the Linux OS (for 64-bit architectures) on both client and server sides.
CUDA applications do not need any change in their source code in order to be executed with rCUDA.
References
- J. Prades; F. Silla (December 2019). "GPU-Job Migration: the rCUDA Case". Transactions on Parallel and Distributed Systems, vol 30, no. 12.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link) - J. Prades; C. Reaño; F. Silla (March 2019). "On the Effect of using rCUDA to Provide CUDA Acceleration to Xen Virtual Machines". Cluster Computing, vol.22, no. 1.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link) - F. Silla; S. Iserte; C. Reaño; J. Prades (July 2017). "On the Benefits of the Remote GPU Virtualization Mechanism: the rCUDA Case". Concurrency and Computation: Practice and Experience, vol. 29, no. 13.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link) - J. Prades; B. Varghese; C. Reaño; F. Silla (October 2017). "Multi-Tenant Virtual GPUs for Optimising Performance of a Financial Risk Application". Journal of Parallel and Distributed Computing, vol. 108. arXiv:1606.04473.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link) - F. Pérez; C. Reaño; F. Silla (June 6–9, 2016). "Providing CUDA Acceleration to KVM Virtual Machines in InfiniBand Clusters with rCUDA". 16th IFIP International Conference on Distributed Applications and Interoperable Systems (DAIS 2016), Heraklion, Crete, Greece.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link) - S. Iserte; J. Prades; C. Reaño; F. Silla (May 16–19, 2016). "Increasing the Performance of Data Centers by Combining Remote GPU Virtualization with Slurm". 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID 2016), Cartagena, Colombia.
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: location (link)