Recursive Internetwork Architecture
The Recursive InterNetwork Architecture (RINA) is a new computer network architecture proposed as an alternative to the architecture of the currently mainstream Internet protocol suite. The principles behind RINA were first presented by John Day in his 2008 book Patterns in Network Architecture: A return to Fundamentals.[1] This work is a start afresh, taking into account lessons learned in the 35 years of TCP/IP’s existence, as well as the lessons of OSI’s failure and the lessons of other network technologies of the past few decades, such as CYCLADES, DECnet, and Xerox Network Systems. RINA's fundamental principles are that computer networking is just Inter-Process Communication or IPC, and that layering should be done based on scope/scale, with a single recurring set of protocols, rather than based on function, with specialized protocols. The protocol instances in one layer interface with the protocol instances on higher and lower layers via new concepts and entities that effectively reify networking functions currently specific to protocols like BGP, OSPF and ARP. In this way, RINA claims to support features like mobility, multihoming and quality of service without the need for additional specialized protocols like RTP and UDP, as well as to allow simplified network administration without the need for concepts like autonomous systems and NAT.
Overview
RINA is the result of an effort to work out general principles in computer networking that apply in all situations. RINA is the specific architecture, implementation, testing platform and ultimately deployment of the model informally known as the IPC model,[2] although it also deals with concepts and results that apply to any distributed application, not just to networking. Coming from distributed applications, most of the terminology comes from application development instead of networking, which is understandable, given that RINA's fundamental principle is to reduce networking to IPC.
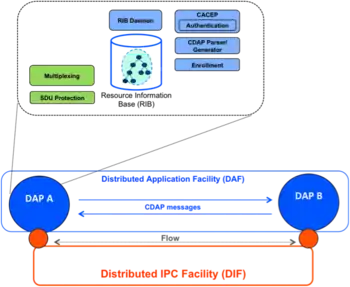
The basic entity of RINA is the Distributed Application Process or DAP, which frequently corresponds to a process on a host. Two or more DAPs constitute a Distributed Application Facility or DAF, as illustrated in Figure 1. These DAPs communicate using the Common Distributed Application Protocol or CDAP, exchanging structured data in the form of objects. These objects are structured in a Resource Information Base or RIB, which provides a naming schema and a logical organization to them. CDAP provides six basic operations on a remote DAP's objects: create, delete, read, write, start and stop.
In order to exchange information, DAPs need an underlying facility whose task is to provide and manage IPC services over a certain scope. This facility is another DAF, called a Distributed IPC Facility or DIF. A DIF enables a DAP to allocate flows to one or more DAPs, by just providing the names of the targeted DAPs and the desired QoS parameters such as bounds on data loss and latency, ordered or out-of-order delivery, reliability, and so forth. For example, DAPs may not trust the DIF they are using and may therefore protect their data before writing it to the flow via a SDU protection module, for example by encrypting it. The DAPs of a DIF are called IPC Processes or IPCPs. They have the same generic DAP structure shown in Figure 3, plus some specific tasks to provide and manage IPC. These tasks, as shown in Figure 4, can be divided into three categories, in order of increasing complexity and decreasing frequency:
- data transfer,
- data transfer control and
- layer management.
A DAF thus corresponds to the application layer, and a DIF to the layer immediately below, in most contemporary network models, and the three previous task categories correspond to the vast majority of tasks of not just network operations, but network management and even authentication (with some adjustments in responsibility as will be seen below).
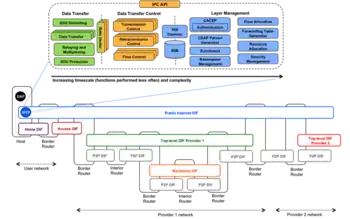
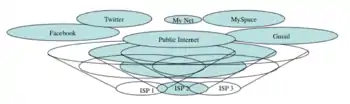
DIFs, being DAFs, in turn use other underlying DIFs themselves, going all the way down to the physical layer DIF controlling the wires and jacks. This is where the recursion of RINA comes from. All RINA layers have the same structure and components and provide the same functions; they differ only in their scopes, configurations or policies (mirroring the separation of mechanism and policy in operating systems).[3] As shown in Figure 2, RINA networks are usually structured in DIFs of increasing scope. Figure 3 shows an example of how the Web could be structured with RINA: the highest layer is the one closest to applications, corresponding to email or websites; the lowest layers aggregate and multiplex the traffic of the higher layers, corresponding to ISP backbones. Multi-provider DIFs (such as the public Internet or others) float on top of the ISP layers. In this model, three types of systems are distinguished: hosts, which contain DAPs; interior routers, internal to a layer; and border routers, at the edges of a layer, where packets go up or down one layer.
In short, RINA keeps the concepts of PDU and SDU, but instead of layering by function, it layers by scope. Layers correspond not to different responsibilities, but different scales, and the model is specifically designed to be applicable from a single point-to-point Ethernet connection all the way up to the Web. RINA is therefore an attempt to reuse as much theory as possible and eliminate the need for ad-hoc protocol design, and thus reduce the complexity of network construction, management and operation in the process.
Naming, addressing, routing, mobility and multihoming
As explained above, the IP address is too low-level an identifier on which to base multihoming and mobility efficiently, as well as requiring routing tables to be bigger than necessary. RINA literature follows the general theory of Jerry Saltzer on addressing and naming. According to Saltzer, four elements need to be identified: applications, nodes, attachment points and paths.[4] An application can run in one or more nodes and should be able to move from one node to another without losing its identity in the network. A node can be connected to a pair of attachment points and should be able to move between them without losing its identity in the network. A directory maps an application name to a node address, and routes are sequences of node addresses and attachment points. These points are illustrated in Figure 4.
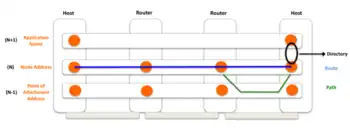
Saltzer took his model from operating systems, but the RINA authors concluded it could not be applied cleanly to internetworks, which can have more than one path between the same pair of nodes (let alone whole networks). Their solution is to model routes as sequences of nodes: at each hop, the respective node chooses the most appropriate attachment point to forward the packet to the next node. Therefore, RINA routes in a two-step process: first, the route as a sequence of node addresses is calculated, and then, for each hop, an appropriate attachment point is selected. These are the steps to generate the forwarding table: forwarding is still performed with a single lookup. Moreover, the last step can be performed more frequently to exploit multihoming for load balancing.
With this naming structure, mobility and multihoming are inherently supported[5] if the names have carefully chosen properties:
- application names are location-independent to allow an application to move around;
- node addresses are location-dependent but route-independent; and
- attachment points are by nature route-dependent.
Applying this naming scheme to RINA with its recursive layers allows the conclusion that mapping application names to node addresses is analogous to mapping node addresses to attachment points. Put simply, at any layer, nodes in the layer above can be seen as applications while nodes in the layer below can be seen as attachment points.
Protocol design
The Internet protocol suite also generally dictates that protocols be designed in isolation, without regard to whether aspects have been duplicated in other protocols and, therefore, whether these can be made into a policy. RINA tries to avoid this by applying the separation of mechanism and policy in operating systems to protocol design.[6] Each DIF uses different policies to provide different classes of quality of service and adapt to the characteristics of either the physical media, if the DIF is low-level, or the applications, if the DIF is high-level.
RINA uses the theory of the Delta-T protocol[7] developed by Richard Watson in 1981. Watson's research suggests that sufficient conditions for reliable transfer are to bound three timers. Delta-T is an example of how this should work: it does not have a connection setup or tear-down. The same research also notes that TCP already uses these timers in its operation, making Delta-T comparatively simpler. Watson's research also suggests that synchronization and port allocation should be distinct functions, port allocation being part of layer management, and synchronization being part of data transfer.
Security
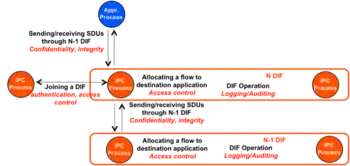
To accommodate security, RINA requires each DIF/DAF to specify a security policy, whose functions are shown in Figure 5. This allows securing not just applications, but backbones and switching fabrics themselves. A public network is simply a special case where the security policy does nothing. This may introduce overhead for smaller networks, but it scales better with larger networks because layers do not need to coordinate their security mechanisms: the current Internet is estimated as requiring around 5 times more distinct security entities than RINA.[8] Among other things, the security policy can also specify an authentication mechanism; this obsoletes firewalls and blacklists because a DAP or IPCP that can't join a DAF or DIF can't transmit or receive. DIFs also do not expose their IPCP addresses to higher layers, preventing a wide class of man-in-the-middle attacks.
The design of the Delta-T protocol itself, with its emphasis on simplicity, is also a factor. For example, since the protocol has no handshake, it has no corresponding control messages that can be forged or state that can be misused, like that in a SYN flood. The synchronization mechanism also makes aberrant behavior more correlated with intrusion attempts, making attacks far easier to detect.[9]
Background
The starting point for a radically new and different network architecture like RINA is an attempt to solve or a response to the following problems which do not appear to have practical or compromise-free solutions with current network architectures, especially the Internet protocol suite and its functional layering as depicted in Figure 6:
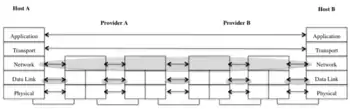
- Transmission complexity: the separation of IP and TCP results in inefficiency, with the MTU discovery performed to prevent IP fragmentation being the clearest symptom.
- Performance: TCP itself carries rather high overhead with its handshake, which also causes vulnerabilities such as SYN floods. Also, TCP relies on packet dropping to throttle itself and avoid congestion, meaning its congestion control is purely reactive, not proactive or preventive. This interacts badly with large buffers, leading to bufferbloat.[10]
- Multihoming: the IP address and port number are too low-level to identify an application in two different networks. DNS doesn't solve this because hostnames must resolve to a single IP address and port number combination, making them aliases instead of identities. Neither does LISP, because i) it still uses the locator, which is an IP address, for routing, and ii) it is based on a false distinction, in that all entities in a scope are located by their identifiers to begin with;[11] in addition, it also introduces scalability problems of its own.[12]
- Mobility: the IP address and port number are also too low-level to identify an application as it moves between networks, resulting in complications for mobile devices such as smartphones. Though a solution, Mobile IP in reality shifts the problem entirely to the Care-of address and introduces an IP tunnel, with attendant complexity.
- Management: the same low-level nature of the IP address encourages multiple addresses or even address ranges to be allocated to single hosts,[13] putting pressure on allocation and accelerating exhaustion. NAT only delays address exhaustion and potentially introduces even more problems. At the same time, functional layering of the Internet protocol suite's architecture leaves room for only two scopes, complicating subdivision of administration of the Internet and requiring the artificial notion of autonomous systems. OSPF and IS-IS have relatively few problems, but do not scale well, forcing usage of BGP for larger networks and inter-domain routing.
- Security: the nature of the IP address space itself results in frail security, since there is no true configurable policy for adding or removing IP addresses other than physically preventing attachment. TLS and IPSec provide solutions, but with accompanying complexity. Firewalls and blacklists are vulnerable to overwhelming, ergo not scalable. "[...] experience has shown that it is difficult to add security to a protocol suite unless it is built into the architecture from the beginning."[14]
Though these problems are far more acutely visible today, there have been precedents and cases almost right from the beginning of the ARPANET, the environment in which the Internet protocol suite was designed:
1972: Multihoming not supported by the ARPANET
In 1972, Tinker Air Force Base[15] wanted connections to two different IMPs for redundancy. ARPANET designers realized that they couldn't support this feature because host addresses were the addresses of the IMP port number the host was connected to (borrowing from telephony). To the ARPANET, two interfaces of the same host had different addresses; in other words, the address was too low-level to identify a host.
1978: TCP split from IP
Initial TCP versions performed the error and flow control (current TCP) and relaying and multiplexing (IP) functions in the same protocol. In 1978 TCP was split from IP even though the two layers had the same scope. By 1987, the networking community was well aware of IP fragmentation's problems, to the point of considering it harmful.[16] However, it was not understood as a symptom that TCP and IP were interdependent.
1981: Watson's fundamental results ignored
Richard Watson in 1981 provided a fundamental theory of reliable transport[17] whereby connection management requires only timers bounded by a small factor of the Maximum Packet Lifetime (MPL). Based on this theory, Watson et al. developed the Delta-t protocol [7] which allows a connection's state to be determined simply by bounding three timers, with no handshaking. On the other hand, TCP uses both explicit handshaking as well as more limited timer-based management of the connection's state.
1983: Internetwork layer lost
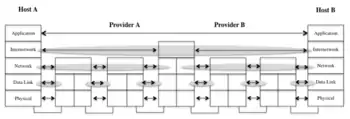
Early in 1972 the International Networking Working Group (INWG) was created to bring together the nascent network research community. One of the early tasks it accomplished was voting an international network transport protocol, which was approved in 1976.[18] Remarkably, the selected option, as well as all the other candidates, had an architecture composed of three layers of increasing scope: data link (to handle different types of physical media), network (to handle different types of networks) and internetwork (to handle a network of networks), each layer with its own address space. When TCP/IP was introduced it ran at the internetwork layer on top of the Host-IMP Protocol, when running over the ARPANET. But when NCP was shut down, TCP/IP took the network role and the internetwork layer was lost.[19] This explains the need for autonomous systems and NAT today, to partition and reuse ranges of the IP address space to facilitate administration.
1983: First opportunity to fix addressing missed
The need for an address higher-level than the IP address was well understood since the mid-1970s. However, application names were not introduced and DNS was designed and deployed, continuing to use well-known ports to identify applications. The advent of the web and HTTP created a need for application names, leading to URLs. URLs, however, tie each application instance to a physical interface of a computer and a specific transport connection, since the URL contains the DNS name of an IP interface and TCP port number, spilling the multihoming and mobility problems to applications.
1986: Congestion collapse takes the Internet by surprise
Though the problem of congestion control in datagram networks had been known since the 1970s and early 80s,[20][21] the congestion collapse in 1986 caught the Internet by surprise. What is worse, the adopted congestion control - the Ethernet congestion avoidance scheme, with a few modifications - was put in TCP.
1988: Network management takes a step backward
In 1988 IAB recommended using SNMP as the initial network management protocol for the Internet to later transition to the object-oriented approach of CMIP.[22] SNMP was a step backwards in network management, justified as a temporary measure while the required more sophisticated approaches were implemented, but the transition never happened.
1992: Second opportunity to fix addressing missed
In 1992 the IAB produced a series of recommendations to resolve the scaling problems of the IPv4-based Internet: address space consumption and routing information explosion. Three options were proposed: introduce CIDR to mitigate the problem; design the next version of IP (IPv7) based on CLNP; or continue the research into naming, addressing and routing.[23] CLNP was an OSI-based protocol that addressed nodes instead of interfaces, solving the old multihoming problem dating back to the ARPANET, and allowing for better routing information aggregation. CIDR was introduced, but the IETF didn't accept an IPv7 based on CLNP. IAB reconsidered its decision and the IPng process started, culminating with IPv6. One of the rules for IPng was not to change the semantics of the IP address, which continues to name the interface, perpetuating the multihoming problem.[13]
Research projects
From the publishing of the PNA book in 2008 to 2014, a lot of RINA research and development work has been done. An informal group known as the Pouzin Society, named after Louis Pouzin,[24] coordinates several international efforts.
BU Research Team
The RINA research team at Boston University is led by Professors Abraham Matta, John Day and Lou Chitkushev, and has been awarded a number of grants from the National Science Foundation and EC in order to continue investigating the fundamentals of RINA, develop an open source prototype implementation over UDP/IP for Java [25][26] and experiment with it on top of the GENI infrastructure.[27][28] BU is also a member of the Pouzin Society and an active contributor to the FP7 IRATI and PRISTINE projects. In addition to this, BU has incorporated RINA concepts and theory in their computer networking courses.
FP7 IRATI
IRATI is an FP7-funded project with 5 partners: i2CAT, Nextworks, iMinds, Interoute and Boston University. It has produced an open source RINA implementation for the Linux OS on top of Ethernet.[29][30]
FP7 PRISTINE
PRISTINE is an FP7-funded project with 15 partners: WIT-TSSG, i2CAT, Nextworks, Telefónica I+D, Thales, Nexedi, B-ISDN, Atos, University of Oslo, Juniper Networks, Brno University, IMT-TSP, CREATE-NET, iMinds and UPC. Its main goal is to explore the programmability aspects of RINA to implement innovative policies for congestion control, resource allocation, routing, security and network management.
GÉANT3+ Open Call winner IRINA
IRINA was funded by the GÉANT3+ open call, and is a project with four partners: iMinds, WIT-TSSG, i2CAT and Nextworks. The main goal of IRINA is to study the use of the Recursive InterNetwork Architecture (RINA) as the foundation of the next generation NREN and GÉANT network architectures. IRINA builds on the IRATI prototype and will compare RINA against current networking state of the art and relevant clean-slate architecture under research; perform a use-case study of how RINA could be better used in the NREN scenarios; and showcase a laboratory trial of the study.
See also
References
- Patterns in Network Architecture: A Return to Fundamentals, John Day (2008), Prentice Hall, ISBN 978-0-13-225242-3
- Day, John; Matta, Ibrahim; Mattar, Karim (2008). "Networking is IPC: A guiding principle to a better internet". Proceedings of the 2008 ACM CoNEXT Conference on - CONEXT '08. pp. 1–6. doi:10.1145/1544012.1544079. ISBN 978-1-60558-210-8. S2CID 3287224.
- Mattar, Karim; Matta, Ibrahim; Day, John; Ishakian, Vatche; Gursun, Gonca (12 July 2008). Declarative Transport: No More Transport Protocols to Design, Only Policies to Specify (Report). hdl:2144/1707.
- J. Saltzer. On the Naming and Binding of Network Destinations. RFC 1498 (Informational), August 1993
- Ishakian, Vatche; Akinwumi, Joseph; Esposito, Flavio; Matta, Ibrahim (July 2012). "On supporting mobility and multihoming in recursive internet architectures". Computer Communications. 35 (13): 1561–1573. doi:10.1016/j.comcom.2012.04.027. S2CID 3036132.
- Hansen, Per Brinch (April 1970). "The nucleus of a multiprogramming system". Communications of the ACM. 13 (4): 238–241. doi:10.1145/362258.362278. S2CID 9414037.
- Watson, R.W. (4 December 1981). Delta-t protocol specification: working draft (Report). doi:10.2172/5542785.
- Small, Jeremiah (2012). Patterns in network security: an analysis of architectural complexity in securing recursive inter-network architecture networks (Thesis). hdl:2144/17155.
- Boddapati, Gowtham; Day, John; Matta, Ibrahim; Chitkushev, Lou (2012). "Assessing the security of a clean-slate Internet architecture". 2012 20th IEEE International Conference on Network Protocols (ICNP). pp. 1–6. doi:10.1109/ICNP.2012.6459947. ISBN 978-1-4673-2447-2. S2CID 7500711.
- Pouzin, L. (April 1981). "Methods, Tools, and Observations on Flow Control in Packet-Switched Data Networks". IEEE Transactions on Communications. 29 (4): 413–426. doi:10.1109/TCOM.1981.1095015.
- Day, John (2008). Why Loc/Id Split Isn't the Answer (PDF) (Report).
- D. Meyer and D. Lewis. Architectural Implications of Locator/ID separation. https://tools.ietf.org/html/draft-meyer-loc-id-implications-01
- R. Hinden and S. Deering. "IP Version 6 Addressing Architecture". RFC 4291 (Draft Standard), February 2006. Updated by RFCs 5952, 6052
- D. Clark, L. Chapin, V. Cerf, R. Braden and R. Hobby. Towards the Future Internet Architecture. RFC 1287 (Informational), December 1991
- Fritz. E Froehlich; Allen Kent (1992). "ARPANET, the Defense Data Network, and Internet". The Froehlich/Kent Encyclopedia of Telecommunications. Vol. 5. CRC Press. p. 82. ISBN 978-0-8247-2903-5.
- Kent, C. A.; Mogul, J. C. (1987). "Fragmentation considered harmful". Proceedings of the ACM workshop on Frontiers in computer communications technology. pp. 390–401. doi:10.1145/55482.55524. ISBN 978-0-89791-245-7. S2CID 10042690.
- Watson, Richard W (1981). "Timer-based mechanism in reliable transport protocol connection management". Computer Networks. 5 (1): 47–56. doi:10.1016/0376-5075(81)90031-3.
- McKenzie, Alexander (2011). "INWG and the Conception of the Internet: An Eyewitness Account". IEEE Annals of the History of Computing. 33: 66–71. doi:10.1109/MAHC.2011.9. S2CID 206443072.
- Day, John (2011). "How in the Heck do you lose a layer!?". 2011 International Conference on the Network of the Future. pp. 135–143. doi:10.1109/NOF.2011.6126673. ISBN 978-1-4577-1607-2. S2CID 15198377.
- Pouzin, L. (April 1981). "Methods, Tools, and Observations on Flow Control in Packet-Switched Data Networks". IEEE Transactions on Communications. 29 (4): 413–426. doi:10.1109/TCOM.1981.1095015.
- Lam; Lien (October 1981). "Congestion Control of Packet Communication Networks by Input Buffer Limits—A Simulation Study". IEEE Transactions on Computers. C-30 (10): 733–742. doi:10.1109/TC.1981.1675692.
- Internet Architecture Board. IAB Recommendations for the Development of Internet Network Management Standards. RFC 1052, April 1988
- Internet Architecture Board. IP Version 7 ** DRAFT 8 **. Draft IAB IPversion7, july 1992
- Russell, Andrew L.; Schafer, Valérie (2014). "In the Shadow of ARPANET and Internet: Louis Pouzin and the Cyclades Network in the 1970s". Technology and Culture. 55 (4): 880–907. doi:10.1353/tech.2014.0096. S2CID 143582561. Project MUSE 562835.
- Esposito, Flavio; Wang, Yuefeng; Matta, Ibrahim; Day, John (April 2013). Dynamic Layer Instantiation as a Service (PDF). USENIX Symposium on Networked Systems Design and Implementation (NSDI ’13).
- Wang, Yuefeng; Matta, Ibrahim; Esposito, Flavio; Day, John (28 July 2014). "Introducing ProtoRINA: a prototype for programming recursive-networking policies". ACM SIGCOMM Computer Communication Review. 44 (3): 129–131. doi:10.1145/2656877.2656897. S2CID 1007699.
- Wang, Yuefeng; Esposito, Flavio; Matta, Ibrahim (2013). "Demonstrating RINA Using the GENI Testbed". 2013 Second GENI Research and Educational Experiment Workshop. pp. 93–96. doi:10.1109/GREE.2013.26. ISBN 978-0-7695-5003-9. S2CID 6735043.
- Wang, Yuefeng; Matta, Ibrahim; Akhtar, Nabeel (2014). "Experimenting with Routing Policies Using ProtoRINA over GENI". 2014 Third GENI Research and Educational Experiment Workshop. pp. 61–64. doi:10.1109/GREE.2014.11. ISBN 978-1-4799-5120-8. S2CID 16799199.
- Vrijders, Sander; Staessens, Dimitri; Colle, Didier; Salvestrini, Francesco; Grasa, Eduard; Tarzan, Miquel; Bergesio, Leonardo (March 2014). "Prototyping the recursive internet architecture: the IRATI project approach". IEEE Network. 28 (2): 20–25. doi:10.1109/MNET.2014.6786609. hdl:1854/LU-5730910. S2CID 7594551.
- Vrijders, Sander; Staessens, Dimitri; Colle, Didier; Salvestrini, Francesco; Maffione, Vincenzo; Bergesio, Leonardo; Tarzan-Lorente, Miquel; Gaston, Bernat; Grasa, Eduard (2014). "Experimental evaluation of a Recursive InterNetwork Architecture prototype". 2014 IEEE Global Communications Conference. pp. 2017–2022. doi:10.1109/GLOCOM.2014.7037104. hdl:1854/LU-5955523. ISBN 978-1-4799-3512-3. S2CID 13462659.
External links
- The Pouzin Society website: http://pouzinsociety.org
- RINA Education page at the IRATI website, available online at http://irati.eu/education/
- RINA document repository run by the TSSG, available online at http://rina.tssg.org
- RINA tutorial at the IEEE Globecom 2014 conference, available online at http://www.slideshare.net/irati-project/rina-tutorial-ieee-globecom-2014