Residual neural network
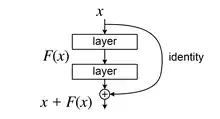
A Residual Neural Network (a.k.a. Residual Network, ResNet)[1] is a deep learning model in which the weight layers learn residual functions with reference to the layer inputs. A Residual Network[1] is a network with skip connections that perform identity mappings, merged with the layer outputs by addition. It behaves like a Highway Network[2] whose gates are opened through strongly positive bias weights. This enables deep learning models with tens or hundreds of layers to train easily and approach better accuracy when going deeper. The identity skip connections, often referred to as "residual connections", are also used in the 1997 LSTM networks,[3] Transformer models (e.g., BERT, GPT models such as ChatGPT), the AlphaGo Zero system, the AlphaStar system, and the AlphaFold system.
Residual Networks were developed by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, which won the ImageNet 2015 competition.[4][5]
Formulation
Background
The AlexNet model developed in 2012 for ImageNet was an 8-layer convolutional neural network. The neural networks developed in 2014 by the Visual Geometry Group (VGG) at the University of Oxford approached a depth of 19 layers by stacking 3-by-3 convolutional layers.[6] But stacking more layers led to a quick reduction in training accuracy,[7] which is referred to as the "degradation" problem.[1]
A deeper network should not produce a higher training loss than its shallower counterpart, if this deeper network can be constructed by its shallower counterpart stacked with extra layers.[1] If the extra layers can be set as identity mappings, the deeper network would represent the same function as the shallower counterpart. It is hypothesized that the optimizer is not able to approach identity mappings for the parameterized layers.
Residual Learning
In a multi-layer neural network model, consider a subnetwork with a certain number (e.g., 2 or 3) of stacked layers. Denote the underlying function performed by this subnetwork as , where is the input to this subnetwork. The idea of "Residual Learning" re-parameterizes this subnetwork and lets the parameter layers represent a residual function . The output of this subnetwork is represented as:





This is also the principle of the 1997 LSTM cell[3] computing , which becomes during backpropagation through time.


The function is often represented by matrix multiplication interlaced with activation functions and normalization operations (e.g., Batch Normalization or Layer Normalization).

This subnetwork is referred to as a "Residual Block".[1] A deep residual network is constructed by stacking a series of residual blocks.
The operation of "" in "" is approached by a skip connection that performs identity mapping and connects the input of a residual block with its output. This connection is often referred to as a "Residual Connection" in later work.[8]

Signal Propagation
The introduction of identity mappings facilitates signal propagation in both forward and backward paths. [9]
Forward Propagation
If the output of the -th residual block is the input to the -th residual block (i.e., assuming no activation function between blocks), we have:[9]



Applying this formulation recursively, e.g., , we have:


where is the index of any later residual block (e.g., the last block) and is the index of any earlier block. This formulation suggests that there is always a signal that is directly sent from a shallower block to a deeper block .

Backward Propagation
The Residual Learning formulation provides the added benefit of addressing the vanishing gradient problem to some extent. However, it is crucial to acknowledge that the vanishing gradient issue is not the root cause of the degradation problem, as it has already been tackled through the use of normalization layers. Taking the derivative w.r.t. according to the above forward propagation, we have:[9]


Here is the loss function to be minimized. This formulation suggests that the gradient computation of a shallower layer always has a term that is directly added. Even if the gradients of the terms are small, the total gradient is not vanishing thanks to the added term .




Variants of Residual Blocks
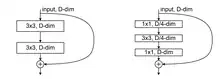
Basic Block
A Basic Block is the simplest building block studied in the original ResNet.[1] This block consists of two sequential 3x3 convolutional layers and a residual connection. The input and output dimensions of both layers are equal.
Bottleneck Block
A Bottleneck Block[1] consists of three sequential convolutional layers and a residual connection. The first layer in this block is a 1x1 convolution for dimension reduction, e.g., to 1/4 of the input dimension; the second layer performs a 3x3 convolution; the last layer is another 1x1 convolution for dimension restoration. The models of ResNet-50, ResNet-101, and ResNet-152 in [1] are all based on Bottleneck Blocks.
Pre-activation Block
The Pre-activation Residual Block[9] applies the activation functions (e.g., non-linearity and normalization) before applying the residual function . Formally, the computation of a Pre-activation Residual Block can be written as:


where can be any non-linearity activation (e.g., ReLU) or normalization (e.g., LayerNorm) operation. This design reduces the number of non-identity mappings between Residual Blocks. This design was used to train models with 200 to over 1000 layers.[9]

Since GPT-2, the Transformer Blocks have been dominantly implemented as Pre-activation Blocks. This is often referred to as "pre-normalization" in the literature of Transformer models.[10]
Transformer Block

A Transformer Block is a stack of two Residual Blocks. Each Residual Block has a Residual Connection.
The first Residual Block is a Multi-Head Attention Block, which performs (self-)attention computation followed by a linear projection.
The second Residual Block is a feed-forward Multi-Layer Perceptron (MLP) Block. This block is analogous to an "inverse" bottleneck block: it has a linear projection layer (which is equivalent to a 1x1 convolution in the context of Convolutional Neural Networks) that increases the dimension, and another linear projection that reduces the dimension.
A Transformer Block has a depth of 4 layers (linear projections). The GPT-3 model has 96 Transformer Blocks (in the literature of Transformers, a Transformer Block is often referred to as a "Transformer Layer"). This model has a depth of about 400 projection layers, including 96x4 layers in Transformer Blocks and a few extra layers for input embedding and output prediction.
Very deep Transformer models cannot be successfully trained without Residual Connections.[11]
Related Work
In the book[12] written by Frank Rosenblatt, published in 1961, a three-layer Multilayer Perceptron (MLP) model with skip connections was presented (Chapter 15, p313 in [12]). The model was referred to as a "cross-coupled system", and the skip connections were forms of cross-coupled connections.
In two books published in 1994 [13] and 1996,[14] "skip-layer" connections were presented in feed-forward MLP models: "The general definition [of MLP] allows more than one hidden layer, and it also allows 'skip-layer' connections from input to output" (p261 in,[13] p144 in [14]), "... which allows the non-linear units to perturb a linear functional form" (p262 in [13]). This description suggests that the non-linear MLP performs like a residual function (perturbation) added to a linear function.
Sepp Hochreiter analyzed the vanishing gradient problem in 1991 and attributed to it the reason why deep learning did not work well.[15] To overcome this problem, Long Short-Term Memory (LSTM) recurrent neural networks[3] had skip connections or residual connections with a weight of 1.0 in every LSTM cell (called the constant error carrousel) to compute . During backpropagation through time, this becomes the above-mentioned residual formula for feedforward neural networks. This enables training very deep recurrent neural networks with a very long time span t. A later LSTM version published in 2000[16] modulates the identity LSTM connections by so-called forget gates such that their weights are not fixed to 1.0 but can be learned. In experiments, the forget gates were initialized with positive bias weights,[16] thus being opened, addressing the vanishing gradient problem.
The Highway Network of May 2015[2][17] applies these principles to feedforward neural networks. It was reported to be "the first very deep feedforward network with hundreds of layers".[18] It is like an LSTM with forget gates unfolded in time,[16] while the later Residual Nets have no equivalent of forget gates and are like the unfolded original LSTM.[3] If the skip connections in Highway Networks are "without gates", or if their gates are kept open (activation 1.0) through strong positive bias weights, they become the identity skip connections in Residual Networks.
The original Highway Network paper[2] not only introduced the basic principle for very deep feedforward networks, but also included experimental results with 20, 50, and 100 layers networks, and mentioned ongoing experiments with up to 900 layers. Networks with 50 or 100 layers had lower training error than their plain network counterparts, but no lower training error than their 20 layers counterpart (on the MNIST dataset, Figure 1 in [2]). No improvement on test accuracy was reported with networks deeper than 19 layers (on the CIFAR-10 dataset; Table 1 in [2]). The ResNet paper,[9] however, provided strong experimental evidence of the benefits of going deeper than 20 layers. It argued that the identity mapping without modulation is crucial and mentioned that modulation in the skip connection can still lead to vanishing signals in forward and backward propagation (Section 3 in [9]). This is also why the forget gates of the 2000 LSTM[16] were initially opened through positive bias weights: as long as the gates are open, it behaves like the 1997 LSTM. Similarly, a Highway Net whose gates are opened through strongly positive bias weights behaves like a ResNet. The skip connections used in modern neural networks (e.g., Transformers) are dominantly identity mappings.
DenseNets in 2016 [19] were designed as deep neural networks that attempt to connect each layer to every other layer. DenseNets approached this goal by using identity mappings as skip connections. Unlike ResNets, DenseNets merge the layer output with skip connections by concatenation, not addition.
Neural networks with Stochastic Depth [20] were made possible given the Residual Network architectures. This training procedure randomly drops a subset of layers and lets the signal propagate through the identity skip connection. Also known as "DropPath", this is an effective regularization method for training large and deep models, such as the Vision Transformer (ViT).
Biological Relation
The original Residual Network paper made no claim on being inspired by biological systems. But research later on has related Residual Networks to biologically-plausible algorithms. [21] [22]
A study published in Science in 2023 [23] disclosed the complete connectome of an insect brain (of a fruit fly larva). This study discovered "multilayer shortcuts" that resemble the skip connections in artificial neural networks, including ResNets.
References
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (10 Dec 2015). Deep Residual Learning for Image Recognition. arXiv:1512.03385.
- Srivastava, Rupesh Kumar; Greff, Klaus; Schmidhuber, Jürgen (3 May 2015). "Highway Networks". arXiv:1505.00387 [cs.LG].
- Sepp Hochreiter; Jürgen Schmidhuber (1997). "Long short-term memory". Neural Computation. 9 (8): 1735–1780. doi:10.1162/neco.1997.9.8.1735. PMID 9377276. S2CID 1915014.
- Deng, Jia; Dong, Wei; Socher, Richard; Li, Li-Jia; Li, Kai; Fei-Fei, Li (2009). "ImageNet: A large-scale hierarchical image database". CVPR.
- "ILSVRC2015 Results". image-net.org.
- Simonyan, Karen; Zisserman, Andrew (2014). "Very Deep Convolutional Networks for Large-Scale Image Recognition". arXiv:1409.1556 [cs.CV].
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2016). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification". arXiv:1502.01852 [cs.CV].
- Szegedy, Christian; Ioffe, Sergey; Vanhoucke, Vincent; Alemi, Alex (2016). "Inception-v4, Inception-ResNet and the impact of residual connections on learning". arXiv:1602.07261 [cs.CV].
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015). "Identity Mappings in Deep Residual Networks". arXiv:1603.05027 [cs.CV].
- Radford, Alec; Wu, Jeffrey; Child, Rewon; Luan, David; Amodei, Dario; Sutskever, Ilya (14 February 2019). "Language models are unsupervised multitask learners" (PDF). Archived (PDF) from the original on 6 February 2021. Retrieved 19 December 2020.
- Dong, Yihe; Cordonnier, Jean-Baptiste; Loukas, Andreas (2021). "Attention is not all you need: pure attention loses rank doubly exponentially with depth". arXiv:2103.03404 [cs.LG].
- Rosenblatt, Frank (1961). Principles of neurodynamics. perceptrons and the theory of brain mechanisms (PDF).
- Venables, W. N.; Ripley, Brain D. (1994). Modern Applied Statistics with S-Plus. Springer. ISBN 9783540943501.
- Ripley, B. D. (1996). Pattern Recognition and Neural Networks. Cambridge University Press.
- Hochreiter, Sepp (1991). Untersuchungen zu dynamischen neuronalen Netzen (PDF) (diploma thesis). Technical University Munich, Institute of Computer Science, advisor: J. Schmidhuber.
- Felix A. Gers; Jürgen Schmidhuber; Fred Cummins (2000). "Learning to Forget: Continual Prediction with LSTM". Neural Computation. 12 (10): 2451–2471. CiteSeerX 10.1.1.55.5709. doi:10.1162/089976600300015015. PMID 11032042. S2CID 11598600.
- Srivastava, Rupesh Kumar; Greff, Klaus; Schmidhuber, Jürgen (22 July 2015). "Training Very Deep Networks". arXiv:1507.06228 [cs.LG].
- Schmidhuber, Jürgen (2015). "Microsoft Wins ImageNet 2015 through Highway Net (or Feedforward LSTM) without Gates".
- Huang, Gao; Liu, Zhuang; van der Maaten, Laurens; Weinberger, Kilian (2016). Densely Connected Convolutional Networks. arXiv:1608.06993.
- Huang, Gao; Sun, Yu; Liu, Zhuang; Weinberger, Kilian (2016). Deep Networks with Stochastic Depth. arXiv:1603.09382.
- Liao, Qianli; Poggio, Tomaso (2016). Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex. arXiv:1604.03640.
- Xiao, Will; Chen, Honglin; Liao, Qianli; Poggio, Tomaso (2018). Biologically-Plausible Learning Algorithms Can Scale to Large Datasets. arXiv:1811.03567.
- Winding, Michael; Pedigo, Benjamin; Barnes, Christopher; Patsolic, Heather; Park, Youngser; Kazimiers, Tom; Fushiki, Akira; Andrade, Ingrid; Khandelwal, Avinash; Valdes-Aleman, Javier; Li, Feng; Randel, Nadine; Barsotti, Elizabeth; Correia, Ana; Fetter, Fetter; Hartenstein, Volker; Priebe, Carey; Vogelstein, Joshua; Cardona, Albert; Zlatic, Marta (10 Mar 2023). "The connectome of an insect brain". Science. 379 (6636): eadd9330. bioRxiv 10.1101/2022.11.28.516756v1. doi:10.1126/science.add9330. PMC 7614541. PMID 36893230. S2CID 254070919.